6D object pose estimation
객체의 6D pose를 추정하는 것은 로봇이 실제 환경과 상호작용하는 데 중요한 역할을 한다. 그러나 다양한 객체의 형태와 장면의 복잡성, 객체 간의 가림 및 혼잡 때문에 매우 어려운 과제이다.
관련 연구
6D object pose estimation에 관한 기존 연구는 templete-based method와 feature-based method로 나뉜다.
- templete-based method : 강체 템플릿을 생성하여 입력 이미지의 다양한 위치에서 스캔, 유사도 점수를 계산하여 텍스쳐가 없는 객체 감지.(객체가 가려진 경우 성능 저하)

- feature-based method : 이미지 픽셀에서 로컬 특징을 추출하고 2D-3D 대응을 설정하여 6D 자세 복원.(객체에 충분한 텍스쳐가 있어야 함)
이 두 방법의 장점을 결합한 심층 학습 프레임워크 제안
PoseCNN
객체의 중심을 이미지에서 지역화하고, 카메라와의 거리를 예측하여 객체의 3D 위치를 추정하며, 쿼터니언 표현을 통해 3D 회전을 추정한다.
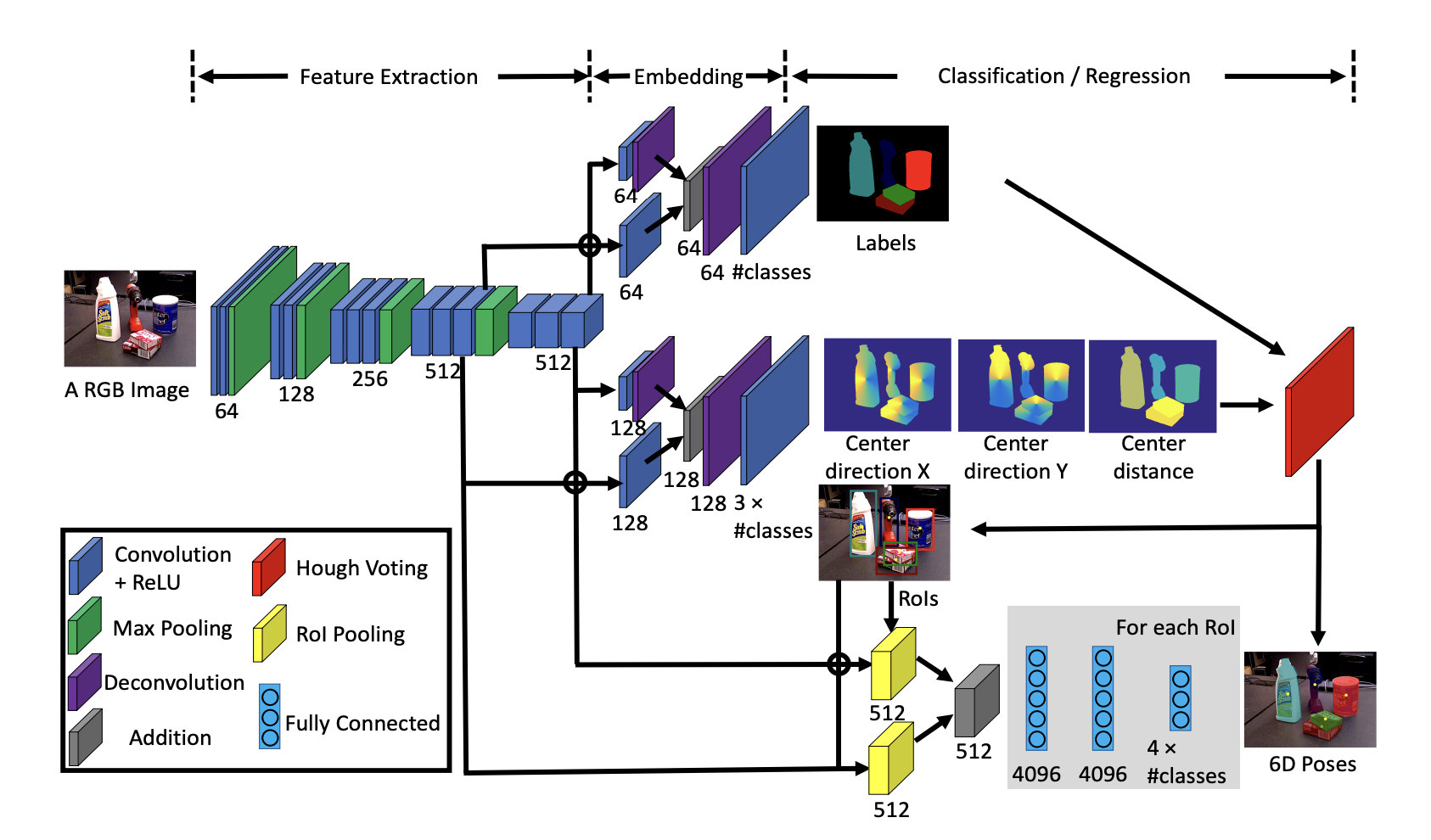
- 입력 : RGB 이미지
- 컨볼루션 레이어와 맥스 풀링 레이어를 거쳐 특징 맵 추출
- 임베딩 - 두 가지 경로
- Semantic Labeling을 위한 경로. 두 개의 컨볼루션 레이어를 거쳐 각 픽셀에 대한 객체 레이블 예측
- 중심 방향 예측과 중심 거리 예측을 위한 경로. 각 픽셀에 대해 객체 중심을 향한 단위 벡터와 객체 중심의 거리 예측
- 분류 및 회귀
- 시맨틱 레이블링 경로는 픽셀별 객체 레이블 예측
- 중심 방향 예측과 중심 거리 예측 경로는 각각 2D 중심 위치를 찾고 3D Translation을 추정
- Hough Voting 레이어를 사용하여 객체 중심을 찾고, 객체의 2D 경계 상자 생성
- 경계 상자를 사용하여 Rol 풀링 레이어를 통해 특징 맵을 crop and pool.(3D Rotation Regression)
- 각 Rol에 대해 3D 회전을 쿼터니언으로 회귀하여 6D pose 예측
- 최종 출력 : 각 객체의 6D pose
Overview
첫 번째 스테이지에서는 13개의 Convolution과 4개의 Max Pooling 레이어를 통해 Feature를 뽑아낸다. 두 번째 스테이지는 임베딩 단계인데, 첫 번째 단계에서 저차원 Feature를 가져와서 고차원 임베딩 단계로 접근한다. 이를 토대로 Semantic labeling을 진행한 후, 해당 정보들을 이용해 Translation과 Rotation을 추정한다.
Semantic Labeling
각 이미지 픽셀을 객체 클래스에 분류하여 객체에 대한 더 많은 정보를 제공하고 가려짐을 효과적으로 처리
semantic labeling branch에서 512d 채널 2개를 사용. 채널을 64d로 줄이며 resolution이 두 배가 되고 두 feature map을 합한 후 deconvolution layer를 통해 원본 이미지 사이즈로 바꾼다. 이 때 채널은 n개인데, 이는 semantic class의 개수이다.
training에서 softmax cross entropy loss를 사용해 픽셀의 class probability를 계산한다.
3D Translation Estimation
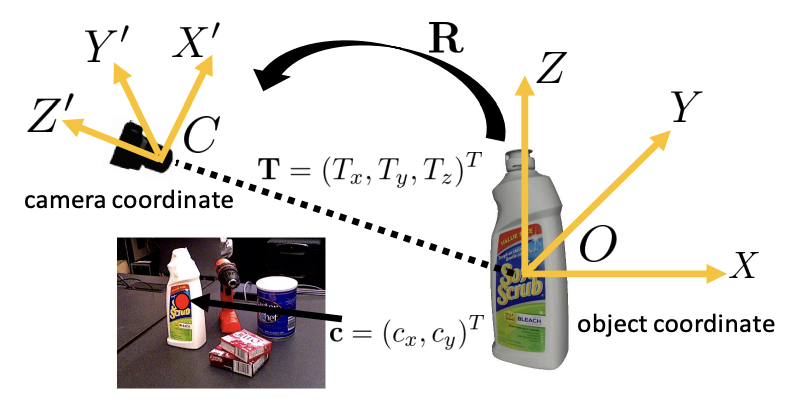
각 픽셀이 객체 중심을 향한 단위 벡터로 회귀하여 객체 중심의 2D 픽셀 좌표 예측. T를 이미지로 projection한 결과를 c=(cx,cy)라고 하면, c와 depth Tz를 알 수 있다면 Tx, Ty를 얻을 수 있다.
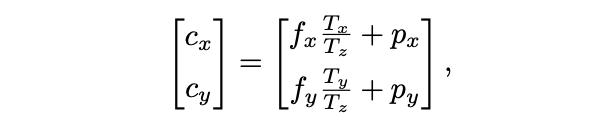
fx,fy는 카메라의 focal length, px,py는 principal point.
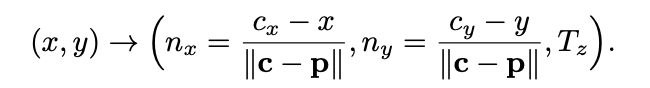
단위 벡터를 만들어 중심을 찾도록 학습한다.
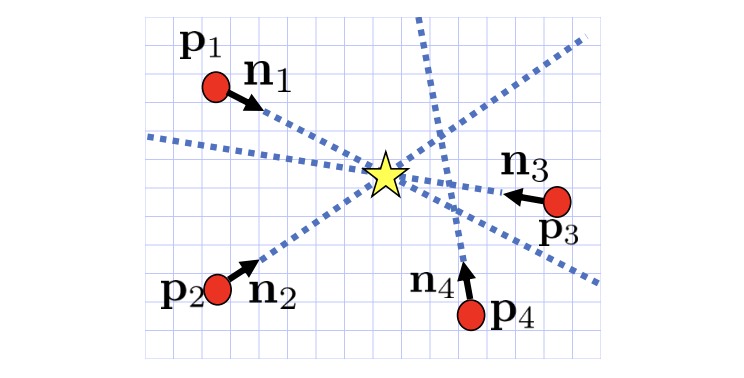
Hough vounting layer를 쌓아 2D 객체 중심을 찾는다. 객체 중심을 찾으면 물체 중심에 투표하는 픽셀을 inliner로 간주하고 Tz를 구한다.
카메라와의 거리를 추정하여 3D 번역을 복원.
3D Rotation Regression
객체의 회전을 쿼터니언 표현으로 회귀하기 위해 객체의 경계 상자 내부에서 특징을 추출함. 두 가지 손실함수(PoseLoss, ShapeMatch-Loss)를 도입하여 객체의 회전 추정을 처리.
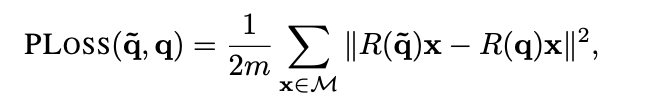
각 파라미터는 다음 정보들을 의미한다.
1. PLoss(a, b): 두 개의 회전행렬 사이의 손실(loss)
2. ~q, q: 회전을 나타내는 매개변수(예측값, GT)
3. x: 3D model 데이터 포인트(벡터)
4. M: 3D model point 집합
5. m: 포인트의 수
6. || -- ||: 벡터의 크기
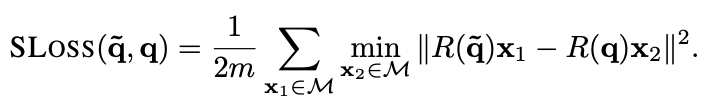
평가
YCB-Video 데이터셋과 OccludedLINEMOD 데이터셋을 활용.
평가 지표: ADD Metric(올바른 모델 포즈와 추정된 포즈 사이의 평균 거리 추정), ADD-S Metric(대칭 객체의 경우 가장 가까운 점 거리를 사용하여 평균 거리 계산)
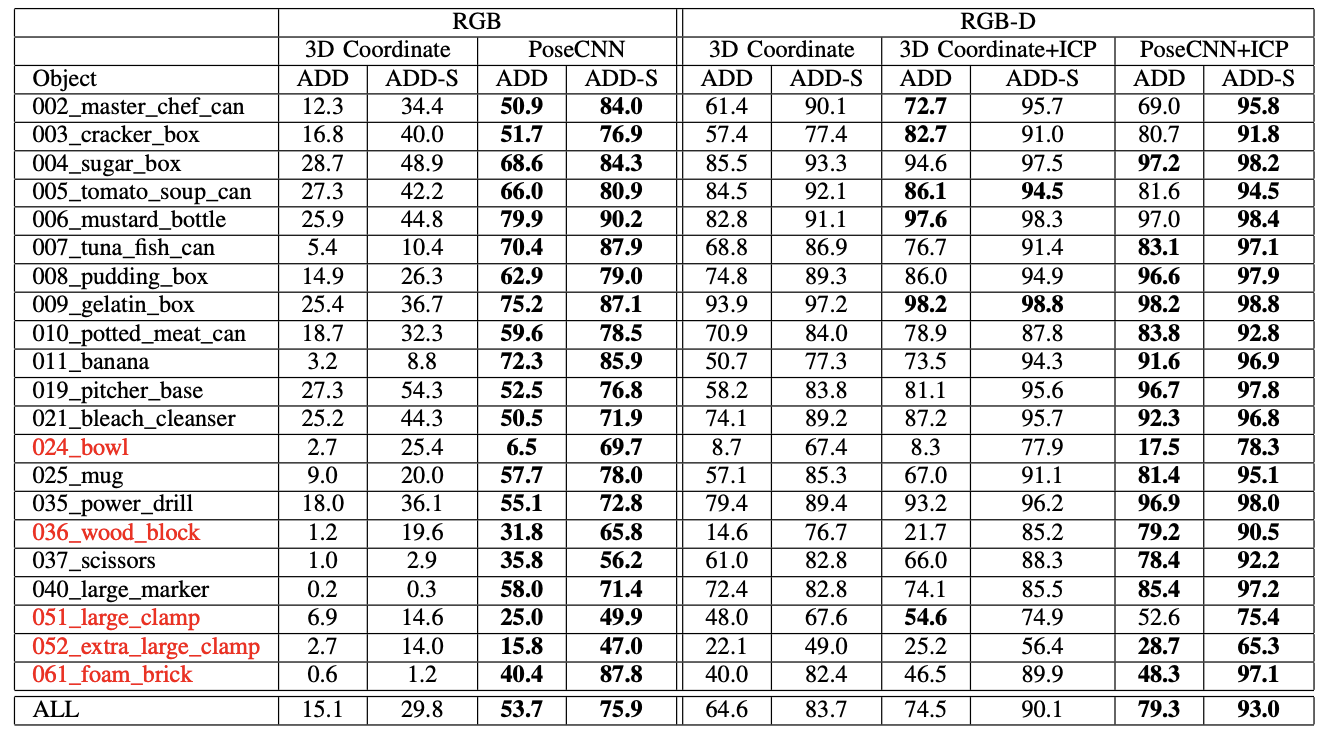
PoseCNN은 컬러 이미지만 사용하는 설정과 RGB-D 설정 모두에서 기준을 능가하며, 가려진 상황에서도 뛰어난 성능을 보여준다. 깊이 데이터를 사용한 ICP 알고리즘을 통해 자세를 정제하면 성능이 더욱 향상된다.
