RAG
검색-증강 생성(Retrieval-Augmented Generation)
LLM의 문제점
- 답변이 없을 때 허위 정보 제공. (할루시네이션)
- 사용자가 구체적이거나 최신의 응답을 기대하더라도 오래되었거나 일반적인 정보 제공.
- 신뢰할 수 없는 출처로부터 응답 생성.
- 용어 혼동으로 인해 응답이 정확하지 않음. 다양한 훈련 소스가 동일한 용어를 사용하여 서로 다른 내용을 설명함.
RAG란?
대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스.
- 사용자가 질문을 입력
- RAG가 외부 데이터베이스에서 질문과 관련된 정보를 검색
- 검색된 정보를 기반으로 LLM이 답변 생성
RAG의 이점
- 파인튜닝에 비해 시간과 비용이 적게 소요됨.
- 모델의 일반성을 유지할 수 있음.
- 답변의 근거를 제시할 수 있음.
- 할루시네이션 가능성을 줄일 수 있음.
작동 과정
- 데이터 임베딩 및 벡터 DB 구축
- 자체 데이터를 임베딩 모델에 통합
- 텍스트 데이터를 벡터 형식으로 변환하여 벡터 DB를 구축
- 벡터화된 정보가 풍부한 데이터베이스는 Retriever(문서 검색기) 부분에서 사용자의 쿼리와 관련된 정보를 찾는 데 활용됨.
- 쿼리 벡터화 및 관련 정보 추출(증강 단계)
- 사용자의 질문(쿼리)을 벡터화
- 벡터 DB를 대상으로 다양한 검색 기법을 사용하여 소스 정보에서 가장 관련성이 높은 부분 또는 상위 K개의 항목을 추출
- 추출된 관련 정보는 쿼리 텍스트와 함께 LLM에 제공
- LLM을 통한 답변 생성
- LLM은 쿼리 텍스트와 추출된 관련 정보를 바탕으로 최종 답변 생성
- 정확한 출처에 기반한 답변이 가능

활용 방법
- Raw data → Connecting
: 원본 데이터의 형식을 컴퓨터가 처리 가능한 형태로 변환해야 함. - Connecting → Embedding
: 데이터를 모델이 처리 가능한 작은 단위로 나누는 과정이 필요.
일반적으로 Chunking이라고 함. - Embedding
: 자연어를 벡터로 변환.
작은 덩어리로 나누어진 데이터와 사용자의 질문을 모두 임베딩해야 함. - Vector DB
: 임베딩으로 변환한 벡터를 저장하는 데이터베이스.
고차원 벡터 데이터를 효율적으로 관리하고 검색하는 데 특화되어 있음.
다양한 기업에서 벡터 DB를 지원하고 있어, 사용자는 목적에 맞는 벡터 DB를 선택할 수 있음. - Retrieval
: 벡터 데이터베이스에 저장된 데이터와 사용자의 질문을 매칭하여, 질문에 가장 적합한 데이터 검색.
검색 로직은 직접 구현하거나, 벡터 DB에서 제공하는 기능을 활용할 수 있음.
프롬프트 엔지니어링
- 언어모델에게 정확한 정보나 창의적인 콘텐츠를 생성하도록 지시하는 방법을 연구하는 분야를 의미.
- 프롬프트란? 인공지능에게 주는 입력 문장이나 질문.
- 인공지능이 원하는 대답을 하도록 프롬프트를 잘 설계하는 것이 인공지능의 출력 품질을 결정함.
프롬프트 엔지니어링 구성 요소
- Instruction : 모델이 수행하기를 원하는 특정 작업 또는 지침
- Context : 모델을 조정할 수 있는 외부 정보 또는 추가 맥락
- Input data : 답변을 찾고자 하는 입력 또는 질문
- Output indicator : 출력의 유형 또는 형식을 의미
#Prompt
Classify the text into neutral, negative, or positive #instruction
Text: I think the food was okay #input data
Sentiment: #output indicator프롬프트 엔지니어링 유형
- zero-shot : 예제를 구성하지 않고 요청
- one-shot : 하나의 예제로 구성하는 프롬프트
- few-shot : 여러 개의 예제로 구성하는 프롬프트
- Chain-of-Thought Prompting : 복잡한 문제를 해결할 때 순차적 해결 방안을 알려주기(계산 식을 풀어서 설명하는 등)
- zero-shot CoT Prompting : A:"순차적으로 생각해봐"
프롬프트 노하우
- 지시 사항은 최대한 구체적이고 명확하게 전달
- 모델에게 역할을 부여하는 것이 더 명확한 답변을 이끌어냄.
- 원하는 답변 형식을 지정하는 것도 중요
- 프롬프트 예제를 다양하게 구성
- 모델이 다양한 케이스에 대한 패턴을 파악할 수 있도록
- 지시문에는 부정문보다 긍정문을 사용
- 언어모델은 'generation'하는 모델이기 때문
- 계절감 있는 출력 결과가 나오게 하고 싶으면, 예제에 날짜나 시즌 어휘를 추가
- ex) 크리스마스, 설날 등
- 대상자를 지정
- 대상자 정확히 인식, 문장의 목적 구체화
프롬프트 마켓 등장
...!
CoT에 이은 SoT
Skeleton-of-Thoguhts
- 병렬 처리를 통해 LLM의 효율성을 극대화하는 방법론
- 뼈대 단계(Skeleton stage) 먼저 답변의 주요 요점들을 간단히 나열한 후, 요점 확장 단계(Point-expanding stage)를 통해 병렬적으로 확장해 나가는 것
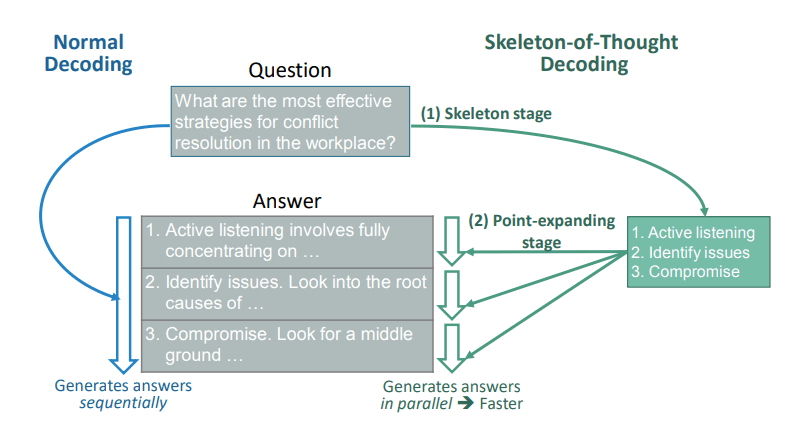
SoT의 장점
- 효율성 향상
- 기존의 언어 모델은 시퀀스 기반으로 순차적으로 텍스트를 생성하기 때문에 추론을 위해 많은 시간이 소요됨.
- SoT에서는 응답의 틀을 먼저 구성한 후 세부 내용을 채우는 방식을 사용함으로써 대규모 언어 모델의 응답 속도를 개선함.
- 여러 부분을 동시에 생성함으로써 전체 생성 시간 단축.
- 구조화된 사고 프로세스
- 전체 응답의 논리적인 흐름을 미리 셀계할 수 있음.
- 골격은 필요에 따라 쉽게 수정하거나 확장할 수 있음.
- 새로운 아이디어나 정보를 추가 시, 전체 구조를 크게 해치지 않고 유연하게 대응 가능.
- 복잡한 주제의 체계적 분석
- 골격은 주요 논점을 명확히 하고 각 부분을 체계적으로 분석할 수 있게 함.
- ex) 학술 연구, 비즈니스 보고서, 창의적 글쓰기, 교육
#시스템
- 사용자의 질문을 받으면, 먼저 문제를 명확히 정의하고 핵심 질문을 파악합니다.
- 문제 해결을 위한 단계별 접근 방식을 이용합니다.
- 각 단계에 대해 간단한 설명을 제공하세요. 이는 전체 사고 과정의 뼈대 역할을 합니다.
- 뼈대의 문장은 충분히 완결적인 문장으로 완성합니다.
- 답변은 논리적이고 구조화되어야 하며, 각 단계가 어떻게 최종 결론으로 이어지는지 명확히 보여주어야 합니다.
KU ICTM