
1장. 컴퓨터 구조를 알아야 하는 이유
1) 문제 해결 능력 향상
- 코드를 정확히 작성했음에도 제대로 실행이 되지 않을 때, 그 원인의 근간을 알아야문제를 해결할 수 있음.
- 컴퓨터를 미지의 대상에서 분석의 대상으로 바라볼 수 있도록 해야함.
2) 성능, 용량, 비용을 고려한 개발 가능
- 개발된 서비스가 필요로 하는 성능, 용량, 비용을 판단할 수 있는 능력은 필수
- 컴퓨터 구조는 결국 성능, 용량, 비용에 대한 이야기
2장. 컴퓨터 구조의 큰 그림
1) 컴퓨터가 이해하는 정보
- 데이터
- 숫자, 문자, 이미지, 동영상과 같은 정적인 정보
- 컴퓨터와 주고받는/내부에 저장된 정보를 데이터라 통칭
- 0과 1로 숫자/문자를 표현하는 방법
- 명령어
- 컴퓨터를 실질적으로 움직이는 정보
- 데이터는 명령어를 위한 일종의 재료
2) 컴퓨터의 네가지 핵심 부품 (+ 알파)
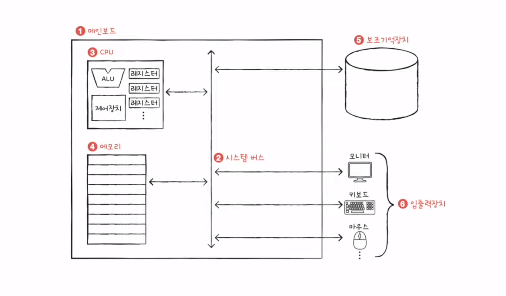
CPU
- Youtube 참고자료
- CPU는 메모리에 저장된 값을 읽어 들이고, 해석하고, 실행하는 장치이다.
- CPU 내부에는 ALU, 레지스터, 제어장치가 있다.
- ALU(산술논리연산장치)는 계산하는 장치
- 레지스터는 임시 저장 장치, CPU 내부의 작은 저장장치
- 제어장치는 제어 신호를 발생시키고 명령어를 해석하는 장치

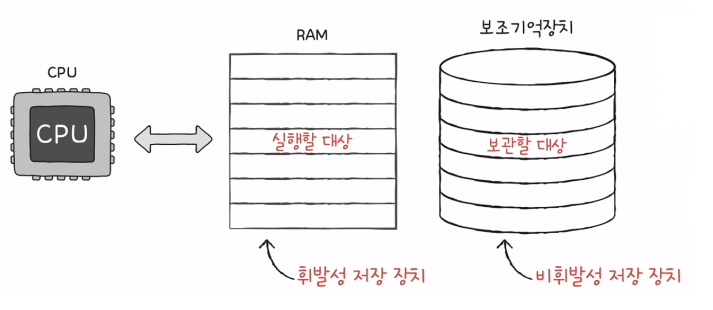
메모리/주기억장치 (RAM, ROM)
- 프로그램이 실행되기 위해서는 메모리에 저장되어 있어야 한다.
- 메모리는 현재 실행되는 프로그램의 명령어와 데이터를 저장한다.
- 메모리에 저장된 값의 위치는 주소로 알 수 있다.

보조기억장치
- 메모리는 전원이 꺼지면 저장된 내용을 잃는다. 휘발성 저장장치.
- 따라서, 보조기억장치는 보관할 정보를 저장한다.

입출력장치
- 컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환할 수 있는 부품
- 보조기억장치와 입출력장치를 합쳐 주변장치(peripheral device)라 통칭하기도 한다.

메인보드 (마더보드)
- 메인보드에 연결된 부품은 버스를 통해 정보를 주고 받음
- 버스는 텀퓨터의 부품끼리 정보를 주고받는 일종의 통로
- 컴퓨터의 핵심 부품을 연결하는 버스는 시스템 버스
- 시스템 버스의 내부 구성
- 주소 버스: 주소를 주고받는 통로
- 제어 버스: 제어 신호를 주고받는 통로
- 데이터 버스: 명령어와 데이터를 주고받는 통로

3장. 컴퓨터의 4가지 핵심 부품 직접 보기
Youtube 참고자료
4장. 0과 1로 숫자를 표현하는 방법
1) 정보 단위
- 비트(bit) : 0과 1을 표현하는 가장 작은 정보 단위
- n비트로 만큼 표현 가능
- 비트보다 더 큰 단위 사용
- 바이트, 킬로바이트, 메가바이트, 기가바이트, 테라바이트...
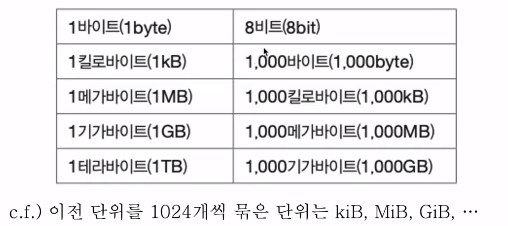
- 바이트, 킬로바이트, 메가바이트, 기가바이트, 테라바이트...
- 워드(word)
- CPU가 한 번에 처리할 수 있는 정보의 크기 단위
- 하프 워드 (half word): 워드의 절반 크기
- 풀 워드 (full word): 워드 크기
- 더블 워드 (double word): 워드의 두 배 크기
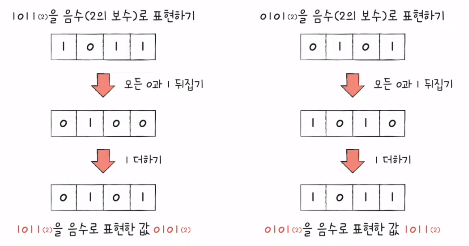
2) 이진법 (2진법)
- 0과 1로 음수 표현하기: 2의 보수
- 어떤 수를 그보다 큰 에서 뺀 값
- 모든 0과 1을 뒤집고 1 더한 값
3) 십육진법 (16진법)
- 이진법으로 숫자의 길이가 너무 길어짐
- 그래서 컴퓨터의 데이터를 표현할 때 십육진법도 많이 사용
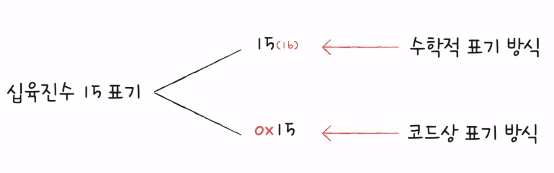
5장. 0과 1과 문자를 표현하는 방법
1) 문자 집합과 인코딩
- 문자 집합 (character set)
- 컴퓨터가 이해할 수 있는 문자의 모음
- 인코딩 (encoding)
- 코드화하는 과정
- 문자를 0과 1로 이루어진 문자 코드로 변환하는 과정
- 디코딩 (decoding)
- 코드를 해석하는 과정
- 0과 1로 표현된 문자 코드를 문자로 변환하는 과정
2) 아스키 코드
- 초창기 문자 집합 중 하나
- 알파벳, 아라비아 숫자, 일부 특수 문자 및 제어 문자
- 7비트로 하나의 문자 표현
- 8비트 중 1비트는 오류 검출을 위해 사용되는 패리티 비트(parity bit)
- A는 65로 인코딩, a는 97로 인코등 등..
- 간단한 인코딩. 그러나, 한글을 포함한 다른 언어 문자, 다양한 특수 문자 표현 불가
- 아스키 코드는 7비트로 하나의 문자를 표현하여, 128개보다 많은 문자를 표현할 수 없음.
- 8비트 확장 아스키 (extended ASCII)의 등장, 여전히 부족
3) 한글 인코딩: 완성형 vs 조합형 인코딩
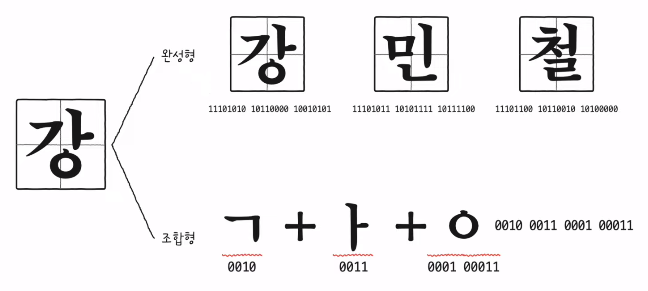
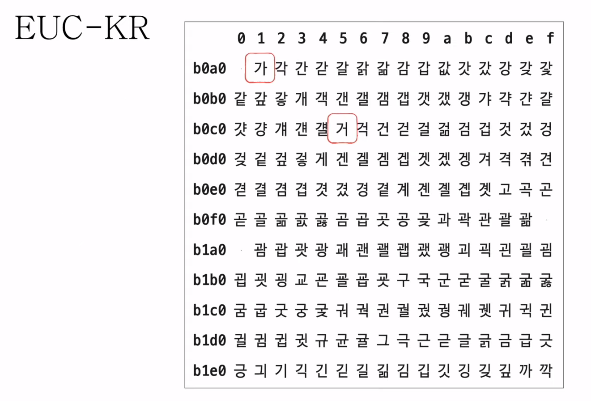
4) EUC-KR
- KS X 1001 KS X 1003 문자집합 기반의 한글 인코딩 방식
- 완성형 인코딩
- 글자 하나 하나에 2바이트 크기의 코드 부여
- 2바이트 == 16비트 == 4자리 십육진수로 표현
- 직접 인코딩해보기
- 2300여개의 한글 표현 가능
- 여전히 모든 한글을 표현하기에는 부족한 수
- 쀏, 뙠, 휔 같은 한글은 표현 불가능
5) 유니코드와 UTF-8
-
유니코드
- 통일된 문자 집합
- 한글, 영어, 화살표와 같은 특수 문자, 심지어 이모티콘까지
- 현재 문자 표현에 있어 매우 중요한 위치
-
유니코드의 인코딩 방식
- utf-8, utf-16, utf-32 등...
-
UTF-8 인코딩
- UTF(Unicode Transformation Format) == 유니코드 인코딩 방법
- 가변 길이 인코딩: 인코딩 결과가 1바이트 ~ 4바이트
- 인코딩 결과가 몇 바이트가 될지는 유니코드에 부여된 값에 따라 다름
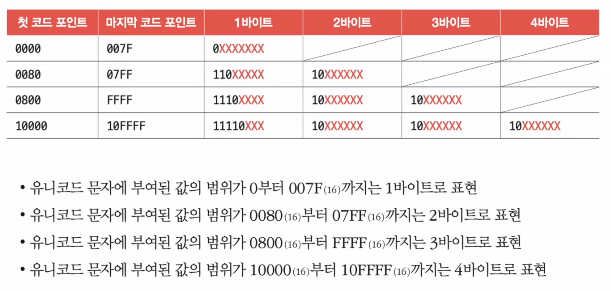
- '한'과 '글'의 인코딩
- 한: D55C (== 1101 0101 0101 1100) => 11101101 10010101 10011100
- 글: AE00 (== 1010 1110 0000 0000) => 11101010 10111000 10000000
6장. 소스코드와 명령어
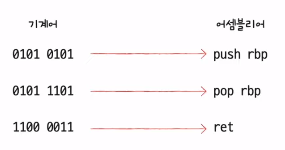
1) 고급 언어와 저급 언어
- 고급 언어: 개발자가 이해하기 쉽게 만든 언어
- 저급 언어: 컴퓨터가 이해하고 실행하는 언어
- 기계어: 0과 1로 이루어진 명령어로 구성된 저급 언어
- 어셈블리어: 0과 1로 이루어진 기계어를 읽기 편한 형태로 번역한 저급 언어
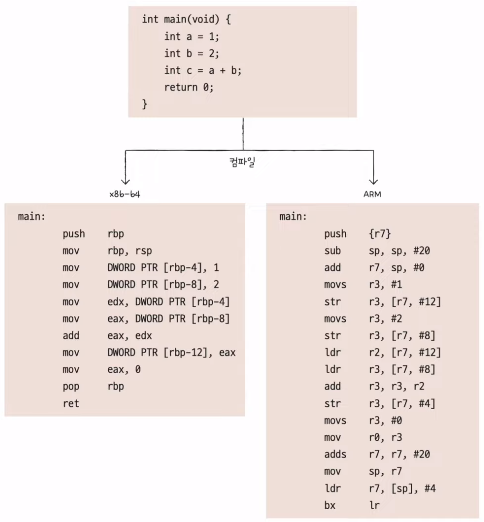
2) 컴파일 언어와 인터프리터 언어
- 컴파일 언어
- 인터프리터 언어
- 인터프리터에 의해 한 줄씩 실행
- 소스 코드 전체가 저급 언어로 변환되기까지 기다릴 필요 없음
- 컴파일 & 인터프리트 과정 살펴보기
- 흑백논리로 세상 모든 언어가 컴파일/인터프리트 언어로 구분되지 않는다. (ex. java)
- 대표적인 고급 언어의 예일 뿐..
7장. 명령어의 구조와 주소 지정 방식
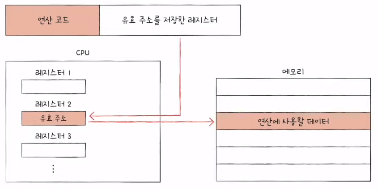
1) 명령어의 구조
- 연산 코드
- 오퍼랜드
- 연산에 사용될 데이터 or 연산에 사용될 데이터가 저장된 위치(주소 필드)
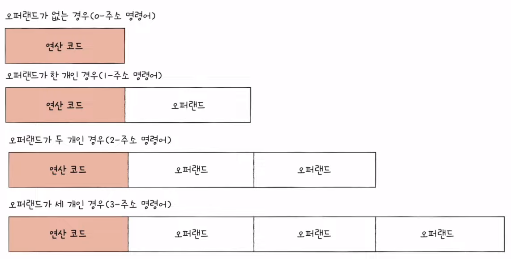
- 연산에 사용될 데이터 or 연산에 사용될 데이터가 저장된 위치(주소 필드)
2) 대표적인 연산 코드의 종류
- 데이터 전송
- MOVE: 데이터를 옮겨라
- STORE: 메모리에 저장하라
- LOAD(FETCH): 메모리에서 CPU로 데이터를 가져와라
- PUSH: 스택에 데이터를 저장하라
- POP: 스택의 최상단 데이터를 가져와라
- 산술/논리 연산
- ADD/SUBTRACT/MULTIPLY/DIVIDE: 덧셈/뺄셈/곱셈/나눗셈을 수행하라
- INCREMENT/DECREMENT: 오퍼랜드에 1을 더하라 / 오퍼랜드에 1을 빼라
- AND/OR/NOT: AND/OR/NOT 연산을 수행하라
- COMPARE: 두 개의 숫자 또는 TRUE/FALSE 값을 비교하라
- 제어 흐름 변경
- JUMP: 특정 주소로 실행 순서를 옮겨라
- CONDITIONAL JUMP: 조건에 부합할 때 특정 주소로 실행 순서를 옮겨라
- HALT: 프로그램의 실행을 멈춰라
- CALL: 되돌아올 주소를 저장한 채 특정 주소로 실행 순서를 옮겨라
- RETURN: CALL을 호출할 때 저장했던 주소로 돌아가라
- 입출력 제어
- READ (INPUT): 특정 입출력 장치로부터 데이터를 읽어라
- WRITE (OUTPUT): 특정 입출력 장치로 데이터를 싸ㅓ라
- START IO: 입출력 장치를 시작하라
- TEST IO: 입출력 장치의 상태를 확인하라
3) 명령어 주소 지정 방식
- 주소 값을 사용하는 이유
- 오퍼랜드 갯수에 따라 데이터를 저장할 크기가 제한됨
- 더 큰 용량의 데이터를 저장하기 위해서
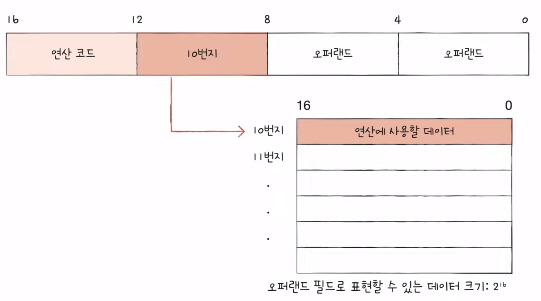
- 유효 주소 (effective address)
- 연산에 사용할 데이터가 저장된 위치
- 명령어 주소 지정 방식 (addressing modes)
- 연산에 사용할 데이터가 저장된 위치를 찾는 방법
- 유효 주소를 찾는 방법
- 다양한 명령어 주소 지정 방식들
- 즉시 주소 지정 방식 (immediate addressing mode)
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시
- 가장 간단한 형태의 주소 지정 방식
- 연산에 사용할 데이터의 크기가 작아질 수 있지만, 빠름

- 직접 주소 지정 방식 (direct addressing mode)
- 오퍼랜드 필드에 유효 주소 직접적으로 명시
- 유효 주소를 표현할 수 있는 크기가 연산 코드만큼 줄어듦
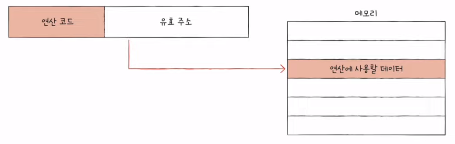
- 간접 주소 지정 방식 (indirect addressing mode)
- 오퍼랜드 필드에 유효 주소의 주소를 명시
- 앞선 주소 지정 방식들에 비해 속도가 느림
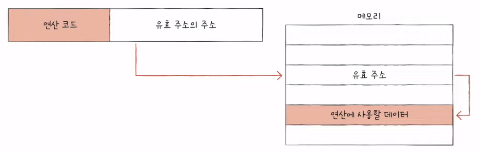
- 레지스터 주소 지정 방식 (register addressing mode)
- 연산에 사용할 데이터가 저장하는 레지스터 명시
- 메모리에 접근하는 속도보다 레지스터에 접근하는 것이 빠름
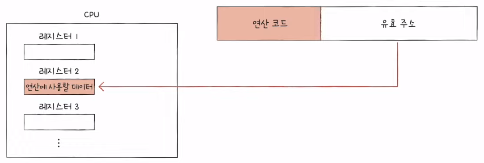
- 레지스터 간접 주소 지정 방식 (register indirect addressing mode)
- 연산에 사용할 데이터를 메모리에 저장
- 그 주소를 저장한 레지스터를 오퍼랜드 필드에 명시
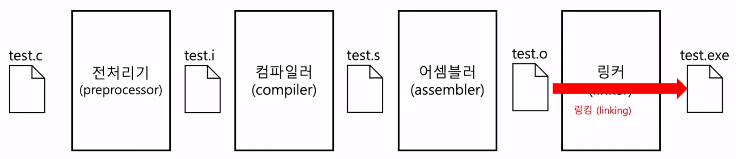
8장. C언어의 컴파일 과정
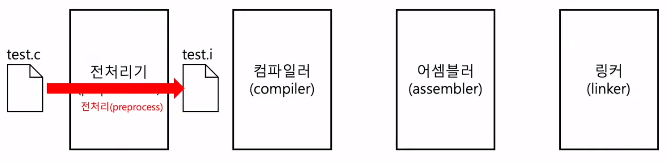
1) 전처리 과정 (preprocessing)
- 본격적으로 컴파일하기 전에 처리할 작업들
- 외부에 선언된 다양한 소스 코드, 라이브러리 포함 (e.g. #include)
- 프로그래밍의 편의를 위해 작성된 매크로 변환 (e.g. #define)
- 컴파일할 영역 명시 (e.g. #if, #ifedf, ...)
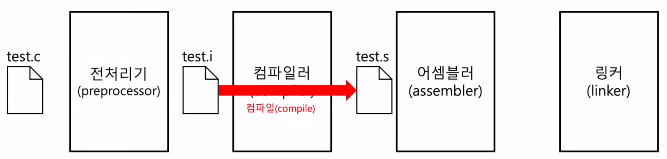
2) 컴파일 과정 (compiling)
- 전처리가 완료 되어도 여전히 소스 코드
- 전처리 완료된 소스 코드를 저급 언어(어셈블리 언어)로 변환
3) 어셈블 과정 (assembling)
- 어셈블리어를 기계어로 변환
- 목적 코드(object file)를 포함하는 목적 파일이 됨
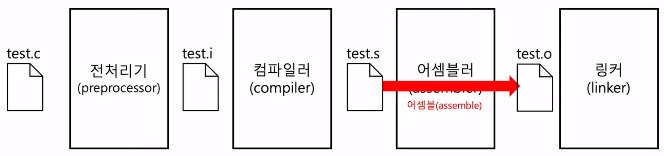
4) 목적 파일 vs 실행 파일
- 목적 파일과 실행 파일은 둘 다 기계어로 이루어진 파일
- But, 목적 파일과 실행 파일은 다르다
- 목적 파일(.o)은 링킹(linking)을 거친 이후에야 실행 파일(.exe)이 된다
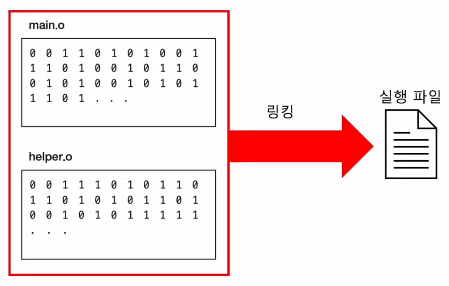
5) 링킹 과정 (linking)
- 다른 목적 파일을 하나의 실행 파일로 묶어주는 작업
9장. CPU의 내부 구성 - ALU와 제어장치
들어가기에 앞서, ALU와 제어장치의 회로에 대한 내용은 다루지 않고, 각각이 내보내고 받아들이는 정보에 대한 것들만 다룰 예정
1) ALU
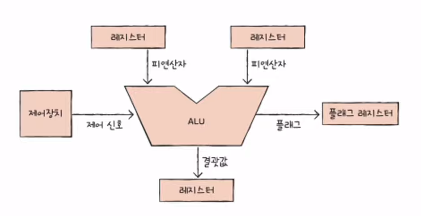
- 레지스터로부터 피연산자를 받아들이고, 제어장치로부터 제어 신호를 받아들인다.
- 플래그
- 연산 결과에 대한 부가 정보
- 플래그 레지스터에 저장됨
- 오버플로우가 나도 플래그 레지스터에 저장한다.

2) 제어장치
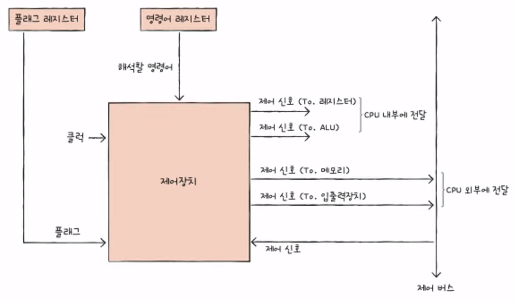
- 클럭
- 컴퓨터의 모든 부품을 일사분란하게 움직일 수 있게 하는 시간 단위
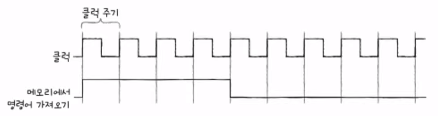
- 컴퓨터의 모든 부품을 일사분란하게 움직일 수 있게 하는 시간 단위
10장. CPU의 내부 구성 - 레지스터
cpu마다 레지스터의 종류는 다르다. 따라서 가장 대표적인 레지스터들에 대해 공부해보자.
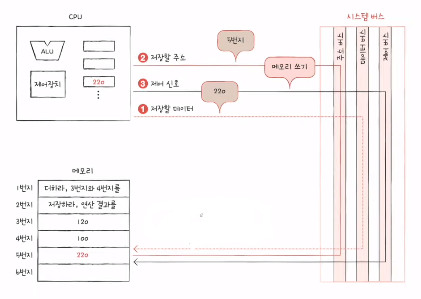
1) 반드시 알아야할 레지스터 1
- 프로그램 카운터
- 메모리에서 가져올 명령어의 주소(메모리에서 읽어 들일 명령어의 주소)
- Instruction Pointer(명령어 포인터)라고 부르는 CPU도 있음
- 명령어 레지스터
- 해석할 명령어 (방금 메모리에서 읽어들인 명령어)
- 메모리 주소 레지스터
- 메모리의 주소
- CPU가 읽어 들이고자 하는 주소를 주소 버스로 보낼 때 거치는 레지스터
- 메모리 버퍼 레지스터
- 메모리와 주고받을 값 (데이터와 명령어)
- CPU가 정보를 데이터 버스로 주고받을 때 거치는 레지스터
2) 순차적인 실행 흐름이 끊기는 경우
- 특정 메모리 주소로 실행 흐름을 이동하는 명령어 실행 시
- e.g. JUMP, CONDITIONAL JUMP, CALL, RET
- 인터럽트 발생시
3) 반드시 알아야할 레지스터 2
- 플래그 레지스터
- 연산 결과 또는 CPU 상태에 대한 부가적인 정보
- 범용 레지스터
- 다양하고 일반적인 상황에서 자유롭게 사용
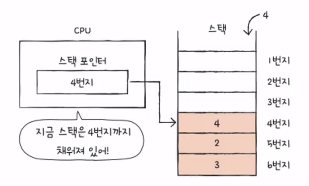
- 스택 포인터
- 스택 주소 지정 방식(: 스택과 스택 포인터를 이용한 주소 지정 방식)에 사용
- 스택의 곡대기를 가리키는 레지스터 (스택이 어디까지 차 있는지에 대한 표시)
- 스택은 메모리 안(스택 영역)에 있음.
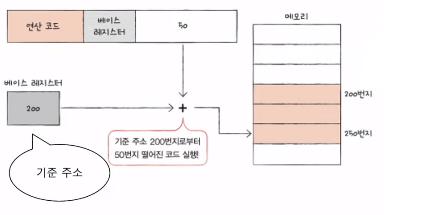
- 베이스 레지스터
- 기준 주소 저장
- 변위 주소 지정 방식에 사용
- 오퍼랜드 필드의 값(변위)과 특정 레지스터의 값(프로그램 카운터 or 베이스 레지스터)을 더하여 유효 주소 얻기
- 상대 주소 지정 방식: 오퍼랜드 필드의 값(변위)과 프로그램 카운터를 더하여 유효 주소 얻기
- 베이스 레지스터 주소 지정 방식: 오퍼랜드 필드의 값(변위)과 베이스 레지스터를 더하여 유효 주소 얻기
11장. 명령어 사이클과 인터럽트
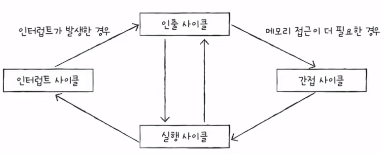
1) 명령어 사이클
- 프로그램 속 명령어들은 일정한 주기가 반복되며 실행. 이 주기를 명령어 사이클이라고 한다.
- 인출 사이클: 가장 먼저 CPU로 가지고 온다.
- 실행 사이클: 가지고 온 것을 실행한다.
- 인출-실행-인출-실행.. 이 반복된다.
- 하지만 CPU로 명령어를 가지고 와도 바로 실행이 불가능한 경우가 있다. 간접 사이클이 필요.
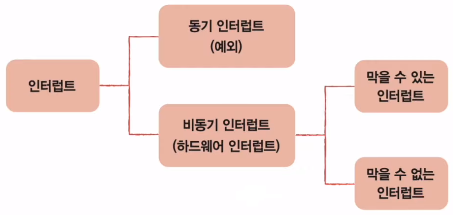
2) 인터럽트
- 동기 인터럽트 (예외): CPU가 예기치 못한 상황을 접했을 때 발생
- 폴트, 트랩, 중단, 소프트웨어 인터럽트가 있음
- 비동기 인터럽트 (하드웨어 인터럽트): 주로 입출력장치에 의해 발생
- 입출력 작업 도중에도 효율적으로 명령어를 처리하기 위해 하드웨어 인터럽트 사용
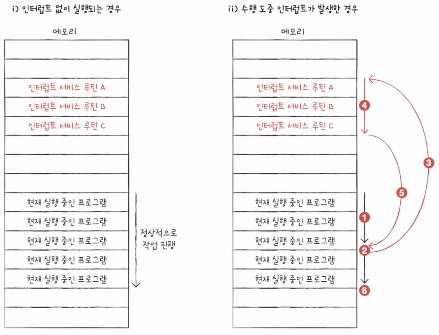
3) 하드웨어 인터럽트의 처리 순서
인터럽트의 종류를 막론하고 인터럽트 처리 순서는 대동소이하다.
- 입출력 장치는 CPU에 인터럽트 요청 신호를 보낸다.
- CPU는 실행 사이클이 끝나고 명령어를 인출하기 전 항상 인터럽트 여부를 확인한다.
- CPU는 인터럽트 요청을 확인하고 인터럽트 플래그를 통해 현재 인터럽트를 받아들일 수 있는지 여부를 확인한다.
- 인터럽트를 받아들일 수 있다면, CPU는 지금까지의 작업을 백업한다. (메모리의 스택 영역에 백업)
- CPU는 인터럽트 벡터를 참조하여 인터럽트 서비스 루틴을 실행한다.
- 인터럽트 서비스 루틴 실행이 끝나면 4.에서 백업해 둔 작업을 복구하여 실행을 재개한다.
키워드 정리
- 인터럽트 요청 신호: CPU의 작업을 방해하는 인터럽트에 대한 요청신호
- 인터럽트 플래그: 플래그 레지스터 속에 있는 인터럽트 요청 신호를 받아들일지 무시할지를 결정하는 비트
- 인터럽트 벡터: 인터럽트 서비스 루틴의 시작 주소를 포함하는 인터럽트 서비스 루틴의 식별 정보
- 인터럽트 서비스 루틴: 인터럽트가 발생했을 때 해당 인터럽트를 처리하기 위한 프로그램
- 인터럽트 서비스 루틴도 프로그램이기에 메모리에 저장
12장. 빠른 CPU를 위한 설계 기법
1) 클럭
- 컴퓨터 부품들은 '클럭 신호'에 맞춰 움직인다.
- 클럭 속도가 빠를수록 일반적으로 CPU가 빠른 것은 맞다. 필요 이상으로 클럭을 높이면 발열이 심각해짐.
- 클럭 속도: 헤르츠(Hz) 단위로 측정
- 헤르츠(Hz): 1초에 클럭이 반복되는 횟수
- 클럭이 1초에 100번 반복되면 100Hz
- 클럭 속도를 늘리는 방법 이외에는?
- 코어 수를 늘리는 방법
- 스레드 수를 늘리는 방법
2) 코어 & 멀티 코어
- 코어(Core)란?
- CPU 내에서 명령어를 실행하는 부품으로 여러 개 있을 수 있음
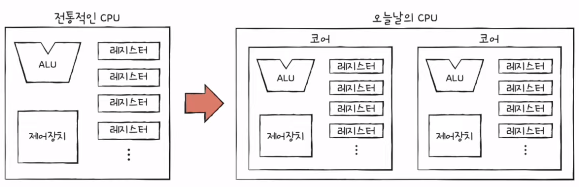
- CPU 내에서 명령어를 실행하는 부품으로 여러 개 있을 수 있음
- 꼭 코어 수에 비례하여 증가하는 것은 아님.
3) 스레드 & 멀티 스레드
-
하드웨어적 스레드
- 논리 프로세서라고도 부른다.
- 하나의 코어가 동시에 처리하는 명령어 단위
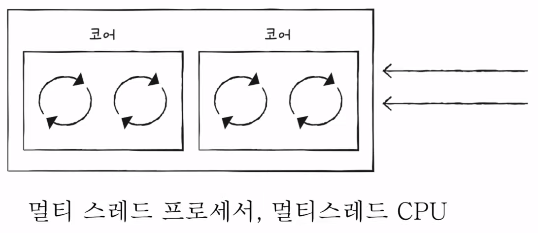
- 하나의 코어가 멀티 스레드를 가지는 가장 큰 핵심은 레지스터이다.
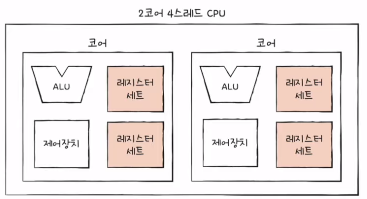
-
소프트웨어적 스레드
- 하나의 프로그램에서 독립적으로 실행되는 단위
- 1코어 1스레드 CPU도 여러 개의 소프트웨어적 스레드를 만들 수 있다.
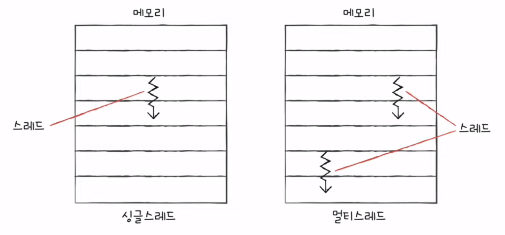
13. 명령어 병렬 처리 기법
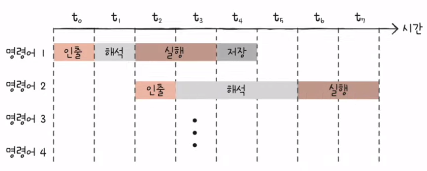
1) 명령어 파이프라인
- 명령어 처리 과정
- 명령어 인출 (Instruction Fetch)
- 명령어 해석 (Instruction Decode)
- 명령어 실행 (Execute Instruction)
- 결과 저장 (Write Back)
- 같은 단계가 겹치지만 않는다면 CPU는 각 단계를 동시에 실행할 수 있다. 아래 사진이 명령어 파이프라인
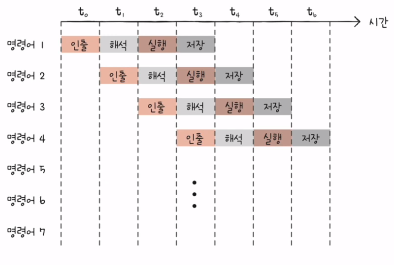
- 명령어 파이프라인을 사용하지 않는다면..
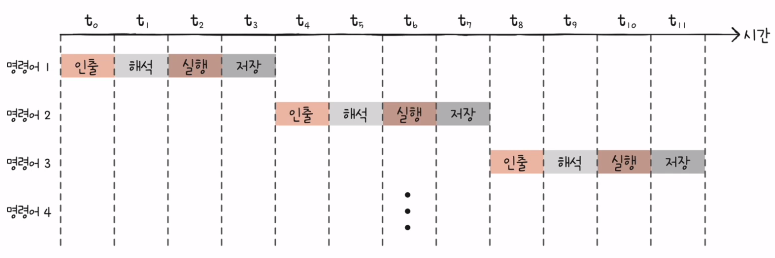
- 파이프라인 위험: 명령어 파이프라인이 성능 향상에 실패하는 경우
- 데이터 위험
- 명령어 간의 의존성에 의해 야기
- 모든 명령어를 동시에 처리할 수는 없다.
- 이전 명령어를 끝까지 실행해야만 비로소 실행할 수 있는 경우
- 제어 위험
- 프로그램 카운터의 갑작스러운 변화
- 분기 예측(branch prediction)을 통해 극복 가능
- 구조 위험
- 서로 다른 명령어가 같은 CPU 부품(ALU, 레지스터)를 사용하려고 하는 경우
- 데이터 위험
2) 슈퍼스칼라
- CPU 내부에 여러 개의 명령어 파이프라인을 포함한 구조
- 오늘날의 멀티스레드 프로세서
- 이론적으로는 파이프라인 개수에 비례하여 처리 속도 증가
- 하지만 파이프라인 위험도의 증가로 인해 파이프라인 개수에 비례하여 처리 속도가 증가하지 않음.
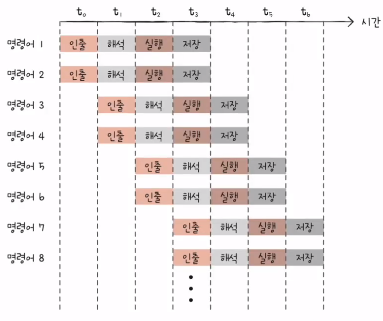
3) 비순차적 명령어 처리
- 파이프라인의 중단을 방지하기 위해 명령어를 순차적으로 처리하지 않는 명령어 병렬 처리 기법
- 100번지와 101번지의 값이 결정 된 이후에 3번을 실행하는 것으로 순서를 바꾸면 파이프라인의 중단이 일어나지 않는다.
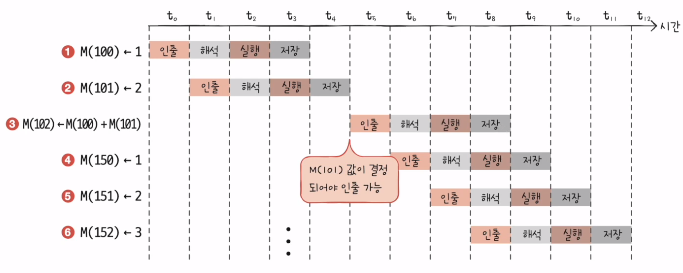
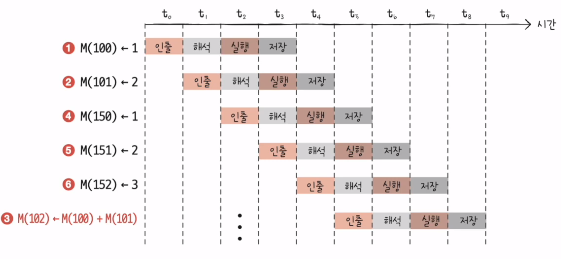
14장. 명령어 집합 구조, CISC와 RISC
1) 명령어 집합 (ISA)
- CPU가 이해할 수 있는 명령어들의 모음
- 인텔의 CPU는 일반적으로 "X86 (X86-64)" 명령어 집합을 따른다.
- 애플의 CPU는 일반적으로 "ARM" 명령어 집합을 따른다.
- 인텔에서 만든 실행파일을 그래도 아이폰에 옮겨 실행하면 실행이 안됨.
- CPU에 따라 고급언어를 저급언어로 만드는 방식이 다르기 때문.
- 명령어 집합(구조)는 사실상 CPU의 언어인 셈이다.
- 명령어가 달라지면 그에 대한 나비효과로 많은 것들이 달라짐
- 명령어 해석 방식, 레지스터의 종류와 개수, 파이프라이닝의 용이성 등..
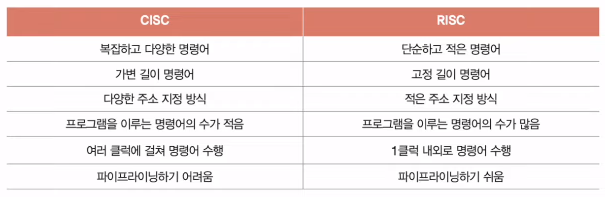
2) CISC (Complex Instruction Set Computer)
- 해석하면 "복잡한 명령어 집합을 활용하는 컴퓨터"
- x86, x86-64는 CISC 기반 명령어 집합 구조
- 복잡하고 다양한 명령어 활용. 명령어의 형태와 크기가 다양한 가변 길이 명령어를 활용
- 다양하고 강력한 명령어 활용. 상대적으로 적은 수의 명령어로도 프로그램을 실행할 수 있다.
- 메모리를 최대한 아끼며 개발해야 했던 시절에는 인기가 높았으나 명령어 파이프라이닝이 불리하다는 치명적인 단점이 존재
- 명령어가 워낙 복잡하고 다양한 기능을 제공하는 탓에 명령어의 크기와 실행되기까지의 시간이 일정하지 않음
- 명령어 하나를 실행하는 데에 여러 클럭 주기필요
3) RISC (Reduced Instruction Set Computer)
- 명령어의 종류가 적고, 짧고 규격화된 명령어 사용.
- 단순하고 적은 수의 고정 길이 명령어 집합을 활용.
- 따라서 명령어 파이프라이닝에 유리하다.
- 메모리 접근 최소화(load, store), 레지스터 십분 활용
- 다만 명령어 종류가 CISC가 적기에, 더 많은 명령어로 프로그램을 동작시킴
4) 정리
15장. RAM의 특성과 종류
1) RAM의 특징
2) RAM의 용량과 성능
- 용량이 클 수록, 많은 프로그램들을 동시에 실행하는 데에 유리하다.
3) RAM의 종류
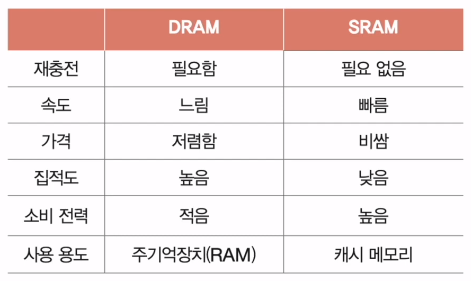
- DRAM (Dynamic RAM)
- 저장된 데이터가 동적으로 사라지는 RAM
- 데이터 소멸을 막기 우해 주기적으로 재활성화 해야함
- 일반적으로 메모리로 사용되는 RAM
- 상대적으로 소비전력이 낮고 저렴하고 집적도가 높아 대용량으로 설계하기 용이
- SRAM (Static RAM)
- 저장된 데이터가 정적인(사라지지 않는) RAM
- DRAM 보다 일반적으로 더 빠름
- 일반적으로 캐시 메모리에서 사용되는 RAM
- 상대적으로 소비전력이 높고 가격이 높고 집적도가 낮아 대용량으로 설계할 필요는 없으나 빨라야 하는 장치에 용이
- DRAM vs SRAM
- SDRAM (Synchronous DRAM)
- 특별한 (발전된 형태의) DRAM
- 클럭 신호와 동기화된 DRAM
- DDR SDRAM (Double Data Rate SDRAM)
- 특별한 (발전된 형태의) SDRAM
- 최근 가장 대중적으로 사용하는 RAM
- 대역폭을 넓혀 속도를 빠르게 만든 SDRAM
- 대역폭: 데이터를 주고 받는 길의 너비
- DDR SDRAM은 대역폭이 2배 넓은 SDRAM
- DDR SDRAM vs SDRAM (SDR(Single Data Rate) SDRAM)
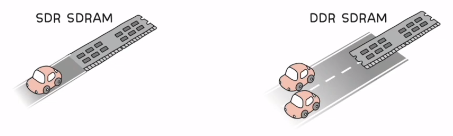
- SDRAM의 종류
- SDR SDRAM (길이 1개)
- DDR SDRAM (SDR의 2배 | 길이 2개)
- DDR2 SDRAM (DDR의 2배 | 길이 4개)
- DDR3 SDRAM (DDR2의 2배 | 길이 8개)
- DDR4 SDRAM (DDR3의 2배 | 길이 16개)
16장. 메모리의 주소 공간 (물리 주소와 논리 주소)
CPU와 실행중인 프로그램은 메모리 몇 번지에 무엇이 저장되어 있는지 알지 못함.
메모리에 저장된 값들은 시시각각 변하기 때문.
- 새롭게 실행되는 프로그램은 새롭게 메모리에 적재
- 실행이 끝난 프로그램은 메모리에서 삭제
- 같은 프로그램을 실행하더라도 실행할 때마다 적재되는 주소는 달라짐
따라서, 물리 주소와 논리 주소라는 개념이 도입.
1) 물리 주소와 논리 주소
- 물리 주소
- 메모리 입장에서 바라본 주소
- 말 그대로 정보가 실제로 저장된 하드웨어상의 주소
- 논리 주소
- CPU와 실행 중인 프로그램 입장에서 바라본 주소
- 실행 중인 프로그램 각각에게 부여된 0번지부터 시작하는 주소
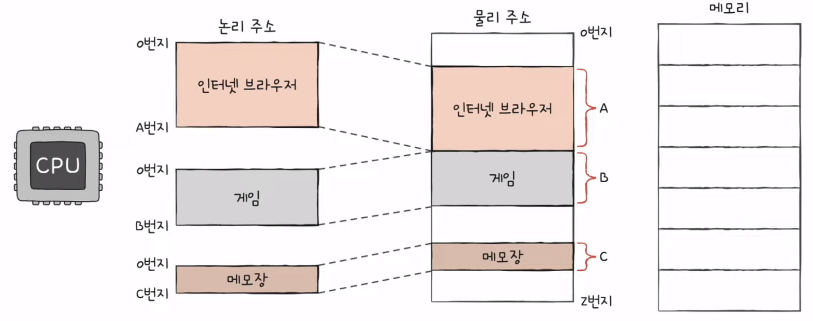
2) 물리 주소와 논리 주소의 변환
- MMU(메모리 관리 장치)라는 하드웨어에 의해 변환
- MMU는 논리 주소와 베이스 레지스터 값을 더하여 논리 주소를 물리 주소로 변환
- 논리 주소: 프로그램의 시작점으로부터 떨어진 거리
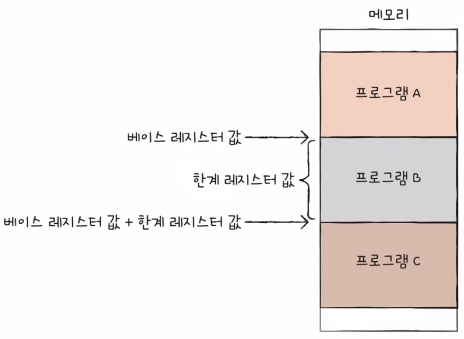
- 베이스 레지스터: 프로그램의 가장 작은 물리 주소(프로그램의 첫 물리 주소)를 저장하는 셈
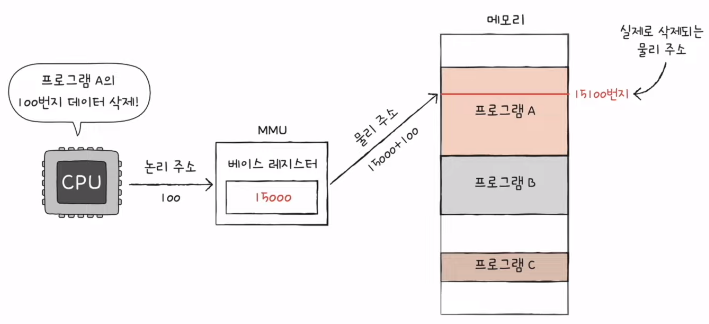
3) 메모리 보호
- 논리 주소의 범위를 벗어가는 명령을 실행하면 안됨.
- 한계 레지스터가 필요
- 프로그램의 영역을 침범할 수 있는 명령어의 실행을 막음.
- 베이스 레지스터가 실행 중인 프로그램의 가장 작은 물리 주소를 저장한다면, 한계 레지스터는 논리 주소의 최대 크기를 저장함.
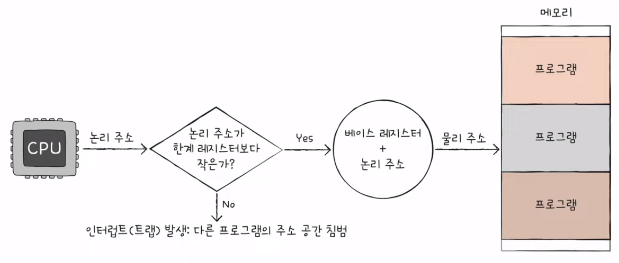
- 이처럼 CPU는 메모리에 접근하기 전, 접근하고자 하는 논리 주소가 한계 레지스터보다 작은지를 항상 검사한다.
- 실행 중인 프로그램의 독립적인 실행 공간을 확보하고, 하나의 프로그램이 다른 프로그램을 침범하지 못하게 보호한다.
17장. 캐시 메모리
1) 자장 장치 계층 구조 (memory hierarchy)
- CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다.
- 속도가 빠른 저장 장치는 저장 용량이 작고, 가격이 비싸다.
- 레지스터 vs 메모리(RAM) vs USB 메모리
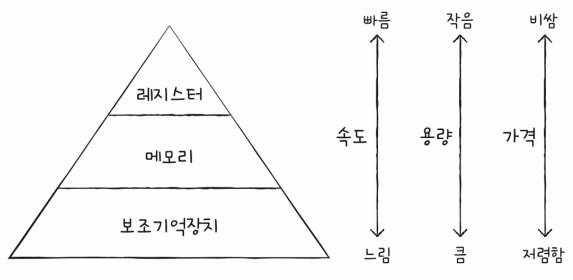
- 레지스터 vs 메모리(RAM) vs USB 메모리
2) 캐시 메모리
- CPU와 메모리 사이에 위치한, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치
- CPU의 연산 속도와 메모리 접근 속도의 차이를 조금이나마 줄이기 위해 탄생
- 메모리가 대형마트라면 캐시메모리는 편의점 같은 존재..
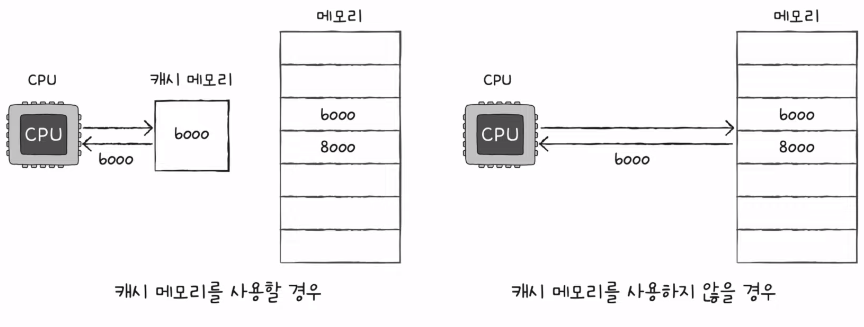
- 캐시 메모리가 반영된 저장 장치 계층 구조
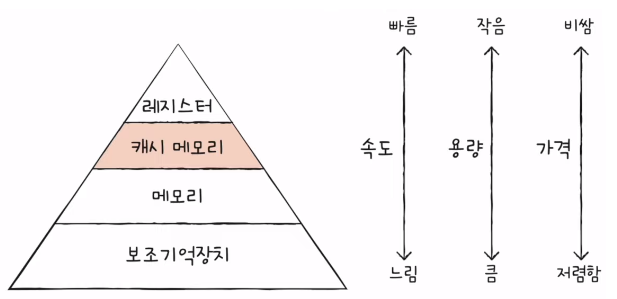
- 계층적 캐시 메모리 (L1-L2-L3 캐시)
- 일반적으로 L1 캐시와 L2 캐시는 코어 내부에, L3 캐시는 코어 외부에 위치해 있다.
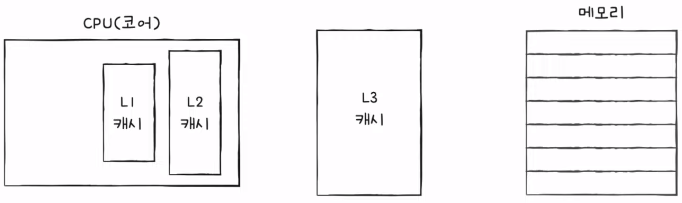
- 멀티코어 프로세서의 캐시 메모리
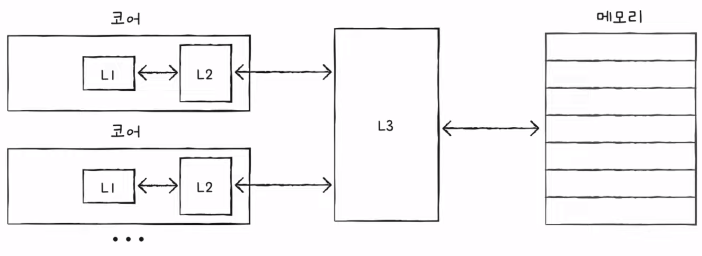
- 분리형 캐시 (D는 데이터, I는 명령어)
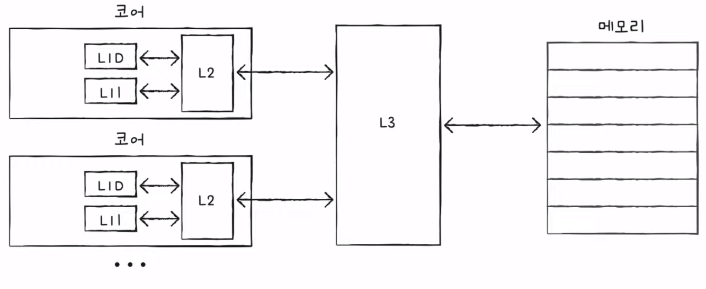
- 계층적 캐시 메모리까지 반영한 저장 장치 계층 구조
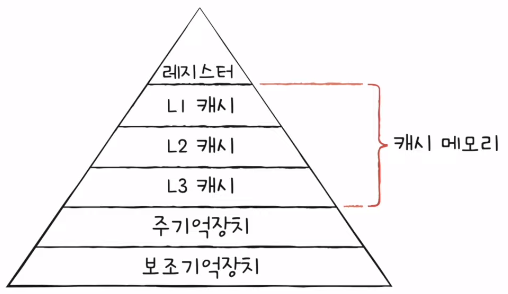
- 일반적으로 L1 캐시와 L2 캐시는 코어 내부에, L3 캐시는 코어 외부에 위치해 있다.
3) 참조 지역성의 원리
- CPU가 자주 사용할 법한 데이터를 예측하는 방법. 캐시 메모리에 저장.
- 캐시 히트: 예측이 들어맞을 경우 (CPU가 캐시 메모리에 저장된 값을 활용한 경우)
- 캐시 미스: 예측이 틀렸을 경우 (CPU가 메모리에 접근해야 하는 경우)
- 캐시 적중률: 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
- 캐시 적중률이 높아야 CPU 성능이 높음
- CPU가 메모리에 접근할 때의 주된 경향을 바탕으로 만들어진 원리
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향 (공간 지역성)
18장. 다양한 보조기억장치(하드 디스크와 플래시 메모리)
1) 하드 디스크의 구성
- 플래터와 스핀들
- 일반적으로 플래터 양면 모두 사용
- RPM: 분당 회전수
- 디스크암과 헤드
- 일반적으로 모든 헤드가 디스크 암에 부착되어 함께 이동
2) 하드 디스크의 저장 단위
- 트랙, 섹터, 실린더
- 트랙: 플래터를 이루고 있는 동심원
- 섹터: 트랙에 속해있는 호
- 실린더: 여러 겹의 플래터 상에서 같은 트랙이 위치한 한 곳을 모아 연결한 논리적 단위
- 연속된 정보는 한 실린더에 기록
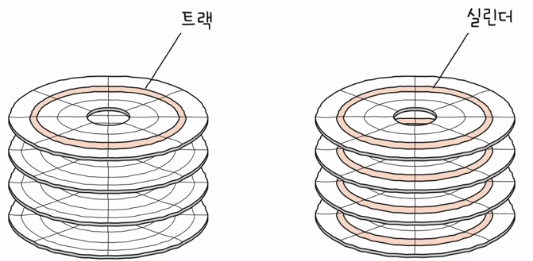
- 연속된 정보는 한 실린더에 기록
3) 하드 디스크의 데이터 접근 과정
- 하드 디스크가 저장된 데이터에 접근하는 시간
- 탐색 시간 (seek time): 접근하려는 데이터가 저장된 트랙까지 헤드를 이동시키는 시간
- 회전 지연 (rotational latency): 헤드가 있는 곳으로 플래터를 회전시키는 시간
- 전송 시간 (transfer time): 하드 디스크와 컴퓨터 간에 데이터를 전송하는 시간
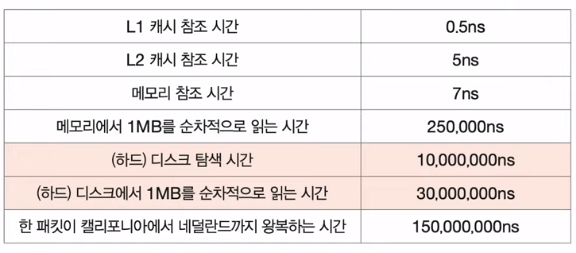
- Jeff Dean - Numbers Every Programmer Should Know
4) 플래시 메모리
- 전기적으로 데이터를 읽고 쓰는 반도체 기반 저장 장치
- 플래시 메모리의 종류
- NAND 플래시 메모리
- NOR 플래시 메모리
- 셀 (cell)
- 플래시 메모리에서 데이터를 저장하는 가장 작은 단위
- 이 셀이 모이고 모여 수 MB, GB, TB 저장 장치가 됨
- SLC, MLC, TLC, QLC
- SLC: 1비트에 저장할 수 있는 플래시 메모리
- MLC: 2비트에 저장할 수 있는 플래시 메모리
- TLC: 3비트에 저장할 수 있는 플래시 메모리
- QLC: 4비트에 저장할 수 있는 플래시 메모리
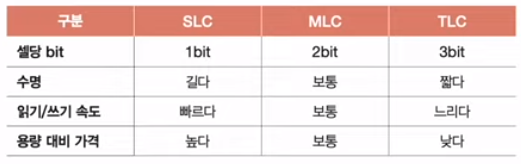
5) SLC, MLC, TLC
- SLC
- 한 셀로 2개의 정보 표현 (0, 1)
- 비트의 빠른 입출력
- 긴 수명
- 용량 대비 고가격
- MLC
- 한 셀에 4개의 정보 표현 (00, 01, 10, 11)
- SLC보다 느린 입출력
- SLC보다 짧은 수명
- SLC보다 저렴
- 시중에서 많이 사용
- TLC
- 한 셀에 8개의 정보 표현 (000, 001, ..., 111)
- SLC보다 느린 입출력
- SLC보다 짧은 수명
- SLC보다 저렴
- 시중에서 많이 사용
6) 플래시 메모리의 저장 단위
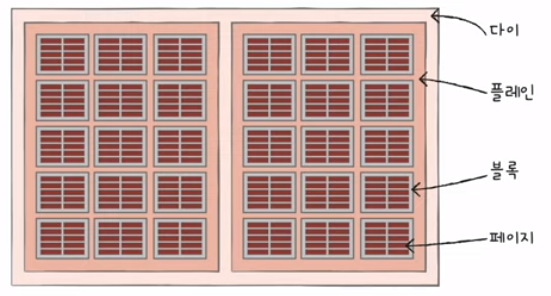
- 셀들이 모여 페이지(page)
- 페이지들이 모여 블록(block)
- 블록이 모여 플레인(plane)
- 플레인이 모여 다이(die)
읽기/쓰기 단위와 삭제 단위는 다르다
- 읽기와 쓰기는 페이지 단위로 이루어짐
- 삭제는 페이지보다 큰 블록 단위로 이루어짐
페이지의 상태
- Free 상태: 어떠한 데이터도 저장하고 있지 않아 새로운 데이터를 저장할 수 있는 상태
- Valid 상태: 이미 유효한 데이터를 저장하고 있는 상태
- Invalid 상태: 유요하지 않은 데이터(쓰레기값)를 저장하고 있는 상태
- 플래시 메모리는 하드 디스크와 달리 덮어쓰기가 불가
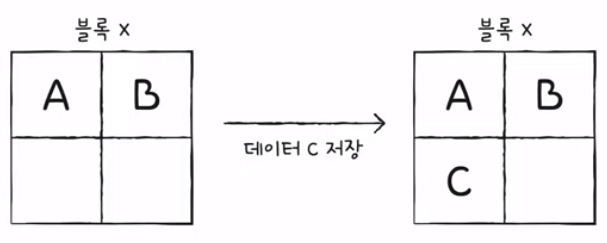
7) 플래시 메모리의 동작 예시
- 데이터 C 저장
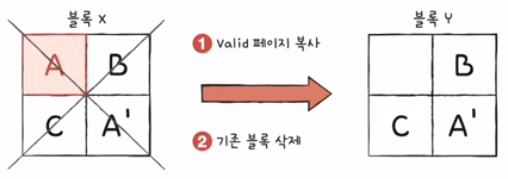
- B와 C를 그대로 둔 채, 기존의 A만을 A'로 수정
- A를 Invalid 상태로 바꾸고 빈 공간에 A'을 넣는다.
- 이런식으로 Invalid 상태가 많아지면 용량 낭비가 심해진다.
- 따라서 가비지 컬렉션이라는 개념이 도입.
- 가비지 컬렉션
- 유효한 페이지들을 새로운 블록으로 복사
- 기존의 블록을 삭제
19장. RAID의 정의와 종류
1) RAID의 정의
RAID (Redundant Array of Independent Disks)
- 하드 디스크와 SSD로 사용하는 기술
- 데이터의 안정성 혹은 높은 성능을 위해 여러 물리적 보조기억장치를 마치 하나의 논리적 보조기억장치처럼 사용하는 기술
RAID 레벨
- RAID를 구성하는 기술
- RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6
- 그로부터 파생된 RAID 10, RAID 50, ...
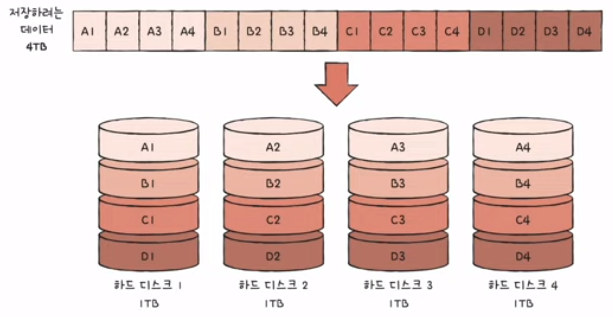
2) RAID 0
- 데이터를 단순히 나누어 저장하는 구성 방식
- 각 하드 디스크는 번갈아 가며 데이터를 저장한다.
- 저장되는 데이터가 하드 디스크 개수만큼 나뉘어 저장
- 스트라입(stripe): 마치 줄무늬처럼 분산되어 저장된 데이터
- 스트라이핑(striping): 분산하여 저장하는 것
- 장점: 입출력 속도의 향상
- 단점: 저장된 정보가 안전하지 않음
3) RAID 1
- 미러링(mirroring): 복사본을 만드는 방식
- 데이터를 쓸 때 원본과 복사본 두 군데에 씀 (느린 쓰기 속도)
- 장점: 백업과 복구가 굉장히 좋다
- 단점: 하드 디스크 개수가 한저오디었을 때 사용 가능한 용량이 적어짐
- 복사본이 만들어지는 용량만큼 사용 불가 -> 많은 양의 하드 디스크가 필요 -> 비용 증가
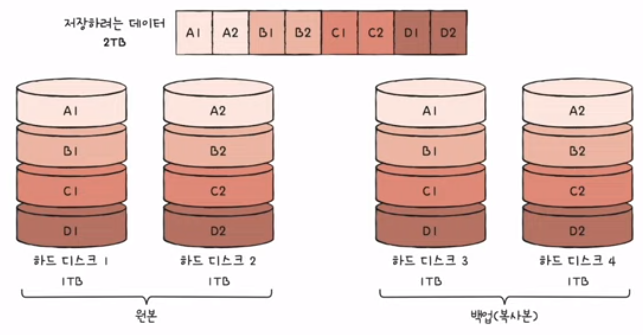
- 복사본이 만들어지는 용량만큼 사용 불가 -> 많은 양의 하드 디스크가 필요 -> 비용 증가
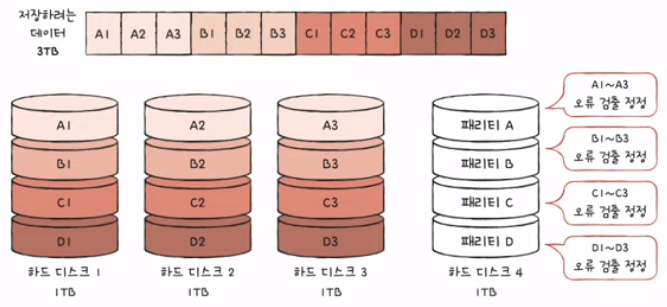
4) RAID 4
- RAID 1처럼 완전한 복사본을 만드는 대신 패리티 비트를 저장
- 패리티 비트: 오류를 검출하고 복구하기 위한 정보
- 패리티를 저장한 장치를 이용해 다른 장치들의 오류를 검출하고, 오류가 있다면 복구
- 패리티 비트는 오류 검출만 가능할 뿐 오류 복구는 불가능
- 하지만, RAID에서 사용되는 패리티 비트는 복구까지 가능
- 단점: 패리티 디스크의 병목현상
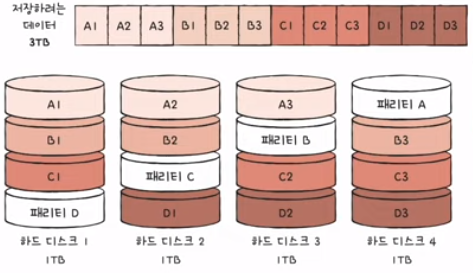
5) RAID 5
- 패리티 정보를 분산하여 저장하는 방식
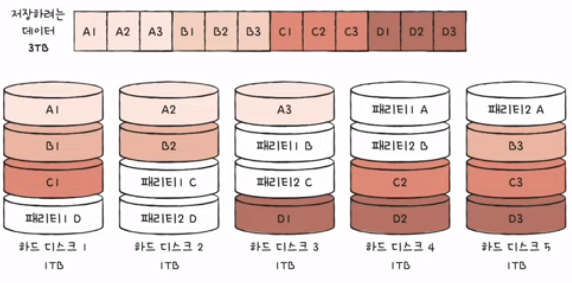
6) RAID 6
- 두 종류의 패리티(오류를 검출하고 복구할 수 있는 수단)
- RAID 5보다 안전, 쓰기는 RAID 5보다 느림
7) RAID 정리
- 각 RAID 레벨마다 장단점이 있음
- 어떤 상황에서 무엇을 최우선으로 원하는지에 따라 최적의 RAID 레벨은 달라질 수 있음
- 각 RAID 레벨의 대략적인 구성과 특징을 아는 것이 중요
- ASUS 홈페이지, BIOS 설정에서 RAID를 만드는 방법
20장. 장치 컨트롤러와 장치 드라이버
1) CPU - 입출력장치 정보 주고 받기
- 입출력 장치의 종류는 너무나도 많다.
- 장치가 다양하면 장치마다 속도, 데이터 전송 형식 등도 다양하다.
- 다양한 입출력장치와 정보를 주고 받는 방식을 규격화하기 어렵다.
- 일반적으로 CPU와 메모리의 데이터 전송률은 높지만, 입출력 장치의 데이터 전송률은 낮다.
- 위와 같은 이유로 입출력장치는 장치 컨트롤러를 통해 컴퓨터와 연결된다.
2) 장치 컨트롤러의 역할
- CPU와 입출력장치 간의 통신중개 (일종의 번역가 역할)
- 오류 검출
- 데이터 버퍼링
- 버퍼링: 전송률이 높은 장치와 낮은 장치 사이에 주고받는 데이터를 버퍼라는 임시 저장 공간에 저장하여 전송률을 비슷하게 맞추는 방법
3) 장치 컨트롤러의 구조
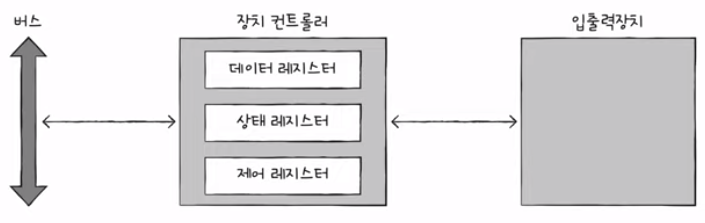
- 데이터 레지스터
- CPU와 입출력장치 사이에 주고받을 데이터가 담기는 레지스터 (버퍼)
- RAM을 사용하기도
- 상태 레지스터
- 상태 정보 버장: 입출력장치가 입출력 작업을 할 준비가 되었는지, 입출력 작업이 완료되었는지, 입출력장치에 오류는 없는지 등의 상태 정보
- 제어 레지스터
- 입출력장치가 수행할 내용에 대한 제어 정보
4) 장치 드라이버
- 장치 컨트롤러의 동작을 감지하고 제어하는 프로그램
- 장치 컨트롤러가 입출력장치를 연결하기 위한 하드웨어적인 통로라면, 장치 드라이버는 입출력장치를 연결하기 위한 소프트웨어적인 통로
- 컴퓨터(운영체제)가 연결된 장치의 드라이버를 인식하고 실행할 수 있다면, 컴퓨터 내부와 정보를 주고받을 수 있음
- 반대로 컴퓨터(운영체제)가 장치 드라이버를 인식하거나 실행할 수 없다면, 그 장치는 컴퓨터 내부와 정보를 주고받을 수 없음
21장. 다양한 입출력 방법
1) 프로그램 입출력
메모리에 저장된 정보를 하드 디스크에 백업
- CPU는 하드 디스크 컨트롤러의 제어 레지스터에 쓰기 명령 내보내기
- 하드 디스크 컨트롤러는 하드 디스크 상태 확인 -> 상태 레지스터에 준비 완료 표시
- CPU는 상태 레지스터를 주기적으로 읽어보며 하드 디스크의 준비 여부를 확인
- 하드 디스크가 준비되었다면 백업할 메모리의 정보를 데이터 레지스터에 쓰기
- 아직 백업 작업(쓰기 작업)이 끝나지 않았다면 1번부터 반복, 쓰기가 끝났다면 작업 종료
프로그램 입출력 방식
- CPU가 장치 컨트롤러의 레지스터 값을 읽고 씀으로써 이루어진다
- 프로그램 입출력 방식: 메모리 맵 입출력 & 고립형 입출력
2) 메모리 맵 입출력 & 고립형 입출력
메모리 맵 입출력
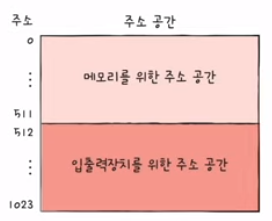
- 메모리에 접근하기 위한 주소 공간과 입출력장치에 접근하기 위한 주소 공간을 하나의 주소 공간으로 간주하는 방법
고립형 입출력
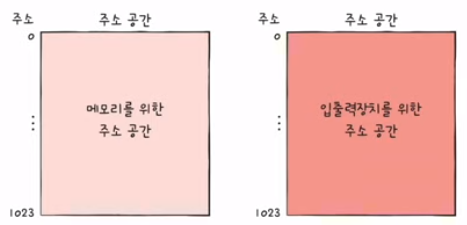
- 메모리를 위한 주소 공간과 입출력 장치를 위한 주소 공간을 분리하는 방법
- (입출력 읽기/쓰기 선을 활성화시키는) 입출력 전용 명령어 사용
정리

3) 인터럽트 기반 입출력
-
동시다발적인 인터럽트: 우선순위를 반영한 인터럽트
-
NMI가 발생한 경우: 플래그 레지스터 속 인터럽트 비트를 활성화한 채 인터럽트를 처리하는 경우
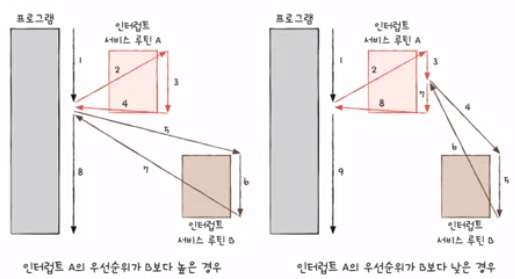
-
PIC (Programmable Interrupt Controller)
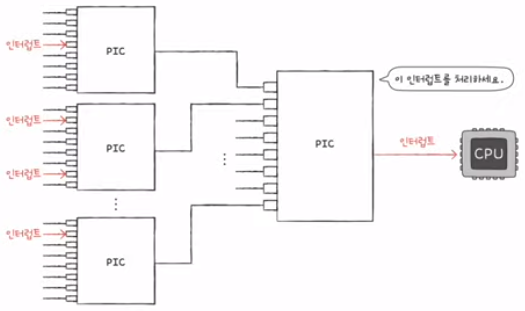
- 여러 장치 컨트롤러에 연결됨
- 장치 컨트롤러의 하드웨어 인터럽트의 우선순위를 판단함
- CPU에게 지금 처리해야 하는 인터럽트가 무엇인지 판단하는 하드웨어
4) DAM
- DMA가 없다면...
- 입출장치의 데이터를 메모리에 저장하는 경우
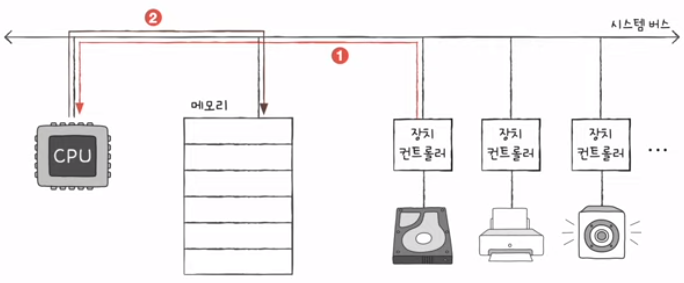
- 메모리의 데이터를 입출력에 저장하는 경우
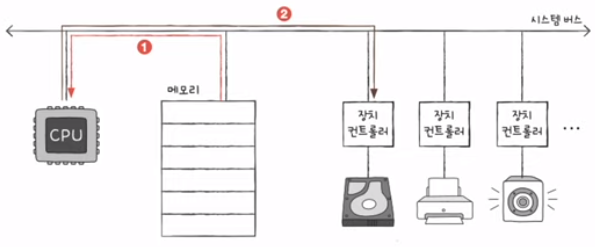
- 즉, 입출력장치와 메모리 간의 데이터 이동은 CPU가 주도하고 이동하는 데이터도 반드시 CPU를 거친다.
- 입출장치의 데이터를 메모리에 저장하는 경우
- DMA (Direct Memory Access)
- CPU를 거치지 않고 입출력장치가 메모리에 직접적으로 접근하는 기능
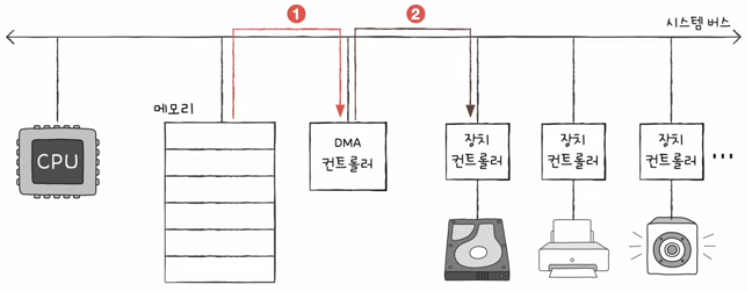
5) DMA 입출력 과정
- CPU는 DMA 컨트롤러에 압출력 작업을 명령
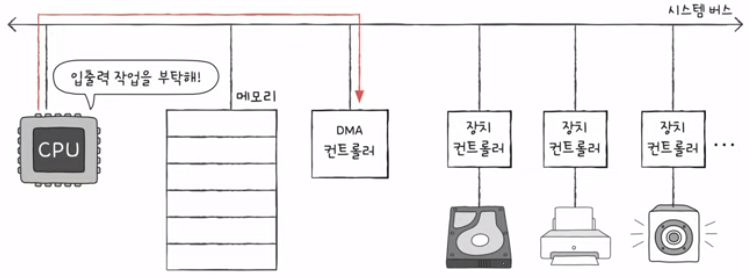
- DMA 컨트롤러는 CPU 대신 장치 컨트롤러와 상호작용하며 입출력 작업을 수행
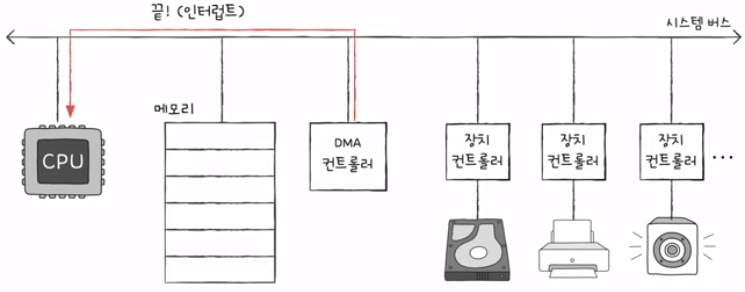
- 입출력 작업이 끝나면 DMA 컨트롤러는 인터럽트를 통해 CPU에 작업이 끝났음을 알림
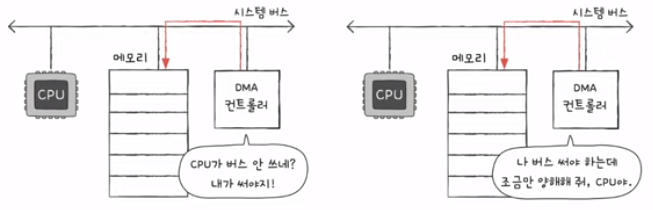
- 하지만, 시스템 버스의 수량은 한정적이다. 따라서 DMA 컨트롤러는 Cycle stealing을 이용한다.
- CPU가 시스템 버스를 이용하지 않을 때마다 조금씩 시스템 버스 이용
- CPU가 일시적으로 시스템 버스를 이용하지 않도록 허락을 구하고 시스템 버스 이용
6) 입출력 버스
- 시스템 버스를 (불필요하게) 두 번 이용하는 DMA 컨트롤러
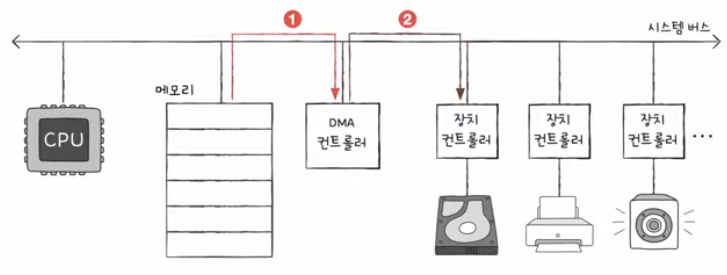
- 이런 문제를 해결하기 위해, 입출력 버스를 통해 시스템 버스의 이용 빈도를 낮춘다
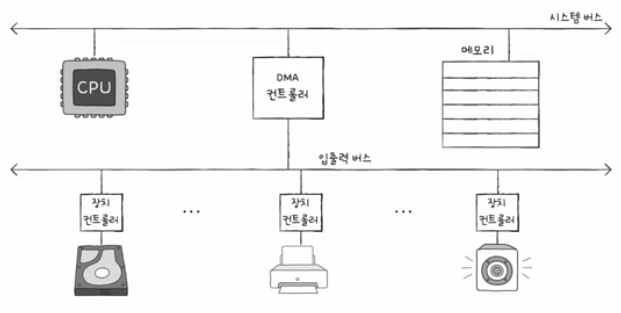
- PCI 버스 (PCI express (PCIe) 버스와 입출력 장치를 연결짓는 슬롯)
- 입출력 버스의 한 종류

Studying NodeJS...