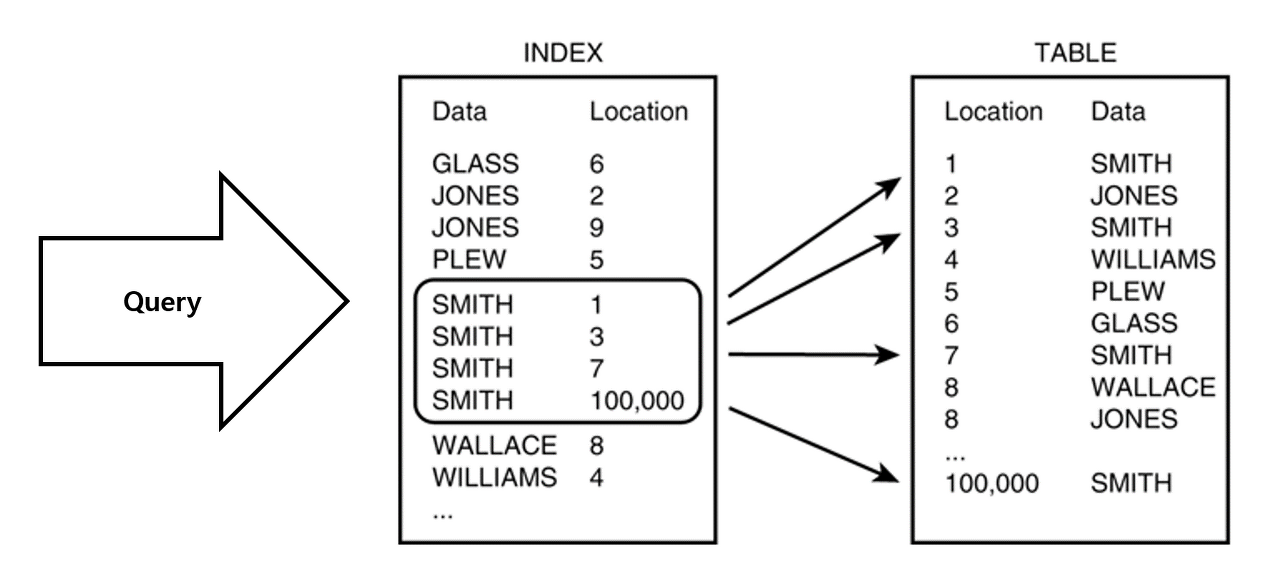
인덱스(Index)
인덱스는 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료구조이다. 인덱스는 데이터베이스에서 데이터를 찾는 데 사용되며, '색인' 이라고도 한다. 인덱스는 주로 WHERE 조건절에 사용되는 컬럼에 생성된다.
즉 인덱스는 책에 있는 목차라고 생각하면 편하다. 우리가 책에서 정보를 찾을때도 먼저 원하는 카테고리를 목차에서 찾고 목차에 있는 페이지 번호를 보고 찾아가듯 인덱스도 인덱스에서 내가 원하는 데이터를 먼저 찾고 저장되어 있는 물리적 주소로 찾아간다.
실제 DB관련 작업을 할 때 대부분의 속도 저하는 바로 SELECT문, 특히 조건 검색 WHERE절에서 발생하는데 가장 먼저 생각해볼 수 있는 대안 중 하나가 바로 인덱스이다. SQL튜닝에서도 인덱스와 관련된 문제사항과 해결책이 많기 때문이다.
쿼리 성능 개선을 위한 인덱스 활용
1. 함수나 연산자를 사용하는 경우
SELECT * FROM table_name WHERE UPPER(name) = 'AHN'; -- 인덱스 활용X
SELECT * FROM table_name WHERE YEAR(date_column) = 2023; -- 인덱스 활용X
SELECT * FROM table_name WHERE column_name + 1 = 100; -- 인덱스 활용X
위와 같이 인덱스가 있는 열에 함수 또는 연산을 수행하는 경우 데이터베이스는 인덱스를 사용하지 못한다. 이는 인덱스의 동작 방식과 함수나 연산자의 동작 방식이 다르기 때문이다.
인덱스는 키의 순서대로 정렬되어 저장되며, 검색 시에는 B-트리 구조를 사용하여 매우 빠르게 검색한다. 하지만 함수나 연산자를 사용하면 검색 대상 데이터에 대한 변환을 수행하므로, 인덱스의 순서와 일치하지 않을 수 있다. 따라서 모든 레코드를 스캔하여 조건을 검사하기에 쿼리의 속도가 느려지게된다.
2. LIKE문 검색에서 와일드카드의 위치
SELECT * FROM table_name WHERE name LIKE 'A%'; -- 인덱스 활용O
SELECT * FROM table_name WHERE name LIKE '%A'; -- 인덱스 활용X
SELECT * FROM table_name WHERE name LIKE '%A%'; -- 인덱스 활용X
위와 같이 LIKE절에서 %가 뒤에 있는 경우, 인덱스를 활용할 수 있지만 %가 앞이나 중간에 있을 경우는 인덱스를 활용할 수 없다.
이유는 앞서 정리한 내용과 마찬가지로, 인덱스의 B-트리 구조와 LIKE절의 검색 패턴이 일치하기 때문이다. 일반적으로 인덱스는 B-트리 구조를 사용하여 정렬된 키를 저장한다. 따라서 %가 뒤에 있을 경우는 문자열 정렬 순서를 그대로 이용할 수 있어서 인덱스를 타지만, 반대의 경우는 정렬 순서를 활용하지 못해 인덱스를 타지 않는다.
3. OR절을 사용하는 경우
SELECT * FROM table_name WHERE name = 'Ahn' OR age = 26; -- 인덱스 활용X
OR절을 사용하면 인덱스를 활용할 수 없는데, 이는 OR절이 두 개 이상의 필드를 동시에 비교하기 때문이다. 위 쿼리의 경우 이름이 Ahn 이거나 나이가 26인 레코드를 찾기 위해 데이터베이스가 인덱스를 사용하는 대신 모든 레코드를 스캔한다.
더 자세히는 OR 절은 여러 개의 조건 중 하나라도 참이면 전체 조건을 참으로 판단한다. 따라서 OR 절이 사용된 쿼리는 데이터베이스가 조건의 모든 가능성을 검사하고 그 결과를 결합해야 한다. 따라서 데이터베이스가 최적의 OR 조건을 뽑기 힘들어 인덱스를 사용할 수 없다. 따라서 상황에 따라서는 OR 절 대신에 UNION ALL 등의 방법을 사용하여 여러 개의 쿼리를 실행하고 결과를 조합하는 것이 더 효율적일 수 있다.
4. NULL 값을 비교하는 경우
SELECT * FROM table_name WHERE name = NULL; -- 인덱스 활용X
SELECT * FROM table_name WHERE age IS NULL; -- 인덱스 활용X
SELECT * FROM table_name WHERE age > 0; -- 인덱스 활용O
NULL 값을 비교하면 데이터베이스는 인덱스를 활용할 수 없다. 이는 NULL 값은 인덱스에 저장되지 않기 때문이다.
5. 테이블 전체를 반환하는 경우
SELECT * FROM table_name;
당연하게도 테이블의 전체 레코드를 반환하는 경우에는 인덱스를 활용할 수 없다. 이는 데이터베이스가 모든 레코드를 반환해야 하므로 인덱스를 사용할 필요가 없기 때문이다.
6. 컬럼의 자료형이 다른 검색을 하는 경우
SELECT *
FROM table1
JOIN table2
ON table1.id = table2.age;
위와 같이 컬럼의 자료형이 다른 것들을 비교하는 쿼리를 실행한다면, 인덱스의 성능이 저하될 가능성이 있다. 이는 인덱스를 사용할 경우, 인덱스 스캔을 수행하기 전에 모든 값들에 대해 자동으로 자료형 변환이 수행되기 때문이다.
자료형 변환이 인덱스의 성능을 저하시키는 이유는 인덱스는 데이터의 값을 기반으로 정렬되어 있기 때문이다. 만약 자료형이 다른 두 컬럼을 비교하려면 두 컬럼의 값을 비교하기 전에 자료형 변환이 수행되어야 하므로, 인덱스의 정렬 순서가 변경될 가능성이 발생하게 되어 인덱스를 효율적으로 사용할 수 없다.
7. IN 연산자를 사용한 검색에서 IN 목록의 개수가 많은 경우
SELECT *
FROM table_name
WHERE id IN (1, 2, 3, ..., 1000);
IN 연산자를 사용한 검색에서 IN 목록의 개수가 위와 같이 많을 경우, 인덱스를 사용하지 않고 수행할 가능성이 높다.
이는 N개의 인덱스 스캔을 수행하는 것이 Full Scan을 사용하는 것보다 더 많은 비용이 들어가기 때문입니다. 이를 개선하기 위해서는 IN 연산자 대신 아래와 같이 JOIN을 사용하여 인덱스를 효율적으로 사용할 수 있습니다.
-- 개선된 쿼리
SELECT *
FROM table_name
JOIN (
SELECT 1 AS id UNION ALL
SELECT 2 AS id UNION ALL
SELECT 3 AS id UNION ALL
...
SELECT 1000 AS id
) AS ids
ON table_name.id = ids.id;
위의 쿼리는 IN 목록 대신 UNION ALL을 사용하여 1000개의 값을 직접 생성하고 있습니다. 이 경우 조인을 수행할 때 인덱스를 사용할 수 있으므로, 성능이 향상될 수 있습니다.
