Week 1: Overview of the ML Lifecycle and Deployment
Specialization overview
MLOps(Machine Learning Operations)
- 의미: machine learning engineering production
- 좋은 모델을 개발한 후에 실제로 모델을 production에 적용하는 기술
- production machine learning system 구축 및 배포하는 데에 필요한 기술
- machine learning model이 아무리 훌령해도 production에 적용하지 못하면 최대 가치 창출이 어려움
- 학습 내용
- machine learning project 전체 수명 주기에 대한 개요(data 가져오기 -> 모델링, 배포)
- 시간에 따른 데이터 변화(dataset 수집, 정리 및 검증 과정)
production machine learning 모델링 파이프라인(높은 정확도를 갖는 추론, 비용 최소화를 위한 modeling resource 관리법) - 분석(모델 공정성(model fairness), 설명 가능성(explainability issues) 문제 해결 및 병목 현상 완화)
- 배포
- MLOps를 통해 얻어가야 하는 것: machine learning 모델 구축과 함께 production에 적용하기 위한 ML project의 전체 수명 주기에 대해 이해하기!
Welcome
ex) 컴퓨터비전 기반 스마트폰 제조 라인에서 나오는 스마트폰을 검사하여 결함 유무 예측 프로그램
-
edge device: 스마트폰 제조 공장 내부에 있는 디바이스
-
자동화된 시각적 결함 검사 소프트웨어
- 검사 소프트웨어에서 스마트폰이 제조 라인에서 나올 때 사진 찍는 카메라 제어
- 검사 소프트웨어에서 촬영한 사진 예측 서버에 전달하기 위한 API 호출
- 예측 서버에서 API 호출 수락 및 이미지 수신
- 예측 서버에서 스마트폰 결함 여부 결정
- 예측 서버에서 예측 반환
- 검사 소프트웨어 제조 라인에서 진행 여부 결정(폐기할지, 생산할지)
-
개발자의 역할
- machine learning model을 production 서버에 넣기
- API 인터페이스 설정
- 나머지 소프트웨어 작성
-
예측 서버 위치: 클라우드 or edge device에 위치 -> 실제로 edge device에 배포를 많이 함
-
가치 있는 production 배포를 위한 과제는 끝이 없다
- 스마트폰 결함 검사를 위해 사진을 촬영했을 시 실제 제조 공장의 이미지 품질이 저하되는 경우가 많음 -> 이상적인 test dataset을 생각했지만 실제 개발자가 생각하지 못한 test data가 있는 것을 data drift 라고 함
-
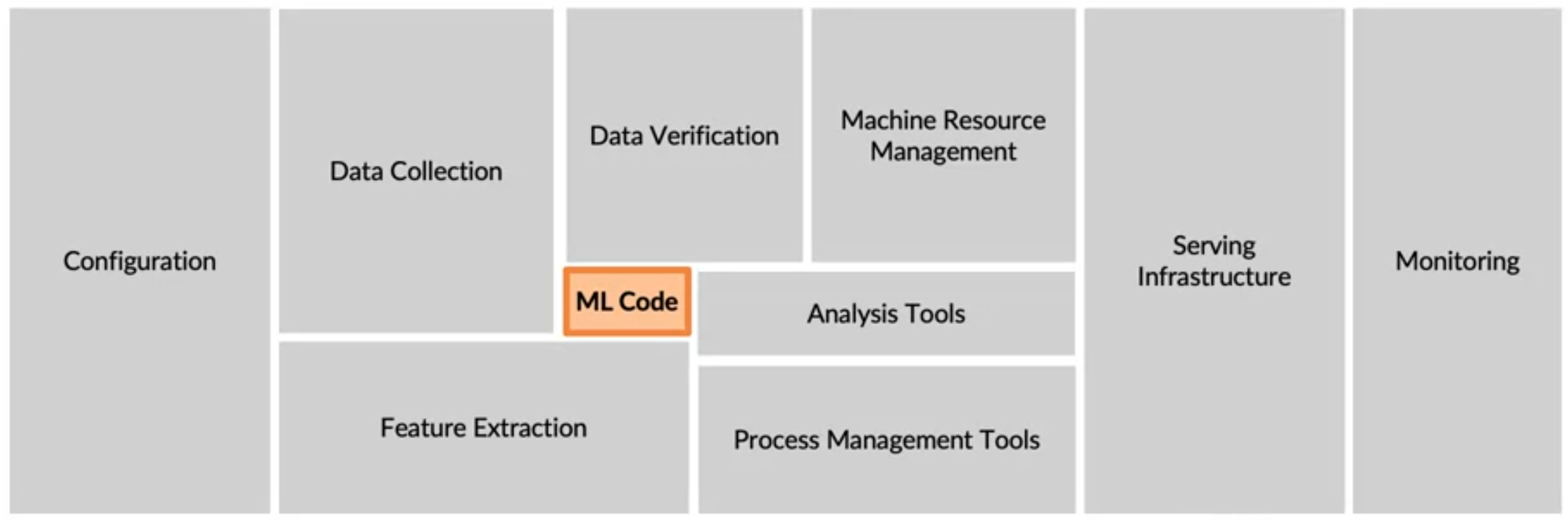
ML production code는 아래 이미지와 같이 ML code는 극히 일부분이고 배포하는데에 더 많은 코드를 작성
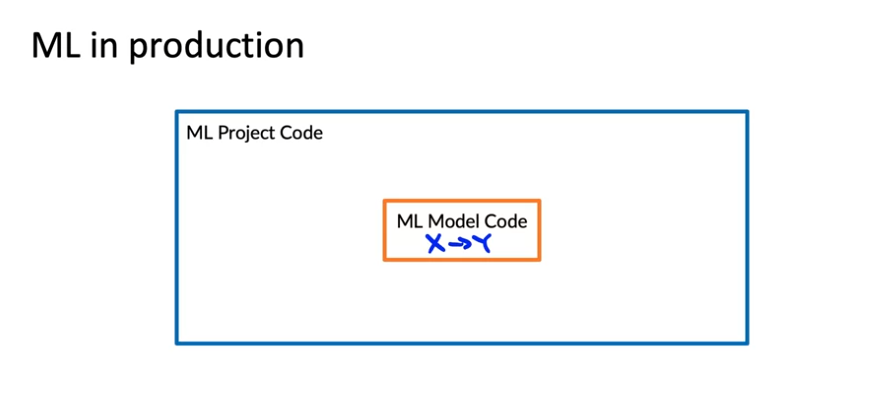
--> 초기 POC(Proof of concept: 개념 증명은 기존 시장에 없었던 신기술을 도입하기 전에 이를 검증하기 위해 사용하는 것)부터 ML 모델 학습부터 배포까지 많은 작업이 필요함을 알 수 있음 -
실제 ML 프로젝트에서는 ML code 외에도 데이터, 수집, 데이터 검증, feature 추출과 같은 데이터 관리를 위한 구성 요소와 더불어 프로덕션 배포를 가능하게 하기 위해 빌드해야 하는 다른 많은 구성 요소가 필요할 때가 많음.
Steps of an ML Project
- ML project 수명 주기
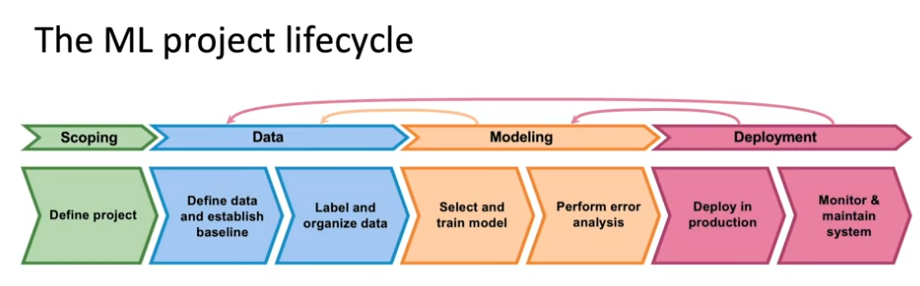
- 프로젝트 정의 및 작업할 대상을 결정하는 범위 지정(feature x와 predict y가 무엇인지 정의)
- 모델 단계: 모델을 선택하여 학습 및 오류 분석 수행 --> 모델 업데이트 --> 이전 단계로 돌아가 더 많은 데이터 수집 --> 최종 검사
- 배포 단계: production에 배포하고 넣는 데 필요한 SW 작성 --> 시스템 모니터링 --> 입력되는 데이터 추적 및 시스템 유지 관리(예: 데이터 분포의 변경으로 인한 모델 업데이트 필요, 초기 배포 후 유지 관리는 더 많은 오류 분석을 수행하고 모델을 재교육 또는 새로 수집한 데이터를 가져오는 것을 의미)
- 배포 후: LIVE DATA에서 실행 중이므로 업데이트된 모델을 배포할 때까지 잠재적으로 데이터 업데이트, 모델 재교육하여 작업을 다시 제공
- scoping: 범위 지정
- Define project: 프로젝트 정의
- Data
- Define data and establish baseline: data 정의 및 baseline 수립
- Label and organize data: data labeling 및 정리
- Modeling
- Select and train model: 훈련 모델 선택
- Perform error analysis: 오류 분석 수행
- Deployment
- Deploy in production: production 배포
- Monitor & maintain system: 모니터링 및 유지 관리 시스템
Case study: speech recognition
음성 인식 예제를 통해 ML 프로젝트 수명 주기 공부하기
- scoping 단계: 프로젝트 정의 & 음성 인식 작업에 대한 결정
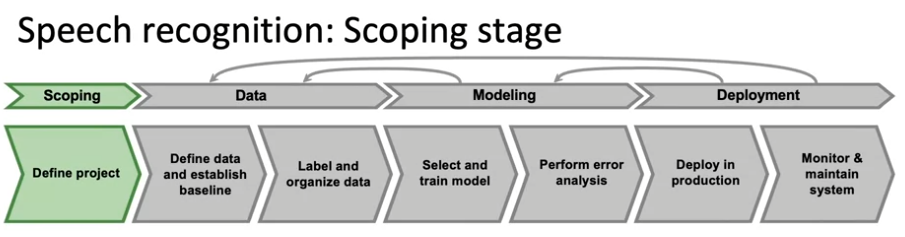
- 프로젝트 정의(프로젝트의 고유한 목표 설정): 음성 시스템 대기 시간, 처리량, 초당 처리하는 쿼리 수, 필요한 resource 추정 --> 예산과 일정 계산
- Decide to work on speeh recognition for voice search.
- Decide on key metrics:
- Accuracy, latency, throughput - Estimate resources and timeline
- data 단계: data 정의 및 기준선 설정, data labeling 및 구성
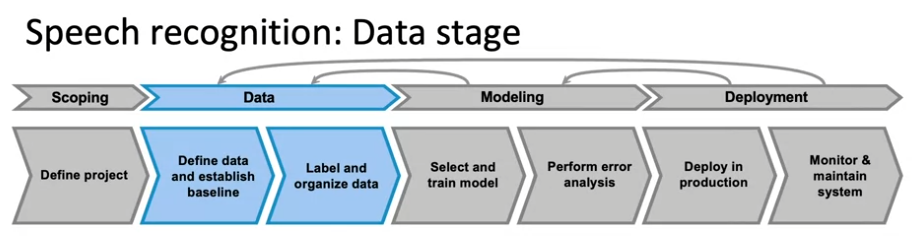
- Define data
- Is the data labeled consistently?(데이터 labeling이 일관성이 있는가?)
--> "음,, 헬로우" 라는 음성을 듣고 "Um, hello." or "Um... hello." 이렇게 일관되지 않는 레이블링을 할 수 있음. - How much silence before/after each clip?
- audio clip 볼륨, 시작 지점, 끝 지점 정의하는 구간 - 고품질 데잍를 확보하기 위한 체계적인 프레임워크를 효과적으로 수행하는 실용적인 방법(뒷 부분)
- Modeling: 모델 선택, 훈련, 오류 분석
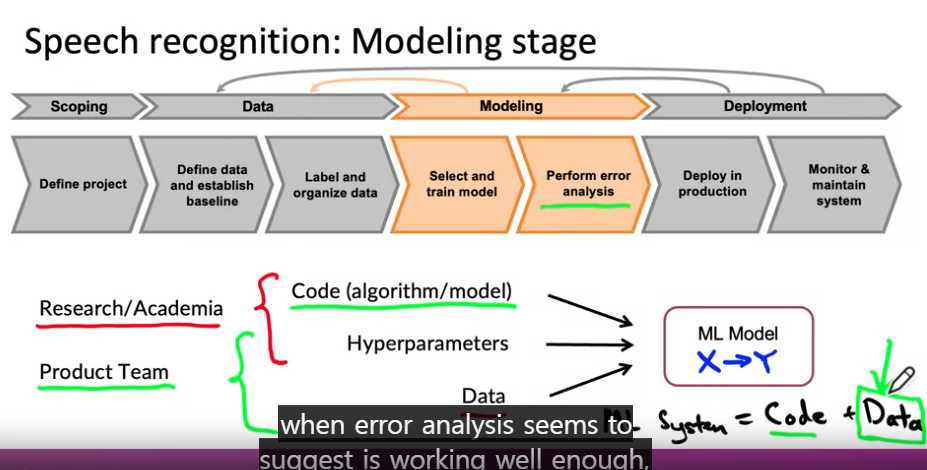
- Research/Academi
- data 고정!- Code 수정 & 성능 향상을 위한 하이퍼파라미터 수정
- Product Team
- code 고정!- data(data 최적화에 집중) & 하이퍼파라미터 수정
- 오류 분석
- Deployment
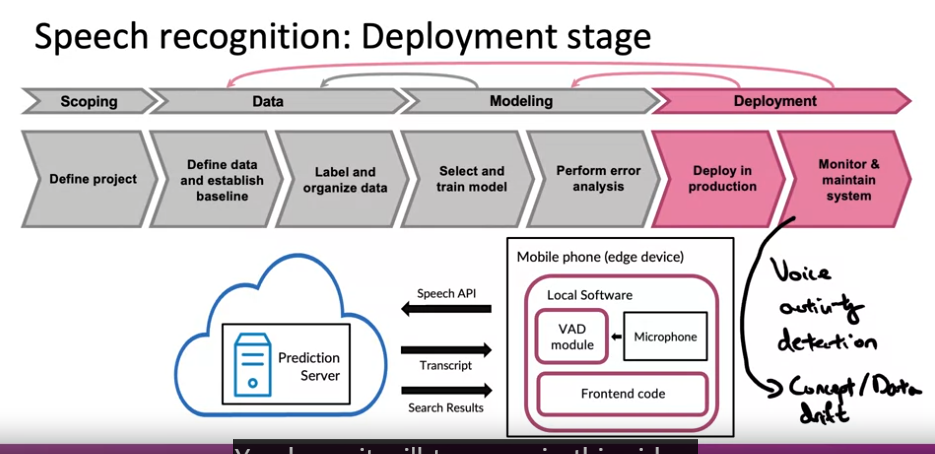
- VAD: Voice Activity Detection
- 일반적인 배포 패턴: 학습 알고리즘 + VAD 작업 --> 스마트폰에서 말하는 사람이 포함된 오디오만 선택 --> 오디오 클립 예측 서버에 전송 --> 두 스크립트를 반환하여 사용자가 시스템에서 말한 내용 출력 --> 검색 결과 출력
- 시간이 지남에 따라 아이들의 목소리를 음성 인식하지 못하는 문젲 발생 --> 음성 인식 성능 저하 --> 데이터 보완 필요 : 이 문제가 바로 "concept/data drift"
Course outline
MLOps(Machine Learning Operations) is an emerging disciplinem and comprises a set of tools and principles to support progress through the ML project life cycle
Key challenges
배포가 어려운 이유
1. ML 통계적 문제
- concept/data drift: 입력 분포 x가 변경되는 경우
- 시스템이 이미 배포된 후 데이터의 변경으로 인해 발생하는 문제- 이미지 촬영 후 인식하는 공장에서 공장 조명의 변화로 입력되는 사진이 변하면 인식에 어려움이 생길 수 있음
- 음성 인식 시스템은 언어 변경과 같은 데이터 변경, 마이크의 변경으로 인해 음성이 변화되어 음성 인식 시스템 성능이 저하될 수 있음
- 새로운 환경으로 인해 시스템이 충격을 받았을 경우 --> 코로나로 인해 구매 패턴이 바뀌면서 신용카드 사기 시스템이 작동하지 않음
- concep drift와 data drift 차이점: concep drift는 x가 주택 크기, y가 주택 가격이라고 가정했을 때 시간이 지나면서 주택이 더 비싸질 수 있음. 즉, x는 변하지 않았으나 y는 변할 수 있음. 반면 data drift는 사람들이 더 큰 집을 짓거나, 더 작은 집을 지으면서 x의 분포가 시간이 지남에 따라 변하는 경우를 말함.
2. SW 엔진 문제
- Realtime or Batch(실시간 예측이 필요한가? 배치 예측이 필요한가?)
- 음성 인식: 0.5초 안으로 실시간 예측 필요- 병원: 하룻밤 한 번씩 환자 기록을 일괄적으로 실행
- Cloud vs. Edge/Browser(클라우드로 실행하는가? edge or web-browser에서도 실행하는가?)
- 자동차, 공장: 인터넷 연결이 끊겨도 계속 수행해야 하므로 edge에서 실행 - Computer resources(CPU/GPU/memory)(컴퓨터 resource 양 고려)
- 사용자는 연구자들의 GPU를 감당할 수 없으므로 개발자는 모델을 압축시켜서 배포해야 함 --> 메모리 리소스 양 파악 필수 - Latency, throughput(QPS)
- 실시간 애플리케이션의 경우 초당 쿼리수와 같은 대기 시간 및 처리량 측정 - Logging
- 시스템을 구축할 때 분석 및 검토를 위해 가능한 많은 데이터를 로깅하고 향후 학습 알고리즘을 재교육하기 위해 더 많은 데이터 제공하는 것이 더 유용할 수 있음 - 보안 및 개인정보 보호, 보안 미 개인정보보호 요구 수준
- 환자 정보: 민감한 정보 --> 요구 수준 높음- 민감도에 따라 규정 요구사항을 기반으로 적절한 수준의 보안 및 개인 정보 보호 설계
Deployment patterns
배포 패턴
1. 이전에 제공하지 않은 새로운 제품이나 기능을 제공하는 경우
2. 사람이 이미 수행하고 있는 작업이 있지만 학습 알고리즘을 사용하여 해당 작업을 자동화/지원하려는 경우
3. 이전에 ML system을 구현하여 이미 작업을 수행하고 있지만 더 나은 시스템으로 교체하려는 경우
핵심 아이디어
- 모니터링을 통해 점진적인 증가를 하는 경우가 많음
- 롤백: 어떤 이유로 알고리즘이 작동하지 않는 경우 이전 시스템으로 되돌리는 방법
shadow deployment pattern
- 방법: 사람이 육안으로 검사 + ML 알고리즘 작업 수행 --> 판단은 인간만 내리고 ML은 예측만
- 장점
- 인간의 판단과 비교하는 방법을 사용하여 데이터를 수집- 학습 알고리즘 예측이 정확한지 확인 --> 학습 알고리즘의 판단을 실제로 사용할 것인지 판단 가능
- 실제 결정을 내리기 전에 학습 알고리즘의 성능을 확인할 수 있음
canary deployment pattern
- 방법: 학습 알고리즘이 실제 결정을 내리도록 준비가 되었다면 초기 트래픽의 적은 부분만 학습 알고리즘이 판단할 수 있도록 시작하고 시스템 모니터링을 통해 성능에 확신이 생기면 점진적으로 트랙픽 비율을 높여 판단 진행
- 장점
- 적은 부분에서 판단을 내리기 때문에 실수를 해도 트래픽의 작은 부분에만 영향을 미침- 초기에 문제를 발견할 수 있을 가능성이 높음
blue/green deployment pattern
- 방법: SW 이전 버전을 blue 버전, 방금 구현한 학습 알고리즘을 green 버전이라고 함. 라우터가 이미지를 이전 버전이나 블루 버전으로 보내고 결정을 내리도록 함. 그런 다음 새 버전으로 전환하고 싶을 때 라우터가 이전 버전으로 x 전송을 준ㅇ단하고 새 버전으로 전환하도록 함. 즉, 이전 예측 서비스가 일종의 서비스에서 실행될 수 있음. 새로운 예측 서비스인 green 버전을 가동하면 라우터가 갑자기 이전 서비스에서 새 서비스로 트래픽을 전환하게 됨
- 장점
- 유연한 롤백 가능 --> 문제가 발생하면 구버전/신버전으로 보내도록 라우터를 재구성
3가지 배포 패턴에서 알 수 있듯이 배포 패턴을 수행하기 위해서는 많은 SW가 필요함. MLOps 도구는 이러한 배포 패턴을 구현하는데 도움이 되거나 직접 구현 가능
Degrees of automation: 스마트폰 스크래치 검사 시스템의 경우
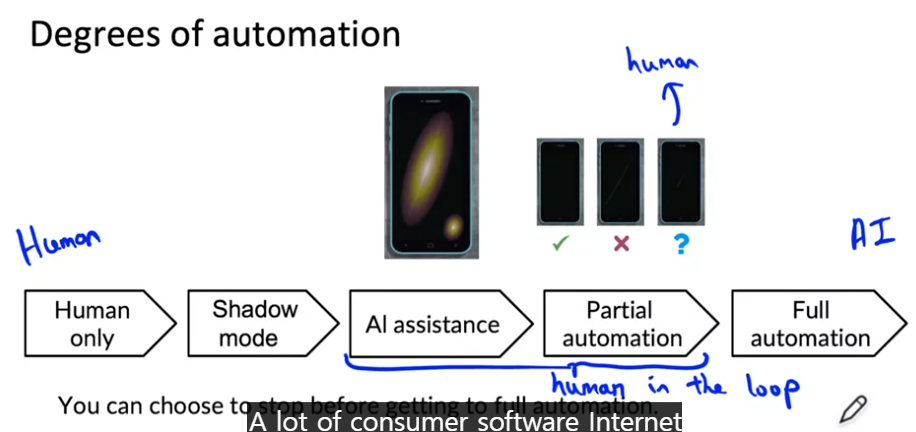
- 배포 X: 자동화없이 사람만이 육안으로 판단하여 스크래치 여부 결정
- 약간 배포: shadow pattern 사용 --> 학습 알고리즘은 예측을 수행하지만 실제 사용되지 않음
- 더 높은 수준의 배포: 인간 검사자가 결정을 내리고 학습 알고리즘은 스크래치가 난 영역을 강조하여
- 부분 자동화: 스마트폰 스크래치 여부 판단을 학습 알고리즘의 결정으로 진행. 만약 학습 알고리즘 판단에 확신이 없을 경우 인간 검사자가 한 번더 확인하여 예측. 인간 검사자의 판단은 알고리즘을 추가로 훈련하고 개선하기 위해 피드백하는 매주 귀중한 데이터
- 완전 자동화: 모든 결정을 학습 알고리즘이 내림
Monitoring
-
대시보드를 사용하여 시간 경과에 따라 어떻게 작동하는지 추적하는 방법
- 대시보드: 시간이 지남에 따라 변화하는 과정을 그래프로 표현하는 보드
- 시간이 지남에 따라 큰 변화가 있을 경우 무언가 잘못되었다는 표시일 수 있음
-
구조화된 데이터 작업에 대해 누락된 입력 값의 비율 모니터링
-
모니터링할 대상을 결정하려고 할 때 팀원들끼리 잘못될 수 있는 모든 상황에 대해 브레인스토밍하는 것이 좋음
-
Examples of metrics to track
- Software metrics: Memory, compute, latency, throughput, server load -> SW가 제대로 실행되고 있는지 확인 가능
- Input metrics: Avg input length, Avg input volume, Num missing values, Avg image brihgtness --> 입력 분포 x의 변화를 측정하는 메트릭
- Output metrics: # times return ""(null), # times user redoes search(음성 인식에 실패해서 사용자가 다시 재시도 하는 경우 -> 성능 저하를 의미할 수 있음), # times user switches to typing, CTR(Click-through rate) --> 출력 y가 어떤 식으로 변경되었는지, 또는 사용자가 타이핑으로 전환하는 것과 같이 학습 알고리즘 출력 후에도 발생하는 무언가를 파악하는데 도움이 됨
- 입력 및 출력 metric은 애플리케이션에 따라 다름 --> 대부분의 MLOps 도구는 애플리케이션에 맞추어 입, 출력 메트릭 추적하도록 구성 필요
-
ML은 반복적인 작업이므로 배포도 곧 반복적인 프로세스
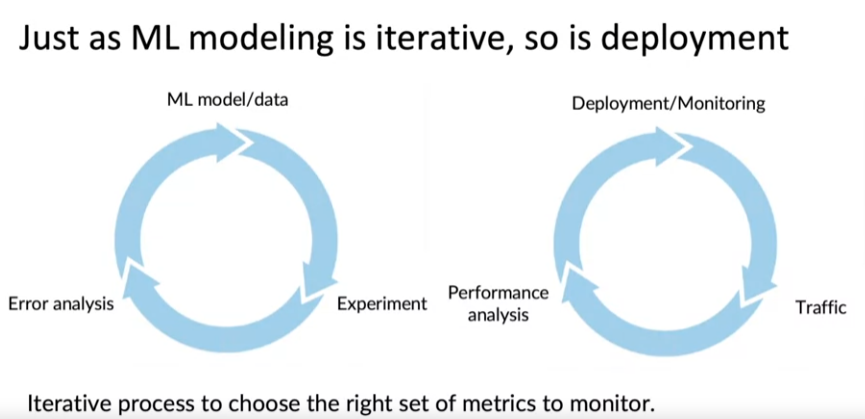
-
Monitoring dashboard: 반복적인 과정의 시작. 실행 중인 시스템을 사용하여 실제 사용자 데이터 또는 실제 트래픽을 얻을 수 있으며 학습 알고리즘이 실제 트래픽, 실제 데이터에 대해 수행하는 방식을 확인함으로써 서능 분석 수행 가능 --> 배포 업데이터 & 지속적인 시스템 모니터링
- Set thresholds for alarms: 임계값 설정 후 임계값에 도달하면 개발자에게 알람이 울리도록 한다.
- Adaptive metrics and thresholds over time: 시간이 지남에 따라 metric과 임계값을 조정
-
학습 알고리즘의 정확도 관련 문제인 경우 모델을 업데이트 해야 함
-
Model maintenance
-- 많은 ML 모델은 약간의 유지 관리 및 재교육이 필요
- 엔지니어는 오류를 분석하고 새 모델을 다시 교육하며 배포하기 전에 괜찮은 지 확인/자동 재교육이 가능한 시스템을 배치하는 것도 한 가지 방법
-
중요한 점: 오류 분석을 수행하거나 더 많은 데이터를 얻기 위해 다시 이전 단계로 되돌아가도록 문제를 찾아주는 것은 시스템 모니터링을 통해서만 가능하다는 것!!!
Pipeline monitoring
- AI 시스템: 단일 ML 모델 + 여러 단계의 파이프라인
- 음성 인식 예제를 통해 ML 파이프라인 알아보기!
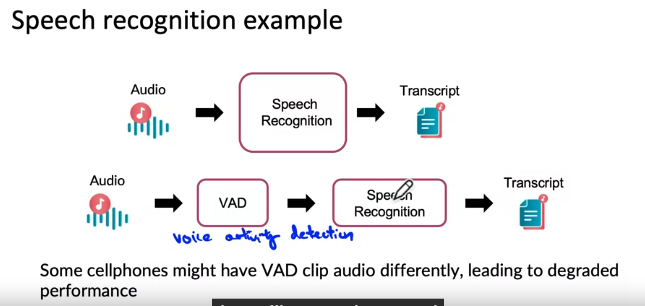
- VAD 모듈(음성 활동 감지 모듈): VAD 모듈을 사용하여 오디오를 효율적으로 자르거나 줄여서 클라우드 서버로 전송
- 누군가 말하고 있는 사실을 감지
- 음성 인식 시스템에 오디오 전달
- 스크립트 생성: 음성을 텍스트로 변환
--> 1이 변경되면 4에 영향을 주며 이는 성능 저하와 연관될 수 있음
- User profile 예제를 통해 ML 파이프라인 알아보기!

- click stream data 사용(사용자가 무엇을 클릭하는지에 대한 정보)
- 사용자의 속성이나 특징 캡처(자동차 소유 여부(소유, 비소유, 알 수 없음) 예측) - 클릭 스트림 데이터 변경 시 입력 분포 변경 --> 자동차가 소유 여부 정보 불확실 --> 알 수 없는 태그 비율 증가 --> 제품 권장 품질에 영향을 미침
- 프로필 작성(자동차 보험 사무소 정보 제공 가능)
- 프로필 기반 제품 추천
2번에서 "알 수 없음" 비율이 높아질 경우 4번 성능을 높이기 위해 시스템을 업데이트 할 필요가 있다고 알림을 받을 수 있으나 어떤 단계에서 문제가 추적하기 어려움
이런 복잡한 기계 학습 파이프라인을 구축할 때 파이프라인 전체에 기계/비기계 학습 기반 구성 요소를 파악하여 모니터링 메트릭을 브레인스토밍 하는 것이 유용!
-
Metrics to monitor: 각 파이프라인에 대한 개별 구성 요소와 관련된 메트릭 브레인스토밍
** Monitor: 각 메트릭을 통해 음성 오디오를 클립할 영역이나 사용자가 자동차를 소유하고 있는 여부를 파악하는데에 있어서 문제 발견에 도움이 될 수 있음 --> 던 개별 구성요소와 설계 메트릭에서 잘못될 상황까지 고려하여 모든 것을 브레인스토밍 해야 함! -
Software metrics
-
Input metrics
-
Output metircs
-
How quickly do tehy change?(데이터는 얼마나 빠르게 변경되는가?)
- User data generally has slower drift.
: 데이터 변경 속도는 문제에 따라 다름(얼굴 인식 시스템의 경우 사람의 외모는 빠르게 변화하지 않지만 휴대폰 제조 공장의 경우 외모의 비해 빨리 바뀌는 경향이 있음 --> 수백만 사용자의 데이터는 비교적 느리게 변경됨, 예외사항으로 코로나와 같은 사건으로 데이터가 급격하게 변할 수 있음) - Enterprise data(B2B applications:업 대 기업은 기업과 기업 사이의 거래를 기반으로 한 비즈니스 모델) can hift fast.
: 기업에서 운영 방식을 결정하면 하루 아침에 그 운영 방식에 맞추어 데이터를 변경해야 함
: 휴대폰 디자인, 운영체제 등
- User data generally has slower drift.
Week 2: Select and Train a model
Modeling overview
- 학습 목표
- 프로덕션 배포에 적합한 ML 모델 구축하기 위한 몇 가지 사례에 대해 알아보기
- 새로운 dataset 처리 방법
- 프로덕션 기계 학습 모델 구축을 위한 주요 과제
- 모델링 부분: 모델 선택 및 훈련, 오류 분석, 드라이브 모델 개선
- 알고리즘 AI 개발 VS 데이터 기반 AI 개발 -> 데이터 중심 접근 방식을 취하는 것이 훨씬 효율적이지만 수집 과정에 있어 많은 시간 소요 --> 데이터 개선에 도움이 되는 도구 학습
Key challenges
AI system = Code(algorithm) + Data
- Model development is an iterative process
-- 데이터 vs 모델 vs 하이퍼 파라미터 중 어떤 걸 수정할 지 선택하고 다시 모델을 업데이트 하며 해당 과정을 반복함
- Challenges in model development
- Doing well on training set (usually measured by average training error).
- Doing well on dev/tset sets. --> test sets에서 낮은 에러율을 보여도 실제 적용하면 성능이 충부하지 못한 경우가 있음
- Doing well on business metircs/project goals.
** 다음 강의에서 2을 해결하는 방법에 대해 알아보자!
Why low average error isn't good enough
test sets에서 잘한다고 끝이 아니다!
- Performance on disproportionately important examples
-- 예) Web Search example

- Informational and Transactional queries는 가장 관련성이 높은 결과를 반환하기를 원하지만 사용자는 곤련성 높은 결과에 2위, 3위를 매겨도 어느 정도 수용하고 인정하는 경우가 많음
- Navigational queries는 매우 분명한 의도를 가지고 검색을 진행할 때 Staford.edu를 1위 결과로 반환하지 않으면 올바른 결과를 제공하지 않았다고 생각하며 해당 검색 엔진은 신뢰를 잃음
- 이 때 Navigational queires는 불균형적으로 중요한 예제 집합. test sets는 예제별로 동등한 가중치를 가지고 테스트가 진행되지만 웹 검색에서는 일부 쿼리가 불균형적으로 중요하기 때문에 이런 예에 가중치를 부여해야 함. --> 그러나 실무에서는 예제별로 가중치를 다르게 준다고 해도 모든 문제를 해결하는 데에 한계가 존재함.
- 예) Web Search example
문제1: Performance on key slices of the dataset

- 예: ML for loan approval(대출 승인을 위한 ML 알고리즘)
- 모든 사람에게 공정하게 승인을 하고자 하지만 실제 dataset에서 발생하는 편향으로 인해 대출 승인에 있어서 차별 발생
- 예: 가게 추천 시스템
- 대기업, 중소기업을 차별하여 추천
문제2: Rare classes(희귀 클래스)

- 의학적 진단에서 인구의 99%가 질병이 없고 1%만 질병이 있을 때, 예측 시스템은 "질병이 없음"이라는 결과를 반환하면 99% 정확도를 달성할 수 있음
- 평균 test sets 정확도가 모든 예제에 동일한 가중치가 부여됨으로써 드문 클래스를 무시해버림
문제3: Unfortunate conversation in many companies

- test sets에서 잘 수행되는 건 마땅히 축하받아야 할 일이 맞지만 프로덕션 배포에는 충분하지 않음
Establish a baseline
- 기준선 설정하여 기반 다지기!
예: 음성 인식 시스템(비정형 데이터) - 사람이 해석을 잘하는 데이터이므로 HLP를 측정하여 기준을 설정하는 것이 좋음

- 4가지 타입의 음성 데이터와 그에 해당하는 정확도가 있다고 가정
- 4가지 타입의 음성 데이터에 대한 인간 수준의 성능(Human level performance, HLP)
-
- 사람이라도 저대역폭 오디오를 인식하지 못하고 따라서 "Low Bandwidth" 오디오 개선보다 "Car Nose" 오디오 작업 개선에 초점을 맞추는 것이 효과적일 수 있음 --> HLP는 "Car nose" data에 집중할 영역을 결정하는 데에 도움이 됨
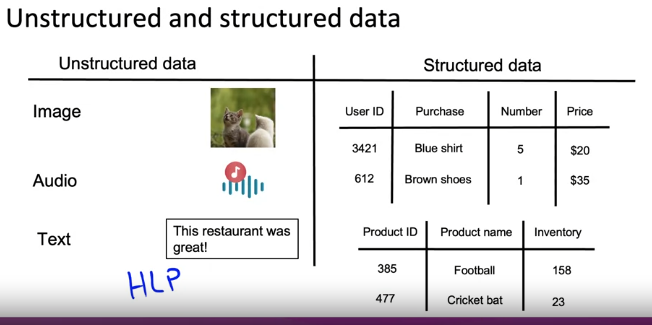
--> 정형/비정형 데이터 비교
정형 데이터(구조화 데이터, DB, Excel 스프레드 시트) - 사람이 해석을 잘하지 못하는 데이터이므로 HLP는 정형 데이터에 덜 유용한 기준선이 됨
Ways to establish a baseline
- Human level performance (HLP)
- Literature search for state-of-the-art/open source: 최신 기술에 대한 문한 검색 및 오픈 소스 결과와 비교
- Quick-and-dirty implementation: 무대뽀로 구현. 어떤 것이 가능할지에 대한 감각을 파악할 수 있음.
- Performance of older system: 이전 시스템의 성능
Baseline helps to indicates what might be possible. In some cases (such as HLP) is also gives a sense of what is irreducible error/Bayes error.
: 기준 시스템 또는 기준 수준의 성능이 하는 일은 가능한 것을 나타는데 도움이 됨. 다시 말해 문제에 대해 기대할 수 있는 최소한의 성능을 파악할 수 있음. 또한 위의 예처럼 어느 부분을 개선하는지 우선순위를 설정하는 데에 도움을 줌.
일부 비즈니스 팀이 90% 정확도를 달성해와!라고 할 때 연구진을 어렵게 만들 수 있음. 따라서 연구진들은 얼마나 정확해질 수 있는지에 대한 baseline 설정하여 예측 시스템의 정확도를 설정해야 함.
Tips for getting started
Getting started on modeling
- Literature search to see what's possible(courses, blogs, open-source projects).: 실용적인 생산 시스템 구축이 목표라면 최신 연구에 집착하지 말자!
- Find open-source implementations if availiable.: 사용 가능한 오픈 소스를 찾고 baseline을 잡아보자!
- A reasonable algorithm with good data will often outperform a great algorithm with no so good data.: 좋은 데이터가 포함된 합리적인 알고리즘이 좋은 성능을 보여준다.
Deployment constraints when picking a model
- should you take into account deployment contrains when picking a model?: 모델을 선택할 때 컴퓨팅 제약 조건과 배포 제약 조건을 고려해야 하는가?
YES, if baseline is already established and goal is to build and deploy.: 기준선이 설정되어 있고 프로젝트가 작동할 것이라고 홗긴하는 경우 컴퓨팅 제약 조건과 같은 배포 제약 조건을 고려해야 한다. --> 따라서 목표는 시스템 구축 및 배포
NO (or not necessarily)m if purpose is to establish a baseline and determine what is possible and might be worth pursuing.: 그러나 아직 baseline 미설정 또는 프로젝트가 작동하고 배포할 가치가 있는지 확신이 없다면 안된다. 먼저 기준선을 설정하고 무엇이 가능한지 결정하는 것이 우선이며 추구할 가치가 있을 경우 배포 제약 조건을 무시하고 일부만 찾는 것이 좋다.
Sanity-check for code and algorithm: 학습 알고리즘 첫 시도 시에 오전성 검사를 실행하는 것이 좋음

- Try to overfit a small training dataset before training on a large one.: 큰 dataset으로 훈련하기 전에 작은 훈련 dataset에 과적합 시도하기. --> 적은 시간과 데이터만으로 버그를 찾을 수 있음
- Example #1: Speech recognition - 음성 인식 시스템이 있다고 가정했을 때 하나의 예제에 대한 output이 빈 공간으로 나오면 하나의 예제에서조차도 제대로 수행되고 있지 않기 때문에 거대한 훈련 세트에서 훈련하는 것은 무의미하다.
- Example #2: Image segmentation - 하나의 이미지에 대해 훈련하고 과적합 되는지 확인하면 단 몇 분/초만에 버그를 찾을 수 있음
- Example #3: Image classification - 10, 100개의 이미지 하위 집합에서 훈련하는 것이 좋음.
Error analysis example
- ML 개발 프로세스의 핵심: 오류 분석
Speech recognition example
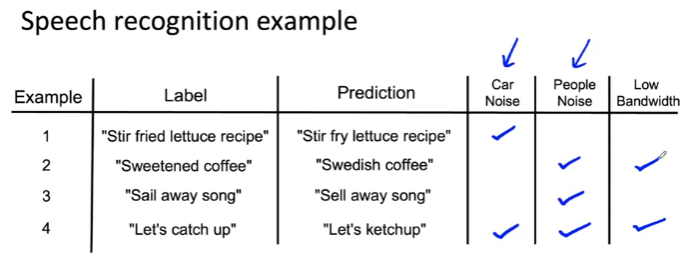
- 잘못된 예제 추출
- 예를 들을 때 어떤 소음이 있었는지 체크
- 이런 테이블을 채워나가다가 다른 요소(Low Bandwidth)를 발견
- 새로운 열을 추가하여 해당 태그를 갖는 예제에 체크
--> 오류를 분석할 수 있음

- 이런 테이블(Google sheet, Excel sheet, Mac 등)을 통해 어떤 태그가 오류의 원인이 되는지, 어떤 태그에 집중해야 하는지 파악할 수 있음
Iterative process of error analysis: 초기 태그 세트를 설정하고 초기 예제 세트를 검사하면서 몇 가지 새로운 태그를 추가하여 반복하는 과정을 토해 오류 분석

-
Visual Inspection: 스마트폰 결함 찾기
- Specific class labels (scratch, dent, etc.)
- Image properties (blurry, dark background, light background, reflection, ...)
- Orther meta data: phone model, factory
-
Product recommendataions: 제품 추천 시스템
- User demographics: 인구 통계적으로 좋은/나쁜 추천을 하는지
- Product features/category: 특정 제품 기능나 카테고리의 영향을 받는지
Useful metrics for each tag --> 작업의 우선순위 결정 가능
- What fraction of errors has that tag?: 태그의 오류 비율. 음성 인식 시스템의 경우 자동차 소음 태그를 단 예제의 오류율이 높다면 자동차 소음에 대한 작업을 진행하면 해당 오류율만큼 성능을 향상 시킬 수 있음
- Of all data with that tag, what fraction is misclassified?: 레이블 분류가 잘못 된 예제와 잘 된 예제 모두에 태그를 지정하여 데이터 확인. 자동차 소음을 갖는 예제의 경우 모든 데이터 중 18%만 잘못 분류되었다고 가정했을 때 해당 유형의 태그가 포함된 데이터의 성능은 특정 수준의 정확도를 갖는다는 사실을 확인할 수 있음.
- What fraction of all the data has that tag?: 전체 데이터에서 해당 태그를 갖는 비율 확인. 전체 dataset 중 해당 태그를 갖는 예제가 얼마나 중요한지 알려줌.
- How much room for improvements is there on data with that tag?: 해당 태그를 갖고 있는 data 개선 여지가 얼마나 있는지. 해당 태그 데이터로 인간 수준의 성능을 축정
Prioitizing what to work on: 태그를 사용하여 집중해야 하는 부분에 대한 우선순위 지정
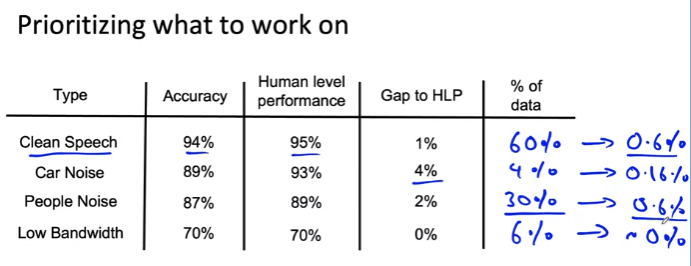
- "Car Noise" 태그에서 HLP 성능과 정확도 간의 차이가 큼 --> 이에 대한 작업을 진행하기 전 해당 태그가 포함된 데이터 비(% of data)비율을 확인해야 함.
- "Clean Speech"에 대해서는 1% 성능 향상을 기대할 수 있으며, 데이터 비율까지 고려하면 60% 데이터의 성능을 1% 개선할 수 있으므로 전체 음성 시스템은 0.6% 향상됨
- "Car Nose"에 대해서는 4% 성능 향상을 기대할 수 있으며, 데이터 비율까지 고려하면 4% 데이터의 성능을 4% 개선할 수 있음로 전체 음성 시스템은 0.16% 향상됨
--> 태그를 비교할 경우 실제 "Car Noise"를 개선하는 것보다 "Clean speech", "People Noise"를 개선하는 것이 정확도 성능 향상에 더 큰 기여.
--> HLP, 일부 기준과 비교하여 개선의 여지를 파악하는 것이 중요
Decide on most important categories to work on based on:
- How much room for improvement there is.: 개선의 여지가 얼마나 있는지
- How frequently that category appears.: 해당 카테고리가 얼마나 자주 나타나는지
- How easy is to improve accuracy in that category.: 해당 카테고리에서 정확도를 향상시키는 것이 얼마나 쉬운지
- How importatn it is to improve in that category.: 해당 카테고리에서 성능을 향상시키는 게 얼마나 중요한지 ("Car Noise"에서 음성 인식 시스템을 더 사용할 가능성이 높음)

평균 성능을 향상시키려는 카테고리를 설정 후 접근 방식 --> 어떤 유형의 데이터를 수집할 지 파악 가능 - Collect more data: data 수집
- Use data augmentation to get more data: 데이터 증강
- Improve label accuracy/data quality
Skewed datasets: 편향된 datasets
Example of skewed datasets

- 예제: 제조 회사
- y = 0: 결함없음 : 99.7%
- y = 1: 결함있음 : 0.3#
- y = 0을 계속 출력하면 99.7% 정확도 달성 --> 오류!
- 예제: 의학적 진단
- 99%가 질병에 걸리지 않고 1%만 질병에 걸린다면 "질병 없음" 만 출력해도 99% 정확도 달성 --> 오류!
- 예제: 음성 인식
- 트리거 단어(Alexa, Ok Google, Hey Zoe)를 듣고 확인하는 시스템- 트리거 단어 시스템의 빈도가 낮으면 트리거가 감지되지 않았다 라는 출력만 내보내면 됨 --> 오류!
오류 해결을 위해 Confusion matrix 사용

- TN: Negative라고 예측한 것이 정답
- TP: Positive라고 예측한 것이 정담
- FN: Negative라고 예측한 것이 오답
- FP: Positive라고 예측한 것이 오답
- Precision: TP / TP + FP --> 매우 편향된 dataset에 대한 학습 알고리즘을 평가할 때 유용
- Recall = TP / TP + FN(실제 정답이 p인 비율) --> 기존 정확도보다 훨씬 유용
- Positive(임계값이 낮아서)라고 예측한 비율이 높아질 경우: TP, FP 증가 & FN 감소 --> Recall 증가
- Negative(임계값이 높아서)라고 예측한 비율이 높으질 경우: TN, FN 증가 & FP 감소 --> Precision 증가

- 학습 알고리즘이 "y = 0"만 출력할 경우
- precision = 0/(0+0)
- recall = 0/(0+86) --> FN의 영향력 무시
F1 Score: precision + recall

- P와 R을 결합
- P와 R 사이 평균을 취하면서 더 나쁜 것을 강조하는 결합 방법
- F1 score를 통해 Model1이 2보다 나은 성능을 가지고 있음을 알 수 있음
왜곡된 데이터 세트의 다중 클래스 분류 문제
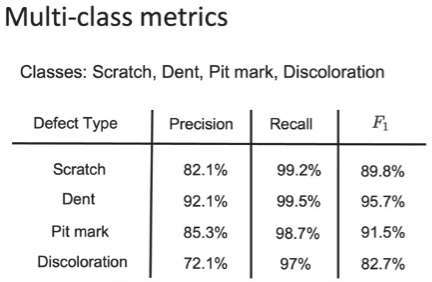
예제: 스마트포 결함 감지
- classes: Scratch, Dent, Pit mark, Discoloration
- 이 문제에서는 precision보다 recall이 높은 것을 더 선호 --> 약간이라도 흠집이라고 의심되는 판단되면 "결함있음"을 출력하고 이후에 사람이 한 번 더 확인하여 결함이 없는 스마트폰을 출시하기를 원하기 때문(높은 precision은 결함이 확실히 있을 때 결함 있음을 출력하므로 이 문제에서는 그렇게 효율적이지 않음)
- F1 score를 사용하여 희귀클래스에서도 올바른 정확도를 계산하고 판단할 수 있음.
Performance auditing: 성능 감사
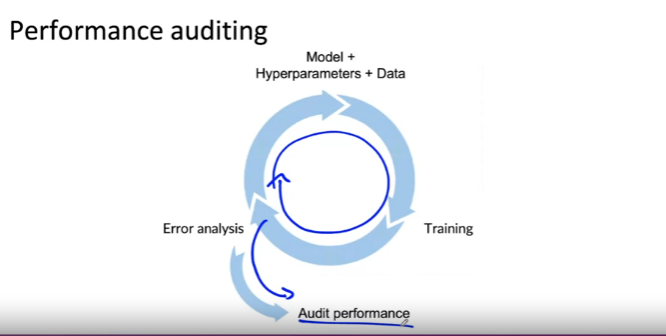
Auditing framework
Check for accuracy, fairness/bias, and other problems.
1. Brainstorm the ways the system might go wrong.: 시스템이 잘못될 수 있는 다양한 방법에 대해 브레인스토밍
- Performance on subsets of data(e.g., ethnicity, gender).: 인종, 성별 등 데이터의 하위집합에서도 좋은 성능을 내는가?
- How common are certain errors(e.g., FP, FN).: 왜곡된 dataset에서 특정 에러가 얼마나 자주 나오는지?
- Performance on rare classes.: 희귀 클래스에서 성능이 어떤지?
- Establish metrics to assess performance against these issues on appropriate slices of data.: 이러한 문제에 대해 데이터의 일부분을 사용하여 알고리즘의 성능을 평가하기 위한 메트릭 설정
- Get business/product owner buy-in.: 오너의 동의 얻기, 오너에게 가장 걱정할 만한 문제와 이런 문제에 대해 합리적으로 평가할 메트릭이다 라는 점에 동의 얻기.
Speech recognition example
- Brainstorm the ways the system might go wrong.: 시스템에서 문제가 될 만한 모든 방법 브레인스토밍
- Accuracy on different genders and ethnicities.: 다른 성별과 인종에 대한 정확도
- Accuracy on different devices.: 장치에 대한 정확도 --> 아주 질이 나쁜 마이크를 사용(추후 성능을 높일 수 있도록)
- Prevalence of rude mis-transcriptions.: GAN을 설명할 때 오역으로 인해 "GANG", "GUN"으로 표현하여 무례한 오역으로 인해 문제가 생길 수 있음 --> 이는 오역보다 훨씬 더 부정적인 인식을 줌
- Establish metrics to assess performance against these issues on appropriate slices of data.: 1번의 이슈를 기반으로 적절한 데이토 조각에서 이러한 문제에 대한 성능을 평가하는 메트릭 설정
- Mean accuracy for different genders and major accents.: 다른 성별과 다른 억양에 대한 음성 시스템의 평균 정확도 측정
- Mean accuracy on different devices.: 다른 디바이스 정확도 측정
- Check for prevalence of offensive words in the outputs.: 출력에서 불쾌하거나 물_한 단어 확인
시스템을 보다 공정하고 덜 편향되게 만드는 방법 중요!
Data-centric AI development
데이터 품질을 중요하게 생각하며 오류 분석과 데이터 증강과 같은 도구를 사용하여 데이터 품질을 체계적으로 개선하자

A useful picture of data augmentation
Speech recognition example
Different types of speech input:
- 기계 noise
- Car noise
- Plane noise
- Train noise
- Machine noise
- 사람들 대화 noise
- Cafe noise
- Libarary noise
- Food court noise

- y축: performance(정확도)
- x축: Space of inputs
- 파란색: input에 대한 학습 알고리즘 정확도
- 초록색: HLP
- 파란색과 초록색 사이 격차 = 개선의 기회
- 만약 "cafe noise" 데이터를 더 많이 수집하여 훈련 세트를 추가하면 "cafe noise"에 대한 알고리즘 성능을 끌어올릴 수 있으며 이는 가까운 지점의 성능이 올라가고 먼 곳도 올라갈 수 있음.
- 비정형 데이터는 한 부분을 당겨도 다른 부분이 실제로 더 아래로 내려가지 않을 가능성이 있는 거스로 나타남.
- 한 카테고리에 대한 데이터를 수집하면 큰 격차는 다른 지점으로 이동할 수 있고 오류 분석을 통해 새로운 큰 격차를 갖는 위치를 알려주며 한 번에 한 영역씩 끌어올리기 위해 노력할 가치가 충분히 있음
Data augmentation: 비정형 데이터에서 유리

- 오디오 클립 + 노이즈 = 합성된 오디오 클립
- 어떤 유형의 노이즈를 사용하는지, 소음은 오디오 클립에 비해 얼마나 커야하는지 체계적으로 고려 필요!
Data augmentation: 학습 알고리즘이 학습할 수 있는 데이터를 만드는 것이 중요
Goal: Create realistic examples that (i) the algorithm does poorly on, but (ii) humans (or other baseline) do well on: 알고리즘에서 잘 작동하지 않지만 인간이나 다른 기준선이 잘 수행할 수 있는 실제와 같은 예제를 만들기
- 이미 잘 작동하는 예제는 필요 없음 --> 더 이상의 성능 향상을 기대하기 어려움
- 너무 시끄러운 노이즈를 합해버리면 성능 향상에 도움되지 않음 --> 인간도 알아들을 수 없는 데이터는 불필요
- [데이터 증강 -> 학습 알고리즘 훈련 -> 성능 평가 -> 데이터 증강] 단계를 반복하면 시간이 오래 걸릴 수 있으므로 비효율적. 따라서 다음 checklist를 참고하여 증강한 데이터가 온전한 지 확인
Checklist: - Does it sound realistic?: 현실감 있게 들리는가?
- Is the x -> y mapping clear?(e.g., can humans recognize speech?): x -> y mapping이 명확한가?(인간이 인식할 수 있는가?)
- Is the algorithm currently doing poorly on it?: 알고리즘이 수행하려는 종류의 사실적인 오디오처럼 들리는가?
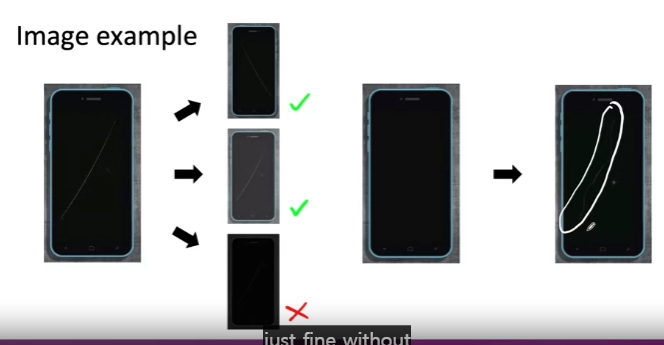
- 기존 datasets: 스크래치가 있는 datasets
- 증강 방법
- 가로로 뒤집기
- 대비 변경
- 이미지 밝기 변경 --> 너무 어두우면 인간도 인식 불가 --> 체크리스트 2번에 충족 X
- photoshop을 사용하여 스크래치 생성
- GAN을 사용하여 자동으로 데이터 생성: 모델 설계를 해야하므로 비효율적
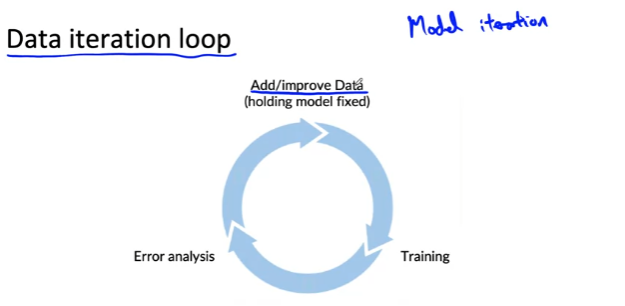
- model iteration: 오류를 분석하고 모델을 반복적으로 교육하여 다음 모델을 개선할 방법을 결정한 것: 데이터 품질, 하이퍼파라미타 등등
Can adding data hurt?: NO
Can adding data hurt performance?
For unstructured data problems, if:
- The model is large(low bias).: 모델이 크고 용량이 크고 편향이 낮은 신경망일 경우 성능 저하 없음.
그러나 새로운 카테고리(카페 노이즈)를 데이터를 추가하여 입력 분포가 변경된다면 카페 소움을 설정하는 리소스를 많이 소비하여 성능에 영향을 줄 수 있음. - The mapping x -> y is clear(e.g., given only the input x, humans can make accurate predictions).: x에 대한 label이 분명하지 않을 경우 성능을 저하시킬 수 있음
Then, adding data rarely hurts accuracy.

- 모호한 예에서 제대로 추측할 수 없음: x-->y mapping이 올바르지 못함
Adding features: 구조화된 dataset 증강
Structured data

예제: Restaurant recommedation example
- input: 사용자, 레스토랑
- output: 식당 추천 여부
- 오류: Vegetarians are frequently recommended restarants with only meat options.(채식주의자에게 육류 옵션이 있는 레스토랑이 자주 추천됨)
- 오류 해결 방법: 이미 많은 사용자와 식당이 있기 때문에 사용자, 식당을 새로 생성하지 않고 추가할 feature가 있는지 확인하는 것이 필요
- Possible features to add?
- Is person vegetarian (based on past orders)?(굳이 0, 1로 나눠지지 않아도 됨)
- Does restaurant have vegetarian options(based on menu)?
Other food delivery examples
- Only tea/coffee
- Only pizza
What are the added features that can help make a decision?
Product recommenation: - Collaborative filtering(느슨하게 사용자를 살표보고 그 사용자와 유사한 사람을 파악한 후 유사한 사람들이 좋아하는 것을 추천하는 접근 방식) --> Content based filtering(식당 설명, 실당 메뉴를 보고 식당이 사용자에게 맞는지 알아보고 추천 여부 결정 --> 따라서 새로운 식당이나 신제품이 있어도 추천리스트에 충분히 올라갈 수 있음)
** 콜드 스타트 문제: 새로운 제품이나 식당이 있을 때 사용자 관련 데이터가 없기 때문에 추천할 수 없음
Data iteration
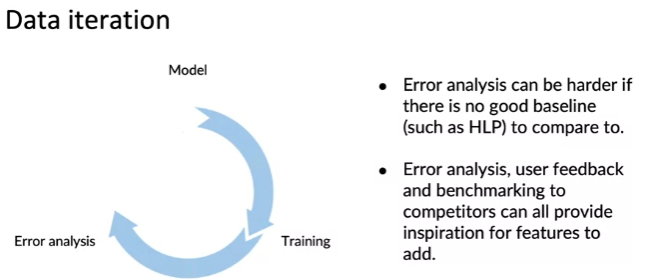
- Model -> training -> error analysis
- HLP와 같은 비교할만한 기준이 없다면 구조화된 데이터 문제에서 오류 분석이 더 어려울 수 있으나 오류 분석을 통해 개선 아이디어 찾기, 사용자 피드백 발견, 경쟁업체에 대한 벤치마킹 가능 --> 이는 곧 어떤 feature를 추가할 지에 대한 영감을 제공

Experiment tracking: 알고리즘을 반복적으로 개선하기 위해 효율적으로 도움이 되는 방법 - 실험 추적
What to track?
- Algorithm/code versioning
- Dataset used
- Hyperparameters
- Results: 모델, F1 score
Tracking tools
- Text files: 내가 하고 있는 일 기록
- Spredsheet
- Experiment tracking system
Desirable features
- Information needed to replicate results: 결과를 복제할 때 필요한 모든 정보가 제공되는지
- Experiment results, ideally with summary metrics/analysis: 특정 훈련 실행의 실험 결과를 신속하게 이해하는데 필요한 도구 사용
- Perhaps also: Resource monitoring, visualization, model error analysis: 리소스 모니터링, CPU/GPU 메모리 리소슷 ㅏ용량, 훈련된 모델 시각화, 모델 오류 분석
From big data to good data
- Data-centric algoritm
- ML 프로젝트 개별 단계에서 고품질 데이터를 보장할 수 있다면 고성능 및 안정적인 ML 배포 가능
- 좋은 데이터: X --> Y mapping 되는 모호하지 않은 데이터

From Big Data to Good Dta
Try to ensure consistently high-quality data in all phases of the ML project lifecycle.
Good data:
- Convers important cases(good converge of inputs x)
- Is defined consistently (define of labels y is unambiguous)
- Has timely feedback from production data(distribution convers data drift and concept drift)
- Is sized appropriately
Week 3: Data Definition and Baseline
Why is data definition hard?

"이구아나 위치를 나타내기 위해 경계 상자를 사용하여 labeling 진행 요청"
- 첫번째 labeling: 2마리 이구아나에 대해 각각의 경계 상자
- 두번쨰 labeling: 2마리 이구아나에 대한 경계 상자를 설정하되 왼쪽 이구아나의 꼬리를 포함하여 경계 상저 설정
- 세번째 labeling: 2마리 이구아나를 아우르는 경계 상자 설정
--> 다양한 labeling 방법이 있으나 dataset에 대해 1/3은 첫번째, 1/3은 두번째, 1/3은 세번째 레이블 지정 규칙을 사용하면 레이블이 일관성 없고 학습 알고리즘에 혼란을 부여
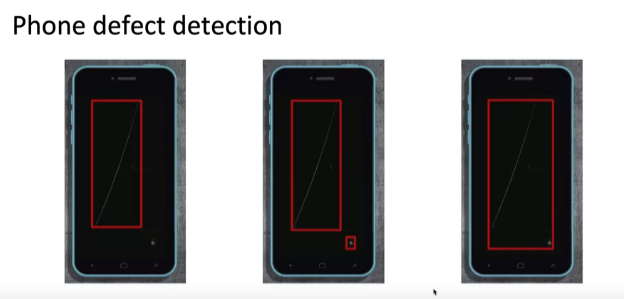
"휴대폰 결함 위치를 나타내기 위해 경계 상자를 사용하여 labeling 진행 요청" - 첫번째 labeling: 분명하게 스크래치가 난 부분 경계 상자
- 두번쨰 labeling: 분명한 스크래치와 약한 스크래치 부분 경계 상자
- 세번째 labeling: 분명한 스크래치와 약한 스크래치를 아우르는 경계 상자
--> 두번째 labeling이 가장 효과적일 것으로 예상
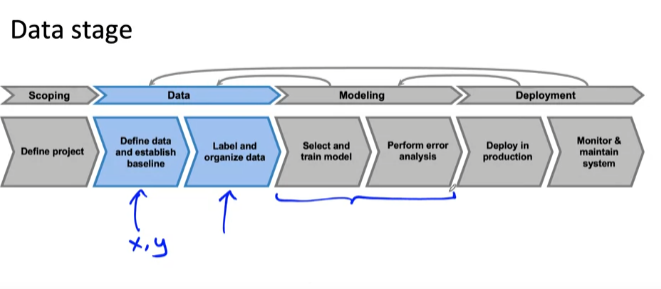
- 기계 학습 프로젝트의 전체 주기 중 데이터 단계에 대해 살펴보자
More label ambiguity examples
모호한 label: 음성 오디오 클립
- 실제 음성: Um, nearest gas station
- "Um, nearest gas station"
- "Umm, nearest gas station"
- "Nearest gas station [unintelliglble]"
- 규칙: m을 1개 쓸지, 2개 쓸지/뒤에 알아들을 수 없는 말을 쉼표, 생략부호, 알아들을 수 없음 으로 쓸지 미리 설정하여 표준화하면 음성 인식 알고리즘에 도움이 됨
구조화된 데이터
-
많은 대기업의 일반적인 응용 프로그램은 사용자 ID 병합
- 동일한 사람에 해당하는 여러 개의 데이터 레코드를 병합하려는 경우
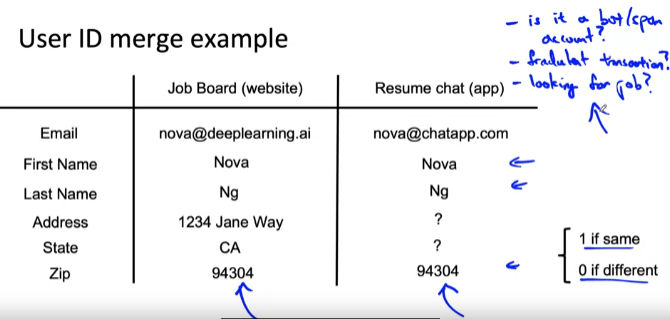
예제ㅣ 온라인 작업 목록을 제공하는 웹사이트가 채팅 모바일 앱을 인수했다고 가정 -
지도 학습 알고리즘 사용: 사용자 데이터 레코드에 대한 입력을 취하고 둘이 실제로 동일인인지 여부에 따라 1/0 출력
-
인간이 직접 진행: 유사한 이름을 갖도록 필터링된 일부 레코드 쌍을 비교후 우편 번호를 입력하여 인간이 판단
--> 일관성이 있는 labeling일 경우 학습 알고리즘에 훨씬 더 도움이 됨 -
사용자 계정이 봇/스팸 계정인가?
-
훔친 계정인가?
-
구직을 원하는가?
--> 잠재적으로 중요하고 가치 있는 예측 작업에 직면하여 기본 정보가 모호할 수 있음
--> label 지정 지침을 제공하여 더 일관성 있고 덜 무작위적인 레이블을 생성하여 학습 알고리즘의 성능을 향상시키자
Data definition questions

- input x가 무엇인가?
- 조명, 대비, 해상도는 괜찮은가? --> 만약 어두운 사진이 여러장 있다면 사람도 해석하기 어려움. 따라서 공장에 가서 정중하게 조명 개선을 요청하여 고품질 데이터를 수집해야 함.
- 포함하고자 하는 feature가 학습 알고리즘 성능에 큰 영향을 미칠 수 있는지 여부 --> ID 병합의 경우 GPS 위치를 사용하여 두 계정이 동일한 사람에게 속하는지 여부를 결정하는 데 매우 유용한 도구가 될 수 있음.
- target label y는 무엇인가?
- 일관된 레이블 제공 필수
Major types of data problems

- 가로축: 비정형 데이터 VS 정형 데이터 사용 여부
--> 인간은 비정형 데이터 분석을 잘함 - 세로축: dataset 크기
--> 데이터 하나하나를 뜯어보지 못하는 값을 예제 임계치로 설정 - 예: 100개 스크래치폰 예제에서 제조 육안 검사 훈련 --> 데이터 증강
- 예: 집의 크기와 다른 특징을 기반으로 주택 가격 예측하려는 52개의 구조화된 데이터 세트
- 예: 5천만 개 기차 예제에서 음성 인식 수행
- 예: 온라인 쇼핑 권장 시스템, database에 백만 명의 사용자가 있는 구조화된 데이터
- 비정형 데이터: 새로운 이미지/오디오 합성과 같은 데이터 증강에 레이블을 지정하는데에 도움을 줄 수 있음
- 정형 데이터: 정형 데이터 자체를 생성하는 것도 어려울 뿐더라 많을 경우에는 없는 데이터를 생성하는 것이 더 어려움
- 비교적 작은 데이터: 깨끗한 레이블 + 일관된 레이블을 갖는 것이 중요
- 비교적 많은 데이터: 깨끗한 레이블 + 일관된 레이블을 갖는 것이 중요하지만 실제로 데이터 하나하나를 살펴보기 어려우므로 프로세스에 중심을 두어 진행
Unstructured vs. structured
Unstructured data
- May or may not have huge collection of unlabeled examples x.: 레이블이 지정되지 않은 x가 많을 수도 없을 수도 있다.
- Humans can label more data.: 인간에게 labeling 작업을 요청하여 더 많은 데이터를 수집할 수 있다.
- Data augmentation more likely to be helpful: 데이터 증강도 도움이 된다.
Structured data
- May be more difficult to obtain more data.: 데이터를 더 수집하기 어려움
- Human labeling may not be possible (with some exceptions).: 인간 labeling도 어려울 뿐더라 올바른지 확인하기 어려움
Small data vs. big data
Small data
- Clean labels are critical.: 깨끗한 레이블
- Can manually look through dataset and fix lables.: 전체적으로 dataset을 확인하고 잘못된 label을 고친다.
- Can get all the labelers to talk to each other.: label 지정자들은 서로 대화를 통해 일관된 labeling을 진행해야 한다.
Big data - Emphasis data process.: data 프로세스에 중점을 둔다
4분면에서 내가 속하는 작업을 확인하고 해당 사분면에서 일했던 사람에게 조언듣기
Small data and label consistency
Why label consistency is important

- 노이즈가 있는 5개 데이터: label에 noise가 껴있음, 정확한 feature를 맞추기 어려움
- 다량의 데이터: noise가 있는 data라도 평균을 통해 함수를 그릴 수 있음
- 노이즈가 없는 5개 데이터: 깨끗하고 일관된 레이블을 갖고 있기 때문에 비교적 올바른 함수를 구할 수 있음
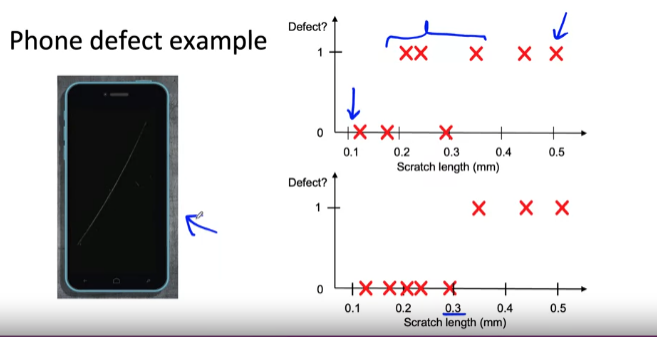
- 첫번째 그래프에서 label 지정자가 모호하게 레이블을 지정한 영역(0.2 ~0.4)가 있음 --> 이에 대한 해결책은 스마트폰과 긁힌 자국이 있는 사진을 많이 수집해야 함
- 두번째 그래프에서 스크래치 길이를 지정하여 레이블링을 지정하면 훨씬 더 일관되게 지정할 수 있으며 학습 알고리즘도 일관된 선택이 가능해짐
Big data problems can have small data challenges too
Problems with a large dataset but where there's a long tail of rare events in the input will have small data challenges too,
- Web search
- Self-driving cars
- Product recommendation systems
매우 큰 데이터셋일지라고 하더라도 희귀한 데이터(long tail) 를 감지하고 레이블을 지정할 때 일관된 레이블을 지정할 수 있도록 보장해야 함.
Improving label consistency: label 일관성 개선 방법
Improving label consistency
- Have multiple labelers label same example.: 여러 레이블 지정자가 동일한 예에 대해서 레이블을 지정하기.
- When there is disagreement, have MLE, subject matter expert(SME) and/or labelers discuss definition of y to reach agreement.: 불일치할 경우 레이블 지정자 간 토론을 통해 label y 정의에 대해 논의&토론하여 합의에 도달하도록 한다. 이상적으로 계약을 문서화하는 것을 추천
- If labelers believe that x doesn't contain enough information, consider chainging x.: x가 충분한 정보를 포함하지 않을 경우 x를 수정하자. 너무 어두운 사진이라 스마트폰 스크래치가 보이지 않을 경우 조도를 변경해야 할 필요성이 있으며 이는 성능에 큰 영향을 줌.
- Iterate until it is hard to significantly increase agreement.: 레이블을 지정하는 프로세스를 반복하여 합의에 도달하도록 한다.
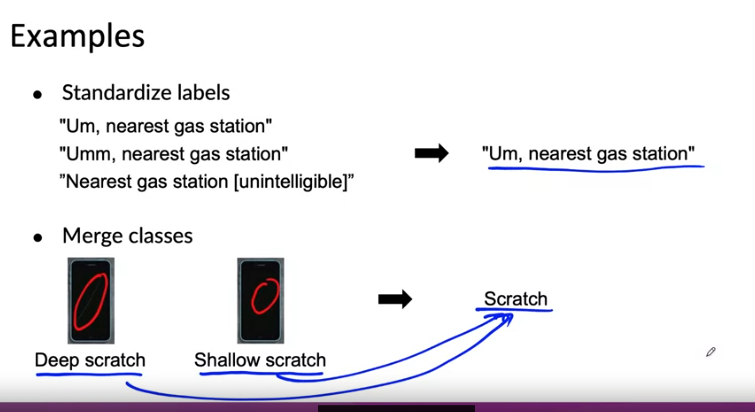
일관성을 높이는 방법
- 레이블 지정하는 방법 표준화: 오디오 클립에 레이블을 지정하는 방법들을 관습으로 표준화
- 클래스 병합: 이미지 간의 깊은 긁힘과 얕은 긁힘을 병합하여 "스크래치"로 레이블을 지정하면 일관성이 높아짐 --> 학습 알고리즘 작업 단순화

불확실성을 포착하기 위해 새로운 class/label 만들기 - 기존 스크래치 감지에서는 있다/없다 로 클래스를 나눴지만 중간의 모호성을 해결하고자 borderline 이라는 클래스를 추가
- 음성 인식에서는 [들리지 않음]이라는 클래스가 실제로 들리지 않을 수도, 이해하지 못할 수도 있기 때문에 새 클래스인 [이해할 수 없음]이라는 클래스를 추가하여 모호성 감소
Small data vs. big data(unstructured data)
Small data
- Usually small number of labelers.: 적은 수의 labelers
- Can ask labelers to discuss specific labels.: 일관된 label를 할당하도록 논의를 부탁할 수 있음
Big data - Get to consistent definition with a small group.: 소그룹으로 일관된 정의 얻기
- Then send labeling instructions to labelers.: 라벨링 지침을 labelers에게 보내기
- Can consider having multiple labelers label every example and using voting or consensus labels to increase accuracy.: 여러 레이블러가 모든 예제에 레이블을 지정하고 정확도를 높이기 위해 투표 또는 합의 레이블을 사용하는 것을 고려.
Human level performance(HLP)

비정형 데이터 작업의 경우 분석 및 우선 순위 지정을 돕고 가능한 것을 설정하는데 도움을 준다.
예제: 육안 검사
- 검사관이 4개를 맞추고 2개를 맞추지 못함 --> HLP: 66.7% --> 사업주가 느끼기에는 인간의 성능이 66.7%인데 어떻게 이거보다 더 높은 성능을 내지 라는 불확실성을 줄 수 밖에 없음
- 따라서 HLP는 가능한 것의 관점에서 기준선을 설정하는데 유용
여기서 잠깐: GT 라는 것이 실제로 가능한 것을 측정하는 것인지, 아니면 두 사람이 우연히 동의함을 측정하는 것인지?
- GT를 사람이 결정짓는 것이라면 HLP에 대해 다른 접근 방식 존재 --> Bayes 오류를 추정하고 분석하여 우선 순위 지정에 도움이 되도록 사용 가능
- 물론 HLP를 사용하여 ML 프로젝트가 이렇게 우수하다라는 것을 보여주고 싶겠지만 이거는 곧 기계 학습 시스템이 인간보다 우수하다는 것을 증명하는 것에 초점을 맞추어 진행되므로 너무 여기에 치중되지 않도록 주의하기
Other uses of HLP
- In academia, establish and beat a respectable benchmark to support publication.: 학계에서 출판을 지원하기 위해 존경할만한 벤치마크를 설정하고 이깁니다.
- Business or product owner asks for 99% accuracy. HLP helps establish a more reasonable target.: 사업주나 제품 소유자가 99% 정확도를 요구합니다. HLP는 보다 합리적인 목표를 설정하는 데 도움이 됩니다.
- "Prove" the ML system is superior to humans doing the job and thus the business or product owner should adopt it.: ML 시스템이 작업을 수행하는 사람보다 우수하다는 것을 "증명"하므로 비즈니스 또는 제품 소유자는 이를 채택해야 합니다.

- 실제로 측정하고 있는 것은 2명의 labelers가 동의할 가능성
- 실제로 레이블 지침에 따라서 첫번째 레이블 지침을 따르기만해도 0.58 --> 0.7% 정확도, 12%향상 되기 때문에 어떤 방식으로든 인간을 능가하지 않음
HLP는 일련의 baseline을 설정하는 데에 도움을 줄 수 있지만 이처럼 인간과 기계를 벤치마킹하는데 사용하면 때때로 이와 같은 부작용이 발생한다.
--> 따라서 무작정 HLP를 낮게 측정하고 우리의 제품은 HLP보다 높다는 것은 좋지 않은 선택이다. HLP를 높여서 가능한 정확도를 목표로 설정하여 진행하는 것이 좋음
Raising HLP

- Ground truth는 다른 인간이 붙인 label이기 때문에 정답이라고 보기 어려움
- 따라서 0.3mm라는 임계치를 설정하고 이 값을 기준으로 GT를 재설정하면 HLP 정확도는 100% 달성
Rasing HLP
- When the label y comes from a human label, HLP << 100% may indicate ambiguous labeling instructions.: 레이블 y가 사람 레이블에서 온 경우 HLP << 100%는 모호한 레이블 지정 지침을 나타낼 수 있습니다.
- Improving label consistency will raise HLP: 라벨 일관성을 개선하면 HLP가 높아집니다.
- This makes it harder for ML to beat HLP. But the more consistent lables will raise ML performance, which is ultimately likely to benefit the actual application performance.: 이것은 ML이 HLP를 이기기 어렵게 만듭니다. 그러나 보다 일관된 레이블은 ML 성능을 높여 궁극적으로 실제 애플리케이션 성능에 도움이 될 것입니다.
HLP
Structured data problems are less likely to involve human labelers, thus HLP is less frequently used.: 구조화된 데이터 문제는 사람이 라벨을 붙일 가능성이 적으므로 HLP가 덜 자주 사용됩니다.
Some exceptions:
- User ID merging: Same person?(ID 병합: 동일 인물인가?)
- Based on network traffic, is the computer hacked?(네트워크 트래픽을 기반으로 컴퓨터가 해킹되고 있는가?)
- Is the transaction fraudulent?(거래가 사기인가?)
- Spam account? Bot?(스팸 계정인가? 봇 계정인가?)
- From GPS, what is the mode of transportation - on foot, bike, car, bus?(GPS에서 볼 때 도보, 자전거, 자동차, 버스 중 이동 수단은 무엇입니까?)
정리
- HLP는 참조로 사용할 수 있는 문제에서 굉장히 유용&중요하다.
- HLP가 100%보다 낮다면 일관성 없는 labeling 지침을 따라 labeling 될 확률이 있으므로 확인해야 한다.
- 2에서 일관성이 없는 것이 밝혀졌다면 일관성 있는 labeling 방법에 따라 데이터를 수정한다.
이를 통해 더 깨끗한 데이터가 제공되어 궁극적으로 기계학습 알고리즘 성능이 향상될 수 있다.
Obtaining data: data 수집

- 데이터 수집에 있어서 소요 시간: 초기 데이터 세트를 수집하고 초기 모델을 훈련시킨 후 오류 분석을 수행하여 더 많은 데이터를 수집하는 것이 좋음(데이터 세트 수집에 너무 많은 시간을 할애하는 것은 좋지 않은 방법)
- 사용자 개인 정보를 존중하고 규제 고려 사항을 따르기
- 예외: 이 문제에 대해 작업한 적이 있고 경험을 통해 최소한 특정 train set 크기가 필요하다는 것을 알고 있는 경우, 그 정도의 데이터를 수집하기 위해 더 많은 노력을 미리 투자하는 것이 좋다.(이미 알고 있을 경우 데이터 수집에 있어서 좀 더 많은 시간을 투자해도 좋다 --> 이미 오류 분석을 통해 파악한 정보이기 때문)
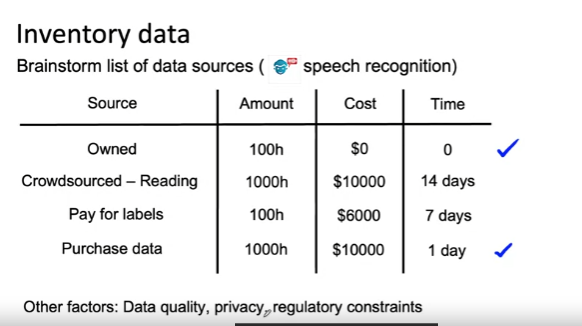
데이터 소스 목록 작성하기
예제: 음성 인식 시스템 - 100시간 분량의 녹음된 음성 데이터 소유 --> 비용 0
- 크라우드소싱 플랫폼 사용
- label 할당
- 데이터 구매
- 중요한 열은 바로 [Time]
- 소유한 데이터는 0
- 크라우드 소싱 플랫폼 찾기 + 소프트웨어 통합 2주
- 시간이 촉박한 경우 이 분석을 기반으로 이미 소유한 데이터와 데이터 구매를 통해 빠르게 진행 가능
Labeling data

-
labeling 수행: 회사 내 vs. 아웃소싱 vs. 크라우드소싱
-
MLE가 직접 labeling: 직관을 구축하는데 도움이 될 수 있지만 시간이 오래 걸릴 경우 오히려 좋지 않음
-
음성 인식 작업: 대부분의 사람이 오디오를 듣고 텍스트 전환 가능
-
공장 검사 또는 의료 이미지: 해당 분야에 전문적인 SME(Subject matter expert)rk wlsgod
-
추천 시스템: 좋은 레이블 할당이 어려움 --> 사용자의 구매 데이터를 하나의 레이블로 의존
-
Don't increase data by more than 10x at a time.: 한 번에 10배 이상 데이터를 늘리지 않기
- dataset 크기가 10배 이상으로 증가할 때 어떤 일이 일어날지 예측하기 어려움
- 데이터를 무식하게 많이 수집하는 것은 가장 유용한 방법이 아님!
Data pipeline(Data cascade): 데이터가 최종 출력에 도달하기 전에 여러 단계의 처리 단계를 거치는 경우

예: 특정 사용자가 일자리를 찾고 있는지 예측(y)하고 싶은 일부 사용자 정보(x)가 있다고 가정
흐름: raw data --pre-processing--> ML
- pre-processing은 여러 조각 코드로 구성될 수 있음
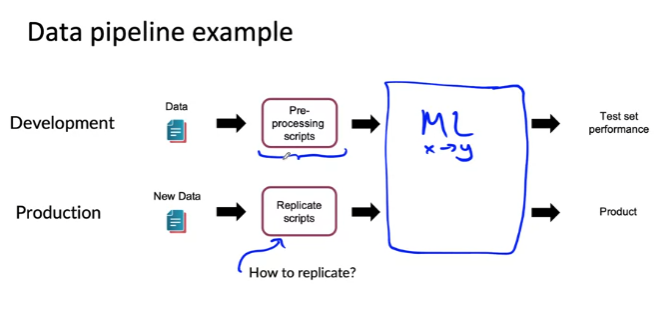
- 실제 배포할 때 동일한 ML에 입력이기 때문에 동일한 입력분포를 갖기 위해서는 development에서 사용한 그대로의 pre-processing을 진행하야 함. 따라서 복제가능성 여부가 매우 중요
POC and Production phases

POC(proof-of-concept):
- Goal is to decide if the application is workable and worth deploying.: 목표는 애플리케이션이 잘 작동하고 배포할 가치가 있는지 결정하는 것이다.
- Foucus on getting the prototype to work!: 프로토타입을 작동시키는데 집중하기
-It's okay if data pre-processing is manual. But take extensive notes/comments.: 데이터 전처리가 수동이면 괜찮습니다. 그러나 광범위한 메모/의견을 작성하십시오.
Production phase: - After project utility is established, use more sophisticated tools to make sure the data pipeline is replicable.: 프로젝트 유틸리티가 설정된 후 데이터 파이프라인이 복제 가능한지 확인하기 위해 보다 정교한 도구를 사용합니다.
Meta-data, data provenance and lineage: 메타 데이터, 데이터 출처 및 계보
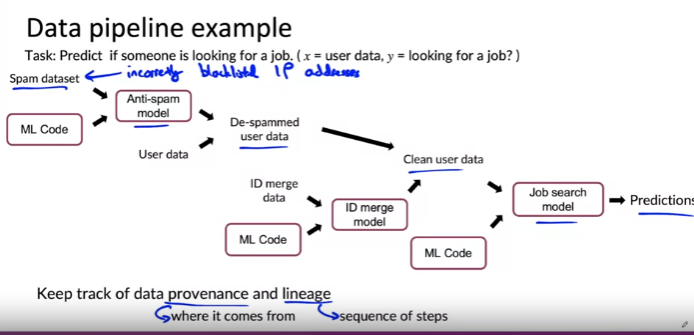
예제: 사용자 레코드를 사용하여 특정 시점에 누군가 일자리를 찾고 있는지 예측하는 시스템을 기반으로 하는 데이터 파이프라인 예
1. 스팸 데이터 세트로 시작한다고 가정
2. 스팸계정목록, 스팸발송자가 사용하는 블랙리스트 IP 주소 목록과 같은 FEATURE 포함
3. 학습 알고리즘, ML 코드 구현 및 훈련하여 스팸 방지 모델 제공 가능
4. 사용자 데이터를 입력 받아 스팸 방지 모델을 적용하여 De-spammed user data를 얻음
5. 다음으로 사용자 ID 병합 수행
6. 일부 ID 병합 데이터로 시작하여 ID 병합 모델 제공7.- ID 병합 모델에 De-spammed user data를 입력
8. clean user data를 얻음
9. clean user data를 Job search model에 입력하여 예측을 수행
- 이렇게 복잡한 데이터 파이프라인에서 만약 블랙리스트에 등록된 일부 IP 주소가 잘못되었다는 것을 발견하면?
--> 기업이나 학교는 IP 주소를 공유할 수 있지만 블랙리스트 또한 IP 주소를 공유할 수 있기 때문에 IP주소를 블랙리스트 주소로 오해하는 사건이 있었음 - 그러나 이렇게 복잡한 모델의 경우 데이터를 업데이트해도 스팸 모델, ID 병합 모델, 일자리 찾기 예측 모델은 변경되지 않음. --> 특히 여러 엔지니어에 의해 개발되고 파일이 분산되어 있는 경우 일이 더 커짐
--> 따라서 데이터 일부를 변경해야 할 때 시스템을 유지&관리하기 위해서는 데이터의 출처와 계보를 추적하는 것이 매우 유용
Meta-data

- 메타 데이터: 데이터에 대한 데이터
- 예: 제조 육안 검사에서 데이터는 스마트폰의 사진과 레이블이지만 메타 데이터는 사진을 찍은 시간, 사진을 찍은 공장, 라인 번호, 카메라 노출 시간, 카메라 조리개와 같은 카메라 설정, 검사중인 스마트폰 번호, 레이블을 제공한 검사관의 id 정보를 담음
- 이러한 메타데이터 정보를 미리 정리&저장 하지 않으면 추후에 다시 메타데이터를 저장할 때 훨씬 어려울 수 있음
- 오류 분석에 매우 유용하고 예상하지 못한 효과나 태그 또는 비정상적으로 성능이 좋지 않은 데이터 카테고리 또는 기타 항목을 찾아 시스템을 개선하는 방법 제안 가능
Balanced train/dev/test splits: 균형잡힌 train/dev/test splits
dataset이 작을 때 train, dev, test set 균형을 유지하면 ML 프로세스를 크게 개선할 수 있음

예: 제조 육안 검사
-
100개의 이미지(작은 dataset) = 30개의 positive samples, 70개의 negative samples
-
train:dev:test = 60%:20%:20%
- train: 21 positive samples --> 전체 데이터에서 30%만 positive
- dev: 2 positive samples --> 전체 데이터에서 10%만 positive
- test: 7 positive samples --> 전체 데이터에서 35%만 positive
- 매우 비균형적인 분할
- 따라서 다음과 같이
- train: 18 positive samples --> 전체 데이터에서 30%만 positive
- dev: 6 positive samples --> 전체 데이터에서 30%만 positive
- test: 6 positive samples --> 전체 데이터에서 30%만 positive
- 균형을 맞춘 분할을 진행하여 분포를 맞춰줌
-
큰 dataset의 경우 랜덤으로 분할해도 영향이 덜 하겠지만 소규모 dataset의 경우 균형잡힌 분할이 있는지 명시적으로 확인하면 학습 알고리즘 성능에 대해 보다 안정적인 측정이 가능함
What is scoping?
작업에 적합한 프로젝트 선택하기
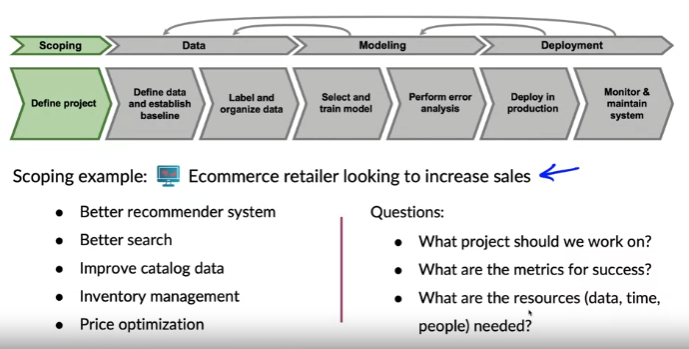
예제: 판매를 늘리려는 전자 상거래 소매업체
왼쪽: 다양한 아이디어
오른쪽: 가치 있는 프로젝트를 진행하기 위한 질문
Scoping process: 프로젝트의 카테고리를 지정하는 프로세스 공유
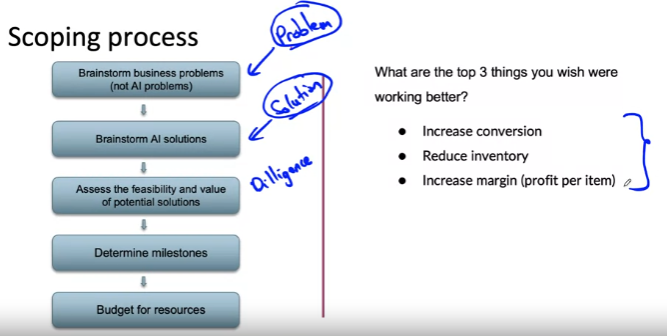
1. 비즈니스/애플리케이션 문제 브레인스토밍(인공지능 문제 식별하지 않음)
예: 웹사이트로 이동하여 판매로 전환, 사용자 증가
2. 1번을 해결하기 위한 AI 솔루션이 있는지 확인 및 브레인스토밍 --> 문제의 식별과 엔지니어로서 솔루션 식별을 분리하는 것이 좋음
3. 잠재적인 솔루션의 실현 가능성과 가치 평가: 기술적인 타당성과 가치를 검증
4. milestone 결정
5. 리소스와 예산 책정
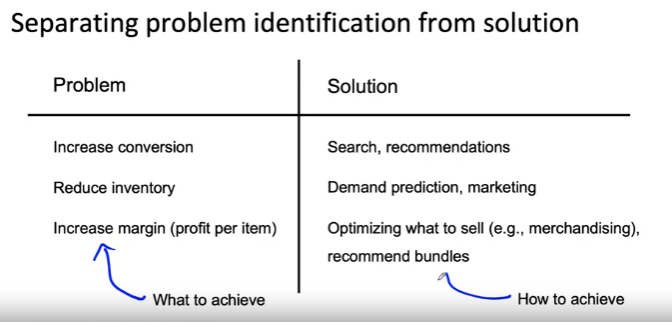
1. 전환율 높이기 --> 웹사이트 검색 결과 품질 개선, 구매 내역 기반 더 나은 제품 추천 제공
2. 재고 감소(창고에 있는 물건 판매) --> 사람들이 어떤 거를 구매하는지 잘 추정하기 위해 수요 예측 프로그램, 마케팅
3. 마진 증가 --> 기계학습을 사용하여 판매 대상 최적화, 판매할 가치가 있는 것과 없는 것을 구분하고 무엇을 판매할지 결정, 카메라 + 커버를 구매시켜 마진 증진 가능
- 문제 식별: 달성하고자 하는 것이 있는지 여부를 생각하는 단계
- 솔루션 식별: 이러한 목표를 달성하는 방법을 생각하는 프로세스
- 무작정 프로젝트에 뛰어들지 말고 많은 가능성을 브레인스토밍하는 것이 중요하다. 그 이후에 유망한 프로젝트를 하나 또는 소수로 좁혀나가야 한다.
Diligence on feasibility and value: 실현 가능성과 가치에 대한 근면
Feasibility: Is this project technically feasible?
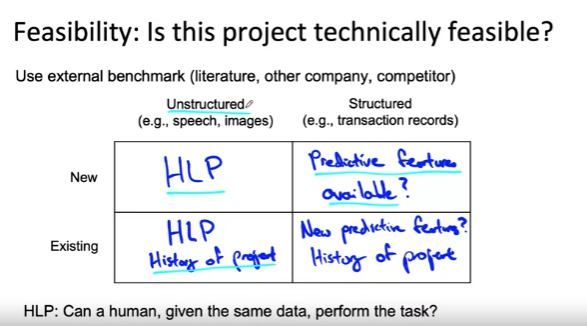
- 연구, 문헌, 기타 출판물과 같은 외부 벤치마크 사용
- 가로축 비정형/정형 데이터
- 세로축: 새로운 프로젝트/이미 존재하는 프로젝트
- 비정형 데이터 중 새로운 프로젝트: HLP를 기반으로 프로젝트가 가능한지 여부에 대한 초기 감각 제공
- 비정형 데이터 중 이미 존재하는 프로젝트: HLP를 기반으로 사용. 프로젝트 이전의 진행력을 기반으로 미래 진행 상황을 예측할 수 있음
- 정형 데이터 중 새로운 프로젝트: 예측 기능을 사용할 수 있는가? input x로부터 분명한 output y를 예측할 수 있는가?
- 정형 데이터 중 이미 존재하는 프로젝트: 예측을 도울 수 있는 새로운 feature 추가

비정형 데이터 예제: 자율 주행 자동차 제작 중 신호등이 빨강/노랑/녹색인지 분류하는 알고리즘
- 왼쪽: 어디에 불이 들어와 있는지 명확하게 확인 가능
- 오른쪽: 어디에 불이 들어와 있는지 확인 불가
- (중요)HLP 벤치마크는 따라서 학습 알고리즘과 동일한 데이터만 제공하도록 해야 함.

구조화된 데이터 예제: y를 예측할 수 있는 input feature x가 있는가?
- 사용자 과거 구매 내역으로 향후 구매 내역 예측 --> 가능
- 날씨 정보로 쇼핑몰의 유동 인구 예측 --> 가능
- 개인 DNA로 개인이 심장병에 걸릴지 예측 --> 유전과 건강 상태로 매핑은 어려움 --> 불가능하지 않지만 복잡하고 비교적 명확하지 않음
- 소셜 미디어 채팅으로 의상 스타일 예측 --> 불가능하지는 않지만 어려움
- 주식의 과거 이력을 보고 미래 가격 예측 --> 불가능
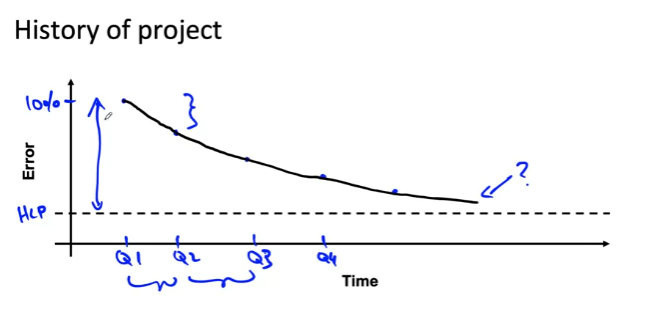
- 프로젝트의 역사
- 과거 프로젝트 개선 속도를 기반으로 미래의 프로젝트 개선 속도를 예측할 수 있음
- 분기별 진행률을 추정함으로써 프로젝트의 향후 진행 속도에 대해 합리적으로 추측 가능하며 이를 통해 기존 프로젝트에 대해 실현 가능성을 파악할 수 있음
Dilligence on value

예제: 음성 인식 시스템 구축
대부분의 비즈니스에서는 기계학습 엔지니어가 최적하하는데 사용하는 메트릭과 비즈니스 소유자가 최대화하려는 일부 메트릭이 있음(왼쪽으로 갈 수록 MLE가 편해지고 오른쪽으로 갈 수록 비즈니스 소유자가 원하는 것)
- MLE 메트릭
- Word-level accuracy: 단어 수준의 좋은 정확도를 얻으려는데 익숙함
- 비즈니스 오너
- Query-level accuracy:사용자 경험에 기반하여 중요한 쿼리를 올바르게 파악 --> 사용자가 중요하게 여기는 부분에 초점(검색 결과)
- Search result quality: 결과의 품질을 높여
- User engagement: 더 많은 사람이 검색 엔진을 더 자주 방문하기를 원하기 때문
- Revenue: 비즈니스 수익 창출
두 차이 간의 타협이 필요함
- 타협 방법: word-level 정확도가 올라갔을 때, query-level 정확도가 향상될 것이며 검색 결과 품질과 사용자 참여 및 수익이 얼마나 향상될 것인지 대략적으로 추측

윤리적 고려사항: 경제적이더라도 윤리적으로, 사회적으로 도움이 될 수 없다면 하지 않는 것을 추천한다. 사람을 돕고 인류를 발전시키는데 도움이 되는 프로젝트에만 노력할 수 있도록 하자
- 프로젝트가 사회적 가치를 만들어 내는가?
- 프로젝트가 공정하고 편향으로부터 자유로운가?
- 윤리적 문제를 공개적으로 토론했는가?
Milestones and resourcing
문제를 식별하고 가치 있는 솔루션을 찾았고 기술적 타당성과 가치에 대한 확신이 생겼다고 가정한 후 마지막 단계
Milestones & Resourcing
Key spcifications:
- ML metrics(accuracy, precision/recall, etc.)
- Software metrics(latency, throughput, etc. given computer resourcese)
- Business metrics(revene, etc,)
- Resources needed (data, personnel, help from other teams)
- Timeline
If unsure, consider benchmarking to other projects, or building a POC first.
6개의 댓글

Identify the key challenges in model development.
Describe how performance on a small set of disproportionately important examples may be more crucial than performance on the majority of examples.
Explain how rare classes in your training data can affect performance.
Define three ways of establishing a baseline for your performance.
Define structured vs. unstructured data.
Identify when to consider deployment constraints when choosing a model.
List the steps involved in getting started with ML modeling.
Describe the iterative process for error analysis.
Identify the key factors in deciding what to prioritize when working to improve model accuracy.
Describe methods you might use for data augmentation given audio data vs. image data.
Explain the problems you can have training on a highly skewed dataset.
Identify a use case in which adding more data to your training dataset could actually hurt performance.
Describe the key components of experiment tracking.
List the questions you need to answer in the process of data definition.
Compare and contrast the types of data problems you need to solve for structured vs. unstructured and big vs. small data.
Explain why label consistency is important and how you can improve it
Explain why beating human level performance is not always indicative of success of an ML model.
Make a case for improving human level performance rather than beating it.
Identify how much training data you should gather given time and resource constraints.
Describe the key steps in a data pipeline.
Compare and contrast the proof of concept vs. production phases on an ML project.
Explain the importance of keeping track of data provenance and lineage.
Identify the key components of the ML Lifecycle.
Define “concept drift” as it relates to ML projects.
Differentiate between shadow, canary, and blue-green deployment scenarios in the context of varying degrees of automation.
Compare and contrast the ML modeling iterative cycle with the cycle for deployment of ML products.
List the typical metrics you might track to monitor concept drift.