Transformer
1. Transformer Architecture - Encoder and Decoder
(1) Transformer가 없던 시절 자연어처리 모델의 한계점
-
RNN
- 입력 시퀀스는 일대일 방식으로 출력 시퀀스로 변환
- 특정 입력은 번역 문제 또는 자동 완성 문제를 찾기 위해 출력에 매핑
- 응용: 기계 번역, 요약, 질문 응답, 대화 모델링 자동 완성 등
- Feed-forward network의 단순 RNN
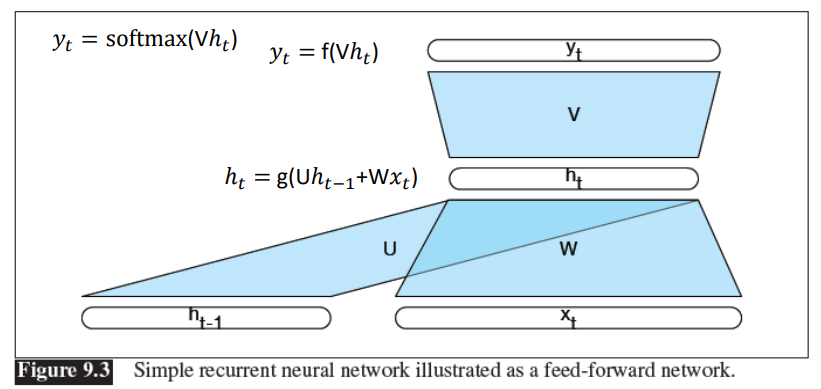
- ht-1: 이전 히든스테이트 --> 이전 정보
- xt: 입력 데이터(샘플 데이터) --> 현재 정보
- ht: 현재 히든 스테이트 --> ht-1 과 xt의 정보
- v: 벡터 ht를 입력으로 하는 피드포워드 신경망 - RNN 문제점
(1) Vanishing & Exploding Gradient
(2) 데이터 병렬 처리 불가 --> 한 번에 한 단어 또는 한문장 만을 전달함을 의미 - RNN 예시
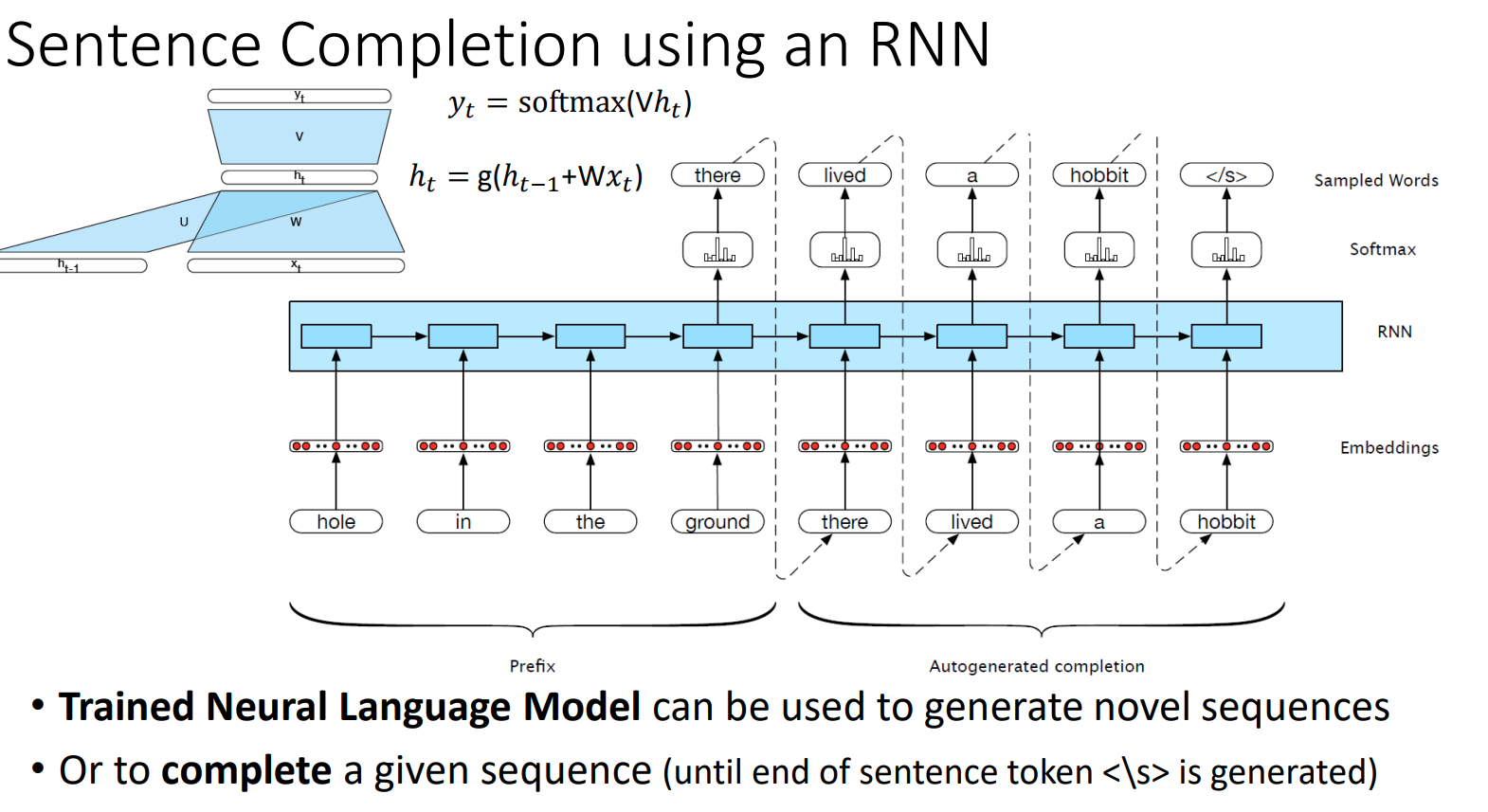
- autoregressive: 자기 회귀로 과거의 정보로부터 현재를 예측(시계열 데이터에서 사용) - Encoder Decoder
(1) Encoder
- x1:n이란 입력 시퀀스(입력 데이터)
- h1:n이란 hidden state로 상황에 맞는 표현의 해당 시퀀스를 의미하며 x1:n으로부터 출력되는 결과물(컨텍스트가 포함됨)
(2) Decoder
- h1:n으로부터 추출한 context vector c를 입력받음
- context vector로부터 적절한 출력 state y1:m을 생성
-
Transformer
- 등장 년도: 2017
- 등장 배경: RNN에서 발생하는 병렬처리 불가 문제를 해결하고자 transformer 등장 --> Transformer는 모든 입력을 한 번에 전달할 수 있음을 의미
- High-level architecture
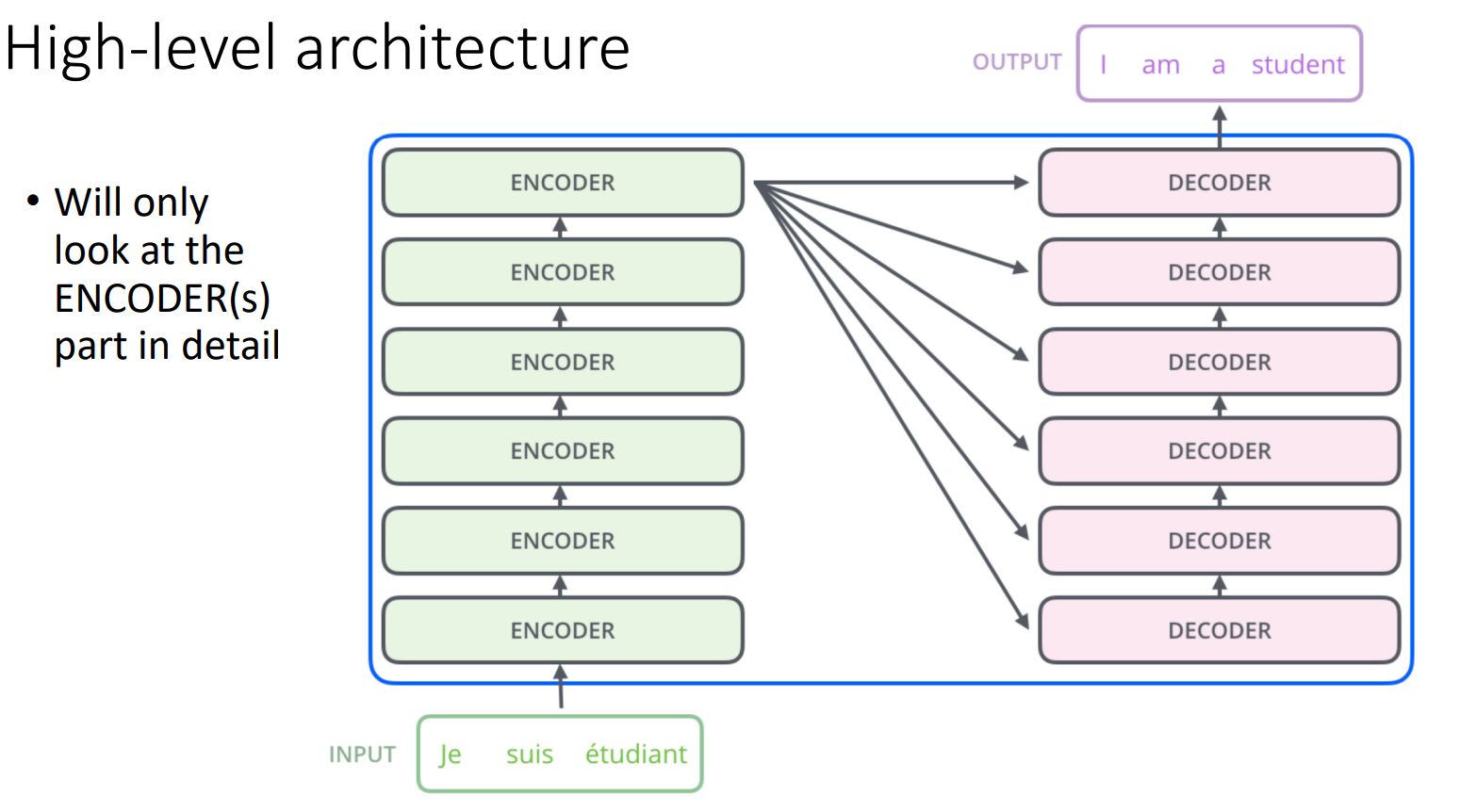
- 여러 인코더, 디코더 레이어가 있음
- 인코더의 최종 출력은 모든 디코더의 입력으로 들어감
- 인코더 구조
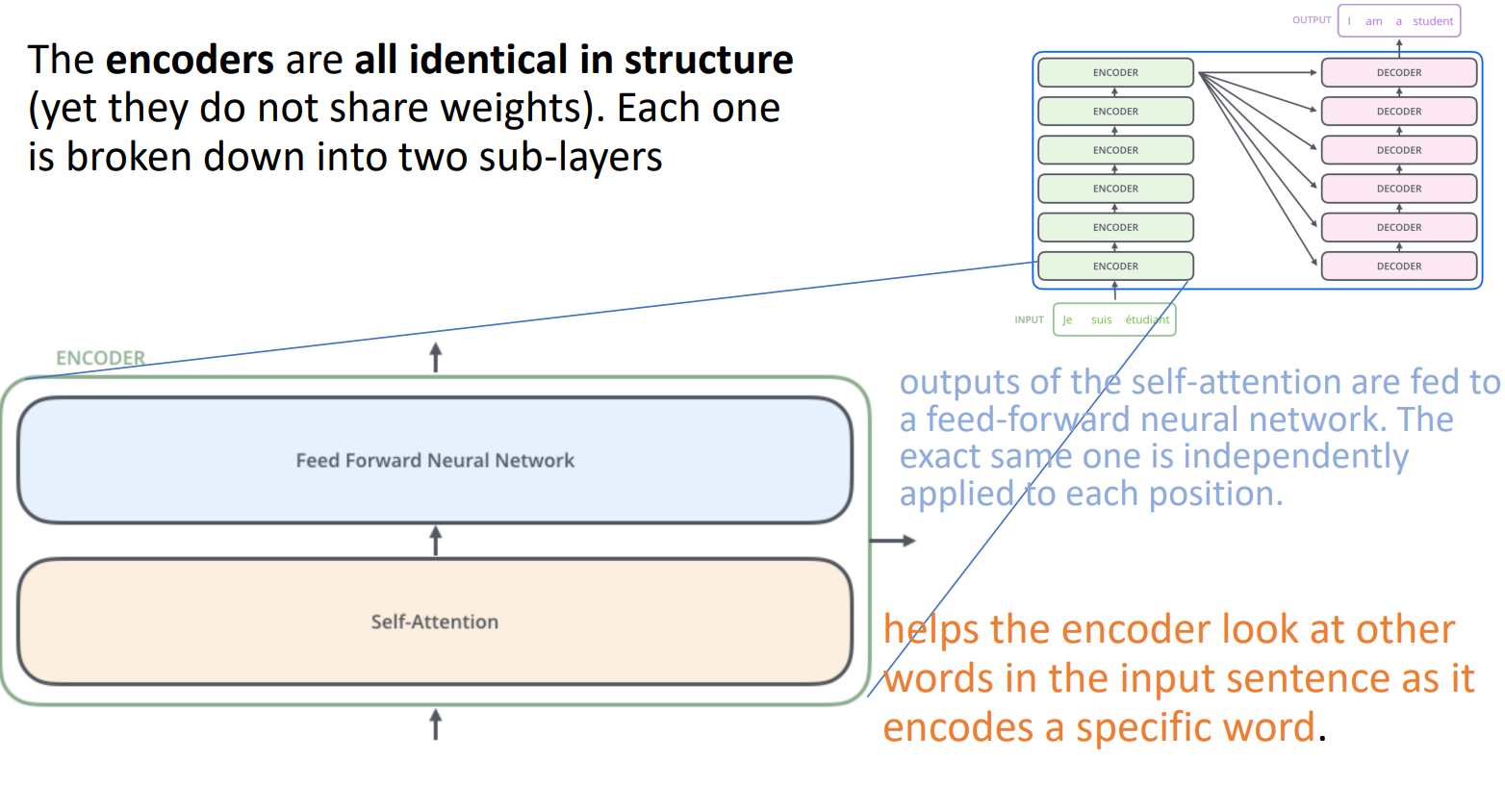
- 인코더 간에 가중치를 공유하지 않음(각각의 가중치를 학습)
- 인코더 = Self-Attention + Feed forward neural network
- self-attention 출력이 feed forward neural network의 입력으로 들어감
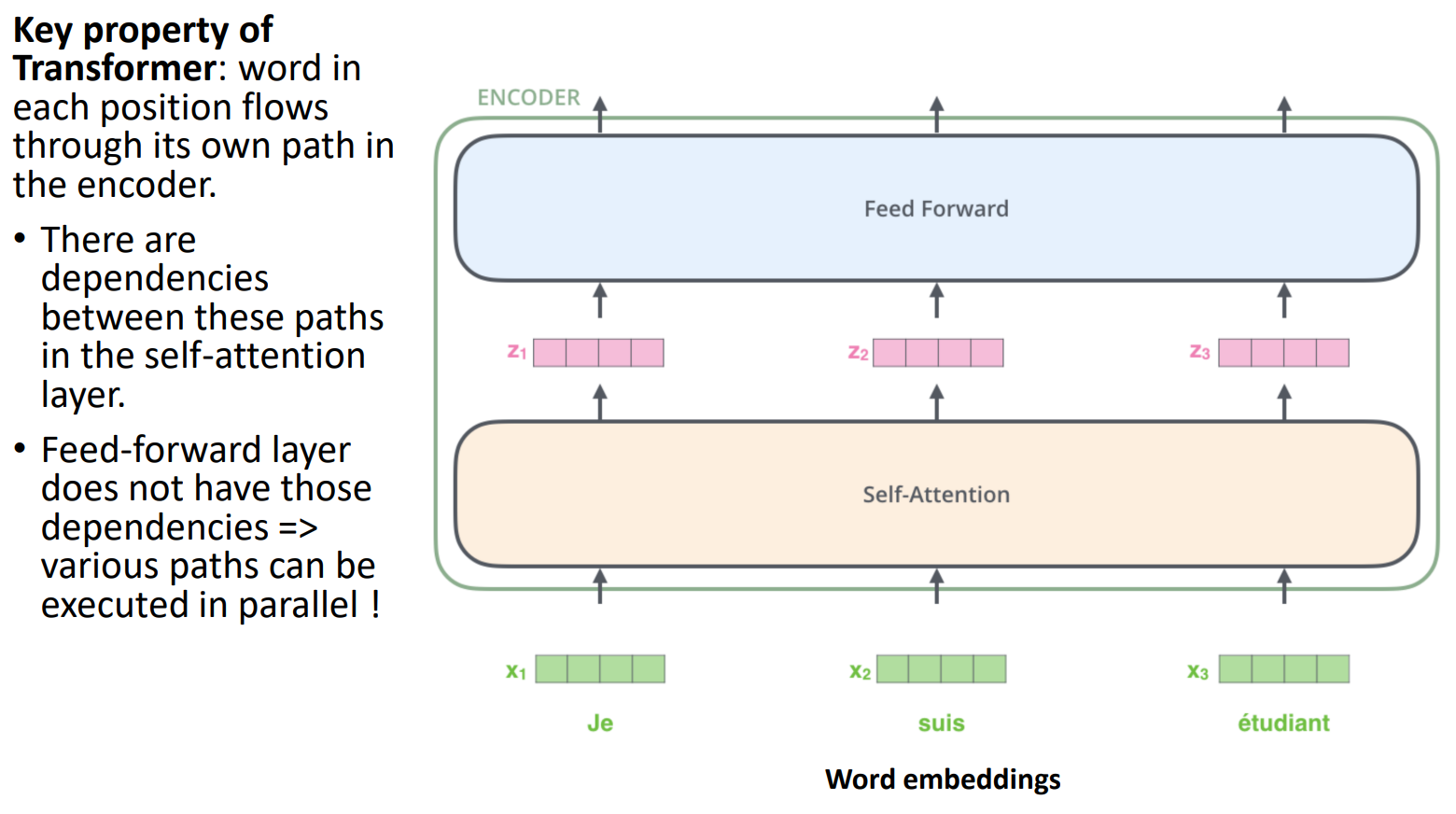
- 입력은 동시에 인코더로 전달됨
- self-attention 계층에서는 dependencies(종속성)를 파악하는 것이 목적(입력 간의 관계 파악)
- dependency: context 정보 때문에 x1이 어떤 방식이든 x2에 의존하는 것, x2는 x3에 의존하며, x3와 x1은 비교적 관계가 낮음
- feed forward에서는 종속성 없이 바로 병렬 처리(입력 사이의 유사성이나 관계 파악X)
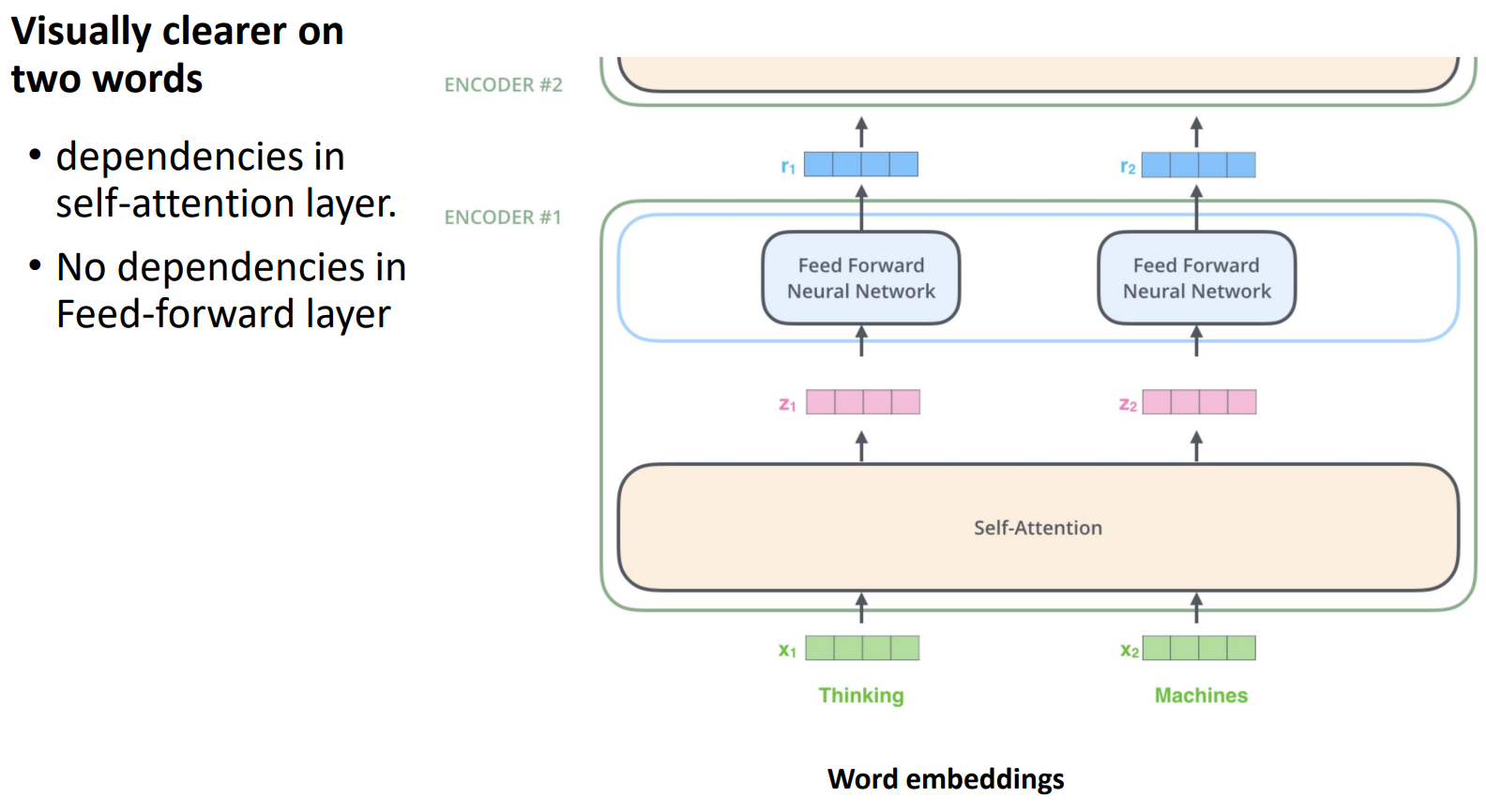
-
예시처럼 self-attention에서는 단어 간의 종속성을 파악하기 위해 한 번에 같이 처리한다면 feed forward는 관계 파악이 주 목적이 아니므로 병렬처리로 진행한다.
-
Self-Attention

- 각 단어를 처리
- 이 단어에 대한 더 나은 인코딩을 구축하기 위한 단서를 얻기 위해 시퀀스의 다른 위치 파악
- 준비물
(1) Query: 우리가 찾고자 하는 것
(2) Key: 쿼리에 대한 잠재적 솔루션
(3) Value: 키 뒤에 있는 실제 솔루션
출처: https://fastcampus.co.kr/data_online_transformer
FaceCampus Transformer 강의
