[논문리뷰] PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
논문 리뷰
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
요약
-
해결하고자 하는 문제: Metric space points 때문에 local 구조 포착이 어렵다. 그렇기 때문에 미세한 패턴을 인식하거나 복잡한 scene들에 대해 일반화가 어렵다.
-
해결 방법: Hierarchical neural network인 PointNet++로 해결한다. 부분적으로 나눈 입력 point set을 중첩시켜 재귀적으로 적용시킨다.
-
Euclidean space의 포인트 집합에 대한 분석에 관심이 많음.
-
특히 geometric point set cloud를 중요하게 보는데, point set cloud 순서에 따라 불변해야 한다.
-
distance metric은 다른 특징을 보여주는 local 이웃 정보를 정의한다. 이게 무슨 말이냐면 density나 다른 속성들은 여러 위치에서 균일하지 않을 수 있다.
-
pointnet의 한계
- 직접적으로 point set을 처리한다.- pointnet은 각 point의 공간을 인코딩하고 모든 point feature를 합친다. 이렇게 되면 모든 정보를 합쳐버리기 때문에 local 정보를 포착하기 어렵다. local 정보는 convolution 아키텍처의 성공에 중요한 것으로 입증되었기 때문에 local 정보를 놓치면 안 된다. CNN은 규칙적인 그리드로부터 정의된 데이터와 다양한 차원의 계층으로부터 특징을 포착할 수 있다.(커널 사이즈를 통해 multi-resolution)
- 즉, CNN처럼 계층적으로 local 패턴을 추출하는 능력은 보이지 않는 케이스에 대한 일반화에 더 좋다.
-
pointnet이 포착하지 못하는 local 정보를 포착하기 위해 hierarchical neural network인 pointnet++ 제안한다.
- 계층적 방법으로 metric space에서 point를 샘플링하여 처리- 기본적인 공간 거리 측정법을 사용하여 point set을 중첩시키는 local 영역으로 분할(CNN과 유사하게 작은 이웃들로부터 미세한 구조를 포착하는 lcoal features를 추출한다. 이런 local feature는 접접 큰 집합으로 구릅화되고 고수준 정보를 처리한다.)
- 이 처리는 모든 point set의 feature를 얻을 때까지 반복된다.
- 2가지 이슈
- point set 분할을 어떻게 생성할 지
- local feature 학습기로 local feature나 point의 set를 어떻게 추출할 것인지
- point set 분할을 어떻게 생성할 지
- 위 2가지 이슈는 서로 연관되어 있다. 왜냐하면 분할된 정보에서 구조를 만들어내야 한다. 때문에 CNN처럼 local feature learner의 weight를 공유할 수 있다.
- local feature learner로는 pointnet을 쓰는데 point net은 순서가 없는 point set을 처리하는데 용이하고 손상된 데이터에 강인하기 때문이다. point net을 사용함으로써 고수준 표현에서 local point나 feature를 추출한다. 이러한 관점에서 pointnet++는 중첩된 input set에 대해 pointnet을 반복적으로 적용한다.
- 남은 한 가지 이슈 point set으로부터 중첩된 분할은 어떻게 얻을 것인가?
- 분할은 중심 위치와 스케일이 포함된 파라미터를 갖는 Eudclidean 공간에서 이웃에 의해 정의된다.
- 전체 point set을 커버하기 위해 FPS 알고리즘으로 point set에 따라 중심을 선택해야 한다.
- 고정된 stride를 갖는 cnn과 다르게 pointnet++는 input 데이터와 측정에 의존하기 때문에 효율적이고 효과적이다.
- 분할은 중심 위치와 스케일이 포함된 파라미터를 갖는 Eudclidean 공간에서 이웃에 의해 정의된다.
요약
1. 해결하고자 하는 문제: 지역적인 구조를 포착하지 못하기 때문에 복잡한 장면의 일관성이 떨어지고 미세한 패턴을 인식하지 못한다.
2. 해결 방법: PointNet++(PointNet + CNN의 kernel 아이디어)
- Hierarchical 구조
- 입력 point set을 분할한 것을 중첩하는 과정을 반복적으로 적용
- multi scale로부터 feature combine
1. PointNet의 한계와 해결 아이디어
1.1. PointNet의 한계: local 정보 습득이 어려움
PointNet은 순서가 없는 point cloud로부터 불변한 결과를 출력하기 위해 max pooling을 사용한 후 모든 feature를 aggregate(하나로 모은다)한다. 그렇기 때문에 local 정보를 획득하기 어려운 점이 존재한다.
1.2. 해결 아이디어: CNN처럼 계층적으로 추출하면?
CNN은 kernel을 통해 input의 곳곳을 탐색하며 local 정보를 습득한다. CNN의 계층적 아이디어를 point set에 적용한다면 local region으로 분할하고 다시 중첩시키는 과정에서 고수준 정보를 추출하는 아이디어를 적용한 PointNet++ 아이디어로 해결하고자 한다.
2. PointNet++의 두 가지 이슈
2.1. 두 가지 이슈
1) point set을 어떻게 분할할까?
2) local feature learner로 point set이나 local feature set을 어떻게 추출할까?
두 가지 이슈는 서로 연관되어 있기 때문에 CNN처럼 weight를 공유하는 방법을 사용한다.
여기서 사용되는 local feature learner는 PointNet인데 PointNet을 사용하는 이유는 순서가 없는 point cloud에 대해 불변한 결과를 추출하기 때문이다.
2.2. 두 가지 이슈 외에 한 문제가 더 있다고..?
바로 overlapping partitioning을 어떻게 생성할 지이다. 쉽게 설명하자면 우리가 위 두 가지 이슈에서 point set을 나누는 작업을 진행했는데, 포인트 집합 간이 겹쳐질 수 있도록 설정하는 것을 말한다.
이렇게 되면 경계 영역에서도 충분한 정보를 얻을 수 있다.
그래서 각 파티션을 만들 때 Euclidean 공간에서 중심점과 특정 크기를 갖는 구(ball)로 정의한다.
이 때 각 구(파티션)의 중심점은 임의의 포인트를 선택한 후, 그 포인트에서 가장 먼 포인트를 선택하고 이 과정을 반복하여 중심점으로 삼는다. 이게 바로 FPS(Farthest Point Sampling)이다.
- FPS: 중심점은 모든 포인트에 대한 정보를 가지고 있어야 한다. 그렇기 때문에 임의로 한 포인트를 잡고 그 한 포인트에서 가장 먼 포인트를 잡는다. 그럼 또 그 포인트에서 가장 먼 포인트를 찾아 나아가면서 모든 포인트를 수용하는 중심점을 찾아가는 알고리즘이다.
2.3. 그럼 그 이웃 scale은 어떻게 설정할건데?
point cloud는 부분마다 density(밀도)가 다르다. 그렇기 때문에 CNN과 같이 고정된 kernel size, stride를 사용하게 되면 어느 부분은 density가 너무 높고, 어느 부분은 density가 낮을 수 있다. 이를 해결하기 위해
1) 다양한 크기(multi-scale)의 이웃을 사용한다.
2) random input dropout을 사용한다.
3. PointNet++
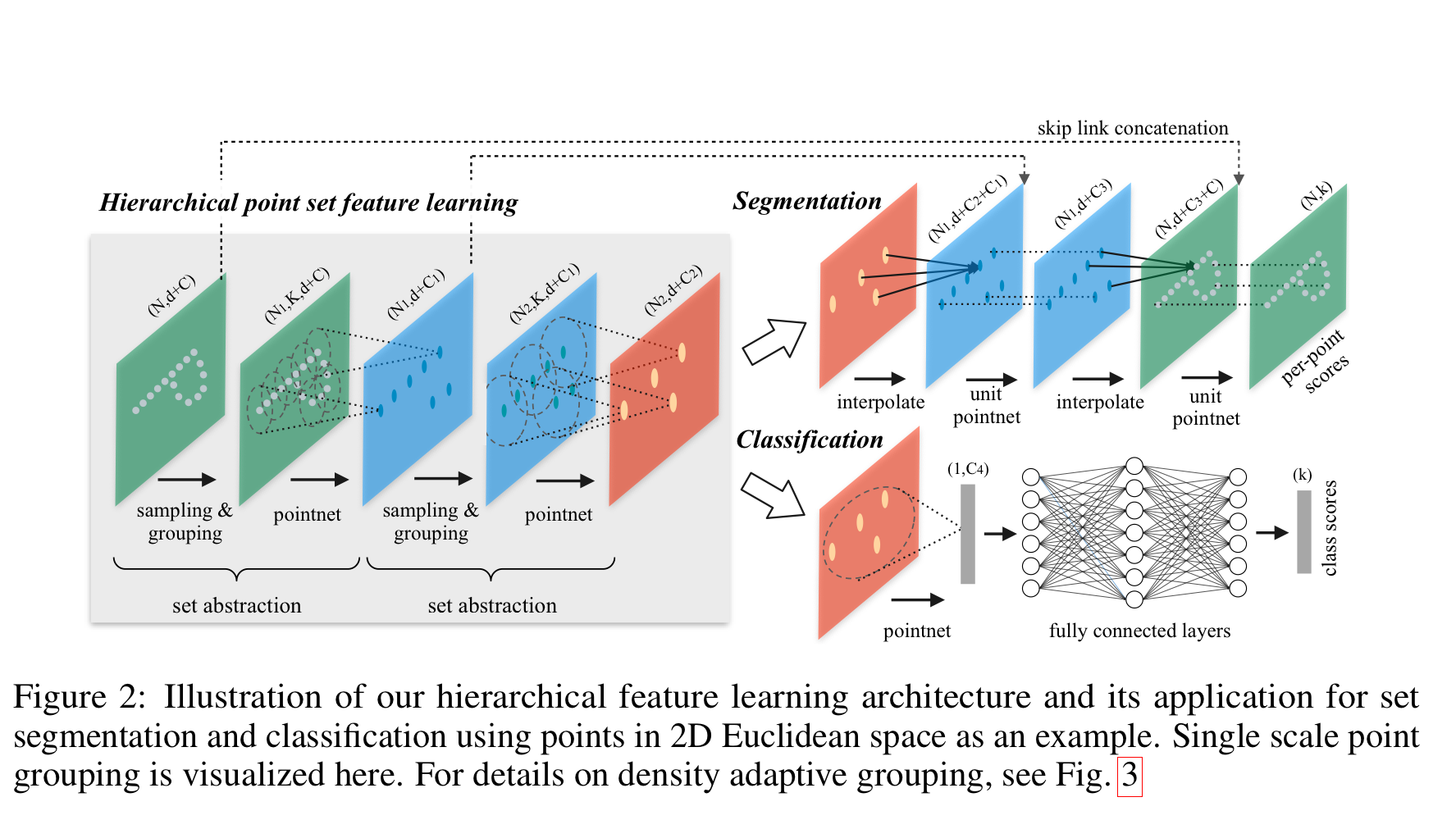
3.1. local feature learner로 PointNet 사용
PointNet은 규칙도 없고 순서도 없는 point cloud에 대해 불변한 결과물을 출력하기 때문에 learner로 사용한다.
그러나 PointNet은 local 정보 추출이 약하기 때문에 hierarchical layer를 사용하여 점점 더 큰 지역을 차례로 계산한다.
3.2. Hierarchical Point Set Feature Learning
- Sampling layer: 중심점 찾기
input point data에 FPS 알고리즘을 적용하여 중심점을 샘플링한다. 이렇게 되면 모든 데이터를 커버할 수 있는 중심점을 선택할 수 있다. - Grouping layer: 중심점을 기준으로 이웃 찾기
선택된 중심점들 주위의 이웃 점들을 모아 작은 그룹을 만든다. 이 때, 일정 반경 내에 있는 점들을 찾는 ball 쿼리나 가장 가까운 k개의 포인트를 찾는 kNN 알고리즘을 사용한다. - PointNet layer: 그룹에 대한 정보 추출 및 그룹 간 관계 학습하기
각 그룹을 처리하여 feature vector를 만들고 각 포인트의 좌표를 중심점에 상대적인 좌표로 변환하여 각 지역 그룹의 포인트 간의 관계를 학습한다.
3.3. Robust Feature Learning under Non-Uniform Sampling Density
Point set은 2D와 다르게 균일하지 않다는 특징이 있다. 그렇기 때문에 발생할 수 있는 문제가 density가 높은 부분으로 학습시키면 sparse한 공간에 대해 일반화되지 않을 수 있다. 그렇기 때문에 density가 다른 문제를 해결하는 adaptive point net layer인 PointNet++를 사용하여 해결한다.
3.3.1. Multi-Scale Grouping, MSG
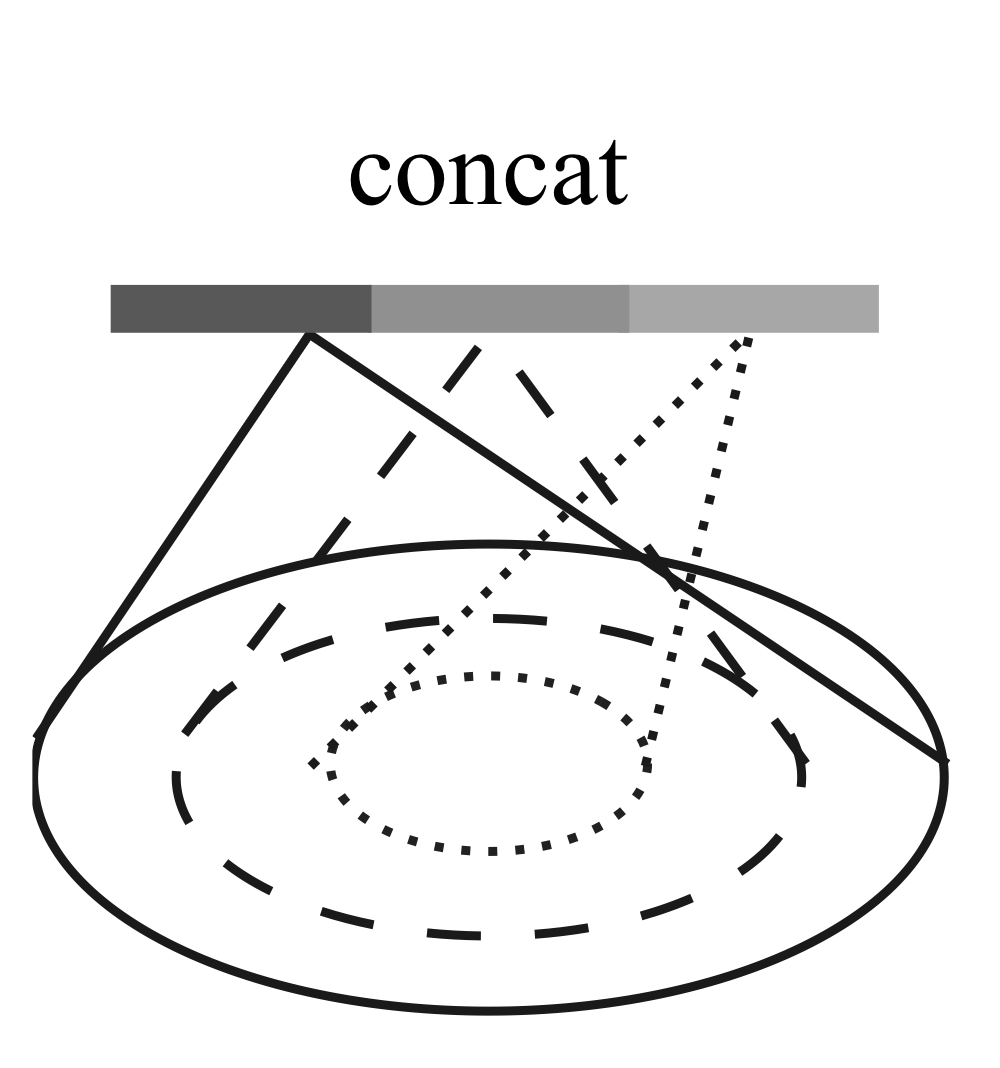
- 다양한 스케일로 점들을 그룹핑하고, 각 스케일에서 PointNet을 사용하여 특징 추출
- 여러 스케일에서 추출된 특징들을 결합하여 다중 스케일 특징 형성
- 훈련할 때 random input dropout하여 다양한 밀도와 균일성을 가진 데이터에 대해 네트워크가 강인하게 학습되도록 유도
3.3.2. Multi-Resolution Grouping, MRG
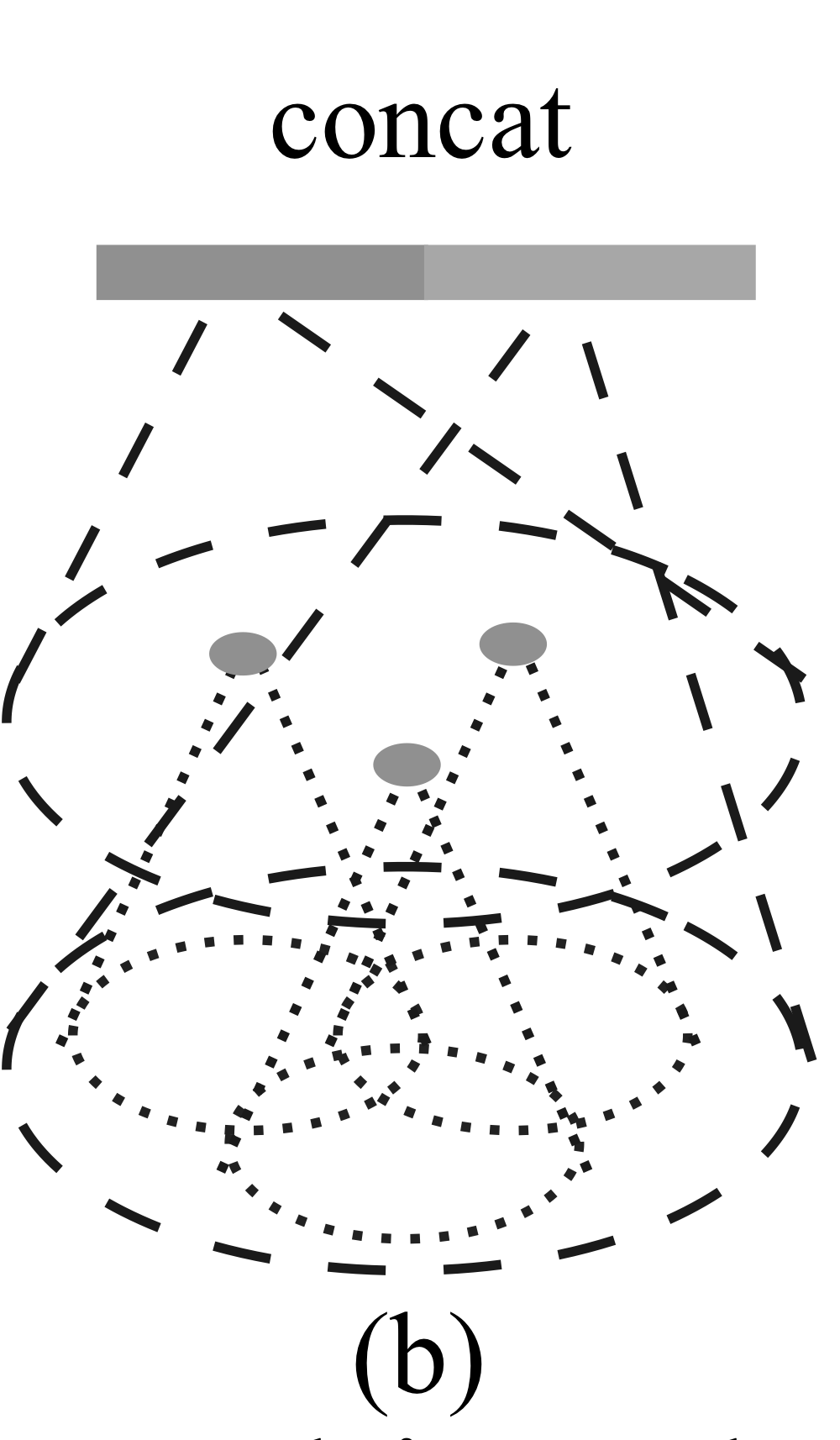
- 두 벡터를 사용
- 첫 번째 벡터: subregion에 대한 feature 요약 정보를 담은 특징 벡터(하위 수준)- 두 번째 벡터: 모든 점들을 직접 처리하여 얻은 특징 벡터
- 밀도가 낮은 경우 첫 번째 벡터보다 두 번째 벡터가 더 높은 신뢰도를 가져가게 되고, 밀도가 높은 경우는 첫 번째 벡터가 더 세밀한 정보를 제공할 수 있다.
- 그래서 두 벡터 사이에 density 기반 weight를 사용하여 조절하면 모든 density 정보를 처리할 수 있다.
3.4. Point Feature Propagation for Set Segmentation
지금까지 진행하면 point set에서 고수준 정보를 추출한다. 그런데 이 때 발생하는 문제점은 내가 만약 point에 label을 붙여 segmentation task를 진행하고 싶다면 이미 압축된 point 정보로는 진행할 수 없다. 다시 말해 기존, 원래의 모든 점들에 대한 특징을 얻어야 한다. 그러나 모든 점을 샘플링하게 되면 계산 비용이 매우 높아진다.
이를 해결하기 위해 interpolation과 unit PointNet을 사용한다.
즉, subsampling된 점들을 interpolation을 통해 원래 점으로 전파하고, unit pointnet을 사용하여 feature vector를 얻는 과정을 반복하여 원래 점 집합에 대한 특징을 얻는다. 또한 skip connection을 통해 원본 점 정보까지 더해지며 최종 원래 점 집합에 대한 특징을 추출한다.
이를 통해 segmentation과 같은 task를 수행한다.
리마인드
방법론 위주로 정리한 PointNet++는 PointNet이 local 정보를 추출하지 못한다는 한계를 해결하기 위해 hierarchical 방법론을 적용하여 local 정보를 추출한다. centroid를 찾고, 그룹화하고, 그룹의 정보와 그룹 사이 정보를 추출한다. 특히, point set이 다양한 density를 가지고 있기 때문에 이를 해결하기 위해 multi-scale 방법을 사용하며 연산량을 줄이기 위해 MSR(하위 수준+전체 점) 방법을 사용한다.
이런 과정을 거쳤을 때 다시 segmentation과 같은 작업을 하기 위해 interpolation하고 feature를 추출하기 위한 unit pointnet, skip connection을 통해 원본 점들에 대한 특징을 추출한다.
