
(2024, 08)

-
computer vision의 세 scenario(= single-image, multi-image, video scenarios) 를 처리할 수 있는 첫 open LMM.
-
LLaVA-OneVision은 각기 다른 modality/scenario에 걸쳐 transfer learning을 가능케 함.
-
image에서 video로의 task transfer를 통해 강력한 video understanding과 cross-scenario 능력을 보여줌.
Modeling
Network Architecture
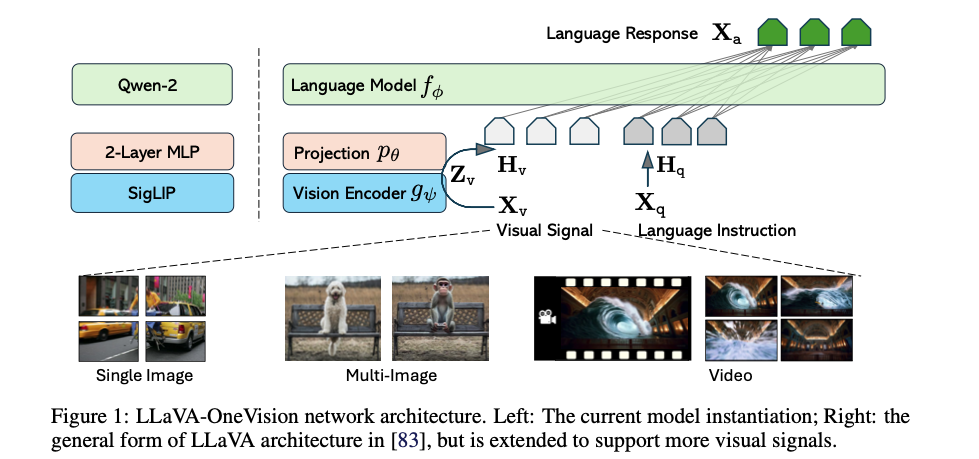
-
LLM parameterized by : Qwen-2
-
Vision Encoder parameterized by : SigLIP
-
Projector parameterized by : 2-layer MLP
-
모델 선택은 경험적으로
- stronger LLM이 multimodal capability가 더 strong 하기 때문.
- SigLIP는 open vision encoder 중에서 LMM 성능 더 좋음.
-
sequence of length 에 대해, target answer 의 probability를 아래와 같이 계산함.
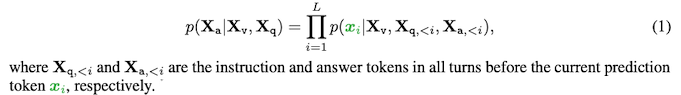
- Eq (1)에서 조건부 확률을 위해 를 명시적으로 추가하여, 모든 answer가 visual signal에 기반하고 있음(grounded)을 강조함.
- visual signal 의 form은 general 함.
- vision encoder에 입력되는 visual input은 대응되는 scenario에 따라 다름.
- single-image sequence에서는 개별 image crop,
- multi-image sequence에서는 개별 image
- video sequence에서는 개별 frame 사용.
Visual Representations
-
visual signal의 representation은 visual encoding의 성공에 있어 핵심적인 요소.
- 두 가지 요인과 관련됨: raw pixel space에서의 resolution과 feature space의 token 수
- visual input representation config (resolution, #token)
- performance와 cost 간의 balance를 위해선, 'resolution scaling'이 'token 수 scaling'보다 더 효과적임을 확인함.
- pooling을 활용한 AnyRes strategy를 권장.
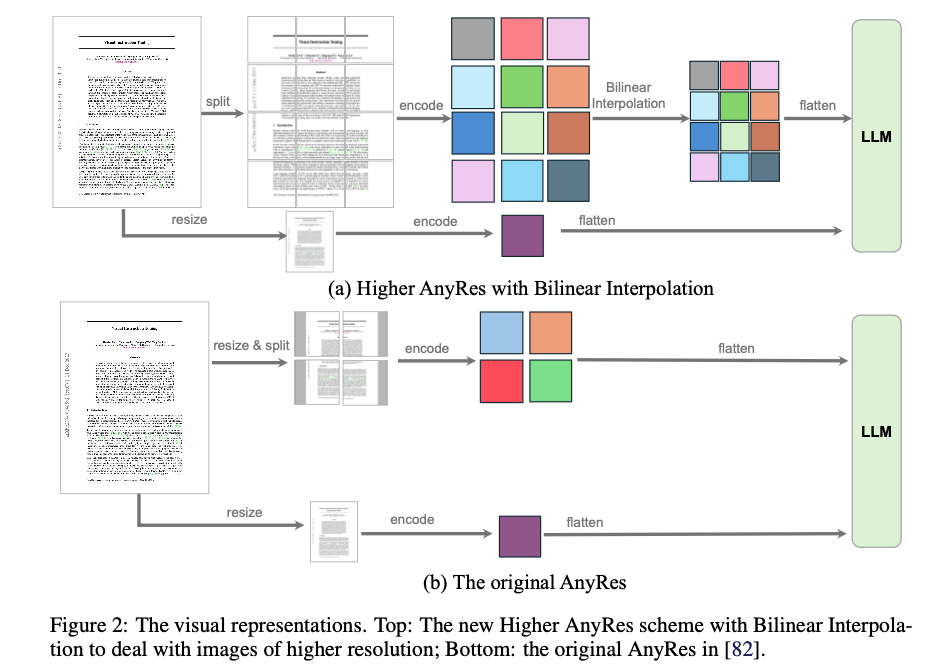
-
AnyRes strategy
-
width , height config의 AnyRes는 이미지를 crop들로 나누며,
각각 (a, b) 형태로 vision encoder에 suitable한 resolution을 가짐. -
crop당 개의 token이 있다고 가정하면, visual token의 총 개수는 .
- 이때, base image는 vision encoder에 입력되기 전에 resizing.
- 특정 threshold 를 고려해, 필요에 따라 bilinear interpolation을 통해 crop당 #token을 줄임. (Eq(2))
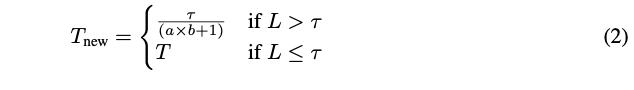
-
a set of spatial configurations (a, b)는 image를 cropping하는 방법을 정의.
다양한 resolution과 aspect ration를 가진 image를 수용.
이 중 minimum crop 개수가 필요한 구성을 선택함.
(자세한 ablation은 LLaVA-Next 논문 참고하라고 하네.)
-

-
제안된 Higher AnyRes strategy
-
multi-image와 video representation에 적응할 수 있는 유연한 visual representation framework 역할 가능.
- performance와 cost의 최적 config를 조정할 수 있으며, 위의 Figure 3에서 구성을 설명.
- Section C.1에서 세부 사항과 주요 encoding 전략을 제공.
-
single-image
- 원본 image resolution을 유지하기 위해 large maximum spatial configuration (a, b), resizing 없이 representation을 수행
- image당 많은 수의 visual tokens을 할당하여 visual signal을 효과적으로 나타내는 긴 sequence를 생성
- 이는 image가 video에 비해 다양한 instruction을 포함하는 고품질 training sample들이 더 많다는 관찰에 기반.
- 긴 sequence로 이미지를 표현하여 video understanding로의 capability transfer가 원활해지도록 함.
-
multi-image
- base image resolution만 고려되고 vision encoder에 입력되어 feature map을 얻으며,
high-resolution image의 multi-crop이 필요하지 않으므로 computational resources를 절약
- base image resolution만 고려되고 vision encoder에 입력되어 feature map을 얻으며,
-
video
- video의 각 frame은 base image resolution으로 resizing되며,
vision encoder를 통해 feature map으로 처리 - Bilinear interpolation을 통해 token 수를 줄여 frame당 tokens 수를 감소시키며, 더 많은 frame을 고려할 수 있음.
- video의 각 frame은 base image resolution으로 resizing되며,
-
이 representation configuration은 실험에서 고정된 compute budget으로 capability transfer를 목표로 설계됨.
-
더 많은 computational resources가 제공된다면, training 및 inference 단계에서 image 또는 frame당 token 수를 증가시켜 성능을 향상 가능.
-
Related Works
-
SoTA proprietary LMMs
- GPT-4V [109], GPT-4o [110], Gemini [131], Claude-3.5 [3]과 같은 SoTA proprietary LMM은
single-image, multi-image, video settings을 포함한 다양한 vision scenario에서 뛰어난 성능을 보임.
- GPT-4V [109], GPT-4o [110], Gemini [131], Claude-3.5 [3]과 같은 SoTA proprietary LMM은
-
Open source LMMs
-
반면, open research 커뮤니티에서는 일반적으로 각 scenario에 맞춘 모델을 개별적으로 개발하는 경향.
- 대부분의 연구는 single-image scenario에서의 성능 한계를 확장하는 데 중점
- 최근에서야 일부 논문이 multi-image scenario를 탐구하기 시작
- video LMM은 video understanding에서 우수한 성능을 발휘하지만, 종종 image 성능을 희생해야 하는 경우가 많음.
- 모든 세 scenario에서 우수한 성능을 보고하는 단일 open 모델은 드문 상황
-
LLaVA-OneVision은 다양한 작업에 걸쳐 SoTA 성능을 보여주고,
cross-scenario task transfer와 composition을 통해 새로운 기능을 선보이며 이 공백을 메우는 것을 목표로 함. -
현재까지 알려진 바로는, LLaVA-NeXT-Interleave [68]가 세 가지 vision scenario 모두에서 우수한 성능을 보고한 첫 시도.
- LLaVA-OneVision은 성능 향상을 위해 이 모델의 training recipe와 data를 계승함.
-
뛰어난 성능 잠재력을 가진 다른 versatile(다목적) open LMM으로는 VILA [77], InternLM-XComposer-2.5 [162]가 있음.
- 다만, 이들의 결과는 완전히 평가 및 보고되지 않아, 실험에서 이들과 비교를 수행함.
-
large-scale high-quality data training 사용
(model-synthesized knowledge와 다양한 instruction tuning data)- model-synthesized knowledge의 경우, LLaVA-NeXT 의 모든 지식 학습 데이터를 계승.
- instruction tuning data의 경우 FLAN에서 영감을 받음.
- 데이터 수집 과정은 Idefics2 [63]와 Cambrian-1 [133]에 비해 더 작은 규모지만 신중하게 선별된 데이터셋 모음에 집중.
-
이와 유사하게, 방대한 visual instruction tuning data가 성능을 크게 향상시킬 수 있음을 확인함.
-
