데브원영님의 인프런 아파치 카프카 강의를 듣고 학습 정리
아파치 kafka
카프카는 유연한 queue 역할을 한다.
고가용성- 서버에 이슈가 생기거나 갑자기 렉이 내려가도 데이터를 복구할 수 있다.
낮은 지연, 높은 처리량
Topic?
-
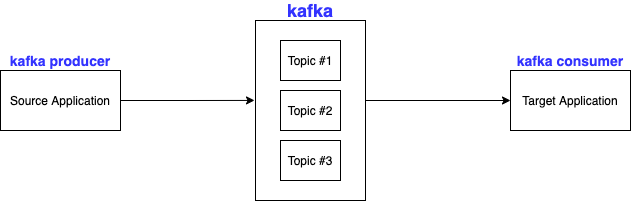
데이터가 들어가는 공간
-
producer가 Topic에 데이터를 넣으면 consumer가 가져가는 구조
-
Topic을 naming할 수 있는데 어떤 데이터를 담을지 명시하는게 좋다. ex) click_log, send_sms, location_log
-
partition 파티션
-
producer는 topic의 partition에 데이터를 차곡차곡 쌓고, consumer는 이 데이터를 오래된 순서대로 가져가서 처리한다. 이때, consumer가 record를 가져가도 데이터는 삭제되지 않는다. 즉, 파티션에 그대로 남게 되는 것.
새로운 컨슈머가 붙게 되면 이 데이터를 다시 가져다가 쓸 수 있다. 단, 새로운 컨슈머는 컨슈머 그룹이 달라야하고
auto.offset.reset=earliest여야 한다. -
producer가 데이터를 kafka로 보낼 때, key를 지정할 수 있다.
- key가 null 이고 기본 파티셔너를 사용하는 경우
- 라운드 로빈으로 할당
- key 값이 있고 기본 파티셔너를 사용하는 경우
- 키의 hash값을 구하고 특정 파티션에 할당한다.
- key가 null 이고 기본 파티셔너를 사용하는 경우
-
파티션을 늘릴 수는 있지만 줄일 수는 없기 때문에 주의해야한다.
-
파티션을 늘리면 컨슈머의 개수를 늘려서 데이터 처리를 분산시킬 수 있다.
-
파티션의 데이터가 삭제되는 시점은 옵션으로 지정할 수 있다. 레코드가 저장되는 최대 시간과 크기를 지정할 수 있다.
- log.retention.ms: 최대 record 보존 시간
- log.retention.byte: 최대 record 보존 크기 (byte)
-
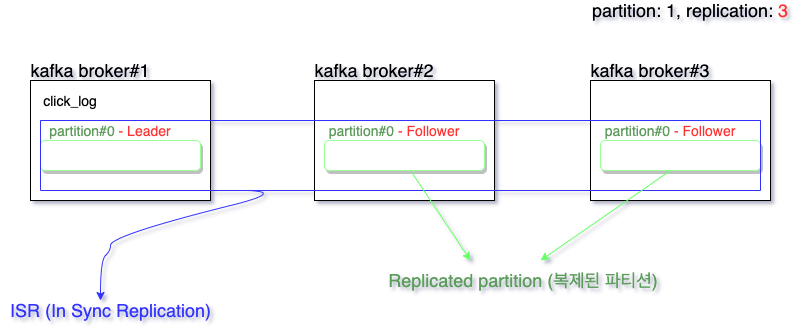
Broker, replication(복제), ISR(In-Sync-Replication)
-
kafka broker
- 카프카가 설치되어 있는 서버 단위
- 보통 3개 이상의 브로커로 구성하는 걸 권장한다.
-
replication
-
replication: 2 -> partition은 원본 1개와 복제본 1개라는 뜻, 총 partition의 개수 2.
-
원본 partition은 Leader partition, 복제본은 Follower partition이라고 한다.
-> Leader partition과 Follower partition을 합쳐서 ISR (In Sync Replication)이라고 한다.
-
replication 사용 이유?
- 파티션의 고가용성을 위해 사용된다.
-
producer가 데이터를 전달할 때, Leader partition이 데이터를 전달받는다.
-
-
ack 옵션
- producer가 갖는 옵션, ack를 통해 고가용성을 유지할 수 있다.
ack=0인 경우- 프로듀서는 Leader partition에 데이터를 전송하고, 응답값을 받지 않는다.
- 데이터가 정상적으로 전송되었는지와 나머지 partition에 정상적으로 복제되었는지 알 수 없다.
- 속도는 빠르지만 데이터 유실 가능성이 있다.
ack=1인 경우- 프로듀서는 Leader partition에 데이터를 전송하고 Leader partition이 데이터를 잘 받았는지 응답값을 받는다.
- 나머지 partition에 정상적으로 복제되었는지는 알 수 없다.
- 데이터 유실 가능성이 있다.
ack=all인 경우- Leader partition이 데이터를 잘 받았는지 응답값을 받고 Follwer partition에도 잘 복제가 되었는지 응답값을 받는다.
- 데이터 유실 가능성은 없지만 속도가 느리다.
-
replication이 많다고 무조건 좋은 것은 아니다. 브로커의 리소스 사용량도 늘어나게 된다.