
인덱스
DB의 테이블에 데이터가 많을 때, 검색 속도를 향상시켜주기위해 사용
색인 / 목차
- 칼럼의 값과 해당 레코드가 저장된 주소를 키와 값의 쌍으로 인덱스를 만들어 두는 것
- 항상 정렬된 상태를 유지하기 때문에 원하는 값 탐색은 빠르지만 새로운 값 추가,삭제,수정을 하게 되면 쿼리문 실행 속도가 느려짐
- 정렬해놓은 컬럼 사본은 항상 최신의 정렬상태를 유지한다.
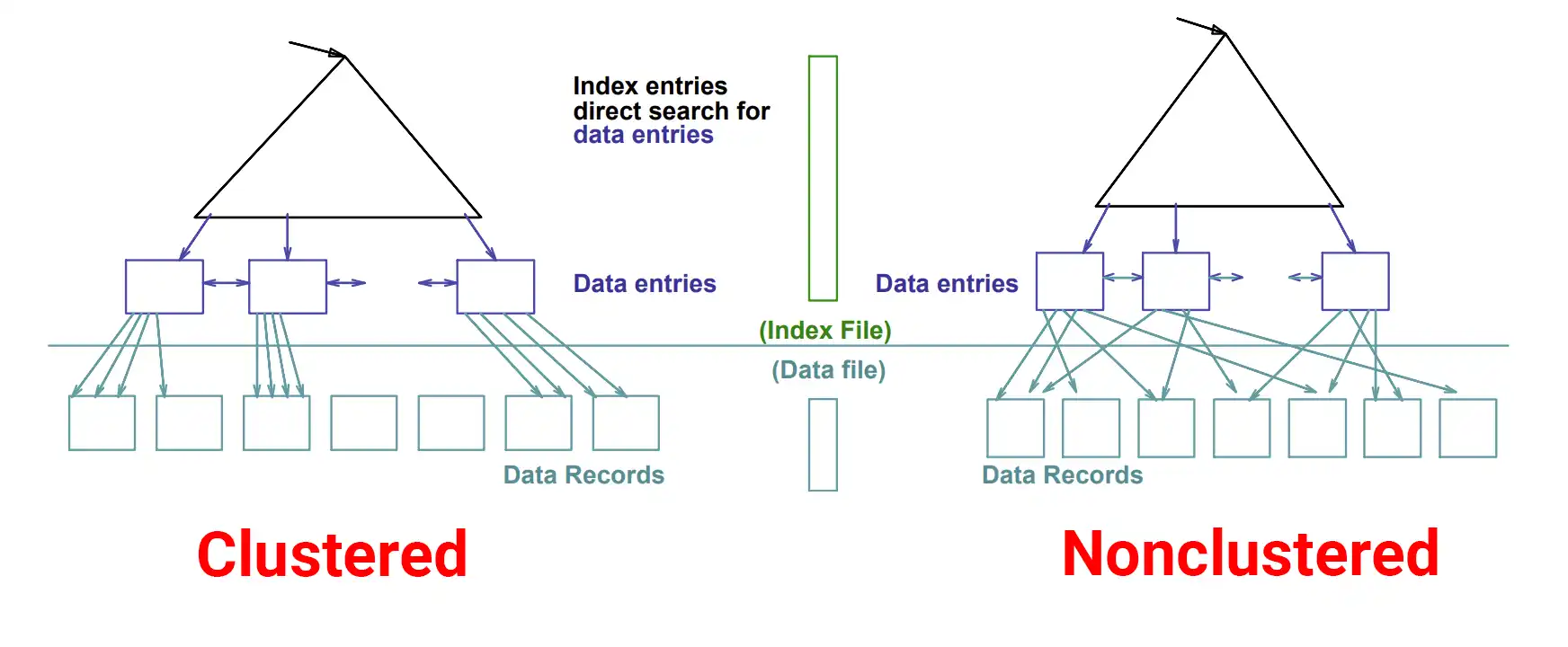
Clustered Index
특정 컬럼을 기준으로 데이터들을 정렬
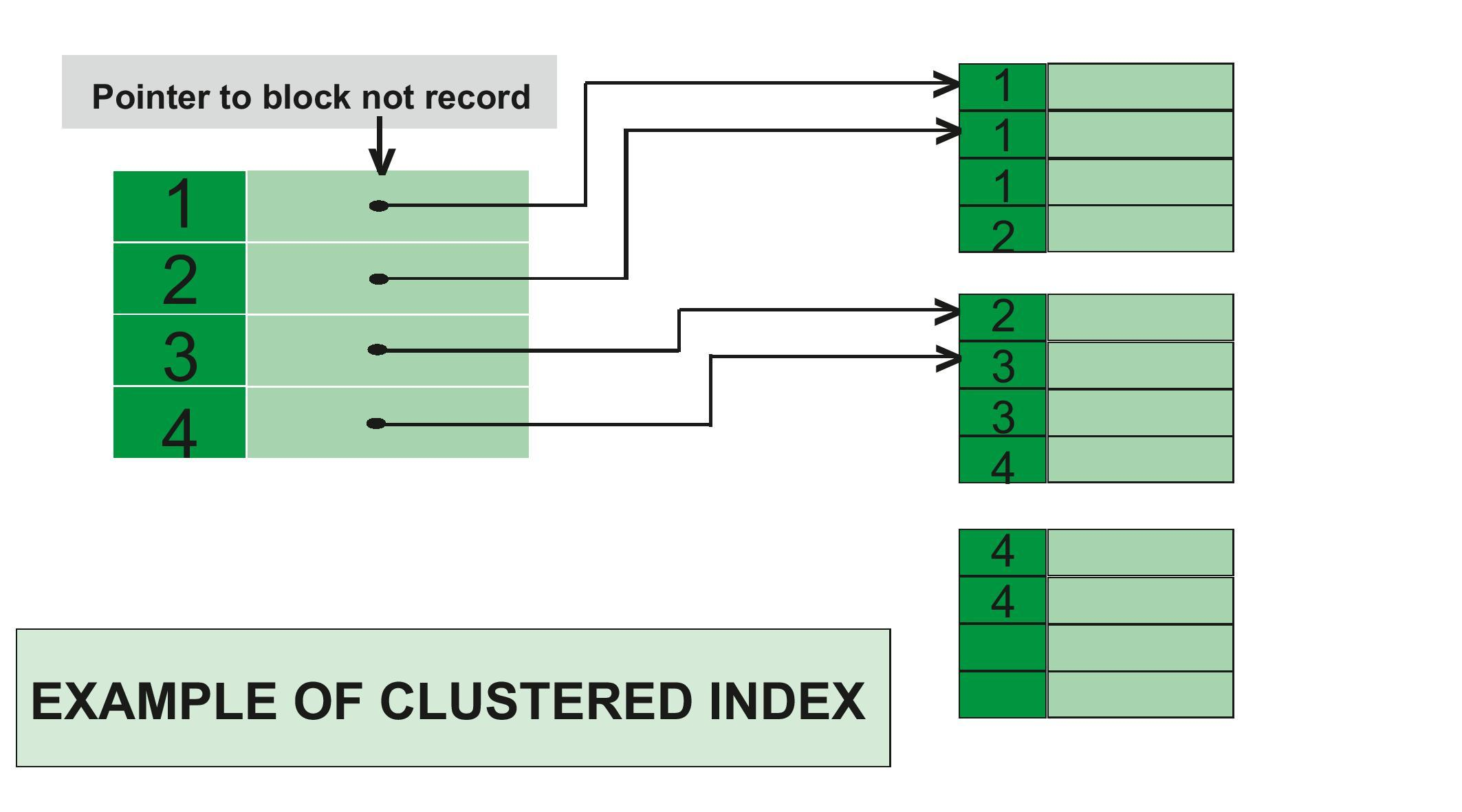
- PK키 값이 비슷한 레코드끼리 묶어서 저장
- PK키 값에 의해 레코드의 저장 위치가 결정 -> 키 값이 변경되면 레코드의 물리적인 저장 위치 또한 변경
- 아래 제약 조건 시 자동 생성
- Primary Key
- Unique + not null
- 어떤 열을 기본 키로 지정하면 그 열을 기준으로 자동 정렬
- 테이블 당 한 개만 가능
- 데이터가 테이블에 삽입되는 순서에 상관없이 Index로 생성되어 있는 컬럼을 기준으로 정렬되어 삽입
단점
- 검색속도를 향상시키지만 새로운 데이터를 삽입하면 많은 비용이 생성된다.
- 테이블에 데이터가 많이 저장된 상태에서 ALTER를 통해 Clustered Index를 추가한다면, 많은 데이터를 정렬하므로 많은 리소스를 차지한다.
Non-Clustered Index
물리적으로 테이블을 정렬하지 않는다
데이터가 저장된 곳과 인덱스가 저장된 곳이 다르다
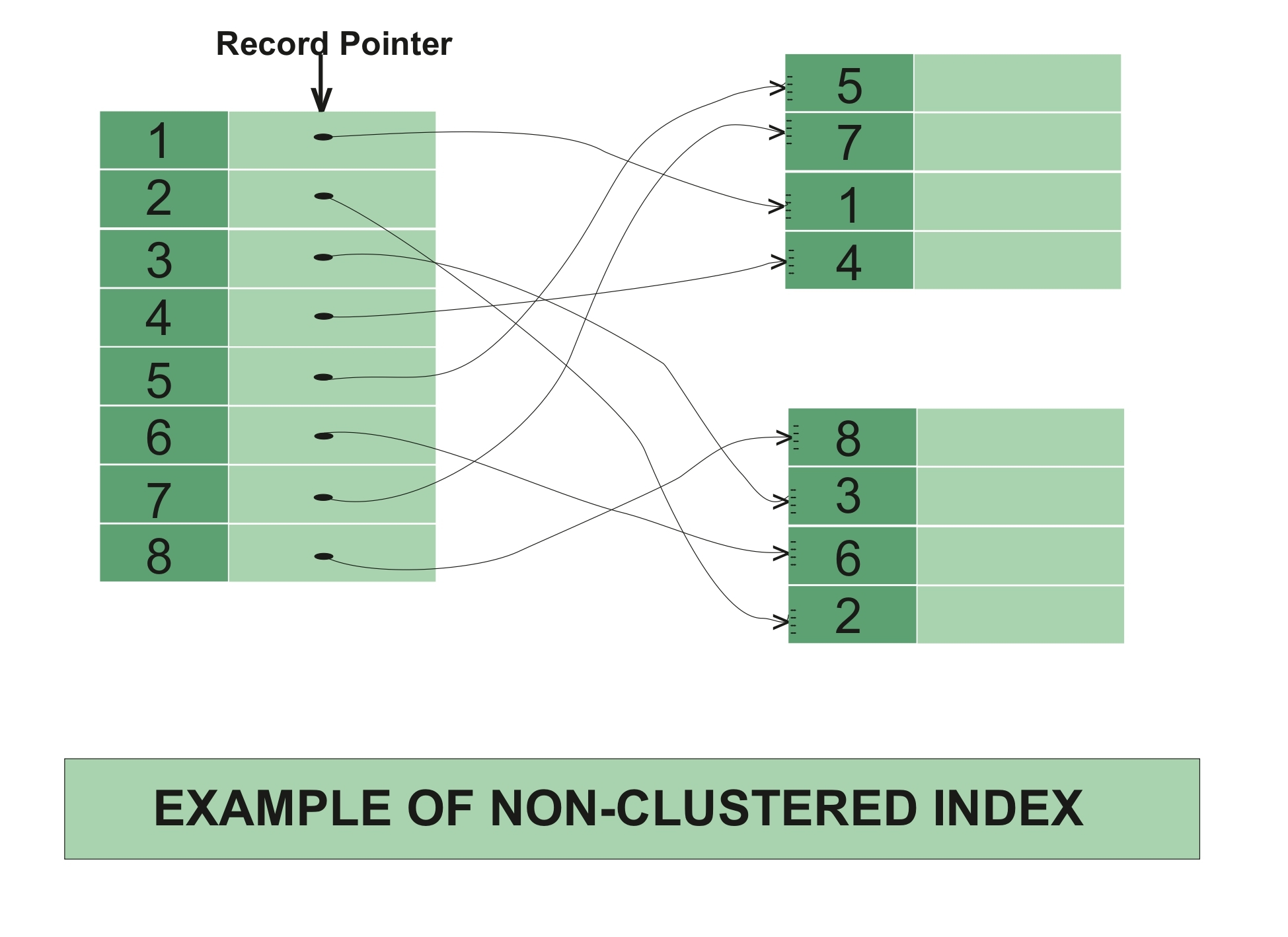
- 실제 데이터 페이지는 그대로 두고 별도의 인덱스 페이지를 생성하기 때문에 추가 공간이 필요하다
- Unique 제약조건 적용 시 자동 생성
- 정렬할 때는 Clustered Index보다 느리지만 데이터를 삽입,수정,삭제할 때는 빠르다.
- 데이터 페이지에는 정렬 순서 상관없이 빈 곳에 데이터를 삽입하면 되기 때문이다.
Non-Clustered Index 방식
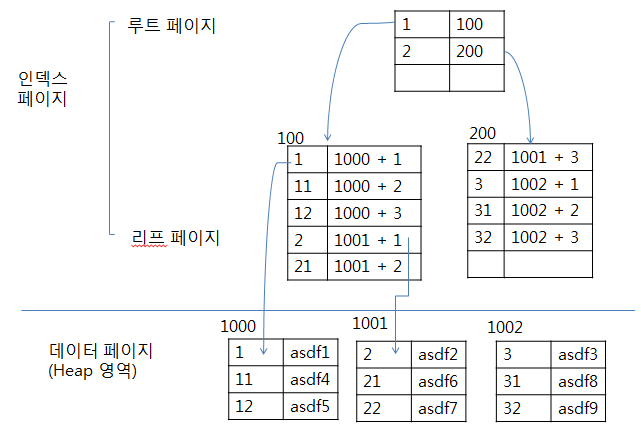
- 데이터 페이지 외에 별도의 인덱스 페이지를 생성한다.
- 인덱스 페이지와 데이터 페이지가 구분되는데 인덱스 페이지에는 루트 페이지와 리프 페이지가 있고 데이터 페이지에는 데이터가 저장되어 있다.
- 인덱스는 정렬되어 있지만 데이터는 정렬되어 있지 않다.
- 인덱스 페이지는 키값(정렬하여 인덱스 페이지 구성)과 RID로 구성된다.
- 리프 페이지는 Index로 구성한 열을 정렬하고 위치 포인터(RID)를 생성한다.
- RID는 데이터가아니라 데이터가 위치하는 포인터
- 파일 그룹 번호 - 데이터 페이지 번호 - 데이터 페이지 오프셋
- 데이터 키 값을 루트 페이지에서 비교하여 리프 페이지에서 번호를 찾고, 리프 페이지에서 RID 정보로 실제 데이터 위치로 이동한다.
Clustered Index와 Non-Clustered Index 혼합
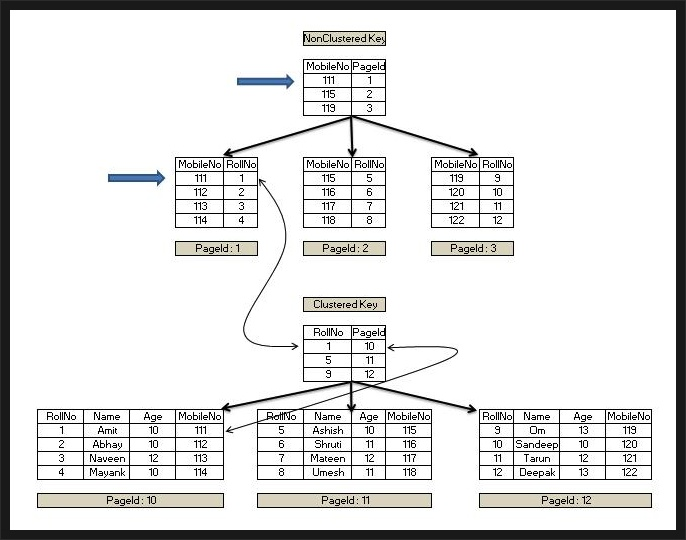
참고
https://velog.io/@gillog/SQL-Clustered-Index-Non-Clustered-Index
https://www.geeksforgeeks.org/difference-between-clustered-and-non-clustered-index/
https://hudi.blog/db-clustered-and-non-clustered-index/

물음표를 느낌표로 바꾸며 성장하는 예비 백엔드 개발자입니다.