
이전에 로컬에서 Redis 로 조회 데이터를 캐싱에 조회 성능을 개선하는 과정을 정리했다. 이제 로컬에서 작업한 코드를 배포해 확인하고자 한다. AWS 의 EC2 와 RDS 를 활용해서 인프라를 구성하고 코드를 배포해 Redis 를 활용할 수 있도록 해보자.
아키텍처 구성
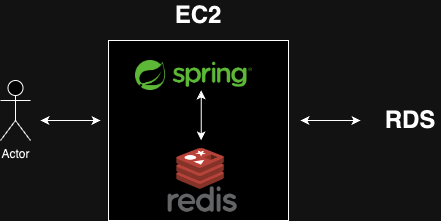
사용자가 요청을 보낼 때는 EC2 를 통해 요청을 보내고, EC2 내부에서 프로세스와 Redis 가 통신하도록 세팅한다. 또 RDS 를 활용해 외부에서 데이터베이스 통신할 수 있도록 구성한다.
인프라 구성
EC2 생성 설정
대부분의 옵션은 디폴트로 두고 몇몇 옵션만 설정해 주었다.
특히 인스턴스 유형을 t3a.small 로 변경해 생성했는데, t2.micro 에서 Spring Boot, Redis 를 다 돌리기엔 성능이 모자라다고 한다.
또 VPC 보안 그룹에서 8080 포트가 접근 가능한 보안 규칙을 추가한다.
RDS 생성 설정
RDS 또한 대부분의 옵션을 디폴트로 둔다.
MySQL 로 초기 데이터베이스 옵션을 로컬에서 생성한 데이터베이스명과 동일하게 설정했다. 생성 후에는 보안 그룹에서 3306 포트를 열어주는 인바운드 규칙을 추가한다.
EC2 인스턴스 내에 jdk, Redis 설치
sudo apt update
sudo apt install redis
sudo apt install openjdk-17-jdkEC2 에 로컬 환경에서 작업한 프로젝트 이동
EC2에서 코드를 clone 하기 전에 profile 을 분리한다.
public repository 로 커밋했기 때문에 데이터베이스 정보는 별도로 EC2 내부에서 환경 변수를 설정했다.
spring:
config:
activate:
on-profile: prod
datasource:
url: ${DB_URL}
username: ${DB_USER}
password: ${DB_PASSWORD}EC2 에서 git clone 후 jar 파일을 실행한다.
./gradlew clean build -x test프로젝트 디렉토리의 /build/libs 내에 생성된 jar 파일을 확인할 수 있다.

jar 파일을 실행하면 정상적으로 실행 완료됨을 확인할 수 있다.

결과
기대한 대로 성능 차이가 있는지 postman 으로 API 를 요청해보자.
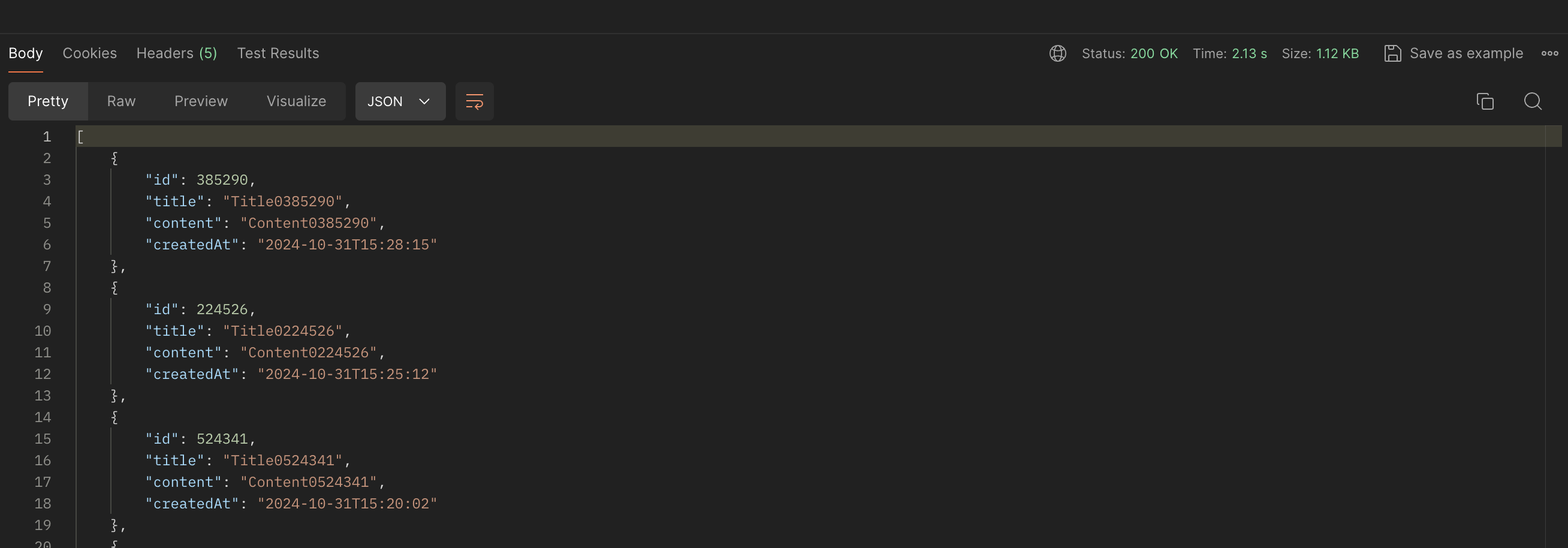
첫번째 요청
2.13s 의 소요시간 확인.
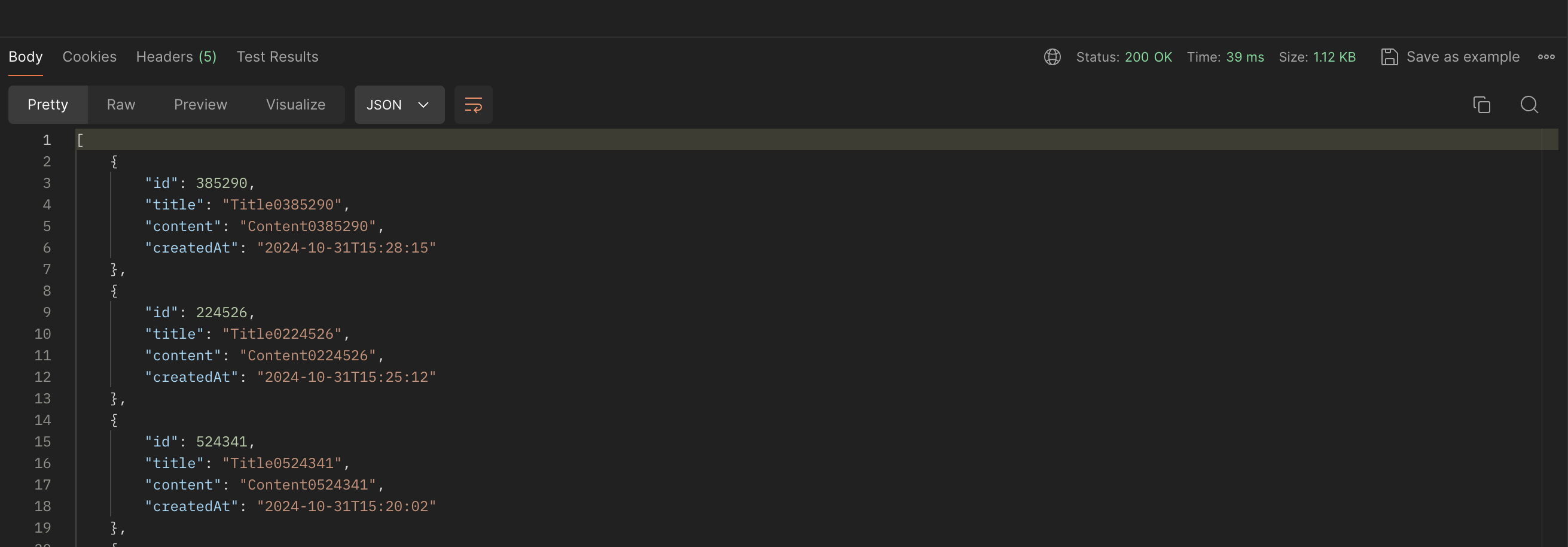
두번째 요청
39ms 의 소요시간 확인.
캐싱되어 조회 속도가 확연히 줄어들었다.
Redis 에 저장된 데이터 확인
의도대로 EC2 에 설치한 Redis 에 데이터가 저장되어 있음을 확인할 수 있다.

실무 환경에서는 Azure 로 구성되어 있어서 AWS 에 대한 지식이 부족한데, 실습 해 보면서 EC2 인스턴스와 RDS에 대한 추가적인 학습이 필요하다고 느꼈다. 일단 익혀보고 필요한 부분은 더 학습해 봐야지 ...
학습에 참고한 강의
