ArrayList의 사용법
배열에는 몇가지 불편한 점이 있었는데 그 중의 하나가 한번 정해진 배열의 크기를 변경할 수 없다는 점이다. 이러한 불편함을 컬렉션즈 프래임워크를 사용하면 줄어든다.
아래의 예를 보자.
package org.opentutorials.javatutorials.collection;
import java.util.ArrayList;
public class ArrayListDemo {
public static void main(String[] args) {
String[] arrayObj = new String[2];
arrayObj[0] = "one";
arrayObj[1] = "two";
// arrayObj[2] = "three"; 오류가 발생한다.
for(int i=0; i<arrayObj.length; i++){
System.out.println(arrayObj[i]);
}
ArrayList al = new ArrayList();
al.add("one");
al.add("two");
al.add("three");
for(int i=0; i<al.size(); i++){
System.out.println(al.get(i));
}
}
}아래 코드처럼 배열은 그 크기를 한번 지정하면 크기보다 많은 수의 값을 저장할 수 없다.
String[] arrayObj = new String[2];
arrayObj[0] = "one";
arrayObj[1] = "two";
// arrayObj[2] = "three"; 오류가 발생한다.하지만 ArrayList는 크기를 미리 지정하지 않기 때문에 얼마든지 많은 수의 값을 저장할 수 있다.
ArrayList al = new ArrayList();
al.add("one");
al.add("two");
al.add("three");ArrayList는 배열과는 사용방법이 조금 다르다. 배열의 경우 값의 개수를 구할 때 .length를 사용했지만 ArrayList는 메소드 size를 사용한다. 또한, 특정한 값을 가져올 때 배열은 [인덱스 번호]를 사용했지만 컬렉션은 .get(인덱스 번호)를 사용한다.
for(int i=0; i<al.size(); i++){
System.out.println(al.get(i));
}그런데 ArrayList를 사용할 때 주의할 점이 있다. 위의 반복문을 아래처럼 바꿔보자.
for(int i=0; i<al.size(); i++){
String val = al.get(i);
System.out.println(val);
}위의 코드는 컴파일 오류가 발생한다. ArrayList의 메소드 add의 입장에서는 인자로 어떤 형태의 값이 올지 알 수 없다. 그렇기 때문에 모든 데이터 타입의 조상인 Object 형식으로 데이터를 받고 있다. 예를들면 아래와 같은 모습일 것이다. (실제와는 다르다)
public boolean add(Object e) {따라서 ArrayList 내에서 add를 통해서 입력된 값은 Object의 데이터 타입을 가지고 있고, get을 이용해서 이를 꺼내도 Object의 데이터 타입을 가지고 있게 된다. 그래서 위의 코드는 아래와 같이 바꿔야 한다.
for(int i=0; i<al.size(); i++){
String val = (String)al.get(i);
System.out.println(val);
}get의 리턴값을 문자열로 형변환하고 있다. 원래의 데이터 타입이 된 것이다.
그런데 위의 방식은 예전의 방식이다. 이제는 아래와 같이 제네릭을 사용해야 한다.
ArrayList<String> al = new ArrayList<String>();
al.add("one");
al.add("two");
al.add("three");
for(int i=0; i<al.size(); i++){
String val = al.get(i);
System.out.println(val);
}제네릭을 사용하면 ArrayList 내에서 사용할 데이터 타입을 인스턴스를 생성할 때 지정할 수 있기 때문에 데이터를 꺼낼 때(String val = al.get(i);) 형변환을 하지 않아도 된다.
전체적인 구성
그럼 이제부터 컬렉션즈 프래임워크가 무엇인가 본격적으로 알아보자. 컬렉션즈 프래임워크라는 것은 다른 말로는 컨테이너라고도 부른다. 즉 값을 담는 그릇이라는 의미이다. 그런데 그 값의 성격에 따라서 컨테이너의 성격이 조금씩 달라진다. 자바에서는 다양한 상황에서 사용할 수 있는 다양한 컨테이너를 제공하는데 이것을 컬렉션즈 프래임워크라고 부른다. ArrayList는 그중의 하나다.
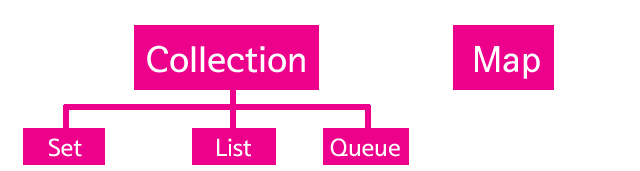
위의 그림은 컬렉션즈 프래임워크의 구성을 보여준다. Collection과 Map이라는 최상위 카테고리가 있고, 그 아래에 다양한 컬렉션들이 존재한다. 그럼 구체적인 컬렉션즈 프래임워크 클래스들을 살펴보자.
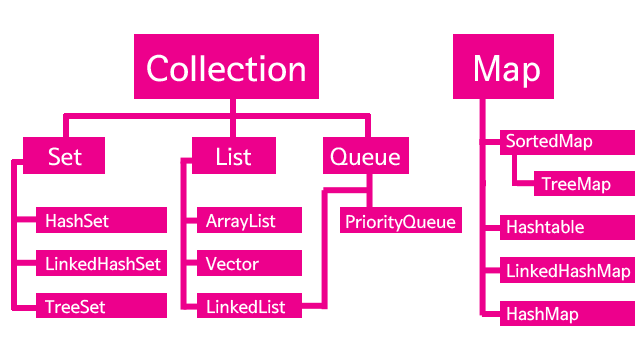
ArrayList를 찾아보자. Collection-List에 속해있다. ArrayList는 LIst라는 성격으로 분류되고 있는 것이다. List는 인터페이스이다. 그리고 List 하위의 클래스들은 모두 List 인터페이스를 구현하기 때문에 모두 같은 API를 가지고 있다. 클래스의 취지에 따라서 구현방법과 동작방법은 다르지만 공통의 조작방법을 가지고 있는 것이다. 익숙한 ArrayList를 바탕으로 나머지 컬렉션들의 성격을 파악해보자.
List와 Set의 차이점
List와 Set의 차이점은 List는 중복을 허용하고, Set은 허용하지 않는다.
package org.opentutorials.javatutorials.collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
public class ListSetDemo {
public static void main(String[] args) {
ArrayList<String> al = new ArrayList<String>();
al.add("one");
al.add("two");
al.add("two");
al.add("three");
al.add("three");
al.add("five");
System.out.println("array");
Iterator ai = al.iterator();
while(ai.hasNext()){
System.out.println(ai.next());
}
HashSet<String> hs = new HashSet<String>();
hs.add("one");
hs.add("two");
hs.add("two");
hs.add("three");
hs.add("three");
hs.add("five");
Iterator hi = hs.iterator();
System.out.println("\nhashset");
while(hi.hasNext()){
System.out.println(hi.next());
}
}
}결과는 아래와 같다.
array
one
two
two
three
three
five
hashset
two
five
one
three
우선 값을 가져오는 방법이 조금 달라졌다. (ArrayList에서도 이 방법을 사용할 수 있다)
Iterator ai = al.iterator();
while(ai.hasNext()){
System.out.println(ai.next());
}메소드 iterator는 인터페이스 Collection에 정의되어 있다. 따라서 Collection을 구현하고 있는 모든 컬렉션즈 프레임웍크는 이 메소드를 구현하고 있음을 보증한다. 메소드 iterator의 호출 결과는 인터페이스 iterator를 구현한 객체를 리턴한다. 인터페이스 iterator는 아래 3개의 메소드를 구현하도록 강제하고 있는데 각각의 역할은 아래와 같다.
hasNext
반복할 데이터가 더 있으면 true, 더 이상 반복할 데이터가 없다면 false를 리턴한다.
next
hasNext가 true라는 것은 next가 리턴할 데이터가 존재한다는 의미다.
이러한 기능을 조합하면 for 문을 이용하는 것과 동일하게 데이터를 순차적으로 처리할 수 있다.
그럼 본론으로 돌아와서 Set과 List의 차이를 짚어보자. 위의 결과를 통해서 알 수 있는 것처럼 Set는 중복을 허용하지 않고 순서가 없지만, List는 중복을 허용하고 저장되는 순서가 유지된다는 것을 알 수 있다. 이러한 특징을 고려해서 컬렉션을 선택해야 한다. 그럼 Set에 대해서 조금 더 알아보자.
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
class Main {
public static void main(String[] args) {
HashSet<Integer> A = new HashSet<Integer>();
A.add(1);
A.add(2);
A.add(3);
HashSet<Integer> B = new HashSet<Integer>();
B.add(3);
B.add(4);
B.add(5);
HashSet<Integer> C = new HashSet<Integer>();
C.add(1);
C.add(2);
System.out.println(A.containsAll(B)); // false
System.out.println(A.containsAll(C)); // true
//A + B
//A.addAll(B);
//A와 B의 교집합
//A.retainAll(B);
//A - B
//A.removeAll(B);
Iterator hi = A.iterator();
while(hi.hasNext()){
System.out.println(hi.next());
}
}
}Map
이번에는 Map 컬렉션에 대해서 알아보자. Map 컬렉션은 key와 value의 쌍으로 값을 저장하는 컬렉션이다.
HashMap의 키로 사용할 객체는 hashCode()와 equlas()메소드를 재정의해서 동등 객체가 될 조건을 정해야 한다. 동등 객체, 즉 동일한 키가 될 조건은 hashCode()의 리턴값이 같아야 하고, equals() 메소드가 true를 리턴해야 한다.

주로 키 타입은 String을 많이 사용하는데, String은 문자열이 같을 경우 동등 객체가 될 수 있도록 hashCode()와 equals() 메소드가 재정의되어 있다. HashMap을 생성하기 위해서는 키 타입과 값 타입을 파라미터로 주고 기본 생성자를 호출하면 된다.
Map<K,V> map = new HashMap<K,V>();키와 값의 타입은 기본 타입(byte,short,int,float,double,boolean,char)을 사용할 수 없고 클래스 및 인터페이스 타입만 가능하다. 키로 String 타입을 사용하고 값으로 Integer 타입을 사용하는 HashMap은 다음과 같이 생성할 수 있다.
Map<String,Integer> map = new HashMap<String,Integer>();다음 예제를 살펴보자
package org.opentutorials.javatutorials.collection;
import java.util.*;
public class MapDemo {
public static void main(String[] args) {
HashMap<String, Integer> a = new HashMap<String, Integer>();
a.put("one", 1);
a.put("two", 2);
a.put("three", 3);
a.put("four", 4);
System.out.println(a.get("one"));
System.out.println(a.get("two"));
System.out.println(a.get("three"));
iteratorUsingForEach(a);
iteratorUsingIterator(a);
}
// map인터페이스에는 entrySet이라는 메소드가 정의되어있는데
// Set데이터 타입의 어떤 객체가 리턴되는데 그 객체가 entries에 담기게 된다.
// Entry라고 하는 인터페이스를 구현하고 있는 어떠한 객체가
// Set컨테이너 안에 들어가게 된다.
// Map.Entry안에는 두가지 메소드가 정의되어 있는데
// 첫번 째는 getKey(), 두번 째는 getValue()라는 것이고
// <String, Integer>가 그 첫번 째 두번 째이다.
static void iteratorUsingForEach(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
static void iteratorUsingIterator(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> i = entries.iterator();
while(i.hasNext()){
Map.Entry<String, Integer> entry = i.next();
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
}Map에서 데이터를 추가할 때 사용하는 API는 put이다. put의 첫번째 인자는 값의 key이고, 두번째 인자는 key에대한 값이다. key를 이용해서 값을 가져올 수 있다.
System.out.println(a.get("one"));이것이 Map의 가장 기본적인 사용법이다. 그럼 Map에 저장된 데이터를 열거할 때는 어떻게 해야할까?
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}메소드 entrySet은 Map의 데이터를 담고 있는 Set을 반환한다. 반환한 Set의 값이 사용할 데이터 타입은 Map.Entry이다. Map.Entry는 인터페이스인데 아래와 같은 API를 가지고 있다.
getKey
getValue
위의 API를 이용해서 Map의 key, value를 조회할 수 있다.
데이터 타입의 교체
컬렉션을 사용할 때는 데이터 타입은 가급적 해당 컬렉션을 대표하는 인터페이스를 사용하는 것이 좋다.
HashMap<String, Integer> a = new HashMap<String, Integer>();이것을 아래와 같이 수정한다. HashMap은 Map 인터페이스를 구현하기 때문에 변수 a의 데이터 타입으로 Map을 사용할 수 있다.
Map<String, Integer> a = new HashMap<String, Integer>();어떤 필요에 의해서 컬렉션을 HashMap에서 HashTable로 바꾸고 싶다면 아래와 같이 수정하면 된다.
Map<String, Integer> a = new Hashtable<String, Integer>();이것의 보충하는 예로는
ArrayList <Object> list = new ArrayList <>();
List <Object> list = new ArrayList <>();
2가지 모두 같은 결과를 도출합니다. 하지만 List를 사용해 ArrayList를 생성하는 것은 유연성에서 효과를 볼 수 있습니다.
여기서 Generic(제너릭)에 대한 개념이 나옵니다.
만약에 우리가 어떤 자료구조를 만들어 배포하려고 합니다.
그런데 String 타입도 지원하고 싶고 Integer타입도 지원하고 싶고 많은 타입을 지원하고 싶습니다.
그러면 String에 대한 클래스, Integer에 대한 클래스 등 하나하나 타입에 따라 만들 것인가요?
그건 너무 비효율적이게 됩니다. 이러한 문제를 해결하기 위해 우리는 Generic(제너릭)이라는 것을 사용합니다.
Generic은 클래스 내부에서 지정하는 것이 아닌 외부에서 사용자에 의해 지정되는 것을 의미합니다.
한마디로 특정 타입을 미리 지정해주는 것이 아닌 필요에 의해 지정할 수 있도록 하는 일반(Generic) 타입입니다.
즉, 저런 인스턴스의 형 변환을 통해 내부 디테일과 메모리 함축에서 이점과 성능을 개선시킬 수 있습니다.
데이터의 용도에 따라 빠른 탐색을 위해서 ArrayList를 사용할 때도 있고, 삽입/삭제를 위해 LinkedList를 사용해야 하는 경우도 있습니다.
(유연성의 예)
List <Object> list = new List <>();
List <Object> list = new LinkedList <>();자바의 다형성 관련 -
클래스를 생성할 때 도형 타입으로 생성하게 되면 정사각형이 아닌
다른 직사각형, 삼각형 등 도형 인터페이스를 구현한 클래스에서 사용될 수 있습니다.
하지만 정사각형 클래스로 생성하게 되면 직사각형, 삼각형 등 에서는 사용할 수 없습니다.
도형에 비유하여 풀어보면,
List list = new ArrayList();
-> 도형 list = new 정사각형();
ArrayList list = new ArrayList();
-> 정사각형 list = new 정사각형();데이터의 삽입이나 삭제가 필요한 상황에서 List로 선언한 인스턴스를 LinkedList로 바꾸게 되면 아무런 문제 없이 LinkedList의 장점을 취할 수 있습니다.
정렬
컬렉션을 사용하는 이유 중의 하나는 정렬과 같은 데이터와 관련된 작업을 하기 위해서다. 정렬하는 법을 알아보자.패키지 java.util 내에는 Collections라는 클래스가 있다. 이 클래스를 사용하는 법을 알아보자.
package org.opentutorials.javatutorials.collection;
import java.util.*;
class Computer implements Comparable{
int serial;
String owner;
Computer(int serial, String owner){
this.serial = serial;
this.owner = owner;
}
public int compareTo(Object o) {
return this.serial - ((Computer)o).serial;
}
public String toString(){
return serial+" "+owner;
}
}
public class CollectionsDemo {
public static void main(String[] args) {
List<Computer> computers = new ArrayList<Computer>();
computers.add(new Computer(500, "egoing"));
computers.add(new Computer(200, "leezche"));
computers.add(new Computer(3233, "graphittie"));
Iterator i = computers.iterator();
System.out.println("before");
while(i.hasNext()){
System.out.println(i.next());
}
Collections.sort(computers);
System.out.println("\nafter");
i = computers.iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
}결과
before
500 egoing
200 leezche
3233 graphittie
after
200 leezche
500 egoing
3233 graphittie
클래스 Collectors는 다양한 클래스 메소드를 가지고 있다. 메소드 sort는 그 중의 하나로 List의 정렬을 수행한다. 다음은 sort의 시그니처다.
public static <T extends Comparable<? super T>> void sort(List<T> list)sort의 인자인 list는 데이터 타입이 List이다. 즉 메소드 sort는 List 형식의 컬렉션을 지원한다는 것을 알 수 있다. 인자 list의 제네릭 는 coparable을 extends 하고 있어야 한다. Comparable은 인터페이스인데 이를 구현하고 있는 클래스는 아래 메소드를 가지고 있어야 한다.
compareTo(T o)아래의 메소드는 이러한 제약 조건을 준수하기 위해서 구현한 메소드다.
public int compareTo(Object o) {
return this.serial - ((Computer)o).serial;
}메소드 sort를 실행하면 내부적으로 compareTo를 실행하고 그 결과에 따라서 객체의 선후 관계를 판별하게 된다.
이렇게 해서 컬렉션즈 프레임워크에 대한 수업을 마무리 하겠다. 컬렉션즈 프레임워크는 효율적인 에플리케이션을 구축하기 위해서 매우 중요한 내용이다. 그런데 컬렉션은 단순히 사용법을 이해하는 것으로는 부족하고, 소위 알고리즘이나 자료구조(data structure)라고 불리는 분야에 대한 충분한 이해가 필요하다. 컬렉션즈 프레임워크는 이러한 분야의 성취를 누구나 쉽게 사용할 수 있도록 제공되는 일종의 라이브러리라고 할 수 있기 때문이다.
-생활코딩-
