rollback
- Transaction을 취소할 때 사용.
- savepoint와 함께 사용하면 특정 지점까지의 작업을 취소 시킬 수 있다.
- 사용법 )
- 직전 commit 이후까지 모든 작업을 취소.
rollback; - savepoint 까지의 작업을 취소.
rollback to 저장점명; - insert쿼리문 실행
commit; //직전 commit
insert, update delete가 트랜잭션으로 구성
rollback -> commit과 사이에 있는 insert, update, delete전 ( commit 직후 ) 으로 되돌아감.
- 직전 commit 이후까지 모든 작업을 취소.
savepoint
- Transaction 대상쿼리문을 작성하기 전에 생성.
- commit, rollback이 되면 사라진다.
- 문법 )
- savepoint 저장점명;
- insert쿼리문 실행
commit; //직전 commit
insert, update delete가 트랜잭션으로 구성
savepoint a;
insert;
savepoint b;
update;
savepoint c;
delete;
rollback to a; -> insert ~ delete 까지 전부 되돌아감
select
- 테이블에서 모든 레코드의 특정 컬럼을 검색하는 쿼리문.
- 기본구문 )
- select 컬럼명, 함수명( 컬럼명 ), 컬럼명 연산자, 컬럼명 alias
- from 테이블명
- where 절
- group by 절
- having 절
- order by 절
alias
- 컬럼명 또는 테이블명 뒤에 정의할 수 있다.
- 컬럼명의 별명. 테이블명의 별명을 부여할 때 사용.
- 가독성을 향상 시킬 때 사용.
- alias를 사용하면 조회결과에 나오는 컬럼명이 alias명으로 변경된다.
- select에서 연결된 where절에서는 alias명을 사용할 수 없다.
- 문법 )
- 컬럼명 as alias명 (as 생략가능)
컬럼명 alias명
- 컬럼명 as alias명 (as 생략가능)
Operator
- 연산에 사용되는 예약된 부호들.
- 산술연산자 : 조회되는 컬럼에서 사용할 수 있다.
- +,-,*,/, 나눈 나머지를 구할 때에는 mod함수를 사용한다.
- 관계연산자
, <, >=, <=, =, != ( <> )
- 논리연산자
- and, or, not
- 문자열연산자
- like, %, _
- null비교 연산자
- is null,is not null
- 범위 비교
- between ,and
- 문자열 붙임 : 조회 컬럼에서 사용할 수 있다.
- ||
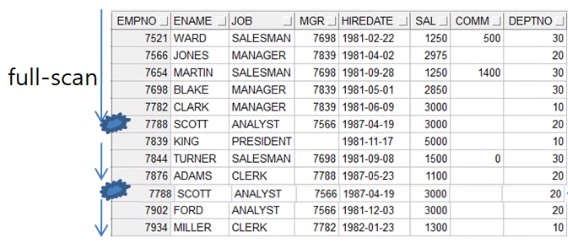
where 절
- 모든 레코드에서 특정 레코드만 검색해야할 때.
- 산술과 ||를 제외한 모든 연산자를 사용할 수 있다.
- full-scan : 비교값에 해당하는 컬럼 값을 위에서 부터 아래로 전체 레코드를 검색하면서 조회한다.
- 사용법 )
- where 컬럼명 연산자 비교값
- select empno, ename, sal
- from emp
- where = empno = 7788;

between
- 범위를 비교할 때 사용하는 연산자 (and는 between으로 대체할 수 있다.)
- 사용법 )
- between 작은값 and 큰값
in
- 포함하는 값을 검색할 때 사용(or는 in으로 대체할 수 있다.)
- 사용법 )
- 컬럼명 in( 값,,,,)
like
- 문자열 데이터 중 일부분의 데이터로만 검색 할 때 사용.
- %,_ 특수문자와 함께 사용.
- % : 글자수에 상관 없는 모든 문자열을 비교한다.
- 사용법 )
컬럼명 LIKE'값%' - 값에 해당하는 문자열로 시작하는
컬럼명 LIKE'%값' - 값에 해당하는 문자열로 끝나는
컬럼명 LIKE'%값%' - 값이 포함되어있는 문자열
- 사용법 )
- _ : 한 글자에 해당하는 문자열을 비교.
- 사용법 )
컬럼명 LIKE'값' - 값에 앞에 한자리의 값이 존재
- 사용법 )
- % : 글자수에 상관 없는 모든 문자열을 비교한다.
CSV파일 한번에 추가 하기
- CSV파일로 변경 => excel
- clt파일 만들거나 수정.
- sqlldr.exe 사용하여 DBMS 추가
- sqlldr userid=scott/tiger control=zipcode.ctl
group by절
- 조회 컬럼의 중복 값을 그룹으로 묶어서 조회하는 일.
- 그룹으로 묶여지지 않는 컬럼이 조회 컬럼에 나오면 error가 발생.
- select 그룹으로 묶인 컬럼명만 조회
- from 테이블명
- group by 그룹으로 묶을컬럼명,,
- 집계함수와 함께 사용되면 그룹별 집계를 얻을 수 있다.
- having절에서 그룹으로 묶여질 조건을 설정할 수 있다.
- 사용법 )
- group by 그룹화할 컬럼명,,,,
- having 그룹으로 묶여질 조건
distinct
- 컬럼의 중복 값을 출력하지 않을 때 사용하는 키워드
- select의 컬럼 앞에 정의
- error가 발생하지 않는다.
- 여러 컬럼과 함께 사용하면 중복배제를 하지 않는다.
- 사용법 )
- select distinct 컬럼명
- 중복 값이 없는 컬럼과 함께 사용되면 중복배제를 하지 않는다.
- 중복 값이 있는 컬럼과 함께 사용하면 앞의 컬럼에 중복값과 뒤에 사용되는 컬럼에 중복값이 존재한다면 뒤의 컬럼에 대해 중복배제를 수행한다.


order by절
- 검색된 레코드를 정렬할 때 사용.
- 오름차순 정렬과 내림차순 정렬이 가능.
- 문자열의 정렬은 자릿수의 정렬을 수행.
- 문법 )
- order by 정렬할 컬럼명 정렬종류,정렬할 컬럼명 정렬종류,,,,
- asc : 오름차순 정렬 ( 기본설정 - 생략 가능)
- desc : 내림차순 정렬
- 앞의 컬럼에 같은 값이 존재하면 두번째 컬럼에 정렬
- order by 정렬할 컬럼명 정렬종류,정렬할 컬럼명 정렬종류,,,,
