
이 글은 최대한 많은 프로그래밍 언어에 적용 가능한 내용으로 작성되었습니다. 몇몇 예시에서는 JavaScript를 사용하였지만, 이는 별도의 설정 없이 브라우저 환경에서 빠르게 확인해보기 위함이며, 'regex 일단 시작하기'를 통해 Python, Java, JavaScript 각 언어에서 'Usage'의 예제들을 적용해볼 수 있는 환경을 구성할 수 있습니다.
이 글을 통해 여러분들께서 정규 표현식을 쉽게 이해하고 활용할 수 있기를 바라며, 참고용 Cheat Sheet처럼 빠르게 활용하실 수 있는 글이 되었으면 좋겠습니다.🥰
+) 정규 표현식 예제를 쉽게 작성하고 테스트 해볼 수 있는 사이트 -> https://regexr.com/
정규 표현식(Regular Expression)이란?
정규 표현식(Regular Expression, 간단히 RegExp 또는 regex)은 문자열 패턴을 표현하는데 사용되는 특별한 형식 언어(Formal Language)입니다. 문자열에서 원하는 패턴을 찾거나 매치시키기 위해 사용되며, 텍스트 처리와 검색 작업을 간편하게 수행하는 강력한 도구입니다.
정규 표현식은 어디서부터 시작되었는지 가볍게 살펴보고, 몇몇 용어와, 정규 표현식의 구성요소에 대해서 알아보겠습니다.
정규 표현식의 역사
정규 표현식은 20세기 초기의 수학자인 Stephen Cole Kleene(스티븐 콜 클리니)에 의해 시작되었습니다. 1950년대, Kleene는 형식 언어의 표현과 분석에 관심을 가지고, 그 당시 다루던 형식 언어를 기술하기 위해 문자열 패턴을 나타내는 수학적인 기호 체계를 고안해냈습니다.

Kleene의 기호 체계에서, 문자열 패턴은 문자, 숫자, 그리고 특별한 메타 문자로 표현되었습니다. 이 메타 문자들은 패턴 내에서 문자들의 반복, 선택, 그룹화 등을 나타내는데 사용되었습니다. 이러한 아이디어는 후에 정규 표현식의 핵심 개념이 되었습니다.
1960년대부터 1970년대에 이르러서 컴퓨터 과학자들은 Kleene의 아이디어를 기반으로 문자열 패턴을 효율적으로 처리하기 위해 정규 표현식 엔진을 개발하였습니다. 이후 정규 표현식은 다양한 컴퓨터 프로그래밍 언어 및 텍스트 편집기에서 지원되며, 문자열 검색, 대체, 추출 등 다양한 텍스트 처리 작업에서 흔히 사용되는 강력한 도구가 되었습니다.
형식 언어(Formal Language)란
형식 언어(Formal Language)는 형식화된 규칙에 따라 구성된 문자열의 집합을 나타내는 언어를 말합니다.
형식 언어는 특정한 패턴, 문법 또는 규칙을 따라야 하며, 이러한 규칙들은 자연 언어(예: 영어, 한국어)의 문법과는 다릅니다. (주로 수학적인 기호와 규칙으로 정의됩니다.)
프로그래밍 언어도 형식 언어의 한 예입니다. 프로그래밍 언어는 특정 문법 규칙을 따라 작성되어야 하며, 잘못된 문법을 사용하면 컴파일 오류나 런타임 오류가 발생할 수 있습니다.

정규 표현식 역시 형식 언어의 일종으로, 문자열의 패턴을 표현하는데 사용되는 형식언어 입니다.
정규 표현식의 구성요소
정규표현식은 3가지 요소로 구성됩니다.

-
패턴 구분자: 정규식을 표현할 때 패턴의 시작과 끝을 나타내는 문자입니다. 일반적으로 슬래시(
/)를 사용하지만, 다른 문자도 사용할 수 있습니다. -
패턴 변경자(flag): 정규식의 동작을 수정하는데 사용되는 옵션입니다. 각각의 변경자는 정규식 패턴 뒤에 옵션으로 추가되며, 검색의 경우 대소문자 구분 여부, 다중행 검색 등을 지정할 수 있습니다.
g: 전역 검색 플래그. 모든 매치를 찾습니다.m: 다중 행 모드 플래그. ^와 $가 각 행의 시작과 끝을 매치합니다.i: 대소문자를 구분하지 않는 검색 플래그.u: 유니코드 모드 플래그. 유니코드 문자에 대한 매치를 지원합니다.s: "dot all" 모드 플래그. 개행 문자를 포함한 모든 문자와 매치합니다.
-
패턴(pattern) (정규 표현식의 핵심 부분): 정규식의 핵심 부분으로, 검색하거나 대체하려는 텍스트의 패턴을 나타냅니다. 패턴은 일반 문자와 메타 문자의 조합으로 이루어집니다.
- 일반 문자 (Literal Characters): 일반 문자는 그 자체로 문자열 내에서 특별한 의미 없이 그 문자 그대로를 나타냅니다. 예를 들어, "a"는 문자 "a"를 의미하며, "123"은 순서대로 문자 "1", "2", "3"을 나타냅니다.
- 메타 문자 (Metacharacters): 단순 문자가 아닌 다른 용도로 사용되는 문자를 말하며 단일 문자 또는 백 슬래쉬
\+ 단일 문자의 형태로 사용됩니다. 메타 문자들은 정규 표현식에서 특별한 의미가 있으므로 자기 자신을 문자 그대로 표현할 수 없습니다.(이스케이프 메타 문자를 통해 일반 문자로 사용 가능합니다)
regex를 사용하는 이유
정규 표현식의 책임은 단 하나입니다. 바로 문자열에서 원하는 부분을 일치 시키는 것입니다. 그 후에 추출(match), 치환(replace), 또는 검증(test)하는 작업들을 주로 합니다.
하지만 위에서 말씀드린 것처럼 프로그래밍 언어도 형식 언어이기 때문에 사용 중인 언어로 충분히 위의 세 기능들을 구현할 수 있습니다. 정규식을 사용했을 때와의 비교를 위해 아래 예제에서 정규식 없이 이를 구현해보겠습니다. (해당 예제는 브라우저에서 "검사 -> Console"에서 바로 실행해 보실 수 있도록 JavaScript로 작성되었습니다)
regex 없이 주민번호 찾기
아래는 "yeongbin 970223-1234567"라는 문자열에서 주민등록 번호를 추출하고, 치환하고, 검증하는 JavaScript코드입니다.
const data = `
yeongbin 970223-1234567
adultlee 981029-1987654
dongdong 991111-1122334
`;
const matchResult = [];
const replaceResult = [];
let testResult = true;
// data를 \n단위로 나눕니다.
data.split("\n").filter(line => line !== "").forEach(line => {
// "yeongbin 970223-1234567"을 "yeongbin"과 "970223-1234567"로 나눕니다.
const splited = line.split(" ");
if (line.split(" ").length === 2) {
const registNumber = splited[1];
// 검증
if (registNumber.length === 14
&& !isNaN(registNumber.slice(0, 6))
&& !isNaN(registNumber.slice(7))) {
matchResult.push(registNumber); //추출
replaceResult.push(registNumber.slice(0, 6) + "-" + "*******"); //치환
}
else {
testResult = false;
}
}
else {
testResult = false;
}
});
console.log(matchResult); //출력: [ '970223-1234567', '981029-1987654', '991111-1122334' ]
console.log(replaceResult); //출력: [ '970223-*******', '981029-*******', '991111-*******' ]
console.log(testResult); //출력: true물론 위의 코드는 개선될 여지가 많이 보입니다. 스페이스가 아닌 다른 공백문자(예를 들어 \t)는 처리하지 못하고, 문자열 양 옆으로 공백이나 다른 문자들이 추가되어도 처리하지 못합니다. 그러기 위해서 추가적인 조건문이나 변수가 추가될 수 있고, 프로젝트가 커져 이런 함수들이 많아진다면 관리하기 힘들어질 것입니다.
regex를 사용해서 개선하기
위의 복잡한 추출, 치환, 검증 과정이 각 정규표현식 한 줄로 가능해 지는 것을 예제를 통해 확인해보겠습니다.
추출하기(match)
const matchRegex = /\d{6}-\d{7}/g;
console.log(data.match(matchRegex));
//출력: [ '970223-1234567', '981029-1987654', '991111-1122334' ]치환하기(replace)
const replaceRegex = /(?<=-)\d{7}/g;
console.log(data.replace(replaceRegex, "*******"));
//출력:
//yeongbin 970223-*******
//adultlee 981029-*******
//dongdong 991111-*******검증하기(test)
const testRegex = /^(\s*\w+\s+\d{6}-\d{7}\s*)+$/;
console.log(matchRegex.test(data));
//출력: true결국, 프로그래머가 정규 표현식을 자주 사용하는 이유는 정규 표현식을 사용하면 간략하고 간편하게, 위의 기능들을 가능하게 하기 때문입니다.
정규 표현식을 사용하기 좋은 다양한 사례들
정규 표현식은 다양한 경우에 사용되고 있습니다. 아래는 정규 표현식을 사용하기 좋은 사례들입니다.
- 자연어 처리와 텍스트 마이닝: 정규 표현식은 자연어 처리와 텍스트 마이닝에도 사용될 수 있습니다. 이러한 분야에서의 정확한 예제는 상황과 목적에 따라 다양합니다. 예를 들어, 문장에서 특정 키워드를 추출하거나 문서 내의 단어 빈도를 계산하는 등의 작업에서 정규 표현식을 활용할 수 있습니다.
- 프로그래밍 언어와 텍스트 편집기의 지원: 대부분의 프로그래밍 언어와 텍스트 편집기에서는 정규 표현식을 지원하고 있습니다. 위 예제들은 JavaScript를 사용하였지만, 다른 언어에서도 비슷한 방식으로 정규 표현식을 활용할 수 있습니다. 각 언어 및 편집기의 문법과 지원하는 기능은 조금씩 다를 수 있으므로 해당 언어 또는 편집기의 공식 문서를 참고하는 것이 좋습니다.
- 토큰화(Tokenization): 자연어 처리에서 텍스트를 작은 단위로 나누는 토큰화 작업에 정규 표현식을 사용할 수 있습니다. 문장을 단어나 구문으로 분리하는데 유용하며, 자연어 처리 작업에서 많이 활용됩니다.
- 웹 크롤링과 데이터 추출: 웹 페이지에서 원하는 정보를 추출하기 위해 정규 표현식을 사용하는 웹 크롤링 작업에도 활용됩니다. 웹 페이지의 특정 패턴을 찾아 데이터를 추출하는데 유용합니다.
- 로그 분석: 로그 파일에서 원하는 정보를 추출하는데 정규 표현식을 사용할 수 있습니다. 로그 분석은 시스템 모니터링과 오류 디버깅에 중요한 역할을 합니다.
regex 일단 시작하기
정규표현식을 사용하기 위해서 어떻게 해야할까요? 정규표현식은 실제로 설치해 쓰는 프로그램이나 유틸리티가 아닙니다. 오히려 정규 표현식은 다른 프로그래밍 언어나 제품에 포함된 '작은 언어(mini language)'입니다.
우선 각 언어별 regex로 추출(match), 치환(replace), 검증(test)하는 코드를 통해 가볍게 시작해보려 합니다.
정규 표현식은 언어마다 조금씩 구현 방식이 다를 수 있습니다. 여러 프로그래밍 언어와 텍스트 편집기에서 각각 자체적인 정규 표현식 엔진을 가지고 있으며, 이 엔진들은 정규 표현식 패턴을 해석하고 매칭하는 방식에 차이가 있을 수 있습니다.
이러한 차이점을 이해하기 위해 해당 언어 또는 툴의 공식 문서를 참고하는 것을 권장드립니다.
JavaScript로 시작하기
// 특정 문자열을 추출 (match)
const text = "The quick brown fox jumps over the lazy dog.";
const pattern = /quick.*lazy/;
const matchedText = text.match(pattern);
console.log(matchedText); // ["quick brown fox jumps over the lazy"]
// 특정 문자열을 치환 (replace)
const originalString = "apple, banana, orange";
const patternToReplace = /banana/;
const replacementText = "grape";
const replacedString = originalString.replace(patternToReplace, replacementText);
console.log(replacedString); // "apple, grape, orange"
// 문자열이 정규식과 일치하는지 검증 (test)
const textToTest = "hello world";
const patternToTest = /hello/;
const isMatched = patternToTest.test(textToTest);
console.log(isMatched); // truematch: 주어진 텍스트에서 정규식 패턴과 일치하는 부분을 추출하여 배열로 반환합니다.replace: 주어진 텍스트에서 정규식 패턴과 일치하는 부분을 치환하여 새로운 문자열을 반환합니다.test: 주어진 텍스트가 정규식 패턴과 일치하는지 여부를 확인하여 불리언 값을 반환합니다.
Python으로 시작하기
import re
# 특정 문자열을 추출 (match)
text = "The quick brown fox jumps over the lazy dog."
pattern = r"quick.*lazy"
matched_text = re.findall(pattern, text)
print(matched_text) # ['quick brown fox jumps over the lazy']
# 특정 문자열을 치환 (replace)
original_string = "apple, banana, orange"
pattern_to_replace = r"banana"
replacement_text = "grape"
replaced_string = re.sub(pattern_to_replace, replacement_text, original_string)
print(replaced_string) # "apple, grape, orange"
# 문자열이 정규식과 일치하는지 검증 (test)
text_to_test = "hello world"
pattern_to_test = r"hello"
is_matched = bool(re.search(pattern_to_test, text_to_test))
print(is_matched) # Truere.findall함수를 사용하여 정규식 패턴과 텍스트를 매칭시키고, 매칭 결과를 추출합니다.re.sub함수를 사용하여 텍스트에서 정규식 패턴과 일치하는 부분을 치환합니다.re.search함수를 사용하여 텍스트가 정규식 패턴과 일치하는지 여부를 확인합니다.
Java로 시작하기
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
// 특정 문자열을 추출 (match)
String text = "The quick brown fox jumps over the lazy dog.";
Pattern pattern = Pattern.compile("quick.*lazy");
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
String matchedText = matcher.group();
System.out.println(matchedText); // "quick brown fox jumps over the lazy"
}
// 특정 문자열을 치환 (replace)
String originalString = "apple, banana, orange";
String patternToReplace = "banana";
String replacementText = "grape";
String replacedString = originalString.replace(patternToReplace, replacementText);
System.out.println(replacedString); // "apple, grape, orange"
// 문자열이 정규식과 일치하는지 검증 (test)
String textToTest = "hello world";
String patternToTest = "hello";
boolean isMatched = textToTest.matches(".*" + patternToTest + ".*");
System.out.println(isMatched); // true
}
}Matcher클래스와Pattern클래스를 사용하여 정규식 패턴과 텍스트를 매칭시키고, 매칭 결과를 추출합니다.String클래스의replace메서드를 사용하여 텍스트에서 정규식 패턴과 일치하는 부분을 치환합니다.String클래스의matches메서드를 사용하여 텍스트가 정규식 패턴과 일치하는지 여부를 확인합니다.
Usage
위의 '정규 표현식의 구성요소'에서 말씀드린 것처럼 정규 표현식은 '패턴 구분자', '패턴 변경자', '패턴'으로 구성되어 있고, 여기서 '패턴'을 작성하는 것이 가장 주된 일입니다.
패턴은 다시 일반 문자와 메타 문자의 조합으로 이루어진다고 말씀 드렸는데, 이제부터 일반 문자로만 사용하는 예제를 가볍게 살펴보고, 이 각각의 메타 문자들을 어떻게 활용하는 지에 대해서 알아보겠습니다.
일반 문자(문자 리터럴)
일반 문자(문자 리터럴)는 정규식에서 특별한 의미를 가지지 않는 문자를 그대로 표현하는 것을 의미합니다. 일반 문자로만 패턴이 구성된 정규식을 작성해보도록 하겠습니다.

알파벳, 숫자를 위한 메타 문자
아래는 알파벳과 숫자를 위한 메타 문자들 입니다.
| 메타 문자 | 설명 |
|---|---|
\w | 알파벳, 숫자, _(언더바)와 일치합니다. |
\W | 알파벳, 숫자, _(언더바)가 아닌 문자와 일치합니다. |
\d | 숫자와 일치합니다. ([0-9]와 같습니다.) |
\D | 숫자가 아닌 것과 일치합니다. ([^0-9]와 같습니다.) |
. | 어떠한 문자나 알파벳, 숫자, 심지어는 문장 부호로 쓰인 마침표(.)와도 일치합니다. |

\w은 숫자도 포함하니깐 11213, 48075, 48237, 90046도 일치해야하지 않나요? 왜 일치하지 않을까요? 맞춰보세요!
오른쪽 정규식에서 쓰인 \.은 .이라는 메타 문자를 일반 문자로 바꿔주는 이스케이프 문자입니다. 잠시후에 알아보도록 합시다.
메타문자 해제를 위한 메타문자(이스케이프)
이미 메타문자로 정의되어 있는 문자들은 단독으로 사용하면 정규 표현식이 이를 메타문자로 인식하게 됩니다. 이스케이프(Escape)는 메타 문자가 가진 원래 의미가 아닌 특별한 의미로 해석되지 않게 합니다.
| 메타 문자 | 설명 |
|---|---|
\ | 메타 문자 앞에 쓰면 메타 문자를 일반 문자처럼 사용할 수 있습니다. |

[과 ]는 메타 문자이기 때문에 오른쪽의 /myArray[0]/ 의 정규식을 작성하면 위 if문 안에 있는 원하는 부분을 일치시킬 수 없습니다. 이스케이스를 활용해 /myArray\[0\]/과 같은 식으로 작성하면 메타 문자가 아닌 일반 문자로 해석할 수 있습니다.
공백을 위한 메타문자
아래는 여러 공백을 표현하기 위한 메타 문자들 입니다.
| 메타 문자 | 설명 |
|---|---|
[\b] | 백스페이스와 일치합니다. |
\f | 페이지 넘김(form feed)과 일치합니다. |
\n | 개행(줄바꿈)과 일치합니다. |
\r | 캐리지 리턴 |
\t | 탭 문자와 일치합니다. |
\v | vertical tab 을 표현하며 수직 탭 문자와 일치합니다. |
\s | 모든 공백 문자([ \f\n\r\t\v]와 같습니다)와 일치합니다. |
\S | 공백 문자가 아닌 모든 문자([^ \f\n\r\t\v]와 같습니다)와 일치합니다. |
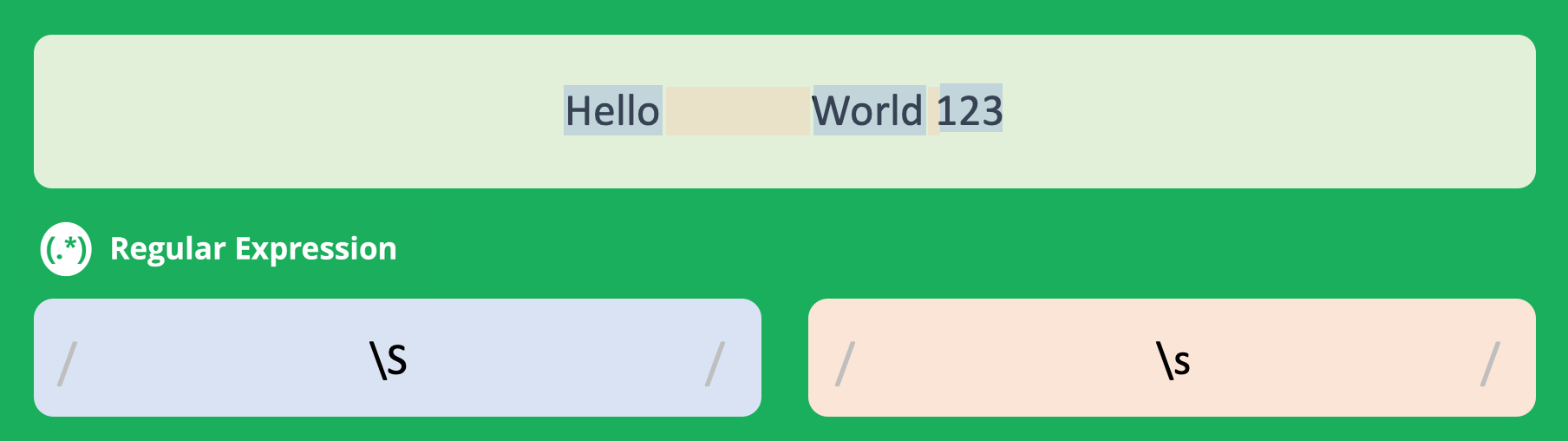
\s과 \S의 차이점을 확인하는 예제입니다.
집합을 위한 메타 문자
문자 클래스(Character Class)는 해당 위치에 어떤 문자가 올 수 있는지를 정의하는데 사용됩니다. 대괄호 [ ] 안에 문자를 나열하여 해당 위치에 하나의 문자가 일치하는지 확인합니다.
| 메타 문자 | 설명 |
|---|---|
[ ] | 한 쌍이 문자 집합을 정의하며, 집합 구성원 중에 한 문자만 일치하도록 합니다. (AND가 아닌 OR) |
^ | 대괄호 안에 작성되며 지정한 문자들을 제외한 모든 것들과 일치합니다. (대괄호 밖의 ^과 다른 의미를 가집니다)(ex. [^abc]: 'a', 'b', 'c'를 제외한 어떤 문자와 일치) |
- | 대괄호 안에 작성되며 범위를 설정할 수 있습니다. (대괄호 안에서만 메타 문자인 특수한 메타 문자) (ex. [0-9]: 0부터 9사이의 숫자) |

해당 예제에서 .xls 앞의 파일 이름이 3글자이고, 가운데는 a 그 다음은 숫자, 그리고 첫자리는 a부터 r사이가 아닌 문자열을 일치시킵니다.
반복, 조건, 대안을 위한 메타 문자
정규식 내에서 특정한 패턴을 표현하고자 할 때, 반복, 조건, 대안 등을 나타내기 위해 사용되는 메타 문자들은 다음과 같습니다.
| 메타 문자 | 설명 |
|---|---|
* | 앞 문자의 0회 이상의 반복(0번 포함)을 의미합니다. |
+ | 앞 문자의 1회 이상의 반복을 의미합니다. ({1,}과 같습니다) |
{ } | 중괄호 안의 숫자 만큼의 반복을 의미합니다. (ex. {3}: 3회 반복, {1, 3}: 1회부터 3회까지의 반복, {3,}: 3회 이상 반복) |
? | 앞 문자의 0또는 1회를 의미하며 앞 문자가 존재할 수도 아닐 수도 있음을 의미합니다. |
| ` | ` |

경계를 위한 메타 문자
정규 표현식은 텍스트의 어떤 구역이나 문자열의 특정 위치에서도 텍스트를 찾을 수 있습니다.
| 메타 문자 | 설명 |
|---|---|
\b | 단어의 일부로 사용하는 문자(영숫자 문자, 밑줄, \w와 일치하는 문자)와 그 외의 문자(\W와 일치하는 문자) 사이에 있는 위치와 일치합니다(실제로 문자와 일치하는 것이 아니고, 위치를 가리킵니다). |
\B | \b의 반대이며 단어 경계와 일치시키고 싶지 않을 때 사용합니다. |
^ | 문자열의 시작을 나타내는 문자열 경계(앵커)입니다. |
$ | 문자열의 끝을 나타내는 문자열 경계(앵커)입니다. |

위는 \b와 \B의 차이점을 확인하는 예제입니다.
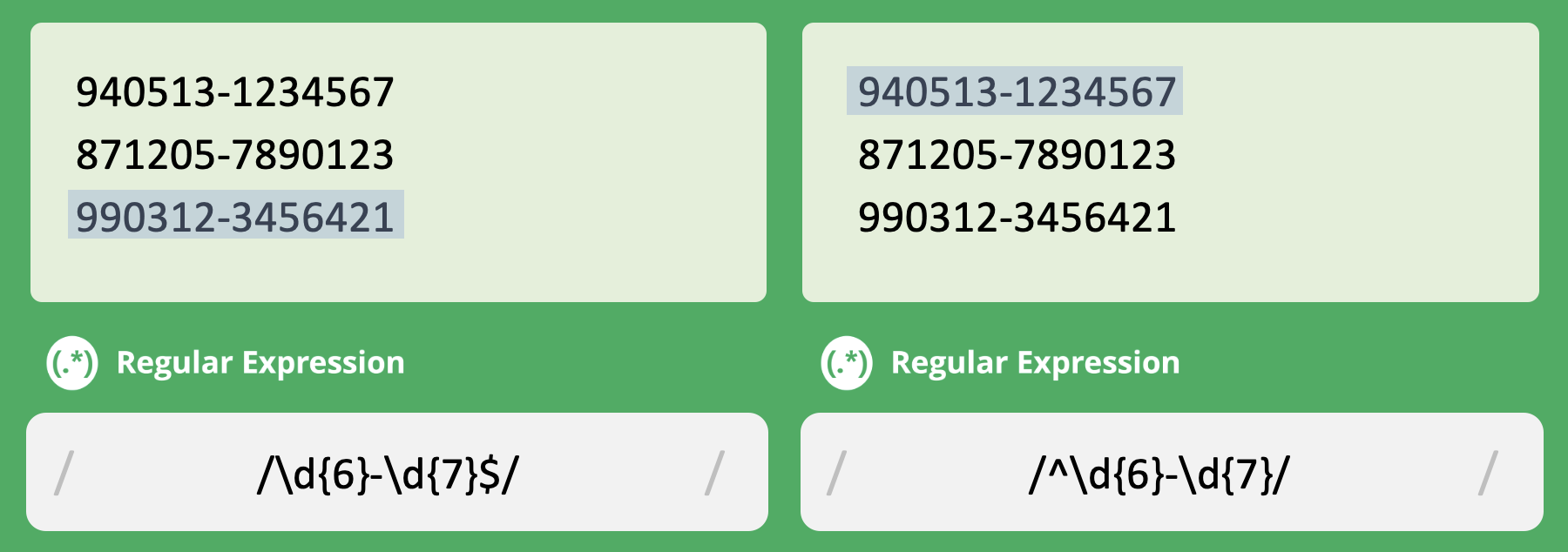
위는 ^와 $의 차이점을 확인하는 예제입니다.
그룹화(하위 표현식)를 위한 메타문자
그룹화 또는 하위 표현식(Grouping or Subexpression): 정규식에서 여러 문자열을 하나의 단위로 묶는 기능을 말합니다. 그룹화를 사용하여 여러 문자열을 하나의 그룹으로 처리하고, 이후 그룹 전체에 반복자 또는 메타 문자를 적용할 수 있습니다.
| 메타 문자 | 설명 |
|---|---|
( ) | 괄호로 묶인 부분은 하나의 그룹을 의미합니다. |

하위 표현식과 반복자를 활용해 ip 주소를 가져오는 정규식을 작성했습니다.
(\d{1,3}.){4}는 위에서 사용한 패턴을 대체하지 못합니다. 왜 그럴까요?
Usage - etc
정규식에서 주의해야 할 점은 중복되는 메타 문자는 하나의 의미만을 갖지 않는다는 것입니다. 상황에 따라 그 의미가 달라지기도 하며 이를 통해 많은 기능들을 제공합니다.
아래에서는 앞서 소개한 메타 문자들이 다른 의미를 갖게 되는 상황과 이를 통해 제공되는 기능을 예제와 함께 살펴보겠습니다.
Back Reference(역참조)
역참조(Backreference): 정규식에서 그룹화된 부분을 나중에 다시 참조하는 기능을 말합니다. 캡처 그룹으로 둘러싸인 부분을 저장하고, 이후 정규식 패턴에서 해당 그룹의 값을 재사용하는 데 사용됩니다. 역참조는 \숫자 형식으로 표현하며, 여기서 숫자는 그룹의 인덱스를 의미하합니다. (첫 번째 그룹은 \1, 두 번째 그룹은 \2와 같은 식으로 참조됩니다.)
(Java를 비롯한 몇몇 언어에서는 $를 사용)

위의 예제를 보면 빨간 글씨의 부분은 <h2>태그와 </h3>태그가 일치하지 않기 때문에 선택되면 안됩니다.
역참조를 사용하지 않은 정규식은 의도되지 않은 부분도 일치시키는 반면, 역참조를 이용한 정규식은 의도한 부분들만 일치시키는 것을 확인하실 수 있습니다.
탐욕적 수량자와 게으른 수량자
탐욕적인 수량자(Greedy Quntifiers): 가능한한 가장 큰 범위의 문자열을 매칭하려고 하는 수량자입니다. 기본적으로 수량자(반복자)는 탐욕적입니다. 탐욕적 수량자는 최대한 많은 문자를 일치시키려고 하기 때문에 전체 문자열에 대해 한 번의 매칭을 시도합니다. (ex. *, +, {n,}, ...)
게으른 수량자(Lazy Quntifiers): 가능한한 가장 작은 범위의 문자열을 매칭하려고 하는 수량자입니다. 게으른 수량자는 ?와 같은 수량자 뒤에 ?를 추가하여 사용합니다. 이렇게 하면 해당 수량자는 가능한한 적은 문자를 일치시키려고 하며, 필요한 경우 더 많은 일치를 찾기 위해 추가 검색을 시도합니다. (ex. *?, +?, {n,}?, ...)

탐욕적 수량자를 사용했을 때에는 <b>AK</b>and<b>HI</b>가 일치되지만, 게으른 수량자인 *?를 사용하면 먼저 <b>AK</b>만 일치시키고, 뒤이어 <b>HI</b>를 찾아 두 부분을 따로 일치시킬 수 있습니다.
전방 탐색과 후방 탐색
전방 탐색 (Positive Lookahead): 주어진 패턴 뒤에 특정 패턴이 존재하는지 확인하는 기능입니다. 이것은 일치할지 여부를 결정하지 않고, 검사만 하며 실제로 일치된 부분에는 포함되지 않습니다. 전방 탐색은 (?=pattern) 형태로 사용됩니다.
후방 탐색 (Negative Lookbehind): 주어진 패턴 앞에 특정 패턴이 존재하지 않는지 확인하는 기능입니다. 이것은 일치할지 여부를 결정하지 않고, 검사만 하며 실제로 일치된 부분에는 포함되지 않습니다. 후방 탐색은 (?<=pattern) 형태로 사용됩니다.
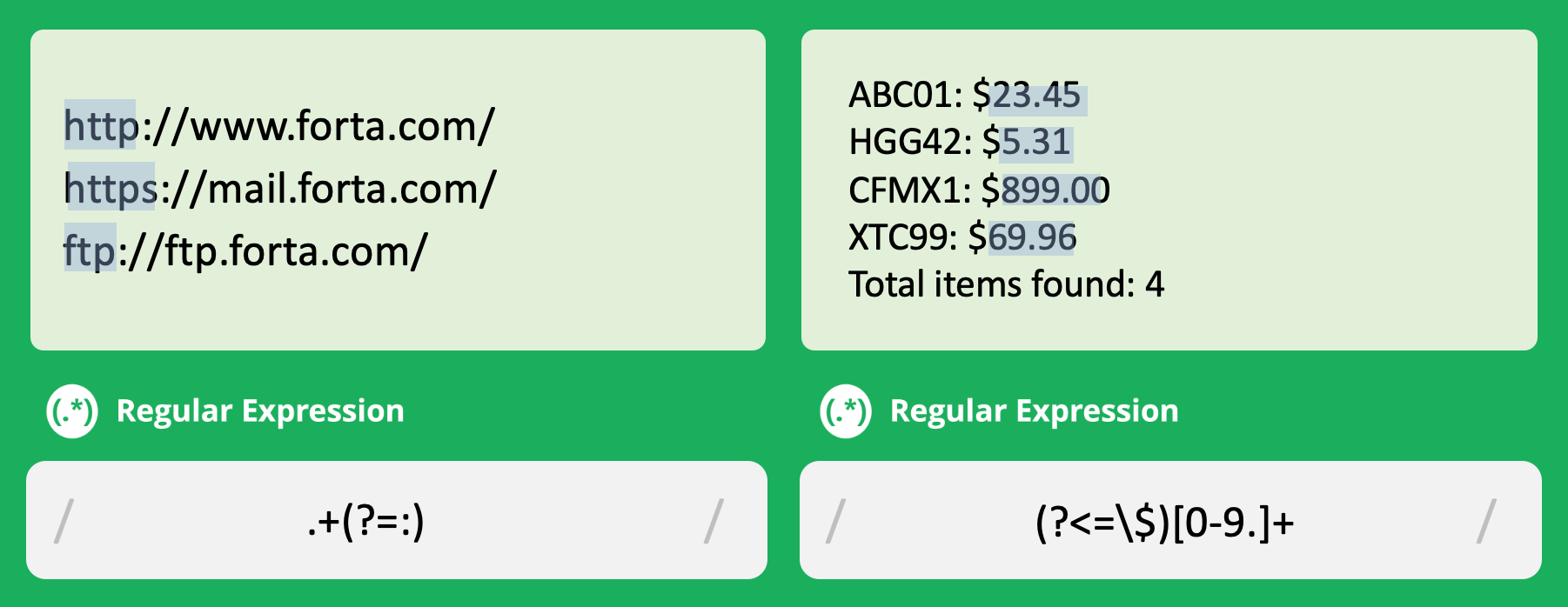
왼쪽은 https:에서 전방 탐색을 통해 :을 제외하고 문자열을 일치시키는 정규식입니다. 만약 .+:와 같이 작성했다면 세미콜론을 포함해 일치시켰을 것입니다. 그렇다고 만약 .+를 작성 했다면.. 의도하는 정규식은 아닐 것입니다.
마찬가지로 오른쪽도 후방 탐색을 통해 $를 제외하고 문자열을 일치시킵니다.
부정형(negative) 전후방탐색: 부정형 전방탐색은 앞쪽에서 지정한 패턴과 일치하지 않는 텍스트를 찾고, 부정형 후방탐색도 이와 비슷하게, 뒤쪽에서 지정한 패 턴과 일치하지 않는 텍스트를 찾는 방식입니다. 부정형 전방 탐색은 (?!pattern) 형태로 사용되고, 부정형 후방 탐색은 (?<!pattern) 형태로 사용됩니다.

해당 예제에서는 부정형 후방 탐색을 활용해 $가 없는 숫자만 일치시키도록 했습니다.
Named capturing group
네임드 캡처링 그룹(Named Capturing Group): 정규식에서 일치하는 부분을 그룹화하여 쉽게 참조할 수 있도록 이름을 지정하는 기능입니다. 기본적인 그룹화 기능과 함께 이름을 부여하여 정규식에서 일치한 부분을 더 쉽게 처리할 수 있도록 도와줍니다.
(?<name>pattern) 형태로 정규식에서 사용되며, 여기서 name은 그룹에 부여할 이름이고, pattern은 해당 그룹과 일치하는 패턴입니다.
해당 예제는 JavaScript를 통해 작성해 보도록 하겠습니다. (Python은 (?P<name>pattern), Java는 (?<name>pattern))
// 이름, 성, 전화번호가 공백으로 구분된 문자열을 파싱하기 위한 정규 표현식
const personalInfo = /(?<firstName>[\w]+)\s+(?<lastName>[\w]+)\s+(?<number>[\d]+)/;
// test할 문자열
const test = "Harry Potter 01012345678";
console.log(test.match(personalInfo));
/* 출력:
[
'Harry Potter 01012345678',
'Harry',
'Potter',
'01012345678',
index: 0,
input: 'Harry Potter 01012345678',
groups: [Object: null prototype] {
firstName: 'Harry',
lastName: 'Potter',
number: '01012345678'
}
]
*/
console.log(test.match(personalInfo).groups.number);
// 출력: 01012345678검증과 추출을 나눠서 할 필요 없이, groups라는 필드로부터 원하는 시점에 캡처링한 영역을 참조할 수 있습니다.
마치며
정규 표현식은 코드 작성과 마찬가지로 원하는 동작을 위해 작성될 수 있는 패턴은 굉장히 다양합니다. 정규 표현 언어는 언어의 한 형태이지만, 직관적이거나 명확하지 않기 때문에 작성한 패턴을 테스트 해보기 위해서, 많은 시도들이 요구될 것입니다.
모든 언어가 문법뿐만 익히는 것이 아니라 사용하면서 익숙해지듯이, 정규 표현식 또한 사용하면서 숙달되어야 합니다. 이를 위해 해당 글 외에 여러 테스트 사이트에서 다양한 시도를 해보며 정규식에 익숙해지는 것을 추천드립니다.
정규 표현식을 통달하는 과정에서 구문을 익히는 것은 가장 쉬운 부분 임을 알고 있어야 한다. 진정한 도전 과제는 그 구문을 어떻게 적용할 것인지, 주어진 문제를 어떻게 분해해야 정규 표현식으로 해결할 수 있는지 익히는 것이다. 이런 것은 단순히 책만 읽어서는 익힐 수 없다. 다른 모든 언어와 마찬가지로 연습을 통해서만 숙달할 수 있다.
벤 포터 저 / 김경수 역. 『손에 잡히는 정규식』. 인사이트(insight). 2009년 07월 31일
긴 글 읽어주셔서 감사합니다🙇🏻. 다음에 더 좋은 글로 돌아오겠습니다.
참고
- chat GPT
- 벤 포터 저 / 김경수 역. 『손에 잡히는 정규식』. 인사이트(insight). 2009년 07월 31일
- Lellow Mellow의 마법같은 정규 표현식



잘 읽었습니다. 혹시 예시에서 사용중인 사이트가 뭔지 알 수 있을까요?