자료구조
컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다.
더 정확히 말해, 자료 구조는 데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령을 의미한다.
배열
가장 기본적인 자료 구조
-
homogeneous collection :
동일한 데이터 타입만 관리 가능(파이썬은 …?)- 타입이 다른 객체를 관리하기 위해서 매번 다른 배열이 필요
-
- Object를 이용하면 모든 객체 참조 가능 → Collection Framework
- 담을 때는 편리하지만 빼낼 때는 Object로만 가져올 수 있음
- 런타임에 실제 객체의 타입 확인 후 사용해야 하는 번거로움 ← 어쩌다 한번씩 발생… 컴파일 시에 체크 불가…🥲
-
Generic을 이용한 타입 한정(Generic이 궁금하면…? 여기로!!)
- 컴파일 타임에 저장하려는 타입 제한 → 형변환의 번거로움 제거 😀
Collection Framework
java.util패키지에 존재-
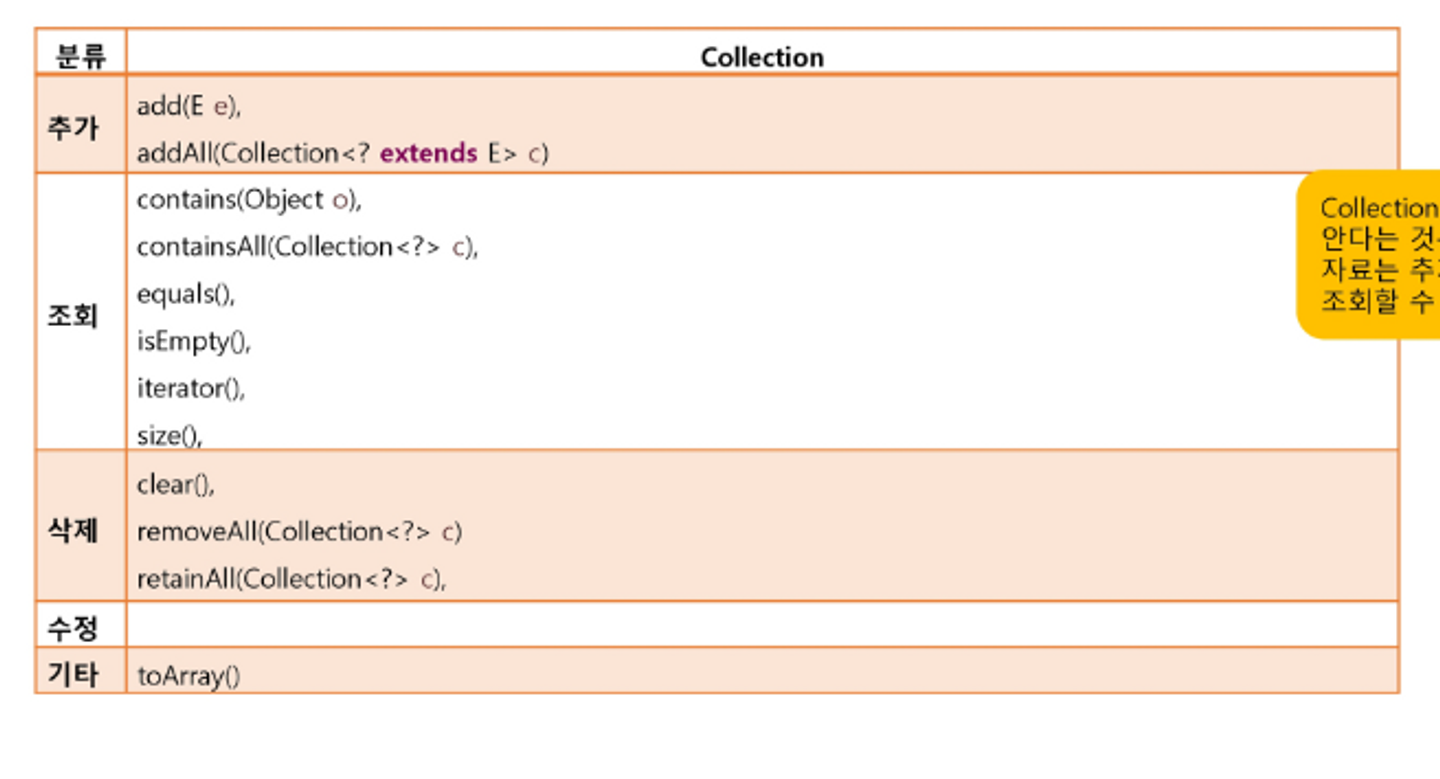
다수의 데이터를 쉽게 처리하는 방법 제공 → DB처럼 CRUD 기능!!! CRUD는 뭐지…?(나중에 알려줄게~~~)
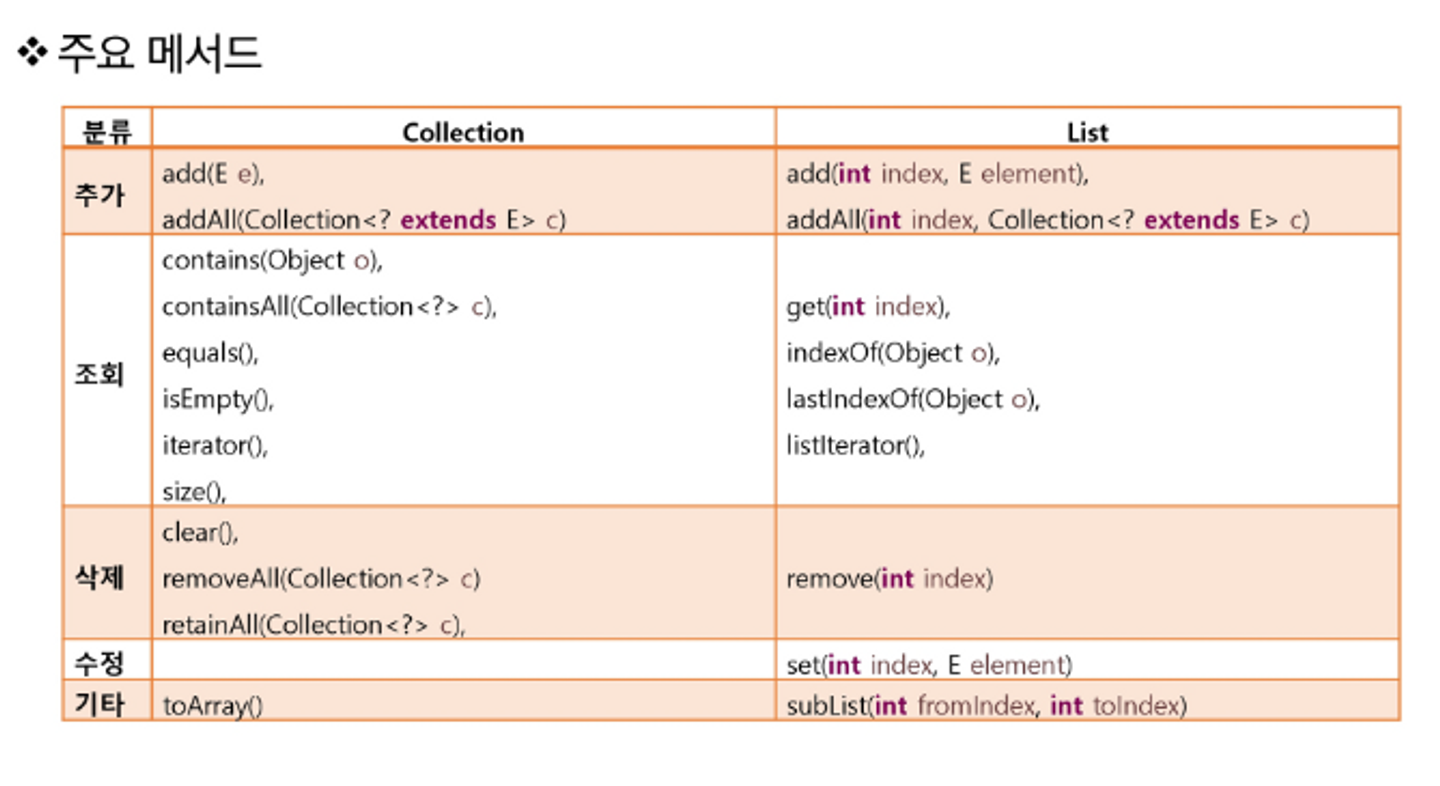
👍 살짝만 알려준다면… C : CREATE (추가) R : READ (조회) U : UPDATE (수정) D : DELETE (삭제)
-
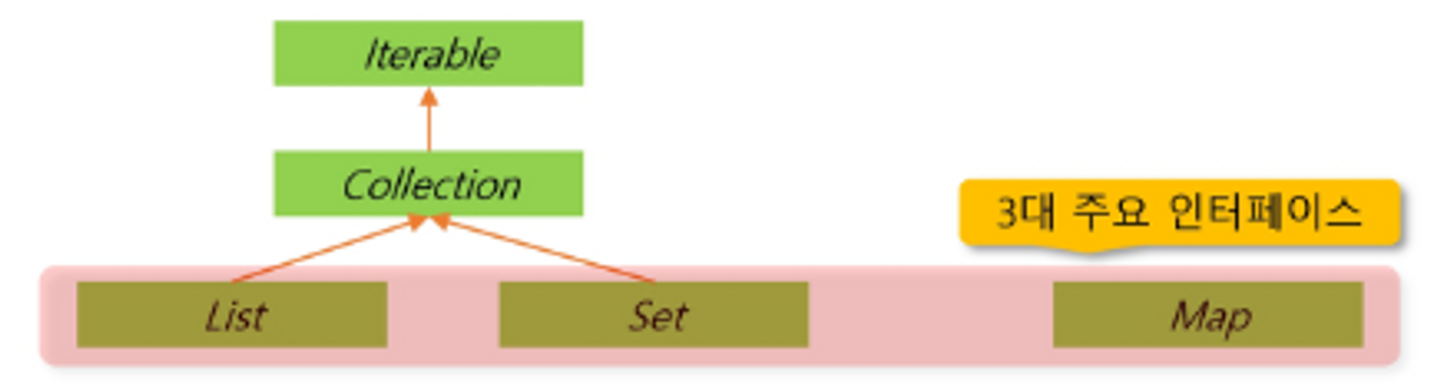
- collection framework 핵심 interface
<aside>
✋ 잠깐!!! Iterable은 뭘까???
Iterable하다는 것은 반복이 가능하다는 것!!!!
</aside>- ㅇㅎCollection에서는 CRUD를 이렇게 쓰는구나!!
List 계열
순서가 있는 데이터의 집합. 순서가 있으니까 데이터의 중복을 허락
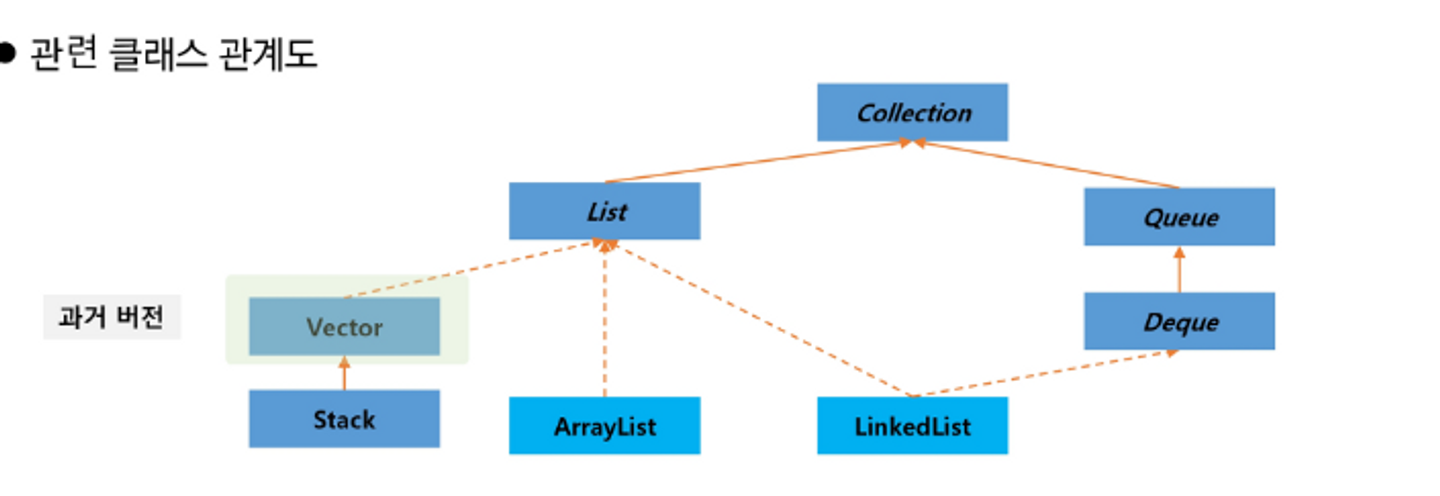
List 역시 Collection을 상속받는구나!
움… 왜 배열이랑 비슷한 거 같은데 크기가 자동으로 늘어나지…?
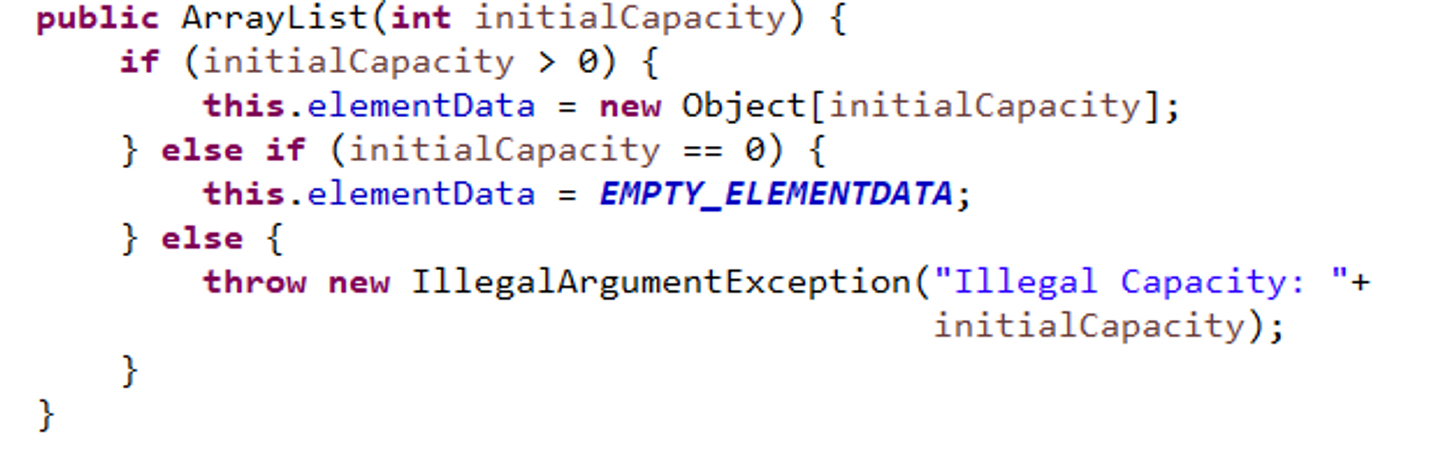

grow라는 함수가 정확히 어떻게 동작하는지는 모르겠지만 호출되면서 크기를 자동적으로 늘려주는구나
그러면 배열을 쓸 필요가 없는건가요?? 🤔
💡 ArrayList는 배열을 기반으로 만들어졌기 때문에 배열과 장단점이 같다고 볼 수 있다!!배열의 장점
- 가장 기본적인 형태의 자료 구조로 간단하며 사용이 쉬움
- 접근 속도가 빠름
배열의 단점
- 크기를 변경할 수 없어 추가 데이터를 위해 새로운 배열을 만들고 복사해야 함
- 비 순차적 데이터의 추가, 삭제에 많은 시간이 걸림
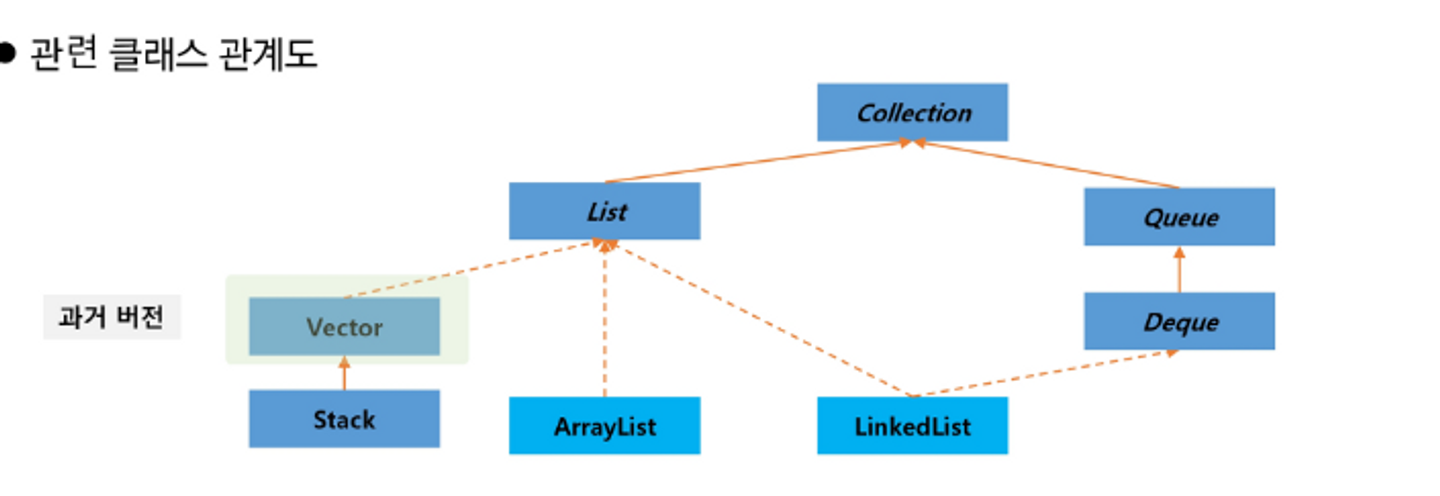
LinkedList
💡각 요소를 Node로 정의하고 Node는 다음 요소의 참조 값과 데이터로 구성됨
ArrayList와 뭐가 다르지??
Node가 다음 요소에 대한 링크 정보를 가지고 있어서 연속적으로 구성될 필요가 없다구~~
그러니까… ArrayList는 순차적으로 데이터가 들어가 있으니까 삭제나 삽입을 할때 데이터를 전체적으로 옮겨줘야하지만 LinkedList는 Node가 가지고 있는 다음 요소의 링크 정보만 바꿔주면 된다구~~(자료구조 시간에 배웠지롱~)
remove를 사용할 때 주의 사항
List<Integer> l = new ArrayList<>();
l.add(1);
l.add(2);
l.add(3);l에 있는 1을 지우고 싶다면 어떻게 해야할까?
l.remove(1)을 하게 되면 1번 인덱스의 값이 지워진다…
때문에 l.remove(Integer(1))를 사용해서 객체의 형태로 전달해줘야한다.
ArrayList의 동적 사이즈

반복문에서 ArrayList의 요소를 삭제하면 크기가 변하기 때문에 예상과 다른 결과가 나오는구나!!!

forEach는 크기가 변하지 않는 Collection에서 사용할 수 있구나!!!
Set 계열
순서를 유지하지 않는 데이터의 집합. 순서가 없어서 같은 데이터를 구별할 수 없음 → 중복 허락 하지 않음
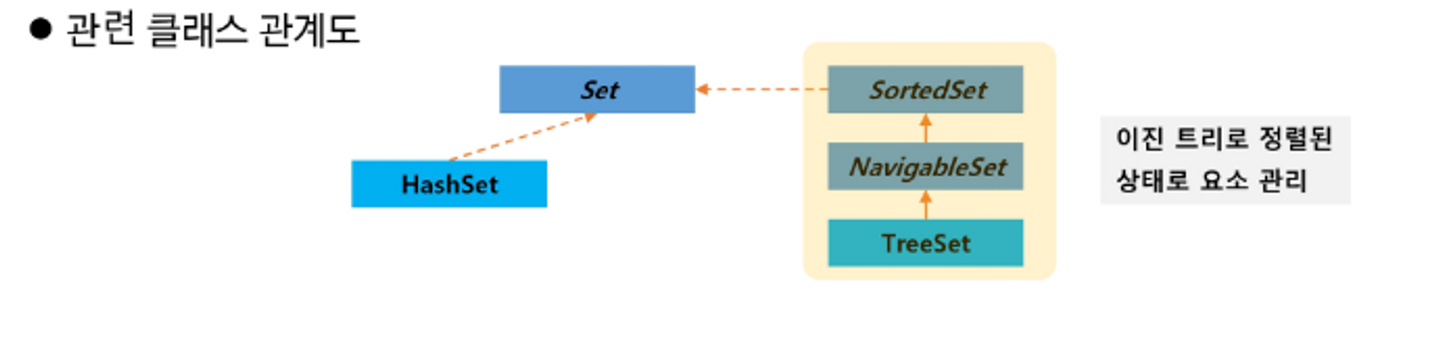
List와 다르게 순서가 없으니까… 데이터를 인덱스로 접근할 수 없겠구나!!!! 그러면… 데이터를 수정할 수 없겠네???
동일한 데이터의 기준
Set<Object> friends = new HashSet<Object>();
friends.add(new SmartPhone("010"));
friends.add(new SmartPhone("010"));
System.out.println("데이터 추가 결과: " + friends);왜 똑같은 값이 중복 저장되지…?
equals와 hashCode를 재정의 해줘야하는구나
즉, 중복될 데이터를 직접 처리해줄 수 있다.
Map 계열
👍 Map은 key로 중복을 체크하는구나~~ 😝key와 value의 쌍으로 데이터를 관리하는 집합. 순서는 없고 key의 중복 불가, value는 중복 가능

entry = key + value
Map은 순서는 없지만 key와 value의 쌍으로 되어있어서 데이터의 위치 접근이 가능하구나!
💡 추가 함수와 수정 함수의 이름이 똑같네…? key가 없을 때만 데이터를 추가하고 싶은데 어떻게 하지…? → `putIfAbsent(key, value)`를 사용정렬
선택정렬
배열의 데이터를 선택해서 정렬하는 정렬 기법
방법 : 가장 작은 데이터를 찾아서 맨앞의 데이터와 체인지
예시
배열 : 3 5 2 9 6
1단계
2 5 3 9 6
2단계
2 3 5 9 6
3단계
2 3 5 9 6
4단계
2 3 5 6 9
Comparator의 활용
익명클래스
내부클래스의 한 종류
- 클래스의 내용정의 + 객체의 생성
- 형식
익명클래스에서 인터페이스를 생성한다면 인터페이스의 메소드를 재정의해줘야한다. 즉,new 부모클래스 | 부모인터페이스() { 클래스의 내용 }new (클래스의 선언부) + (implements) + 인터페이스의 형태로 괄호를 생략하고 작성해줄 수 있다. 💡 인터페이스를 생성할 수는 없기 때문에 ```java Arrays.sort(arr, new Comparator() { @Override public int compare(Data o1, Data o2) { return o1.year - o2.year; } }); ``` 위의 코드에서 `new Comparator()`는 인터페이스를 생성한 것이 아니라 인터페이스를 상속받는 `이름없는` 클래스 즉, `익명클래스`를 선언한 것!!!!
매번 익명클래스를 선언하는 거 귀찮은뎅…. 🤔 → 그래서 나온게 람다 표현식!!!
Arrays.sort(arr, (o1, o2) -> o1.year - o2.year);이렇게 바꿔 쓸 수 있지
❓ 그러면 람다 표현식에서는 어떤 메소드를 재정의하는지 어떻게 알지?
@FunctionalInterface라는 어노테이션을 붙여놓은 인터페이스는 재정의해야될 메소드를 하나만 가지고 있구나! ← 컴파일러가 구별해주니까 편리
Arrays.sort(arr, (o1, o2) -> {
return o1.year - o2. year;
});함수의 구현부가 한!문!장!일 경우에는 → 뒤에 리턴할 값만 써주면된다!!!!
test((String msg) -> {
return "{{" + msg + "}}"
});test((msg) -> {
return "{{" + msg + "}}"
});test((msg) -> "{{" + msg + "}}");test(msg -> "{{" + msg + "}}");