
2일에 걸친 삽질의 결과를 기록해두려고 한다.
문제는 멘토들을 상담 유형 별로 적절히 배치해 상담 대기 시간을 최소화 하는 것이 목적이다.
Greedy 풀이 시도
문제를 읽고 가장 먼저 떠올린 생각은 상담 유형에 멘토들을 1명씩 배치한 후 각 유형에 멘토들을 추가해 가며 가장 대기 시간이 적은 배치를 계속해서 선택하는 것이다.
무슨 말이냐면 유형이 3개 멘토가 5명이라면 (1, 1, 1)에서 (1, 1, 2), (1, 2, 1), (2, 1, 1) 중에서 (1, 2, 1) 배치의 대기 시간이 가장 적었다면, 다음 배치 때는 (2, 2, 1), (1, 3, 1), (1, 2, 2) 의 대기 시간을 비교하는 것이다.
멘토를 한명씩 배치할 때마다 최선의 선택을 하면 결과적으로도 가장 대기 시간이 적어지지 않을까? 라는 생각에 떠올린 풀이다.
from heapq import heappush, heappop
def cal_spend_time(mentorList, waitList, k):
time = 0
for _type in range(k): # 타입 별로 대기 시간 계산
endTime = []
for _start, _spend, t in waitList: # start_time, spend_time, type
if t != _type + 1:
continue
if mentorList[_type] > 0:
heappush(endTime, _start + _spend)
mentorList[_type] -= 1
else:
if _start < endTime[0]:
time += endTime[0] - _start
heappush(endTime, endTime[0] + _spend)
heappop(endTime)
return time
def solution(k, n, reqs):
mentors = [1] * k
greedy = [1e9] * (n)
for i in range(k - 1, n):
if sum(mentors) < n:
idx = 0
for j in range(k):
mentors[j] += 1
time = cal_spend_time(copy(mentors), reqs, k)
if greedy[i] > time:
idx = j
greedy[i] = time
mentors[j] -= 1
mentors[idx] += 1
else:
greedy[i] = cal_spend_time(copy(mentors), reqs, k)
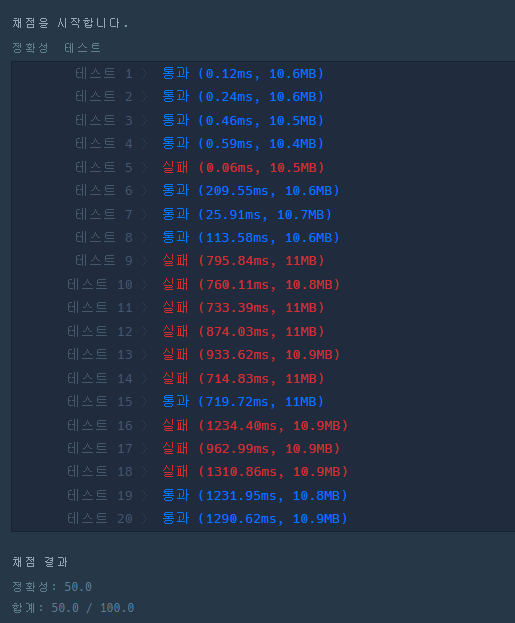
return greedy[n-1]하지만 단 3개만 통과하고 나머지는 Fail이었다. 그리디로 풀면 답이 다른가 해서 시도한 방법이 완전탐색 이었다.
완전탐색 풀이 시도
바로 완전탐색 풀이를 시도했다. 가능한 모든 멘토들의 배치를 구한 후 각 배치의 대기 시간을 측정해서 비교하는 것이다.
모든 멘토드의 배치를 구할 때 사용한 방법에서 한두번의 삽질이 있었다.
첫번째 방법
cases = set()
for comb in combinations_with_replacement([i for i in range(1, k + 1)], r=k):
if sum(comb) == n:
for perm in permutations(comb, k):
cases.add(perm)k == 3, n == 5 일때를 예시로 들어보자.
첫 반복문에서 [1, 2, 3]으로 이루어진 중복 조합을 만들기 위해 combinations_with_replacement를 사용한다.
위로부터 만들어진 조합의 합이 n(= 5)이 되는 경우인 [1, 1, 3], [2, 1, 2], ... 를 사용해 가능한 모든 순서를 반환하는 permutation을 사용한다. 하지만 이상하게도 몇가지 테스트 케이스에서 오류가 발생했다.
두번째 방법
이건 꽤 간단히 수정할 수 있었다.
cases = set()
for comb in combinations_with_replacement([i for i in range(1, n - k + 2)], r=k):
if sum(comb) == n:
for perm in permutations(comb, k):
cases.add(perm)가질 수 있는 조합 원소 중 최대값은 n - k + 2 이다. 따라서 1 이상 n - k + 2 이하의 수로 중복 조합을 구하면 모든 멘토의 조합을 찾을 수 있다.
이제 각 case에 대해서 최소 대기 시간을 계산하면 된다.
def cal_wait_time(waitings, n): # 유형 별 waiting_list에 n명의 상담 원이 있을 때 대기 시간 계산
total_time = 0
counsel_list = []
for _ in range(n):
heappush(counsel_list, 0)
for start, duration in waitings:
prev_end = heappop(counsel_list) # 자리가 생기는 시간
if start > prev_end: # 바로 상담 가능
heappush(counsel_list, duration)
else:
wait_time = prev_end - start
total_time += wait_time
heappush(counsel_list, duration + wait_time)
return total_time누가 상담을 하던 가장 빨리 끝나는 시간이 기준이 되어야 하므로 heap을 사용했다.
상담 중인 사람들 중 가장 빨리 끝나는 사람의 종료 시간 prev_end과 그 다음 순번인 사람의 시작 시간 start의 차이가 대기 시간 wait_time이다.
대기 시간 wait_time과 소요 시간duration의 합이 이번 차례 사람의 종료 시간이 된다.
이제 코드를 모두 합치면 아래와 같다.
최종 코드
from heapq import heappush, heappop
from itertools import combinations_with_replacement, permutations
def solution(k, n, reqs):
def cal_wait_time(waitings, n): # 유형 별 waiting_list에 n명의 상담 원이 있을 때 대기 시간 계산
total_time = 0
counsel_list = []
for _ in range(n):
heappush(counsel_list, 0)
for start, duration in waitings:
prev_end = heappop(counsel_list) # 자리가 생기는 시간
if start > prev_end: # 바로 상담 가능
heappush(counsel_list, duration)
else:
wait_time = prev_end - start
total_time += wait_time
heappush(counsel_list, duration + wait_time)
return total_time
result = 1e9
waiting_list = [[] for _ in range(k)]
for req in reqs:
waiting_list[req[2] - 1].append([req[0], req[0] + req[1]])
cases = set()
for comb in combinations_with_replacement([i for i in range(1, n - k + 2)], r=k):
if sum(comb) == n:
for perm in permutations(comb, k):
cases.add(perm)
for case in cases:
time = 0
for i in range(k):
time += cal_wait_time(waiting_list[i], case[i])
result = min(result, time)
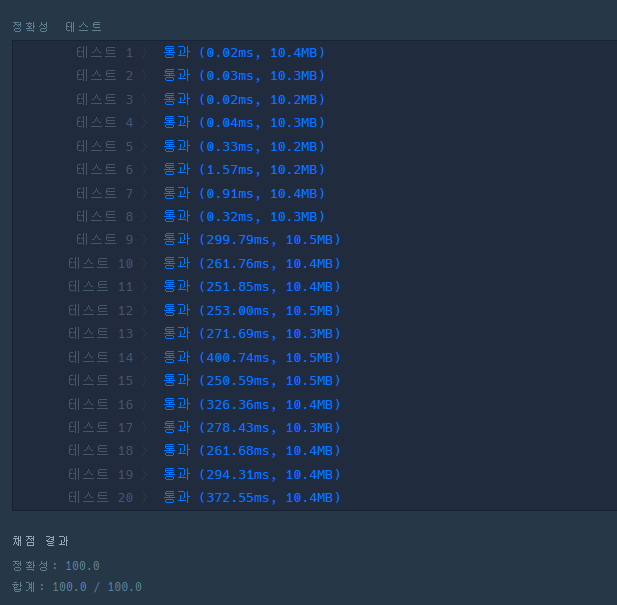
return result결과

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.