
RUS about paper
Stable Diffusion에 대해 알아보던 도중, [High-Resolution Image Synthesis with Latent Diffusion Models] 논문 리뷰를 간결하게 잘 해놓은 영상이 있어 해당 내용을 공부할 겸 속기한 것을 기록해두려고 한다. 유용한 자료를 남겨주신 분들께 무한한 감사를 전하고 싶다. 이분들처럼 공부하고 요약할 수 있는 능력이 생겼으면 좋겠지만 나는 너무 게으름. 링크는 Reference에 기록해두었으니 관심있는 분들은 한번 보면 좋을 것 같다.
Prerequisite

최근 Text-to-Image 생성 모델이 많은 관심을 받고 있다. DELL-E나 Image GAN 같은 모델 이 있고 Stable Diffusion이 가장 핫한 모델이다.
Stable Diffusion같은 경우 다른 모델들과 다르게 컴퓨터 사용 리소스가 대폭 줄어서 4GV 이하의 V-LAB에서도 돌릴 수 있다. 따라서 현재 API들이 굉장히 많이 나오고 있는 모델로, 주어진 문장에 맞게 사람이 이해해도 semantic하게 납득이 가는 이미지를 잘 생성해낸다.

VAE(variational auto encoder)같은 경우 이미지와 같은 고차원 데이터를 encoding을 통해 저차원 space로 맵핑시킨 다음, 다시 decoder를 이용해 생성해낸다. encoding을 이요해서 이미지에 고차원을 저차원으로 줄이는 개념은 사실상 주성분 분석과 같은 PCA(principal component analysis), 즉 성분분해의 개념과 굉장히 유사하다고 볼 수 있다. 따라서 이러한 의미 정보를 담는 차원의 공간을 latent space라 하고, 이 latent space에 들어가는 변수들을 latent variable이라 한다. decoder 같은 경우에는 latent variable을 받아서 다시 이미지를 복원시키는 역할을 하고 있다.
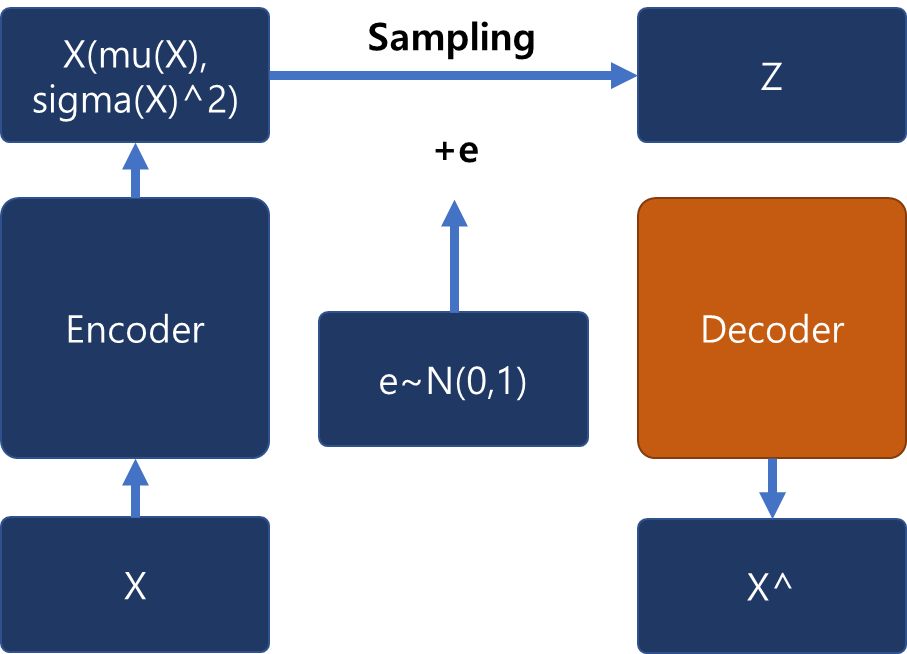
X가 데이터라고 가정했을 때 X가 encoder 안에 들어가서 Z, 즉 latent varible로 맵핑하기 위해서 1) 평균과 분산을 통해 분포를 표현 가능한 정규분포 방식의 샘플링을 사용하고, 그냥 정규분포 방식을 이용해서 Z를 샘플링하는 것이 아니라 2) 샘플링하는 과정에서 노이즈를 더해줘서 미분가능한 함수로 바꿔준 후에 3) 그 함수를 학습시키는 방식으로 유도해낸다.
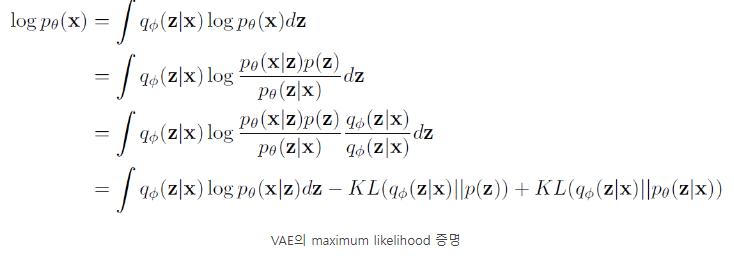
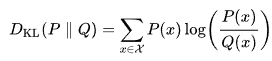
(위의 두번째 식은 Kullback-Leiber divergence)
auto encoder에서 궁금한 점은 결국 X를 만들어내는 p와 같은 함수를 찾는 것이다. Z로 한번 압축을 한 후, 이 Z를 전제로 했을 때 X를 만들어 내는 조건부 확률을 최대화하는 방식으로 학습을 진행한다.

최종적인 VAE loss 같은 경우, objective function같은 경우 Z를 베이스로 했을 때 X를 만들어내는 함수를 유도해내는 것이 그 목표라 할 수 있다.
따라서 Z로부터 X가 나타날 확률을 최대화하는 것으로 maximum likelihood estimation을 하게 되면서 이를 cross-entropy와 같은 방식으로 표현하게 된다. KL divergence 공식 같은 경우에는 이미 p(z), 즉 latent space를 만들 때 함수를 이미 알고 있고 X에서 Z를 만들 함수를 알고 있으므로 두 함수의 분포차는 최소한의 bound가 되는 lower bound가 된다. 그래서 regularizaion term으로 이 공식을 사용한 것을 확인할 수 있다.
Diffusion Model Process
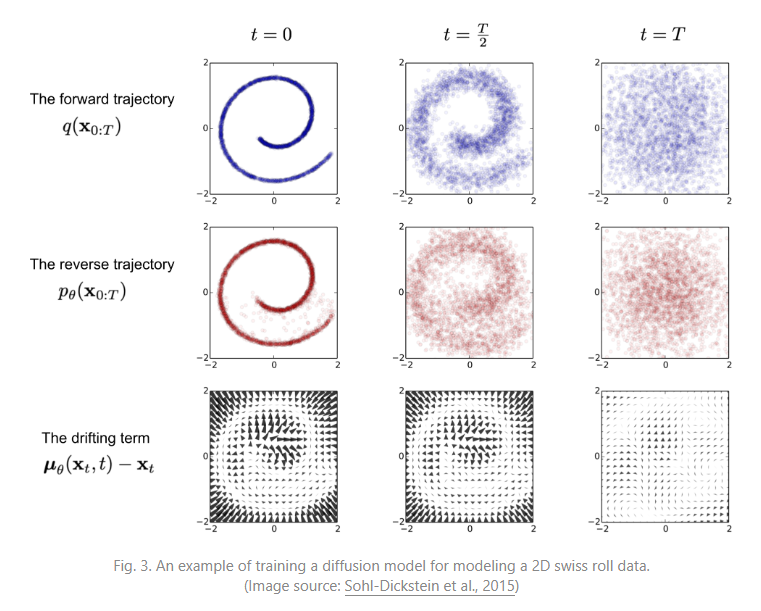

(위의 첫번째 그림은 Forward Diffusion Process)
auto encoder가 노이즈를 한번에 더하는 방식으로 노이즈를 더했다면, diffusion 같은 경우 노이즈를 더하는 과정 자체를 여러 step으로 나눠서 진행한다. 각각의 step이 하나의 함수가 되어 이 step이 진행될 때마다 원본의 이미지가 조금 더 가우시안 분포에 가까워지는 과정을 diffusion process라 부른다.
함수식을 보면 t-1시점의 x가 t시점으로 변화할 수 있는 forward 함수를 Markov Chain으로 형성한 것이 전체적인 process의 정의라 볼 수 있다. 이를 Markov Diffusion Kernel이라 부른다. 그리고 β라는 파라미터를 사용하게 되는데 βt 파라미터는 t0시점부터 t시점까지의 변환을 몇번이나 길게 가져가게 되느냐, 즉 step을 얼마나 촘촘하게 가져가게 되느냐를 결정해주는 파라미터라 보면 된다.
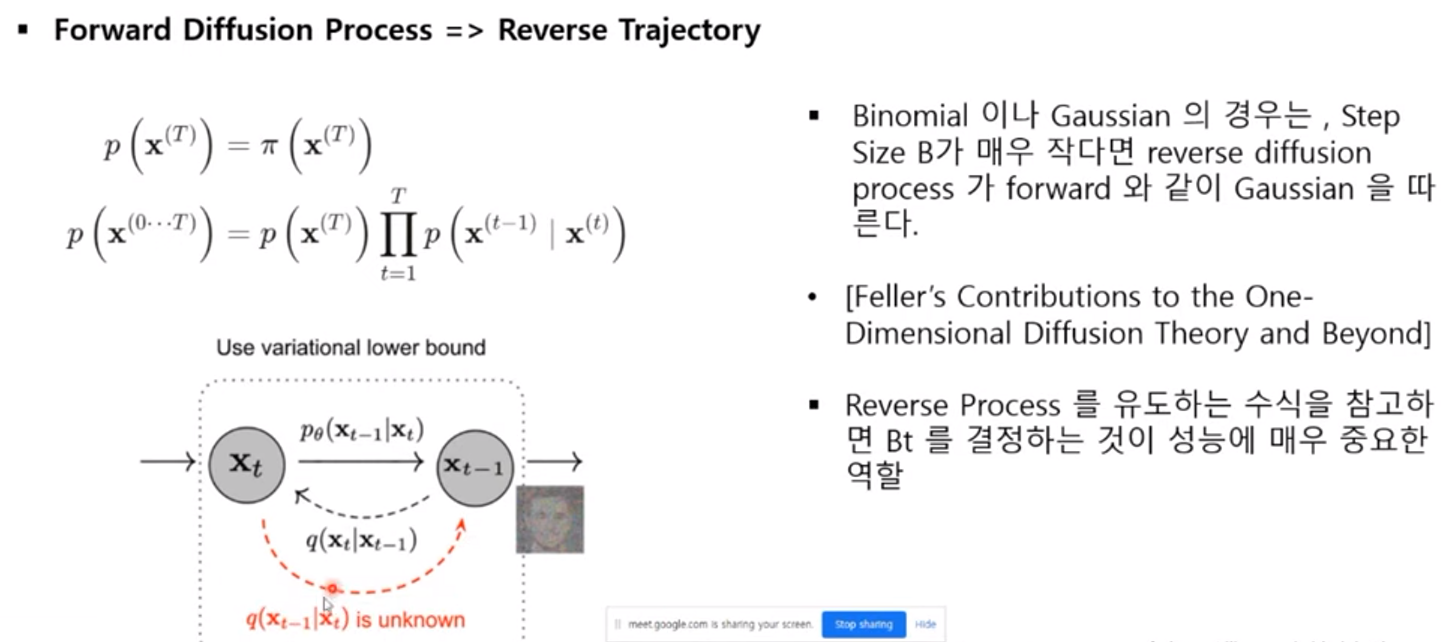
앞에서 process 했던 함수들은 이미 알고 있는 함수로, 궁금한 함수는 그 함수들의 inverse 함수에 초점을 맞추고 학습을 진행하게 된다. 다시 말해서 앞선 함수는 t-1시점에서 t시점을 추론하고, 그 함수의 inverse 함수는 반대로 t시점에서 t-1시점을 추론한다. 위의 그림과 같은 경우 앞이 노이즈 이미지이고, 이 이미지에서 다시 원본 이미지를 만들어내는 함수를 추론해내는 것이 목표이다. 따라서 여기서는 파라미터로 β가 주어진다. β같은 경우 step 사이즈가 노이즈를 주입하는 step이 매우 작다면, 그 reverse function 또한 비슷한 분포를 따를 수 있다는 전제를 깔게 된다. 이러한 전제를 깔고 가면 이 βt를 결정하는 것이 reverse process를 얼마나 잘 추론해낼 수 있느냐에 대해서 중요한 역할을 한다.
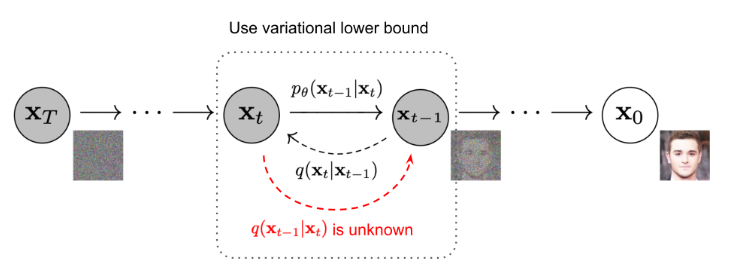
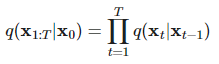
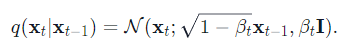
앞에서 언급한 노이즈에서 다시 원본 이미지를 추론해내는 과정인 xt에서 t-1시점을 추론해내는 함수를 구하는 것이 목표이다.
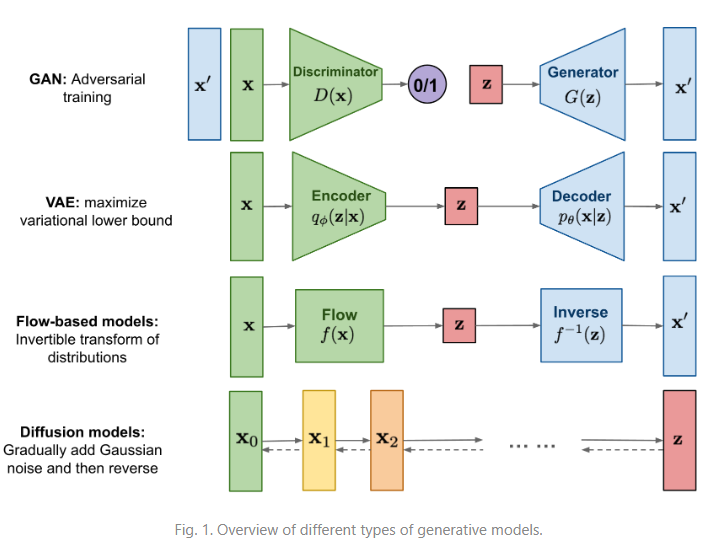
위의 그림은 생성모델로 유명한 GAN과 auto encoder, 그리고 diffusion encoder의 전체적인 아키텍처를 정리해놓은 표이다. auto encoder는 원본 이미지가 들어왔을 때 encoder를 통해 latent variable로 표현해내고 latent variable을 다시 디코더를 통해서 이미지를 추론해내는 전체적인 과정이다. encoder에서 decoder까지의 과정을 diffusion 모델들은 step을 나누어서 진행하게 된다.

본 논문은 아키텍처 중심의 논문이다. VAE의 노이즈 과정과 diffusion 모델의 노이즈 과정을 섞는데, X input값에서 encoder를 해서 latent variable을 만들어내는 것까지는 auto encoder의 과정과 유사하다. latent vector 상에서 diffusion 모델이 했던 것처럼 forward process를 통해 노이지를 주입하고, 그것을 다시 decoder로 풀어내는 과정은 auto encoder와 동일하다.
Architecture
pixcel space 상에 encoding을 해서 latent vector들를 뽑아냈을 때의 diffusion process, 그리고 뽑아낸 후에 latent variable들을 다시 denoising 해내는, decoder로 옮기는 과정은 다시 step-by-step으로 나누어 주어 각각의 step은 UNET 구조의 함수로 이루어지게 된다. 이러한 전체적인 아키텍처를 가지고 그 생성 모델의 역할을 해야되는 것을 볼 수 있다. conditioning 같은 경우에는, 예를 들어서 텍스트나 이미지, 혹은 다른 도메인의 데이터들이 들어왔을 때 그 데이터들을 각각의 스텝에서 attention mechanism을 통해서 학습하게 된다.
Key Points of Stable Diffusion
- denosing 과정에서 auto encoder를 사용한다.
- pixcel 공간이 아닌 latent space에서 denoising을 진행하면서 수백개의 GPU가 필요한 computing cost를 줄인다.
- 모델의 복잡성이 감소하고, 세부적인 표현능력이 상승한다.
- 아키텍처 상에 cross-attention을 사용함으로써 텍스트, 오디오 등과 같은 다른 도메인을 함께 모델상에서 사용이 가능하다.
Introduction
diffusion 모델들이 computing cost를 많이 필요로 해서 그러한 것들을 개선하는 데 포인트를 맞췄다. 예를 들어, 가장 많은 연산을 필요로하는 diffusion 모델들 중 하나를 골라보면, 거의 몇백대의 V100을 이용해서 수일간 학습시켜야 하는 케이스가 존재한다. 50,000개의 샘플들을 A100으로 추론해도 5일씩 걸리는 학습과 추론에 너무 많은 computing cost를 필요로 하는 단점이 있다.

위 그림은 다른 생성 모델들과 이미지 복원 테스크를 했을 때의 성적이다. FID metric을 사용하고 있는데 이는 낮을수록 좋은 metric이라 해석하면 된다. less aggressive한 down-sampling, 즉 이미지에 크기를 크게 down-sampling하지 않고도 효율적으로 task를 수행해냈다는 점을 계속해서 강조하고 있다.

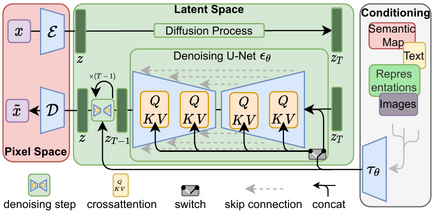
평가 metric인 FID같은 경우, Inception V3 모델을 feature extractor로 사용하여 실제 이미지와 생성된 이미지 사이에서 activation map들을 모두 추출해내고, 이 추출해내는 전체 activation map에 대해서 분포를 만들게 되는데, 이 분포를 Wassertein-2 distance를 이용해서 추정한 값이라 한다. auto encoder를 먼저 학습시키고 process를 쭉 타면서 auto encoder 외의 step마다 UNET 아키텍처를 또 학습시키게 하는 구조이다. 따라서 이러한 모델들을 latent diffusion model, 다시 말해 latent 공간에서 학습을 진행하는 diffusion model이라 정희하겠다 밝히고 있다.

앞에서 사용했던 encoder 같은 경우 마치 transfer learning을 하듯, 정확히 동치되는 개념이라 보기엔 조금 힘들 수 있지만, transfer learning을 하듯 multiple한 다른 task에 반복적으로 사용을 할 수 있다 하고, 논문의 appendix를 보면 다양한 task들의 해당 encoder를 써서 진행을 했기 때문에 빠른 속도로 많은 task들의 실험을 해볼 수 있었다고 한다. task들로는 unconditional image synthesis, 다시 말해 이미지 복원이고, inpainting(위 이미지 참고) 같은 경우 이미지를 가렸을 때 다시 복원시키는 super resolution task에 적용을 시켜 computational cost를 많이 낮췄다 언급하고 있다. 다른 도메인의 embedding들에 대해서 노이즈 이미지와 함께 cross-attention을 사용했다고 한다.
Method
- Latent Space(Low dimensional)
Likelihood-based generative models로써, High Dimensional Pixel Space보다 Low Dimension인 Latent Space에서의 연산이 훨씬 유리하다. - Underlying Unet
Inductive bias를 활용할 수 있다. Time-conditional Unet
논문에서 키포인트로 잡았던 latent space로 옮겨 연산을 한다는 포인트는 결국 pixcel space보다 low dimension한 latent space의 영상이 computing cost를 줄이는 데 훨씬 유리하다는 점과, 모델의 추론능력 상으로 보아 sementic한 포인트들에 조금 더 집중할 수 있다는 점을 내세웠고, UNET을 사용한 것은 UNET 구조가 제공하는 inductive bias를 사용할 수 있기 때문에 UNET을 사용했다고 한다.
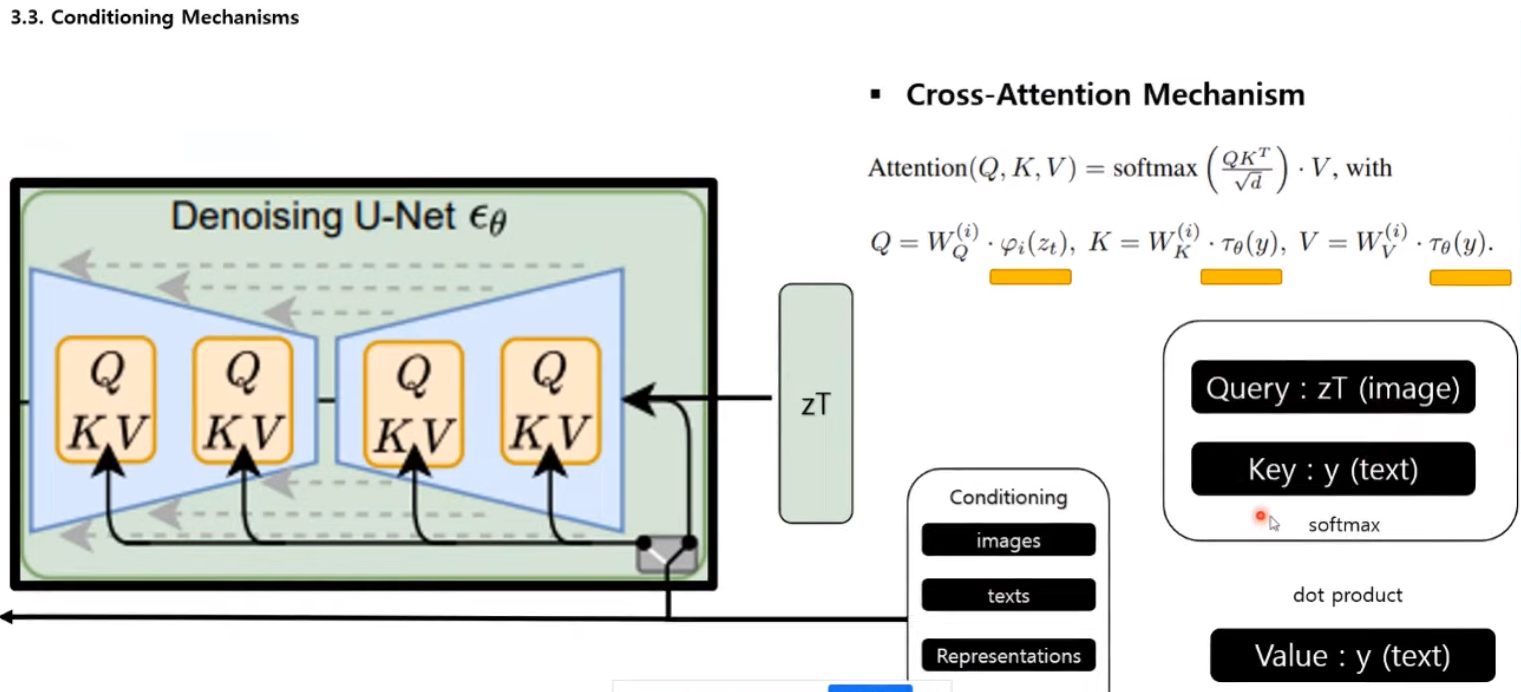
모델에서 사용한 attention mechanism을 조금 더 자세하게 살펴보면 zT가 노이즈가 오염된 이미지라 생각을 하면 되고, 이게 쿼리값으로 들어가고, 입력을 input으로 넣고 싶은 텍스트 embedding을 key값으로 가져가게 된다. 따라서 두개의 가중치를 Dot Product(스칼라 곱)에서 계산을 하고, softmax 값으로 가중치 형태로 끌어낸다. 이것을 다시 텍스트 이미지에 Dot Product하는 전형적인 cross attension mechanism을 사용했다고 한다.
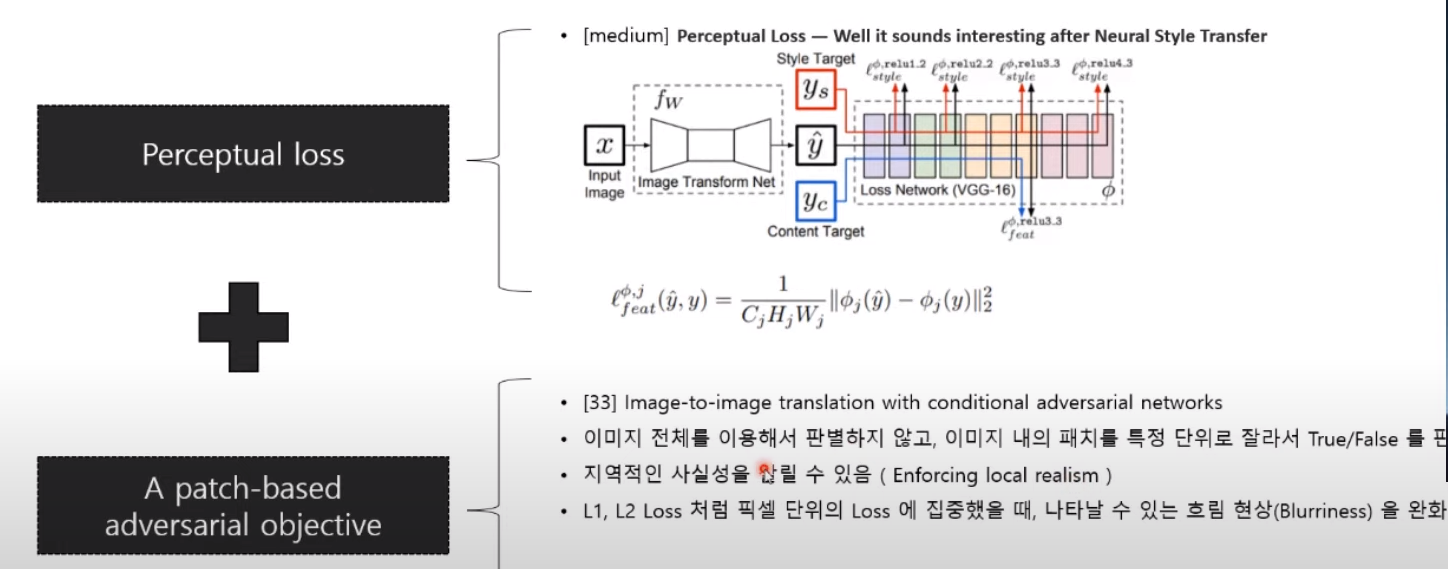
loss로는 perceptual loss와 patch based adversarial objective를 사용했다. perceptual loss는 네트워크 상에서 feature map이 나오게 되는데, 이 feature map마다 거리계산을 했다고 보면 된다. patch based adversarial objective는 전체적인 이미지를 한번에 T/F를 통해서 score를 측정하는 게 아니라 patch 단위로 T/F를 판별하는 방식이다. 이 방식을 사용하게 되면 지역적인 사실성을 살릴 수 있고 L1이나 L2 loss처럼 pixel 단위 loss를 사용했을 때 나타날 수 있는 blurriness 현상을 많이 완화하고 있다고 한다. loss 자체는 GAN에서 많이 사용하고 있고, reference에 있는 논문 자체도 아마 patch GAN이라는 이름으로 등록이 되어 있을 것이다.
Experiments

실험에서 사용했던 데이터셋은 CelebAHQ, FFHQ, LSUN-Churches, LSUN-Beds, ImageNet이다.
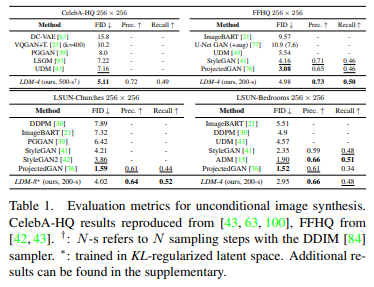
CelebAHQ은 고해상도 이미지 사진 샘플로 많이 쓰이는 사진이다. 이것들을 복원 task에 적용하였을 때, unconditional 복원/이미지 합성이라 하면 그냥 복원, 복원 task를 했을 때 FID 기준으로 SOTA를 달성했고 한다. 기준은 256*256이다.
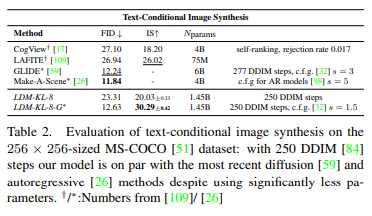
conditional latent diffusion, text-to-image 합성에 대해서는 지금 FID상으로도 latent 모델이 괜찮은 score를 보여주고 있는데, 포인트는 결국 파라미터 개수이다. 60억개에 달하는 파라미터 수를 10억개로 추렸고, 그래서 inference 속도에 의해 유리하게 됐다는 장점을 가지고 가는 것 같다고 한다.
Sample Task

그림과 같이 sementic한 박스의 label을 주게 되면 공간에 이미지를 생성해준다고 한다.
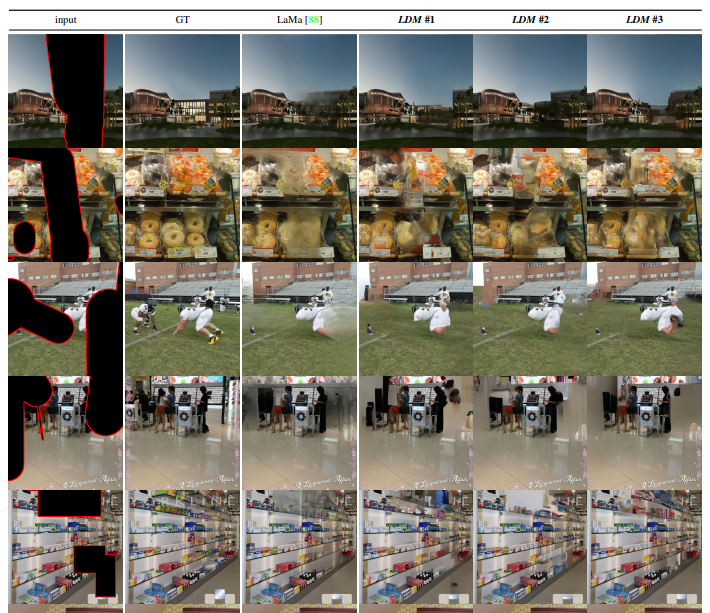
그 다음 inpainting task, groundtruth가 있고 input이 있을 때 이것들을 대칭적으로 학습시키게 되면 input값이 다 비어서 들어와도 빈칸들을 메워주는 형태의 task이다.

위와 같은 task같은 경우에는 배경에 대한 sementic segmentation을 가져가고 segmentation class를 바꿔주는 것들로 이미지 합성을 해낸 케이스이다.
Q&A
Q. 노이즈를 주입하는 과정이랑 노이즈를 해석하는 과정이랑 둘 다 매 step마다 신경망이 쓰인다고 생각하면 될지?
A. stable diffusion 모델 같은 경우 원래는 diffusion 모델들에서는 신경망이 안쓰였는데, 그 step마다 신경망을 갖고 온 게 stable diffusion 모델이다.
Q. 그러면 노이즈를 주입하는 과정과 해석하는 과정 두 과정에서, 둘 다 매 step이 같은 신경망을 사용하게 되는지 아니면 조금 다른 신경망을 사용하게 되는지?
A. 여기서는 지금 주입을 할 때는 신경망을 거의 사용하지 않는다. 그러니까 step마다의 노이즈를 주입하는 과정 자체는 학습이 될 필요가 없이 정해진 함수를 사용해도 괜찮다는 로직이다. 원래 diffusion 모델 자체가 신경망을 안쓰고 앞에서 그 노이즈를 주입할 때 정해진 함수에 의해서 주입을 한다.
Q. 그러면 주입을 할 땐 쓰지 않고 해석을 할 때 신경망을 쓰는데, 그러면 매 step마다 사용하는 신경망은 전부 다 파라미터 share인건지?
A. 그런걸로 보이나, 세세하게까지는 weight에 대해 이야기해주고 있지 않다.
Q. 그러면 아까 혹시 이러한 해석 과정의 step이 전체 성능을 좌우한다고 말씀하셨는데, step이 길면 길수록 좋아지는 건지?
A. 자세한 실험 과정과 케이스는 부록을 참고해주시면 좋을 것 같다. 어차피 최적을 찾아내는 거니까 어느 step 이상 넘어가면 의미가 없을 것 같기도 하다.
Reference
[Article] [논문 리뷰 YouTube] [stable diffusion 1] [stable diffusion 2] [GitHub] [diffsion model] [Auto Encoder]
