[컴퓨터 네트워크] CH2. 애플리케이션 계층 (2)
2.2 웹과 HTTP
웹 페이지는 다양한 object들로 구성되어 있으며, object들은 HTML 파일, JPEG 사진, Java스크립트 등이 있다.
대부분의 웹페이지들은 기본 HTML 파일과 여러 참조 객체로 구성되어 있다
HTTP 개요
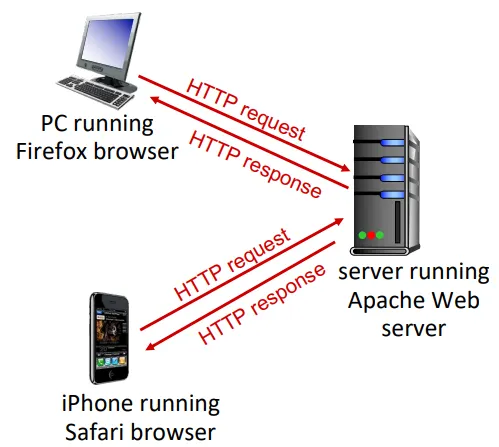
HTTP란 ?
웹의 어플리케이션 계층 프로토콜로, 웹 object를 주고 받는데에 필요하다.
-
클라이언트 : 요청하거나 받는 브라우저로, 보여지는 웹 오브젝트이다
-
서버: 요청에 대한 응답을 보내는 오브젝트이다.
HTTP는 TCP를 이용한다
→ 문서가 정확히 와야하기 때문에..
- HTTP 클라이언트는 먼저 서버에 TCP 연결을 시작. (포트번호 80)
- 서버는 클라이언트로부터의 TCP연결을 수락
- 클라이언트와 서버 사이 HTTP 메시지를 교환 (by 전용 소켓)
- TCP 연결 닫힘
HTTP는 stateless(무상태)이다
즉, 서버가 클라이언트에게 요청 파일을 보낼 때, 서버는 클라이언트에 관한 어떠한 상태 정보도 저장하지 않음
→ 그렇기에 클라이언트가 몇 초 후에 같은 객체를 요청하면, 서버는 또 보내준다
기억하지 않는 이유? 만약 모든 상태를 저장하면 어마어마한 혼란이 오며 성능에 영향을 주기 때문..
HTTP 연결 : 두가지 타입
- 비지속 연결
- TCP 연결 시작
- 맺어둔 TCP 연결로 하나의 object 정보 가져옴
- TCP 연결 닫음
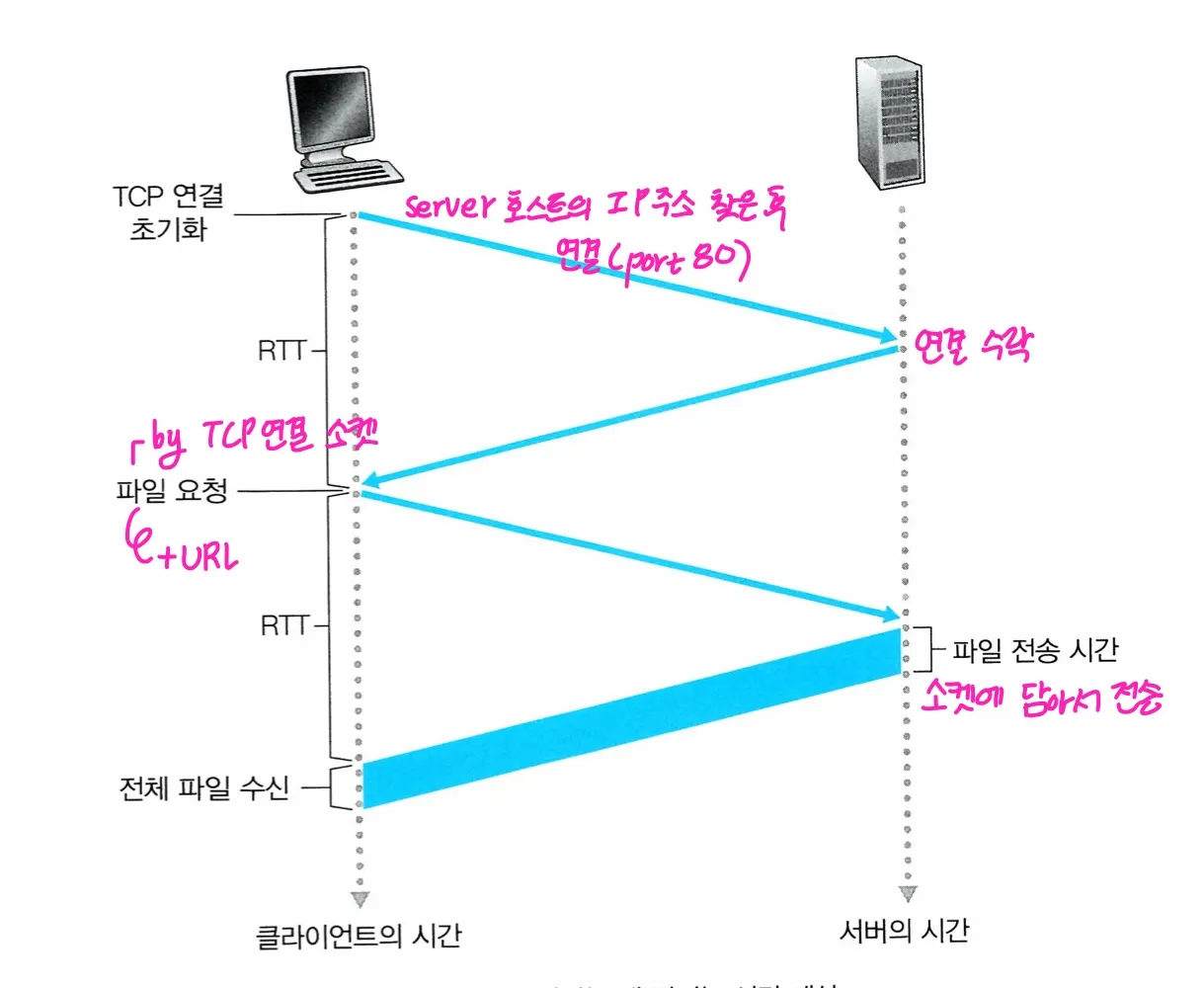
- RTT (definition) : 작은 패킷이 클라이언트→ 서버로 가고, 서버 → 클라이언트로 가는데 걸리는 시간
하나의 오브젝트에 걸리는 HTTP 응답 시간 : 2RTT + 파일 번역 시간
비지속 연결에는 몇가지 단점이 있다..
- 한 오브젝트당 2RTT가 필요함
- 각 TCP 연결때문에 OS에 부담이 간다
- 지속 연결
서버가 응답을 보낸 후에 연결을 그대로 유지한다. → 다음 클라이언트 요청에는 이후의 TCP 연결을 위한 setup시간이 필요 없당
⇒ 각각의 오브젝트를 참조할 때에 하나의 RTT만 필요하다
HTTP 요청 메시지
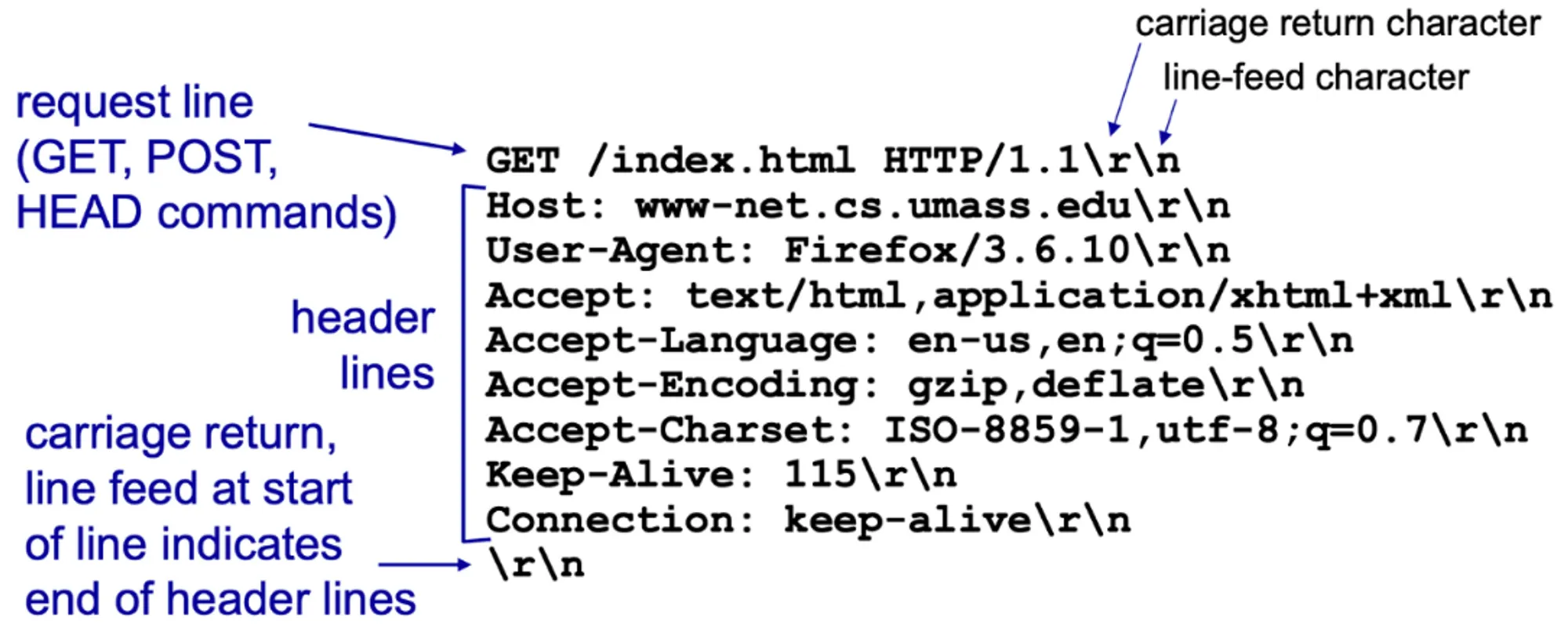
HTTP 요청 메시지 : 일반 포맷

다른 HTTP 요청 메시지
- POST 메소드 웹페이지는 주로 입력을 포함한다. 사용자는 입력을 HTTP POST요청 메시지의 개체 몸체(entity body)에 담아서 클라이언트로부터 서버로 보낸다
- GET 메소드 사용자 데이터를 HTTP GET 요청 메시지의 URL 필드에 포함한다 ex. www.somesite.com/animalsearch?monkeys&banana
- HEAD 메소드 내용을 빼고 헤드만 보내는 메소드로, 특정 URL만 반환된다
- PUT 메소드 웹 서버에 새로운 파일을 업로드하는 메소드로, HTTP 요청 메시지의 개체 몸체에 있는 내용으로 완전히 대체될 것이다
HTTP 응답 메시지
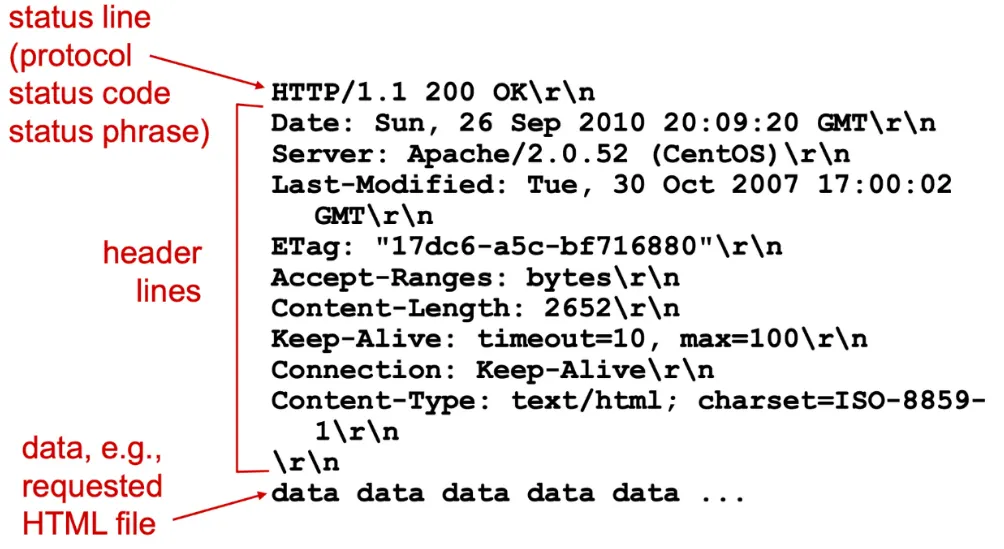
HTTP 응답 상태 코드
- 200 OK : 요청 성공, 정보가 응답으로 보내진다.
- 301 Moved Permanently : 요청 객체가 영원히 이동되며, 새로운 URL은 응답메시지의 location에 있음
- 400 Bad Request : 서버가 요청을 이해할 수 없다는 일반 오류 코드
- 404 Not Found : 요청 문서가 서버에 존재 X
- 505 HTTP Version Not Supported : 요청 HTTP 프로토콜 버전을 서버가 지원 X
사용자와 서버간의 상호작용 : 쿠키
앞에서 말했듯이 HTTP 서버는 상태를 유지하지 않는다
-웹 transaction(처리)을 완성시키기위해 여러번의 HTTP 메시지를 교환할 필요가 없다
-모든 HTTP 요청은 서로 독립적이다
-부분완성 transaction으로부터 recover할 필요가 없다
웹 사이트와 클라이언트 브라우저는 transaction 사이의 몇가지 상태들을 포함한 쿠키를 사용한다
쿠키의 4가지 요소는 다음과 같다
- HTTP 응답 메시지의 쿠키 헤더 라인
- 다음 HTTP 요청 메시지의 쿠키 헤더 라인
- 사용자의 브라우저에 사용자 종단시스템과 관리를 지속시키는 쿠키 파일
- 웹사이트의 백엔드 데이터베이스
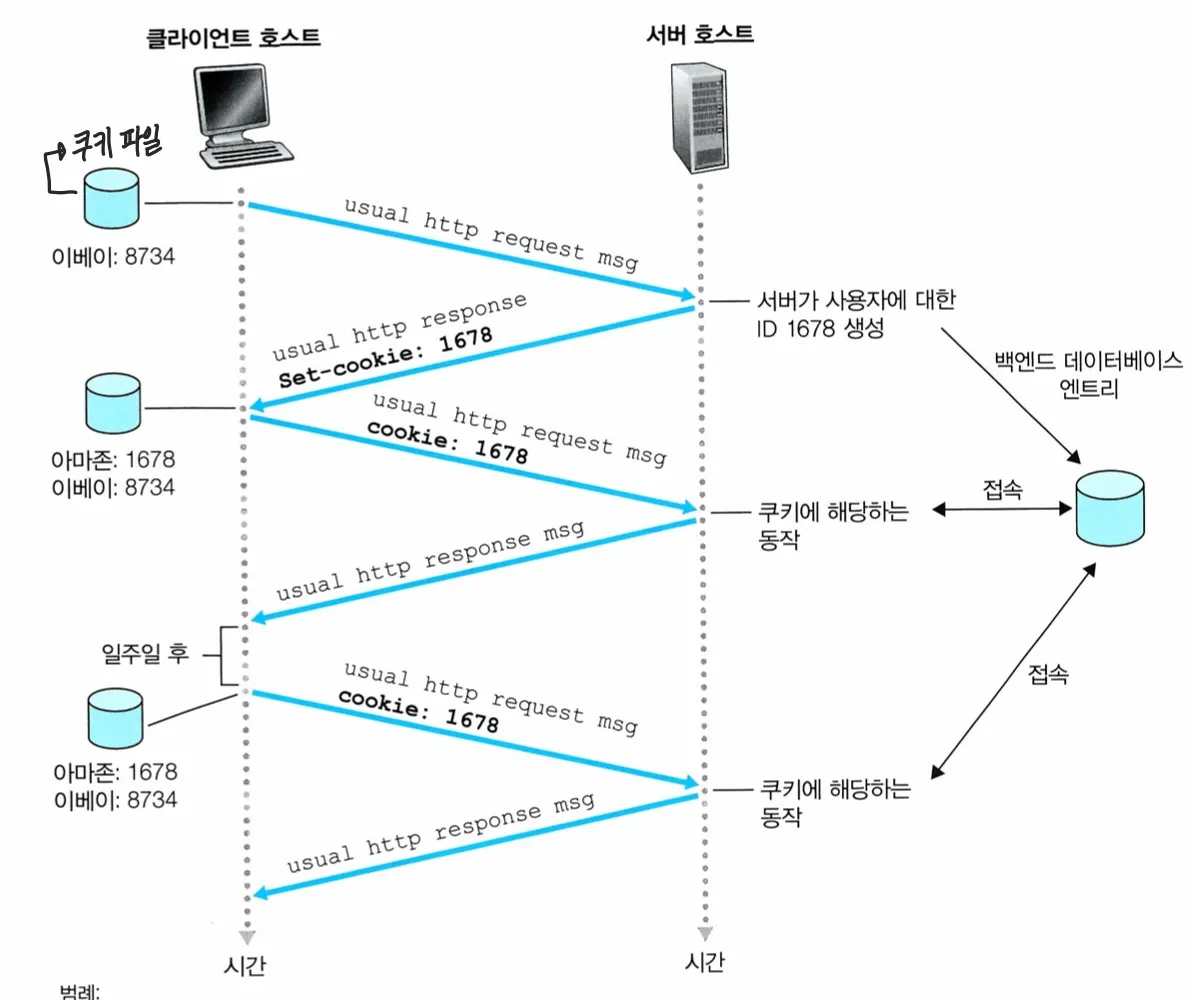
Ex. 수잔이 특정 PC에서 인퍼넷을 사용하는데, 처음에는 이커머스 사이트(서버)에 방문했다고 가정하자
→ 서버는 이 클라이언트에게 ID(쿠키)를 할당하고, 그 ID를 백엔드 데이터 베이스에 저장하고 이용한다
그 후 서버는 쿠키를 참조하여, set-cookie라는 필드로 넣어 응답한다
이후 다시 요청할 때 cookie 값을 담아서 요청하면 된다
→ 이렇게 하면 서버는 해당 클라이언트를 cookie로 관리할 수 있다
HTTP 쿠키 : comment
쿠키는 어떻게 이용될 수 있는가?
- authorization (승인) : 같은 쿠키값이면 해당 사용자라고 믿는다
- shopping carts : 아마존 예시로, 원하는 구매 목록을 유지할 수 있어, 그 세션이 끝날 때 총괄하여 지불 가능
- recommendations (추천) : 사용자가 과거에 아마존에서 방문한 웹 페이지에 기초하여 제품을 추천함
- user session state (Web email) : 만약 아마존에 정보를 등록하면, 아마존은 이 정보를 db에 추가하고, 그녀의 ID를 이름과 연관시킨다. 즉 후에 방문하고 쇼핑할 때 이름, 신용카드번호, 주소를 재입력 할 필요 X
⇒ 쿠키 덕에 HTTP의 stateless한 특성을 state하게 만들 수 있다
➕cookie and privacy
쿠키는 사이트에 대한 많은 정보를 사이트에게 알려준다.. 이러한 정보를 제 3자 (사용자가 방문하지 않은 사이트)가 이용할 수 있음
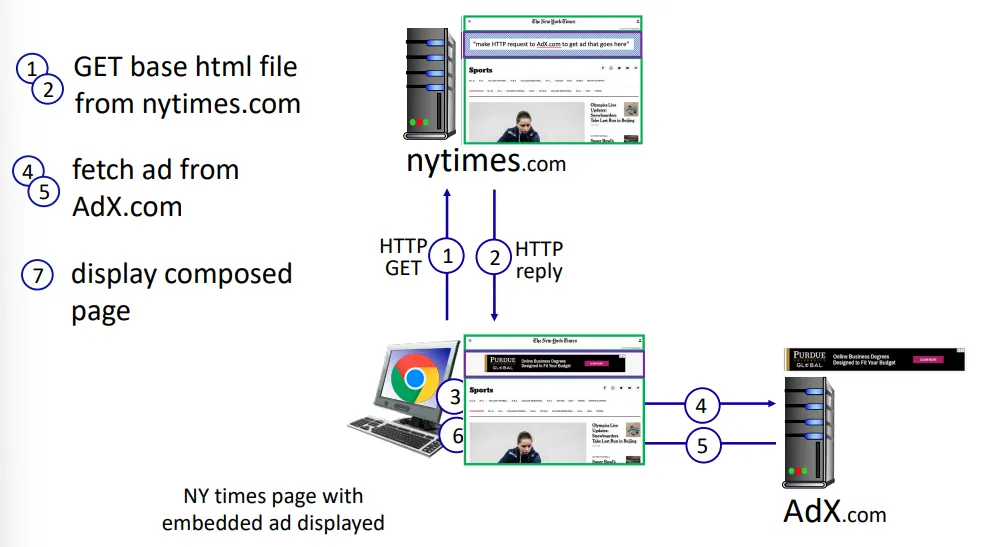
예시 : NY타임즈 웹 페이지가 보여지는 과정
쿠키 : 사용자의 browsing을 추척
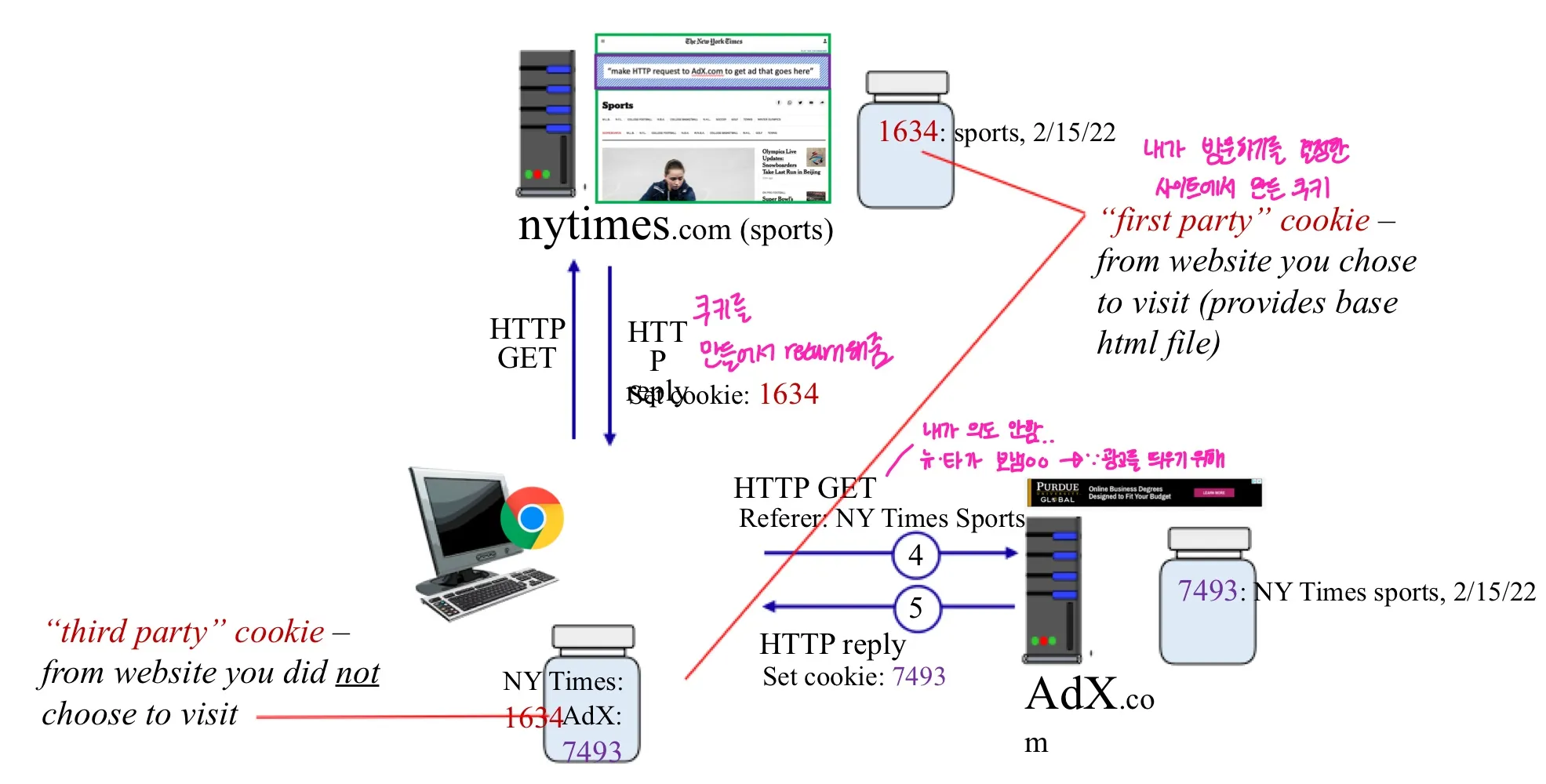
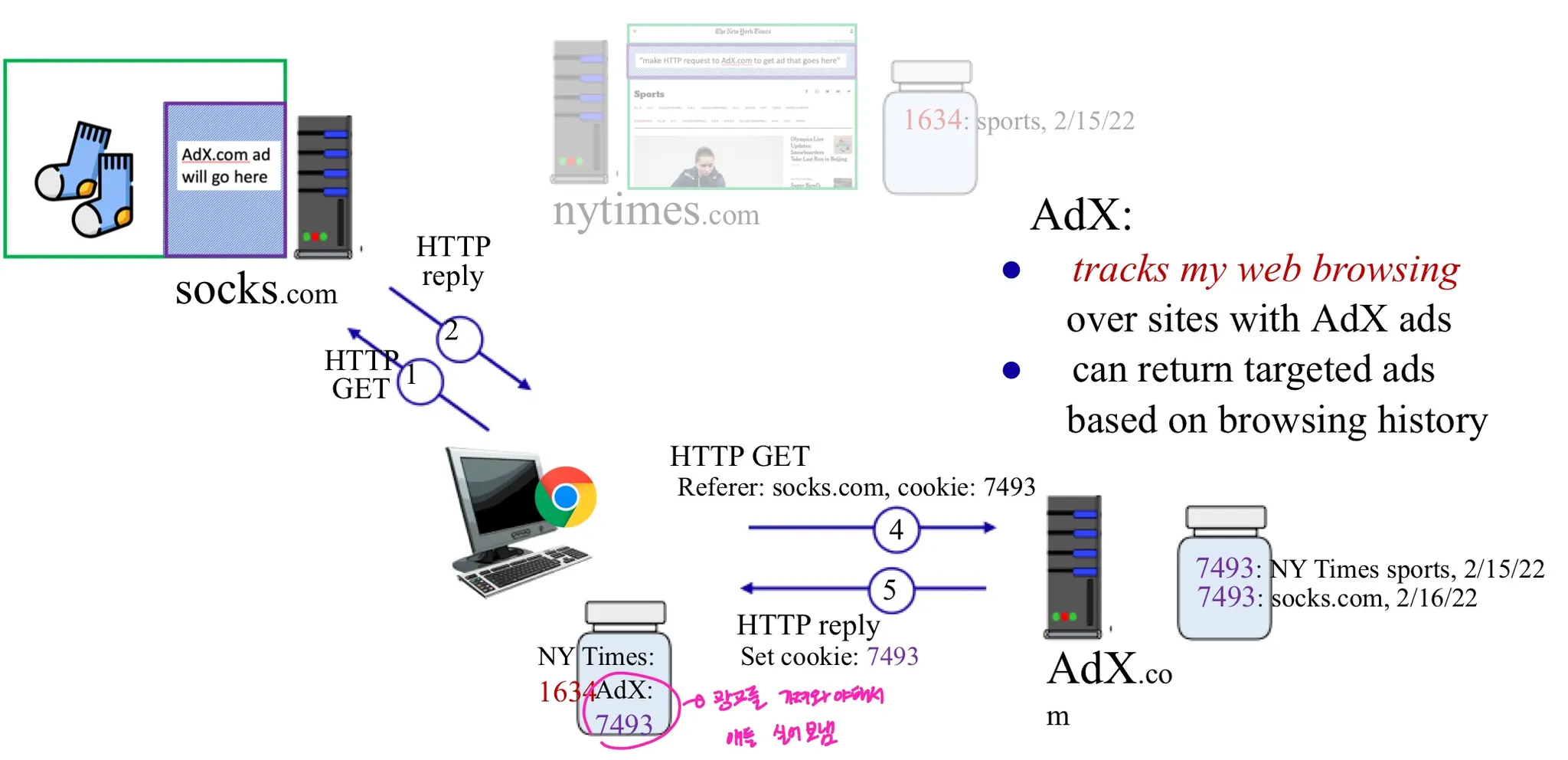
쿠키는 이러한 경우 사용됨..
- 주어진 웹사이트 (first party cookies)가 사용자의 행동을 추적
- 사용자의 방문 선택과 상관없이 여러 사이트가 사용자의 행동을 추적한다
- 그러나 사용자는 이 사실을 모름..
쿠키를 통한 제 3자의 추적
✅ Firefox, Safari Browser에서는 금지되었고, 2023년에는 구글에서도 금지되었다
GDPR과 쿠키
쿠키들이 독립적인 신원을 가질 때, GDPR을 조건으로 개인적인 데이터가 고려되어야한다
웹 캐싱
목표 : 기존 서버의 도움없이 클라이언트 요청을 수행하는 것
즉, cache는 기존 클라이언트에게는 서버, 기존 서버에게는 클라이언트같은 역할을 한다.
만약, 오브젝트가 캐시에게 있다면 바로 클라이언트에게 보내주고, 없다면 기존 서버에게 요청해 받은 후 클라이언트에게 보낸다
✅ 캐시는 클라이언트와 서버 둘 다 가능함
서버는 응답 헤더에 오브젝트 유효기간을 담아 캐시에게 전달한다.
왜 Web caching ?
-
클라이언트 요청에 대한 응답시간을 줄일 수 있다
ㄴ캐시가 클라이언트와 더 가까이 있음
-
프록시 서버와 기존 서버간의 접근 링크상의 트래픽을 감소한다
-
인터넷은 캐시와 밀접하다
ㄴ poor 컨텐츠 제공자가 더 효과적으로 컨텐츠를 제공할 수 있음
예시 : caching
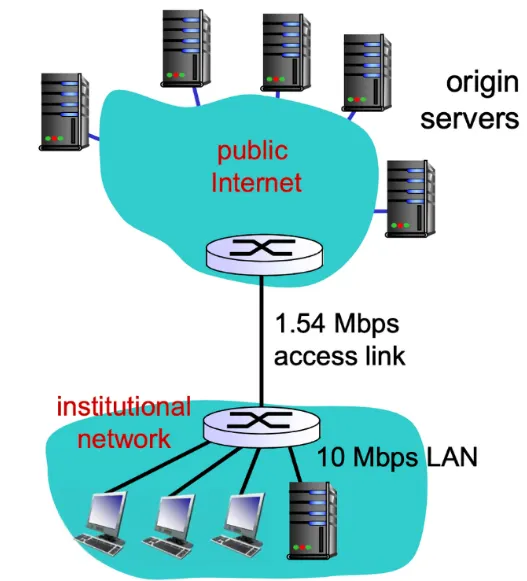
가정
access link rate : 1.54 Mbps
RTT(institutional router~server) : 2초
웹 오브젝트 크기 : 100K bits
avg request rate from browsers to origin server: 15 req/sec (초당 queue에 얼만큼 들어오는가)
초당 브라우저에 들어오는 응답의 양 : 15req/sec
결과
접근 링크 사용률 : .97
❗TI가 1에 가까울수록 problem
LAN 사용률 : 15% (1.5Mbps/10Mbps LAN)
end-end delay = 인터넷 지연 + 접근 링크 지연 + LAN 지연
→ 2초 + minutes + usecs(마이크로 세컨)
브라우저 캐싱 : 조건부 GET
목표 : 브라우저가 최신 캐시된 버전을 가지고 있는 경우 객체를 전송X
→ 오브젝트 전송 지연도 없고, 링크 사용률이 낮음
if-modified-since 필드는 last-modified date 값을 가짐
✅캐시는 객체와 더불어 마지막으로 수정된 날짜도 함께 저장
- 이후 오브젝트가 수정되지 않은 경우 304 Not Modified 메시지 전송
- 수정된 경우 200 OK 메시지 보냄
HTTP
목표 : 여러개의 오브젝트 HTTP요청 시의 지연 줄이기
http 1은 지속적인 TCP 연결을 이용하는데, 이 하나의 TCP 상에서 웹 페이지에 있는 모든 객체를 보내면 HOL 블로킹 문제가 발생할 수 있다는 사실을 깨달음.
HOL블로킹 ? → 즉 웹페이지에 비디오, 문서, 사진 등.. 여러개가 존재하는데 만약 비디오를 맨 처음에 띄우면 링크를 통과하는데 오래걸림.. 근데 이거때문에 뒤에 파일들이 계속 기다리게된다..
또한, loss가 일어났을 때 재전송을 받아야하는데, 이때도 대기타야한다..
이러한 문제의 해결책으로 HTTP/2 등장
이는 서버가 클라이언트에게 어브젝트를 보낼 때의 유연성을 증가시킨다
HTTP 메시지를 독립된 프레임들로 쪼개고 인터리빙하고 반대편 사이트에서 재조립하면 된다
인터리빙이란 ? 수행되는 순서를 조정하는 것?
HTTP/3 : 보안성을 추가한 것으로 UDP를 넘어 혼잡제어, 오브젝트 서버를 알아낼 수 있다
