SQL 동작 순서
💡 'FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY'
정규 표현식

https://schatz37.tistory.com/39
CTE
CTE는 쿼리 내에서 임시 테이블을 정의하여, 후속 SELECT문에서 사용할 수 있도록 하는 구조
-> 임시로 쿼리 결과를 저장해 놓고, 여러번 참조해서 사용하는 용도로 사용
사용 방법
WITH 키워드와 AS로 cte_name에 맵핑할 쿼리를 작성한 후 cte_name으로 지정한 테이블을 조회한다.
WITH CTE_NAME AS (
-- CTE 정의 부분
SELECT column1, column2, ...
FROM some_table
WHERE condition
)
-- CTE 사용 부분
SELECT * FROM CTE_NAME;
여러 CTE 사용
여러 개의 CTE를 콤마(,)로 구분하여 동시에 정의할 수 있음.
각 CTE는 쿼리에서 독립적으로 사용할 수 있다.
WITH
TotalSales AS (
SELECT SUM(amount) AS total_amount
FROM sales
),
AverageSales AS (
SELECT AVG(amount) AS average_amount
FROM sales
)
-- CTE 사용
SELECT total_amount, average_amount
FROM TotalSales, AverageSales;재귀 쿼리
https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-RECURSIVE-%EC%9E%AC%EA%B7%80-%EC%BF%BC%EB%A6%AC
사용 방법
WITH RECURSIVE 쿼리문을 작성하고 내부에 UNION을 통해 재귀를 구성
WITH RECURSIVE cte_count
AS (
-- Non-Recursive 문장( 첫번째 루프에서만 실행됨 )
SELECT 1 AS n
UNION ALL
-- Recursive 문장(읽어 올 때마다 행의 위치가 기억되어 다음번 읽어 올 때 다음 행으로 이동함)
SELECT n + 1 AS num
FROM cte_count
WHERE n < 3
)
SELECT * FROM test;별칭
칼럼(column)에 별칭 사용하기
SELECT mem_id AS "아이디", addr AS "주소" FROM member;테이블(Table)에 별칭 사용하기
SELECT * FROM member as "개인정보";별칭을 지정해줄 때 띄어쓰기가 들어간다면, 큰 따옴표(")로 묶어주어야 한다. 또한 테이블 별칭은 WHERE 절에서 사용 가능하지만 열(칼럼) 별칭은 WHERE 절에서 사용 불가능하다. (SELECT절보다 WHERE 절이 먼저 실행되기 때문)
기타 함수
✅ 문자열 자르기
SUBSTRING( 문자열, 시작위치, 길이 )
문자열에서 시작 위치부터 길이만큼 출력
LEFT( 문자열, 길이 )
문자열에서 왼쪽부터 길이만큼 출력
RIGHT( 문자열, 길이 )
문자열에서 오른쪽부터 길이만큼 출력
✅ 날짜와 시간의 연산 -> DATE_ADD()
DATE_ADD(연산을 수행할 날짜, INTERVAL 더하거나 빼고자 하는 값 단위)
주요 단위로는 YEAR, MONTH, DAY, HOUR, MINUTE, SECOND 등이 있다.
사용 예시
SELECT DATE_ADD(NOW(), INTERVAL 1 DAY) AS tomorrow;✅ TRUNCATE(number, decimal_places)
number: 변환할 숫자decimal_places: 유지할 소수점 이하 자리 수 (또는 정수 자리수 조정)- 양수(+) → 소수점 이하 자리 유지
- 0 → 소수점 이하 버림 (정수로 변환)
- 음수(-) → 정수 부분에서 해당 자리 이하를 0으로 만들고 버림
사용 예시
SELECT
TRUNCATE(123.456, 2) AS TRUNC_2, -- 소수점 2자리 유지
TRUNCATE(123.456, 0) AS TRUNC_0, -- 정수 변환 (소수점 이하 버림)
TRUNCATE(123.456, -1) AS TRUNC_-1, -- 10 단위로 자름
TRUNCATE(123.456, -2) AS TRUNC_-2; -- 100 단위로 자름🎯 TRUNCATE() vs ROUND() 차이
| 함수 | 동작 방식 | 예제 (123.456) | 예제 (98.765) |
|---|---|---|---|
ROUND(값, 2) | 반올림 | 123.46 | 98.77 |
TRUNCATE(값, 2) | 버림 | 123.45 | 98.76 |
ROUND(값, -1) | 10 단위 반올림 | 120 | 100 |
TRUNCATE(값, -1) | 10 단위 버림 | 120 | 90 |
💡 즉, ROUND()는 반올림, TRUNCATE()는 그냥 자름!
✅ COALESCE(A,B)
인자로 주어진 컬럼들 중에서 NULL이 아닌 첫 번째 값을 반환하는 함수
A 컬럼 값이 NULL 값이 아닌 경우 A 값을 리턴하고 A가 NULL이고 B가 NULL이 아닌 경우 B 값을 리턴함. 만약 모든 인수가 NULL이면 NULL을 반환한다.
✅ SET
특정 변수 값을 설정할 때 사용됨
SET @myVar := 10; -- 변수 설정 (MySQL):=은 대입 연산자로 비교 연산자인 =과 구분하기 위해 앞에 :를 붙인다.
윈도우 함수
🚀 RANK()
특정 기준에 따라 순위를 매기는 함수 -> 같은 값이 있으면 같은 순위를 부여하고, 다음 순위는 건너뛴다. 즉, 3,3 다음은 5로 순위가 시작됨
PARTITION BY를 사용하면 그룹별로 순위를 매길 수 있음
SELECT
이름, 부서, 급여,
RANK() OVER (ORDER BY 급여 DESC) AS 순위
FROM 직원;🚀 DENSE_RANK()
RANK()와 기능과 사용방법은 똑같지만 동일한 값이 있으면 같은 순위를 부여하지만 건너뛰지 않음. 즉 3,3 다음은 4등
with salary_rank_cte as (
select id,
dense_rank() over(partition by departmentId order by salary desc) as salary_rank
from Employee
)
select d.name as Department, e.name as Employee, e.salary as Salary
from Employee e join Department d on e.departmentId = d.id join salary_rank_cte s on s.id = e.id
where s.salary_rank <= 3이렇게 partition by와 혼용해서 사용할 수도 있다. (다른 윈도우 함수들도 가능)
🚀 ROW_NUMBER()
고유한 순위를 부여함. 값이 동일해도 다른 순위를 부여한다는 뜻
SELECT name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num
FROM employees;🚀 LAG()
이전 행의 값을 가져온다. 사용법은 아래와 같다.
LAG(컬럼명, 이동할 행 수, 기본값) OVER (ORDER BY 정렬기준)이때, 기본값을 지정하지 않으면 이전 행이 존재하지 않을 경우 NULL로 처리된다.
예시
SELECT name, salary,
LAG(salary, 1, 0) OVER (ORDER BY salary DESC) AS prev_salary
FROM employees;🚀 LEAD()
다음 행의 값을 가져옴
LEAD(컬럼명, 이동할 행 수, 기본값) OVER (ORDER BY 정렬기준)이때, 기본값을 지정하지 않으면 NULL로 처리된다.
예시
SELECT name, salary,
LEAD(salary, 1, 0) OVER (ORDER BY salary DESC) AS next_salary
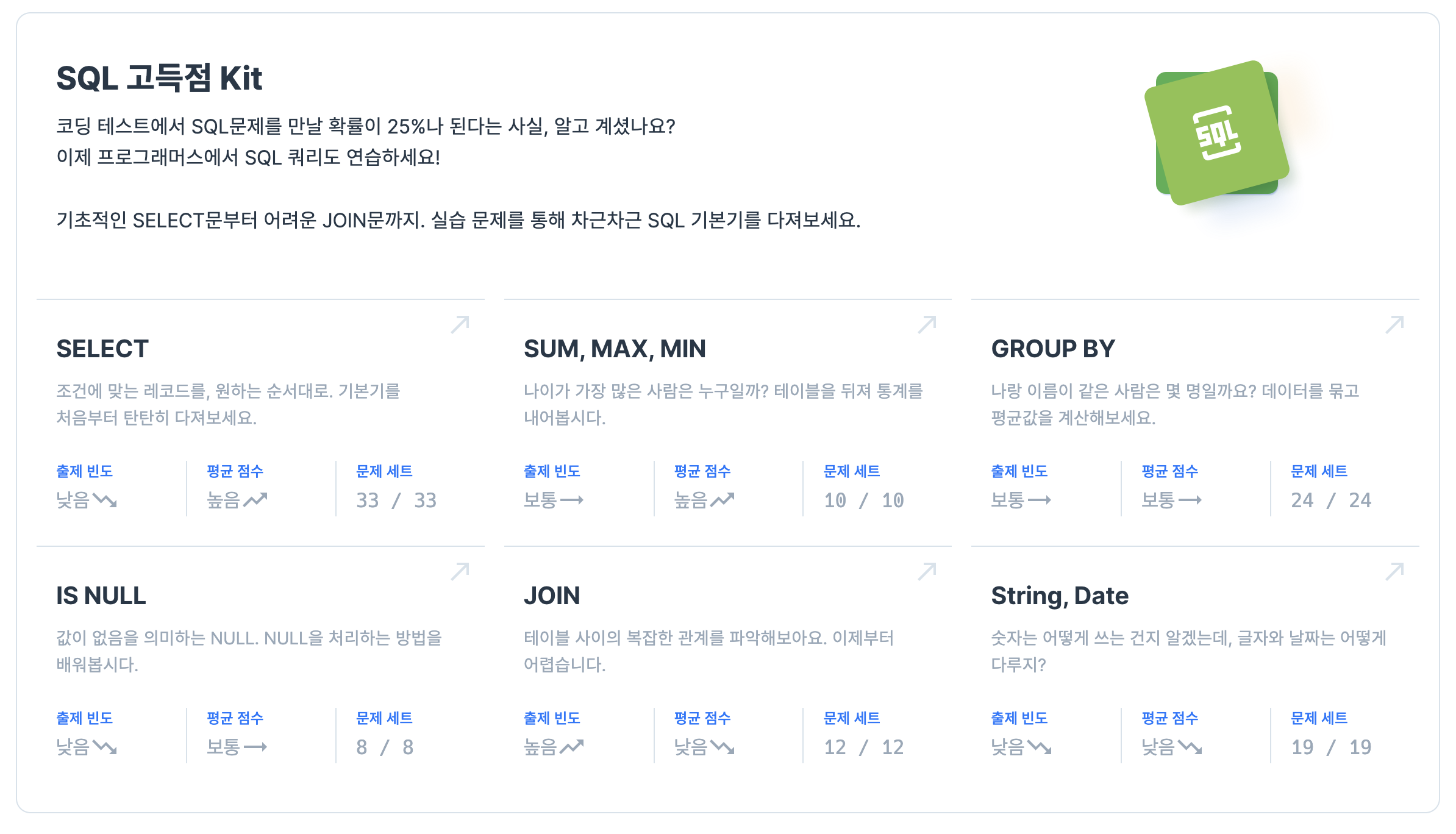
FROM employees;SQL에 부족함을 느껴서 3일간 프로그래머스 SQL 고득점 KIT를 모두 풀었다.. 계속 복습해서 익숙해지자! 💪🏻