머신러닝
- 이상치(outlier) 탐지 및 제거
-
통계적 기법 : 데이터가 정규분포를 따른다고 가정하고 평균에서 ±3σ(표준편차) 범위를 벗어나는 값을 이상치로 간주 -> 직관적이고 간단하나,정규성 가정이 틀릴수 있음.
-
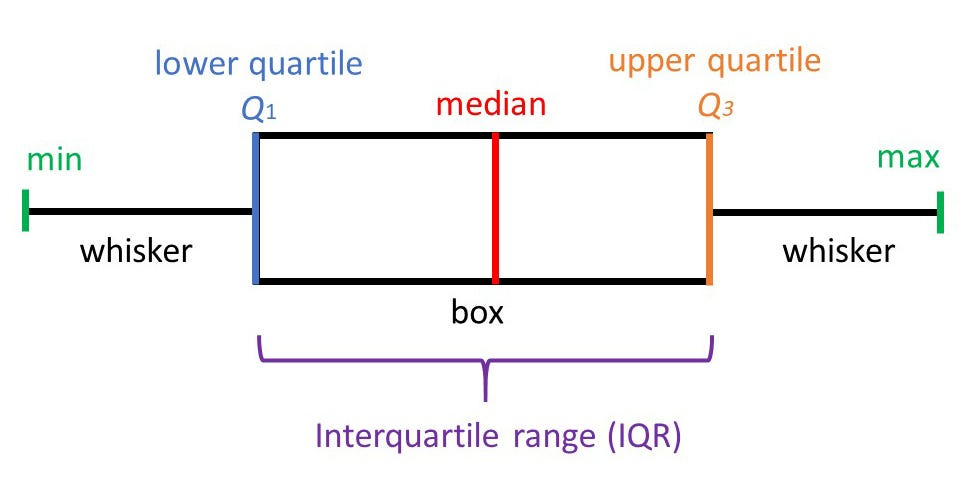
박스플롯(boxplot) : 사분위수를 이용해 벗어나는 데이터를 이상치로 간주 -> 분포 특성에 영향을 적게 받는 장점
-
머신러닝 기반 : 이상치 탐지 알고리즘
- 처리 기법
1️⃣이상치 단순제거
2️⃣이상치 값을 조정(클리핑)
3️⃣별도로 구분하여 모델에서 제외하거나, 다른 모델(이상치 예측 모델)로 활용 - 이상치 제거 코드
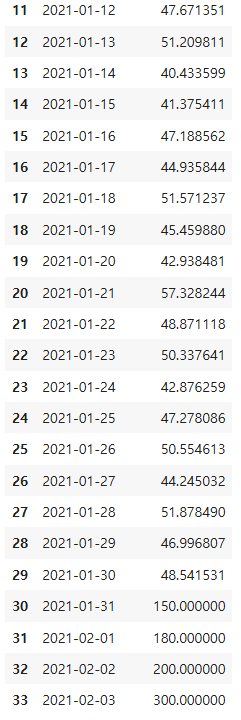
# 이상치 제거 (간단하게 박스플롯 기준 적용 예시)
Q1 = df['sensor_value'].quantile(0.25)
Q3 = df['sensor_value'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df = df[(df['sensor_value'] >= lower_bound) & (df['sensor_value'] <= upper_bound)]
df정규화 / 표준화 (스케일링)
- 왜 필요한가?
모델(거리기반 알고리즘, 딥러닝 등) 에 따라 특정 변수의 스케일이 크게 영향을 미칠수 있음
1️⃣ 정규화
minmaxscaler: 모든 값을 0과 1 사이로 매핑, 최소/최대값이 이상치에 민감
새로운 데이터가 기존 최대값보다 커지거나, 최소보다 작아지는 경우, 스케일링 범위를 벗어날 수 있어 재학습하거나 다른 처리가 필요.
2️⃣ 표준화
StandardScaler: 평균을 0, 표준편차를 1로 만듦
데이터 분포가 심하게 치우쳐 있으면, 평균과 표준편차만으로 충분한 스케일링이 되지 않을수 있음.
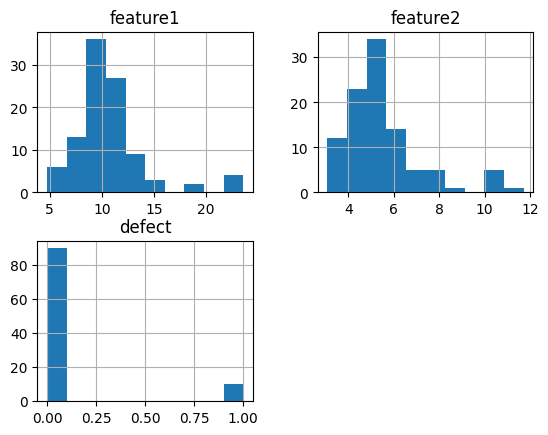
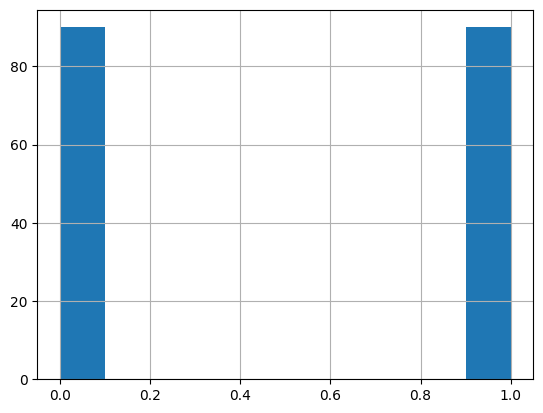
불균형 데이터 처리
-
문제점 : 정상 99%, 불량 1% 처럼 한 클래스가 극도로 적은 경우 예측하지 못할 가능성이 큼(편향 발생)
-
해결기법
1) oversampling
SMOTE: 소수 클래스의 데이터를 무작정 복사만 하는게 아니라, 비슷한 데이터들을 서로 섞어서 새로운 데이터 생성2) undersampling : 다수 클래스 데이터를 줄이는 방식(자주 쓰지는 않음)
3) 혼합 기법 : smote 와 언더샘플링을 섞어서 사용
범주형 데이터 변환
-
원-핫 인코딩: 범주형 변수를 각각의 범주별로 새로운 열로 표현, 해당 범주에 해당하면1, 아니면 0 / 단, 범주가 매우 많으면 차원이 커짐 -
레이블 인코딩: 범주를 숫자로 직접 맵핑 (m = 0, l =1, xl = 2)
단순하지만, 모델이 숫자의 크기를 서열정보로 잘못 해석할수 있음.
피처 엔지니어링
: 모델 성능 향상을 위해 기존 데이터 변형, 조합하여 새로운 특성(피처)을 만드는 작업
💡다중공선성이란?
이 변수들이 서로 너무 비슷한 정보를 담고 있어 (즉, 서로 강하게 상관이 있어) 모델이 헷갈리는 문제가 생김

재밌게 사는사람