
DB Index란?
보통 책의 마지막에 나오는 색인 Index는 찾고 싶은 정보가 있는 페이지를 더 빠르게 찾기 위해 존재하는 추가 페이지입니다. DBMS에서도 더 빠르게 조회하기 위해서 DB의 인덱스를 사용합니다.
인덱스가 없다면 조회를 할때마다 O(N) 복잡도를 가지기 때문에 풀스캔을 하게 됩니다. 그런데 인덱스가 있다면 O(logN) 복잡도로 낮아지기 때문에 조건에 맞는 튜플을 더 빠르게 찾을 수 있습니다.
인덱스를 설정하면 추가적인 메모리를 조금 더 사용하더라도 인덱스 기준으로 정렬된 데이터가 빠르게 접근할 수 있습니다. 조회하려는 속성(컬럼)들을 (복합)인덱스가 모두 커버하는 경우는 Covering Index라고 부르고 실제 테이블에 접근할 필요가 없이 인덱스 테이블에서 처리를 할 수 있기 때문에 조회 성능이 훨씬 더 빠릅니다!
MySQL의 Clustered 인덱스
인덱스가 데이터와 군집화되어 있어서 범위 검색에는 특히 효율적이지만, 새로운 데이터에 대한 인덱스 Insert 시에는 정렬을 해서 삽입해야 하기 때문에 비효율적일 수 있습니다. 기본키 PK는 Clustered 인덱스로 볼 수 있습니다.
이와 달리 Non-Clustered 인덱스는 새로운 데이터에 대한 인덱스 Insert 시 정렬을 할 필요가 없습니다.
인덱스가 필요한 상황
- 자주 조회되거나 데이터 삽입, 수정, 삭제가 자주 발생하지 않는 컬럼
where, join, order by에 자주 사용되는 컬럼 - 중복도가 낮은 컬럼 (다양한 데이터를 보유하는 컬럼)
인덱스 알고리즘
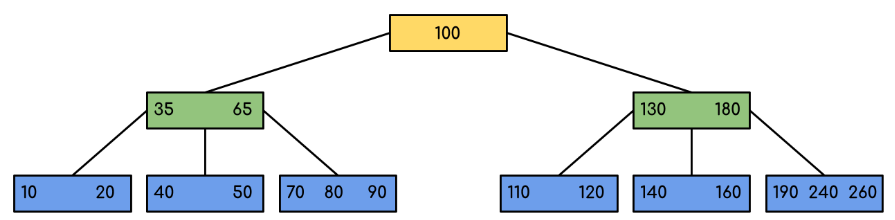
B tree (Balanced Tree)
 출처: https://www.geeksforgeeks.org/introduction-of-b-tree-2/
출처: https://www.geeksforgeeks.org/introduction-of-b-tree-2/
이진 탐색 트리 개념을 확장하면서 인덱스를 구현하는 방법이고, MySQL과 PostgreSQL에서 기본적으로 인덱스를 생성할 때 사용하는 알고리즘입니다. 최대 자녀 노드 수를 늘릴 수 있기 때문에 세컨더리 스토리지 접근 횟수(disk I/O)도 줄일 수 있고 block단위에 대한 저장 공간 활용도가 좋아서 DB Index에 유리한 알고리즘입니다.
각 노드의 최대 자녀 노드 수 n에 따라 n차 B tree라고 부를 수 있습니다. n차 B tree 알고리즘의 원칙은 데이터 추가 방법 중 하나는 항상 leaf 노드에 오름차순으로 하고, 노드에 key가 넘치게 되면 중간값인 key는 승진하고 좌우 key는 분할하는 것입니다.
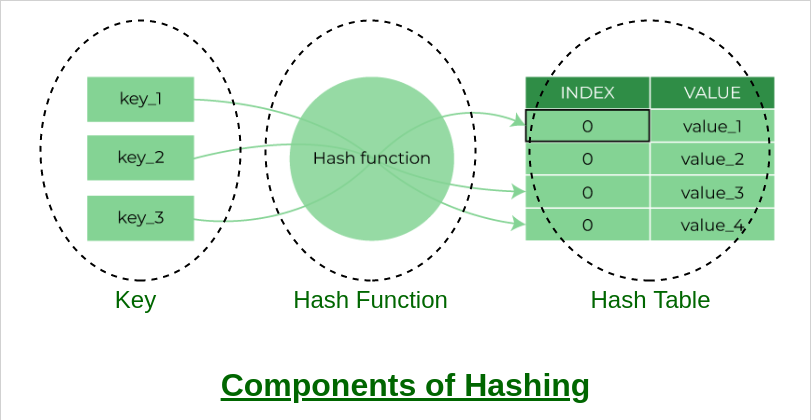
Hash
 출처: https://www.geeksforgeeks.org/implementation-of-hash-table-in-python-using-separate-chaining/
출처: https://www.geeksforgeeks.org/implementation-of-hash-table-in-python-using-separate-chaining/
해시 함수를 이용하여 해시 테이블을 만들어서 사용하는 방법입니다.
단점으로는 같거나 같지 않은 경우만 비교할 수 있고, 범위로 비교할 수가 없습니다.
참고한 사이트들
[Database] 인덱스(index)란?
B tree의 개념과 특징, 데이터 삽입이 어떻게 동작하는지를 설명합니다! (DB 인덱스과 관련있는 자료 구조)
PostgreSQL Index with B+Tree
