PR-383: Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results
PR12 Season4 정리
목록 보기
6/6
- ImageNet SOTA는 Meta Pseudo label
- 최근 연구: 큰 데이터셋, ResNet CNN구조 재조명, 새로운 training scheme, 모델 구조
- Regularization
- Aug: randAugment, AutoAugment
- Image: Cutout(네모칸 지우는), CutMix(두개 다른 클래스 합치기), MixUp(픽셀 섞어서)
- Architecture: drop-path, drop-block, architecture에서 특정 부분은 update x
- Label smoothing
- Progressive image resize during training
- different train-test resolution
- Training configuration
- more training epoch
- dedicated optimizer for large batchsize(LAMB Optimizer)
- Scaling learning rate with batch size
- Exponential-moving average(EMA) of model weights
- Improved weight initializations
- AdamW: Decoupled weight decay
- Architecture
- Vgg, Tr, EfficientNet, MLP
- 각 archi에 fit된 tailor made training scheme
Motivation : Unified scheme
- architecture에 상관없는 training scheme 제안 필요
- CNN, MLP, mobile-oriented, Tr
- Resnet
- 다양한 training scheme이 잘 작동
- Resnet strikes back: An improved training procedure in timm.
- Mobile oriented model
- depth-wise convolution
- RMSProp, waterfall learning rate scheduling, EMA
- Tr-based, MLP-only model
- inductive bias가 없음
- longer training
- strong arg(cutmix-mixup, drop-path regularization
- large weight decay, repeated augmentations
- 어떤 한 모델에 대한 scheme 다른 모델에 적용하면 성능 하락

Knowledge Distillation(KD)
- Hilton loss
- distillation loss : teacher model의 soft label과 student model의 soft prediction을 KL divergence로 distribution이 가깝도록 만듦
- student loss : student model의 hard prediction을 cross-entropy
- KD의 중요성에 대한 논문
- Compounding the performance improvement
- ResNet50의 CLS에 KD가 중요
- DeIT: ViT와 같은 구조 distillation token을 사용하는 KD 적용
- Once-for-All : super network - sub network 학습
- Circumventing outlier of auto-augment with knowledge dict
- KD가 aug의 noise 줄인다.
- 강한 aug 가능
- Compounding the performance improvement
- 하지만 ImageNet에서 KD 잘 사용 안함
- KD 장점
- image가 완전히 mutually exclusive 하지 않은 case, 사람이 봐도 애매, 클래스가 2개인 case
- teacher label이 gt label보다 더 많은 정보, class간의 유사성 상관관계
- label의 error 보정, label smoothing 따로 할 필요x
- more effective, robust optimization
- image가 완전히 mutually exclusive 하지 않은 case, 사람이 봐도 애매, 클래스가 2개인 case
Proposed training scheme
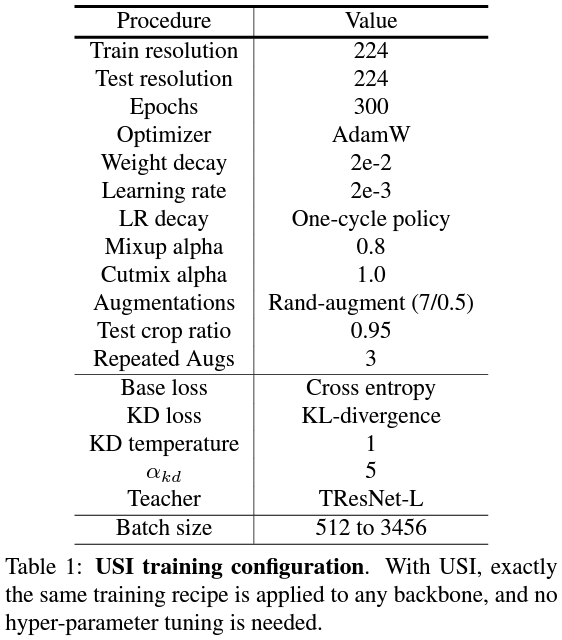
Experiment
- USI 의 robustness 검증
- Architecture, batch size, teacher model, architecture-based regularization
- Scaling sgd batch size to 32k for imagenet training.
- Large batch optimization for deep learning: Training bert in 76 minutes.
- architecture-based regularization : drop-path 적용 상관 없음
- (distillation loss 영향력 조절)에 상관 없음
- KD temperature(): vanilla가 제일 낫다
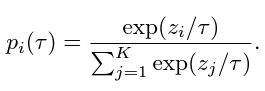
- : softening the teacher predictions
- : sharpening the teacher predictions
- : vanilla softmax
- 추가로 성능 향상 방법
- training epoch ↑ patient teacher
- aug 적용 : mixup-cutmix(tr), cutout(cnn, mobile oriented) → 다 좋다
- speed accuracy comparison
- USI로 동일한 scheme 적용하면, inference speed - top1 accuracy trade off 비교가능
Conclusion
- unified scheme → hyperparam tuning
- SOTA보다 좋음, tailor made scheme보다 좋음
- USI 적용해서 speed accuracy comparison이 동일한 조건에서 가능
- discussion : imagenet이 아니라 cls scheme 적용가능성?
- lr ↑, training epoch ↑, strong aug 하면 적용 어렵다
- KD 적용 자체는 이점이 많다.

2023년 기록, 2023년 계획 : 연구, 블로그, 컨트리뷰션