퍼퓨미즘 향수 추천 알고리즘 정리
1. 데이터 전처리
먼저, pandas 라이브러리를 이용하여 data frame 객체로 만들어 37000개의 향수 데이터를 정제한다.
- null인 데이터를 제거한다.
- 리스트로 되어있는 데이터를 띄어쓰기로 구분된 문자열로 변환 필요
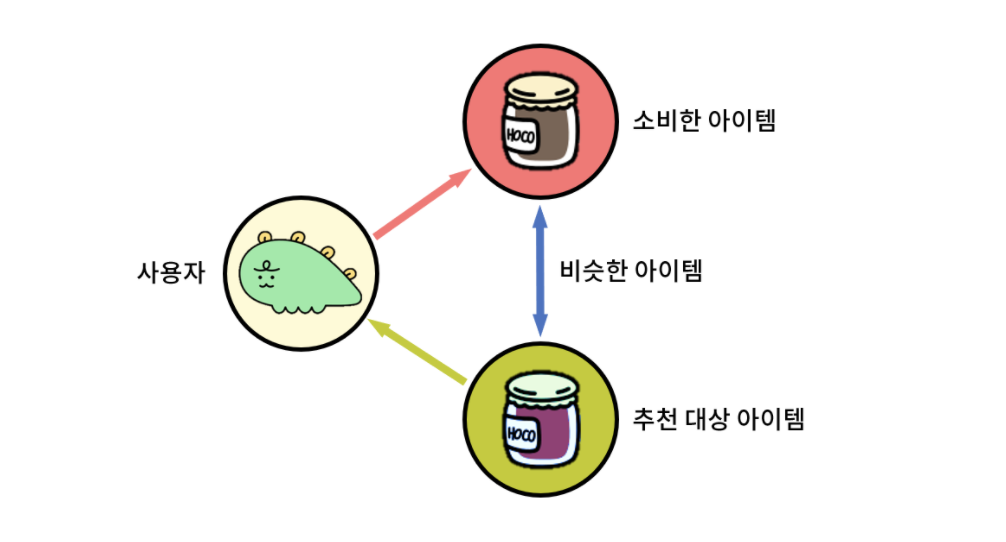
2. 컨텐츠 기반 필터링
컨텐츠 기반 필터링이란?
컨텐츠 자체의 특성을 분석하고 이를 기반으로 유사한 아이템을 추천해주는 추천 방식
ex) 액션 -> 액션 / 로맨스 코미디 -> 로맨스 코미디
이외에 사용자의 행동양식을 기반으로 예측하여 추천하는 협업 필터링 방식이 있다.
퍼퓨미즘에서는 사용자 행동 양식 데이터가 없었기 때문에 컨텐츠 기반 필터링을 선택
코사인 유사도
컨텐츠를 벡터로 표현하여 벡터 간의 유사도를 계산한다.
유사도 함수에는 여러가지가 있는데 코사인유사도가 가장 빠른 모델이고 현업에서도 많이 사용되기 때문에 사용했다.
유사도 함수의 일종으로 두 벡터의 코사인 각도를 계산하여 유사도를 측정하는 방식
-1에서 1사이의 값을 가지며 -1은 서로 완전 반대, 0은 서로 독립, 1은 서로 완전 같음을 의미
사용자 데이터를 군집화 후에 코사인 유사도
인기있는 향수 없는 향수 나눔
컨텐츠 기반 필터링의 단점 : 들어 있는지 없는지만 가지고 판단함
기존 방식
- 전체 데이터 프레임에 사용자 데이터 추가
- 코사인유사도를 전체를 돌렸다! (사이킷런 라이브러리 사용 0아니면 1 사이의 값이 나옴)
- 그것을 정렬을 한다
-> 추출 시간이 5분 이상 걸려 실시간 서비스 제공에 부적합했음. 그래서 군집화 머신러닝 알고리즘을 도입하게 됨
군집화(Clustering)
비지도 학습의 일종으로 데이터 내에서 거리가 가까운 것들끼리 각 군집들로 분류하는 것
그 중에서도 DBSCAN 알고리즘을 도입해서 사용했다.
DBSCAN 라이브러리
밀도 기반 클러스터링 방법으로 복잡하게 분포된 데이터셋에도 효과적으로 군집화가 가능하다
밀도 기반이기 때문에 복잡한 구조에서도 군집화가 가능하다는 이점이 있지만 제대로 적용되지 않는 경우가 있다는 것이 단점.
군집화 도입 후 방식
- 전체 데이터 프레임에 사용자 데이터 추가.
- DBSCAN 라이브러리를 통해 군집화하고 사용자 향수를 같은 그룹 번호를 뽑는다. 그 그룹에 해당하는 df를 만든다.
- 코사인 유사도를 계산해서 정렬해서 높은 값 3개을 추출한다!
(코사인 유사도 결과는 2차원 배열로 나옴)
