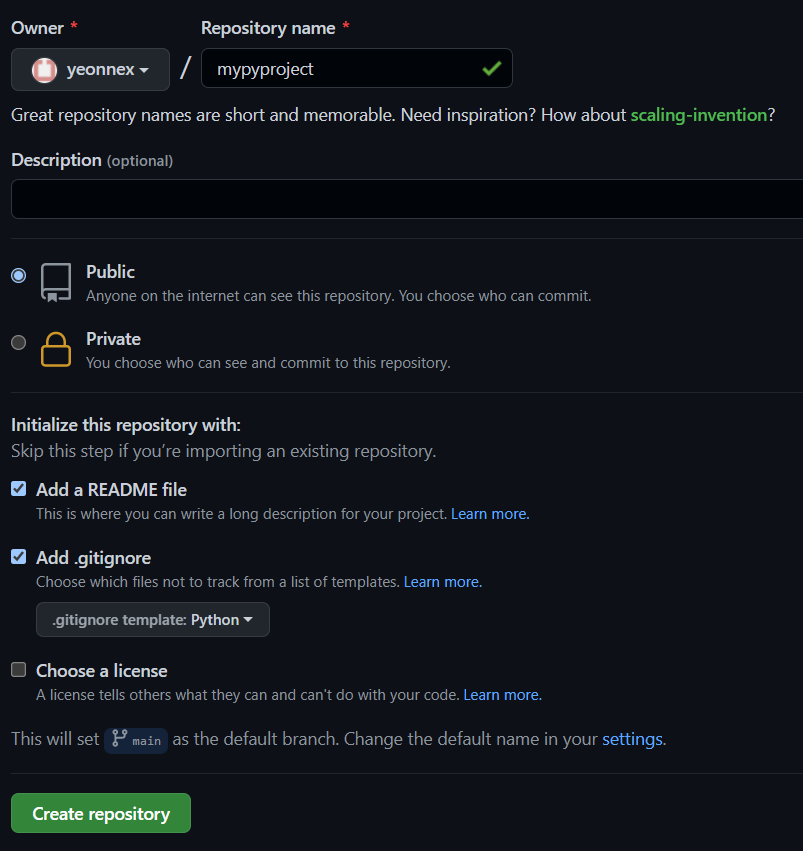
1. 파이썬용 .gitignore 설정
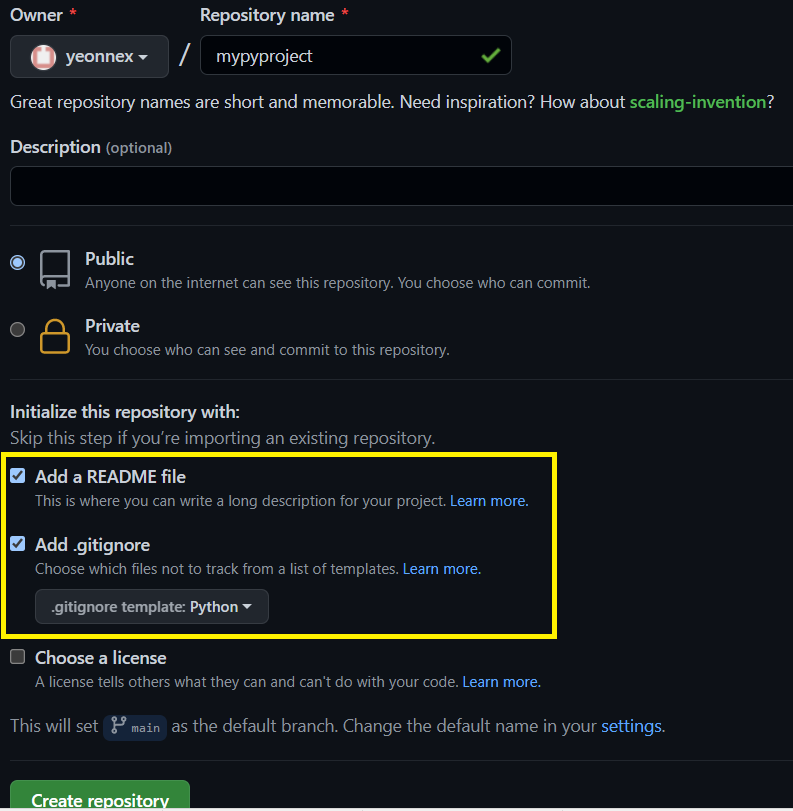
read.me 파일을 체크해주고, .gitignore 파일을 더해주는데, 타입을 파이썬으로 지정해주자. 그렇게 하면 파이썬용 .gitignore 파일에 맞게, 파이썬에서 생기는 불필요하고 귀찮은 파일들 자동적으로 깃 추적에서 제외시킬 수 있게 파일이 짠! 하고 구성되었다.
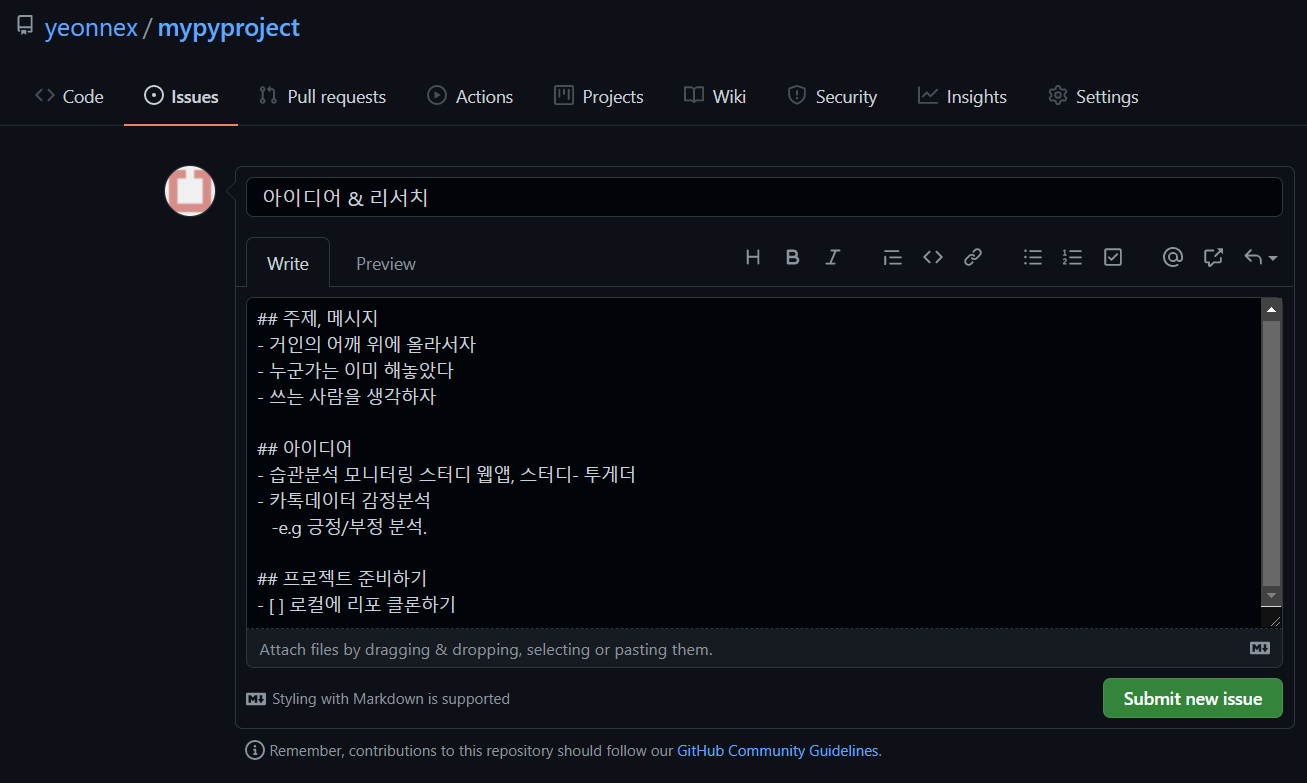
2. 이슈 만들기
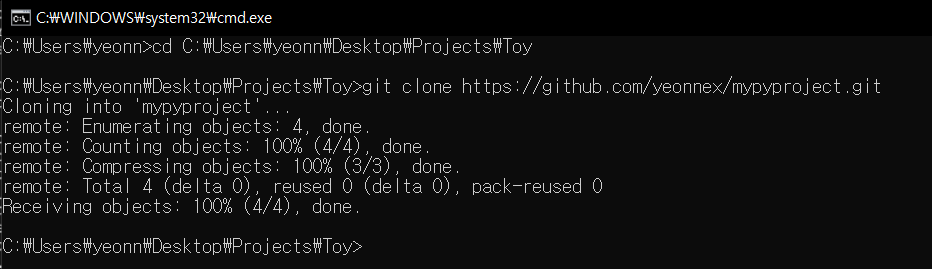
3. 깃 클론
4. 가상환경 만들기
클론한 프로젝트로 디렉토리를 이동해서, 가상환경을 만들어줘야 한다. 즉 이 프로젝트 안에서만 쓸 파이썬 가상환경을 만들어줘야 하는 것이다. 안그러면 나중에 어떤 라이브러리가 의존성 문제를 일으킬 수 있기 때문임. 단순한게 좋다면 virtualenv를 쓰자. 이것도 파이썬 패키지임.
$ pip install virtualenv로 설치할 수 있다.
이제 가상환경을 만들 수 있다.
$ virtualenv venv
이렇게 만든 가상환경은 깃에다 올리면 안된다. 생각보다 사이즈가 크기때문.그리고 계속 바뀌는거라. .gitignore 에다 추가해주자.
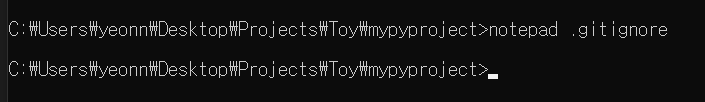
원하는 텍스트 편집기를 사용을 해서 venv를 추가해주자. 근데 처음에 레포 만들때 파이썬전용 ignore 파일 만들었어서 이미 venv 라는 항목이 들어가있긴함

5. ide 로 프로젝트 열기
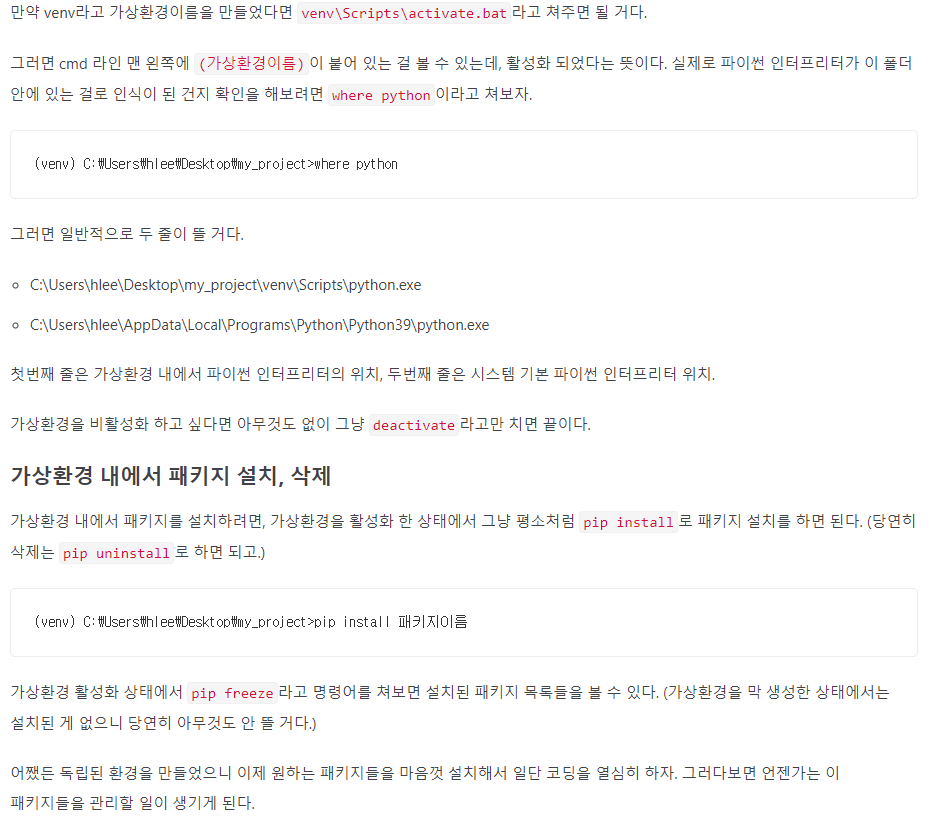
ide 로 갔으면, 이 프로젝트를 위한 가상환경을 활성화해주어야 한다. 물론 명령어로
venv\Scripts\activate.bat 이런식으로 활성화해줄 수도 있지만, gui로 쉽게 활성화할 수도 있다. setting > select python interpreter
6. 프로젝트 안에다가, 프로젝트와 동일한 이름의 파이썬 패키지를 만들자
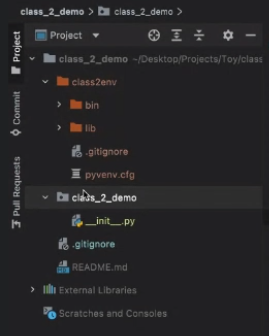
파이썬 관련된 파일을 전부다 저기에 들어가게 한다!!!
이걸 왜 이렇게 하냐면, 나중에 배포를 할 때 파이썬 파일이 여기저기 흩어져있으면은 굉장히 귀찮아지기 때문에, 하나에다 모아준다. 이거는 다른 여러 라이브러리를 가봐도 이와 같은 구조로 되어있다.
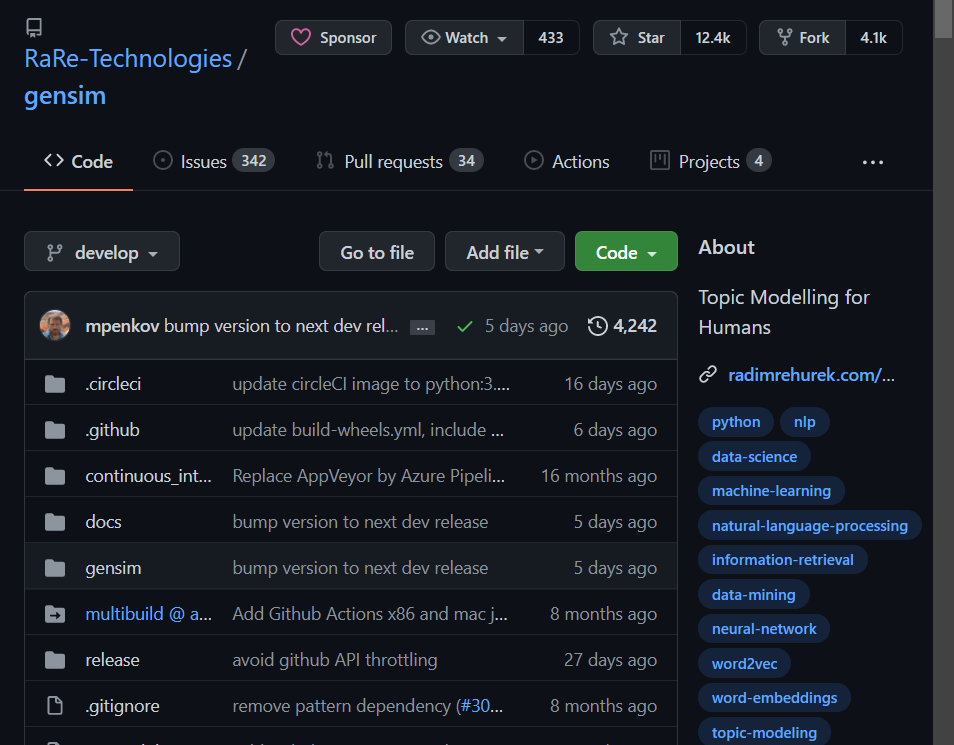
gensim 라이브러리를 가보면, 프로젝트 이름과 동일한 이름의 파이썬 패키지가 있는 것을 볼 수 있다.
tensorflow 를 가봐도, 동명의 디렉토리가 꼭 들어있다.
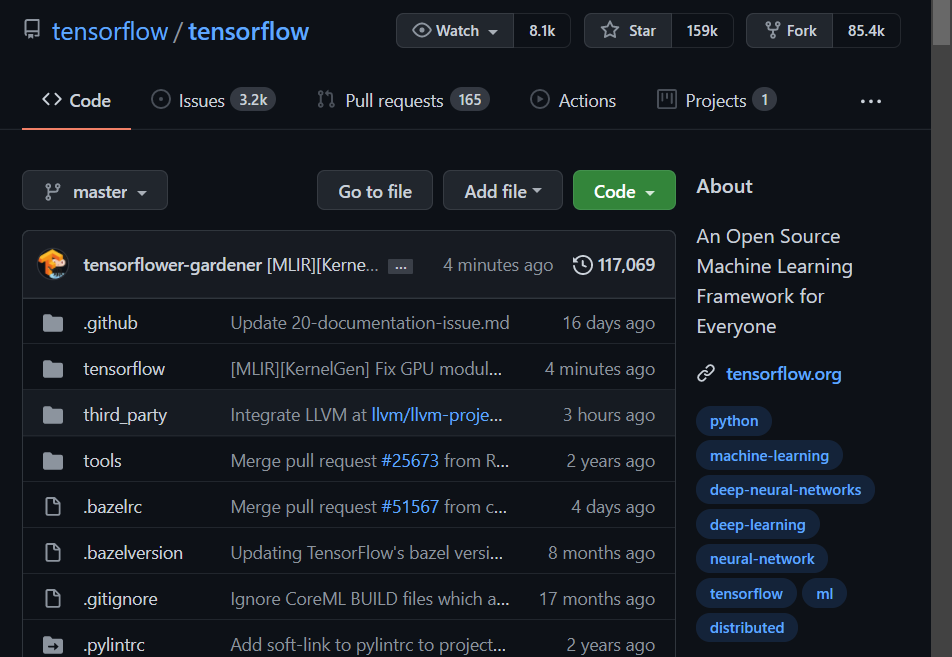
분명 프로젝트가 있는데, 또 똑같은 이름의 디렉토리가 있는 것이다. 배포를 하기 위해서는 저렇게 한 곳에다가 코드를 모아주는 것이 좋다.
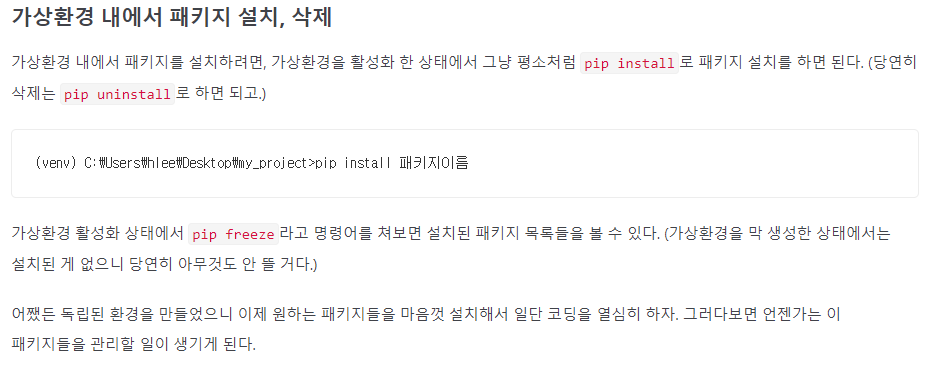
7. 해당 파이썬 프로젝트가 어떤 외부 라이브러리에 의존하는지 적어둬야 한다.
텐서플로우를 설치해야 실행되는 프로젝트라면, 그걸 적어 놔야지 클론하는 사람이 편하고 쉽게 reproduce 할 수 있기 때문.
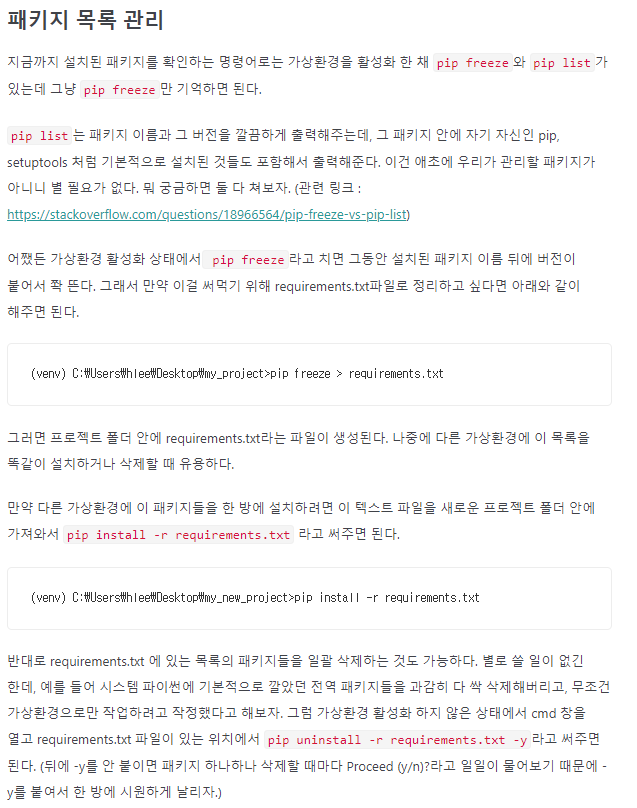
$ pip freeze > requirements.txt
처음 프로젝트를 시작했을 때 pip list 를 하면 뭐가 뜨지 않지만, 진행하면서 프로젝트를 설치하다보면 pip list 했을 때 설치된 라이브러리의 이름과 버전들의 목록이 쭈르륵 뜨는 것을 볼 수 있다.
파이프 심볼로 requirements.txt 에 저장하고 깃에 올리면, 다른 사람들이 클론했을 때 한번에 설치할 수 있는 방법이 생긴다.
- 프로젝트를 만드는 사람 :
pip freeze > requirements.txt - 프로젝트를 클론하는 사람 :
pip install -r requirements.txt
8. 파이썬 패키지 안에 꼭 놀이터를 하나 만들자.
뭐든 다 써도 되는, 막 코딩해도 되는! 뭔지 모르겠어도 그냥 치면서 실행시켜 보는 것.
9. 파이썬 패키지 안에, paths.py 를 만들어 경로를 관리하자
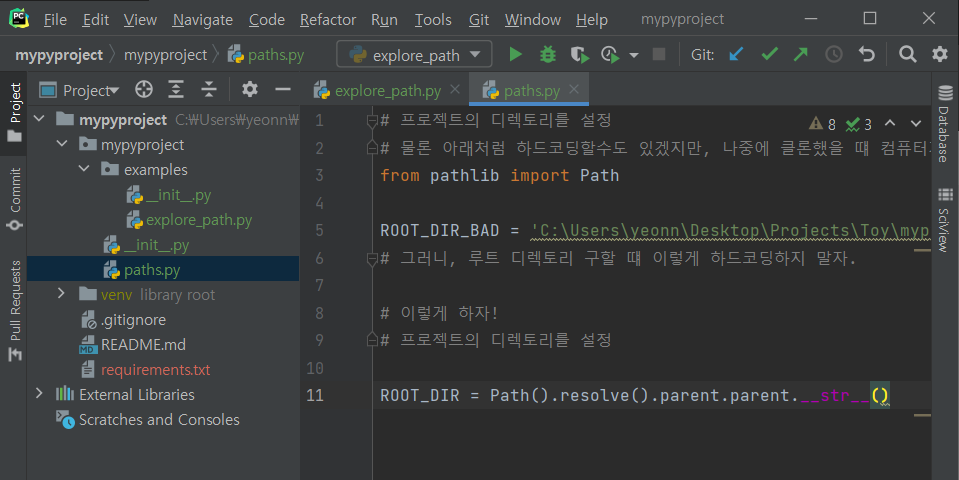
경로를 이렇게 상수선언하면, 나중에 코드를 짤 때 굉장히 편리해진다.
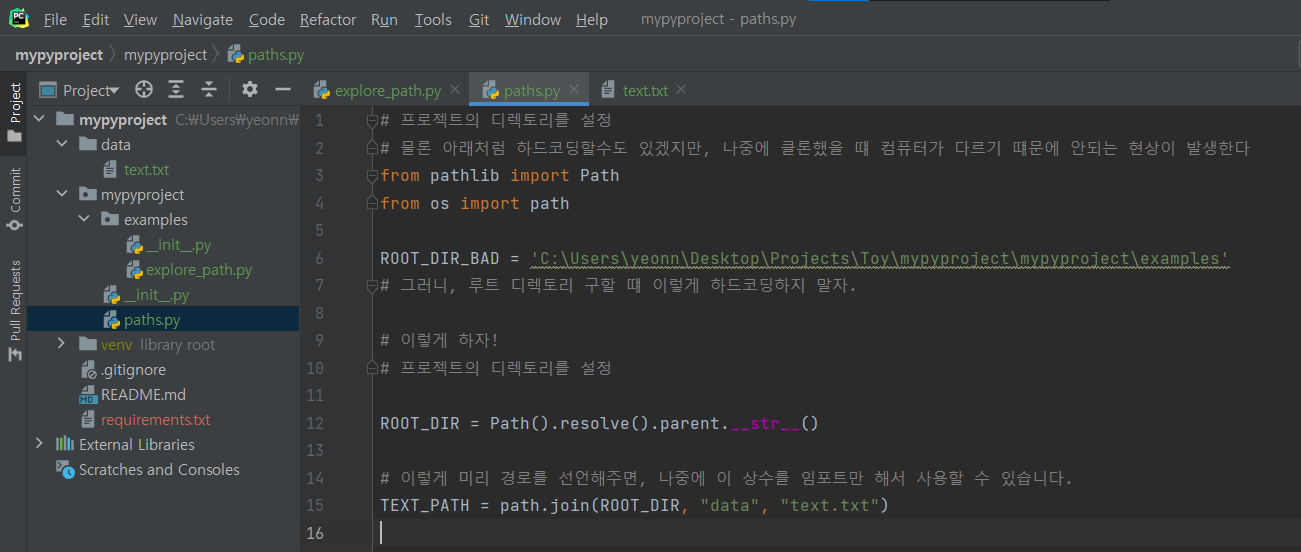
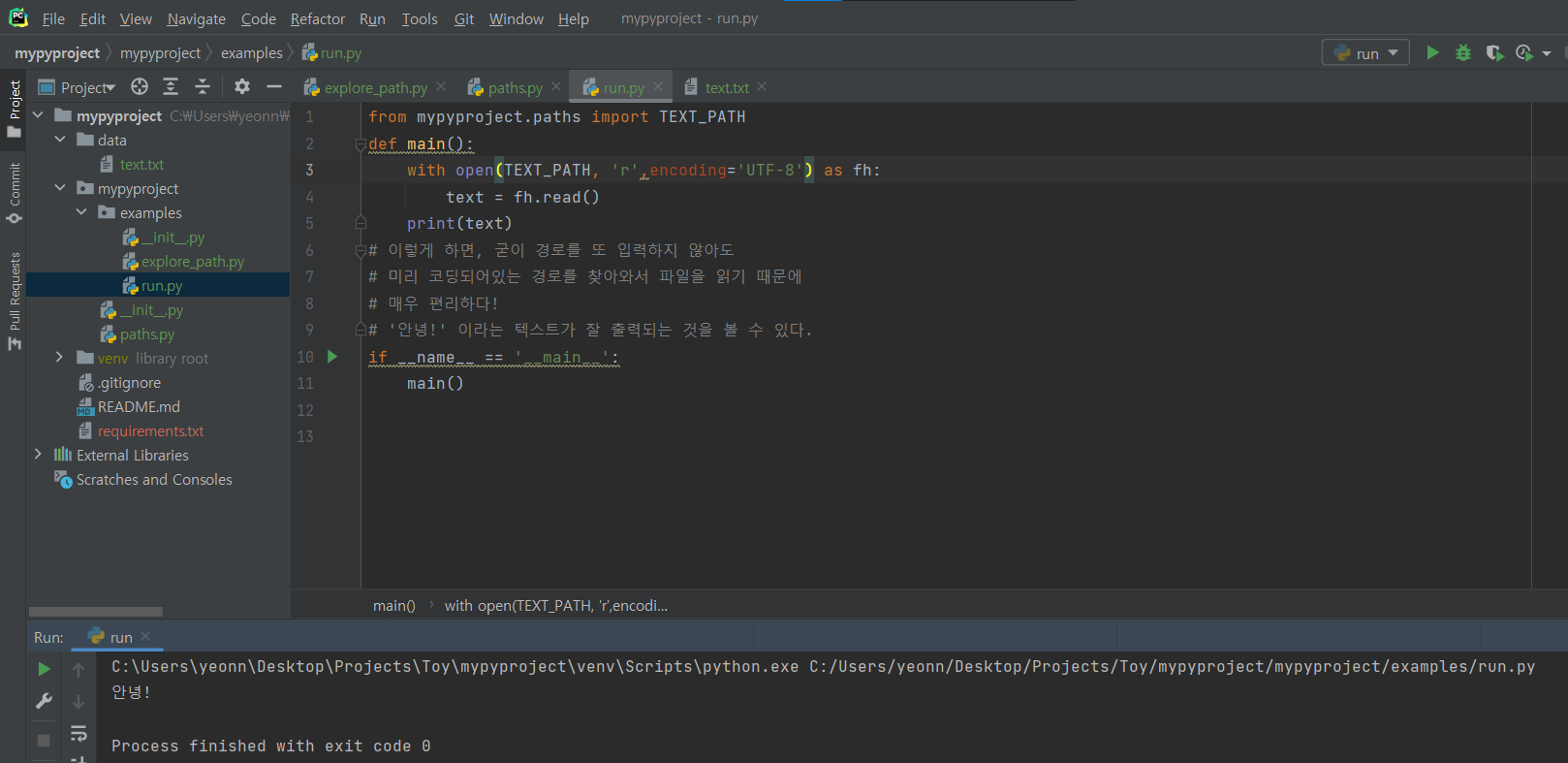
다른 사람들의 깃헙 프로젝트를 봐봐도, 위와 같은 구조를 띄고 있는 것을 확인할 수 있다.
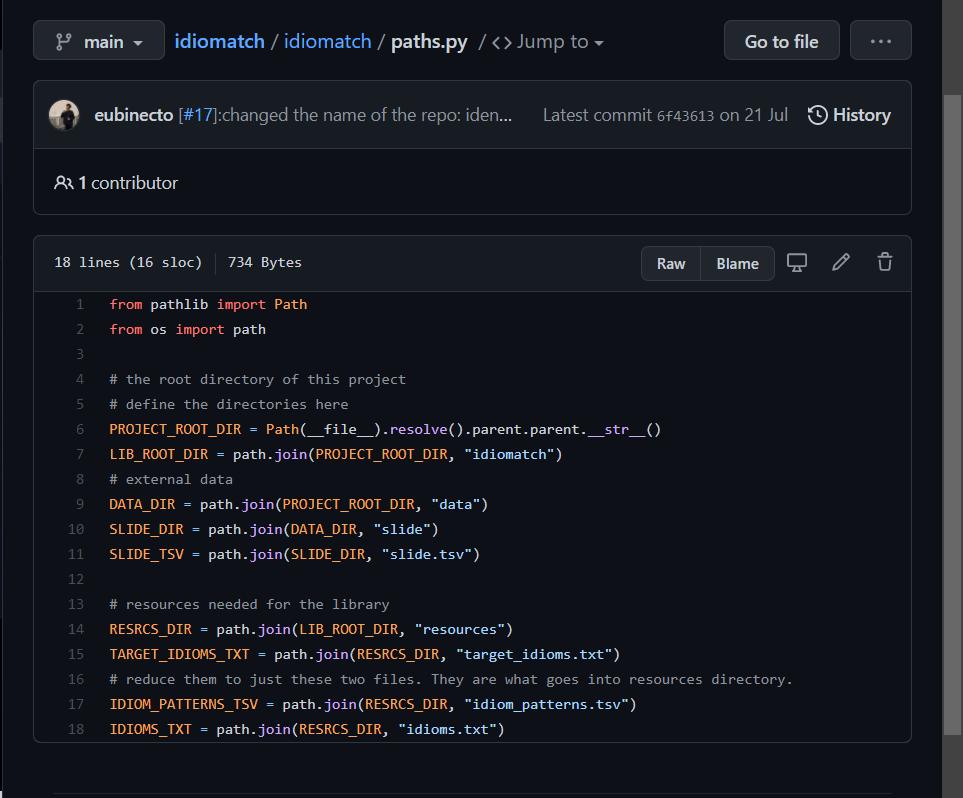
이렇게 경로들을 상수처럼 선언을 해놓고, 필요할 때 임포트해서 가져다 쓰는 방식!
여기까지 했으면, 프로젝트를 준비 완-료
10. 풀고자 하는 문제가 뭐지?
입력과 출력을 정확하게 수식으로 표현할 수 있어야 한다.
- 댓글 감정분석
- 입력 : 문장 (w1, w2, ...wn)- 출력 : 긍정/부정 -> binary classification -> logistic regression -> [ 0.8, 0.2 ] -> 확률분포
이렇게 명확하게 정의해놔야, 검색을 효율적으로 할 수 있음
다음 단계는 - 거인의 어깨위에 올라서는 단계
- 아무리 아이디어가 좋아도, 지구상 어딘가에 누군가는 동일한 사람이 이미 만들어놓았음. 겸손한 태도를 가져야 한다.
검색 - 라이브러리
자연어처리 관련
-
hugging face 의
transformers
https://huggingface.co/transformers/
- 구글이든 페북이든 다 언어모델을 개발하는데, 여기다가 무료로 배포해줌. 그러면 사전 훈련된 모델을 얼마든지 무료로 받아와서 가지고 놀 수 있음 -
kakao의
pororo
https://github.com/kakaobrain/pororo
- 한국에서도 비슷한 시도. 서너줄만으로도 감성분석을 할 수 있게 도와주는 한국어 라이브러리. 챗봇을 만든다면, 트랜스포머는 한국어를 아마 지원을 안할텐데, 한국어 프로젝트를 한다면 추천하는 라이브러리 -
일단, transformers 로 감성분석을 할 수 있는지 살펴보자!
transformer 의 pipeline을 검색해보면, 바로 가져다쓸 수 있는 것을 모아놓음
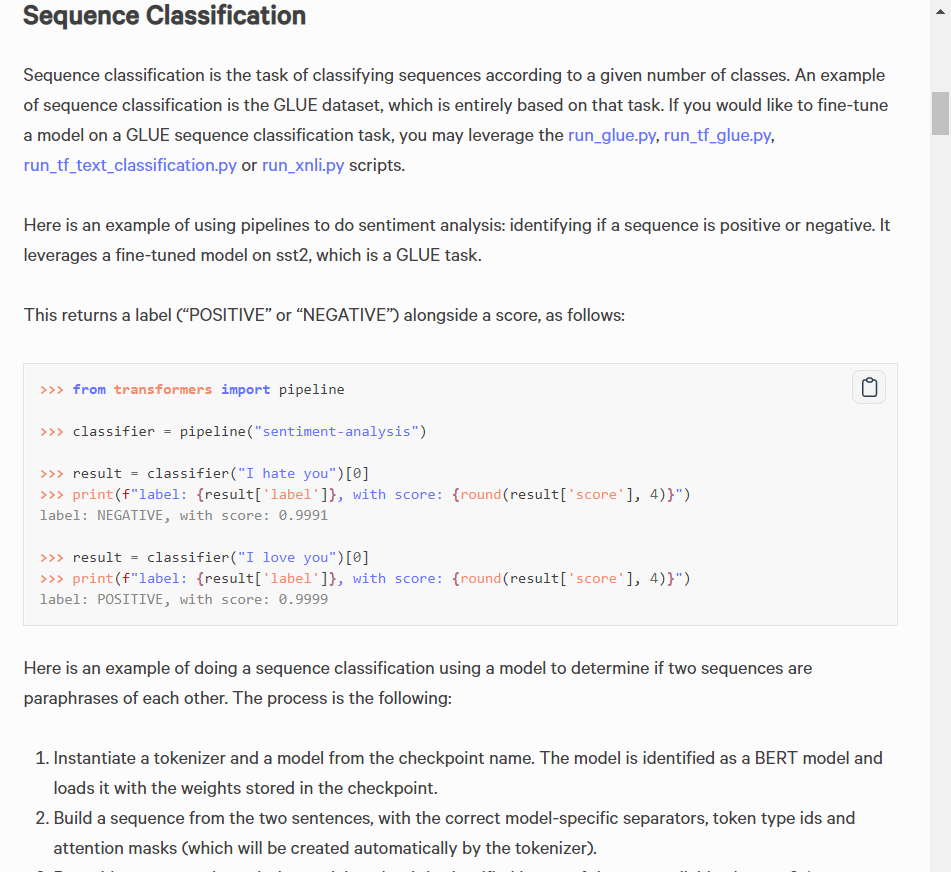
검색해보니, 감정분석 파이프라인이 있음!
바로 사용해보겠다.
바로 사용해보겠다는 말이, 그냥 말그대로 바로 사용해보겠다는 말이다.
처음보는 라이브러리라도, 어려워도, 그냥 풀장에 뛰어드는 것이 좋다.
예시 코드가 있으면 그냥 바로 복붙해보자.
이걸 위해 프로젝트 안에 동명의 파이썬 패키지 놀이터 폴더를 만들어 놓은 것이다.
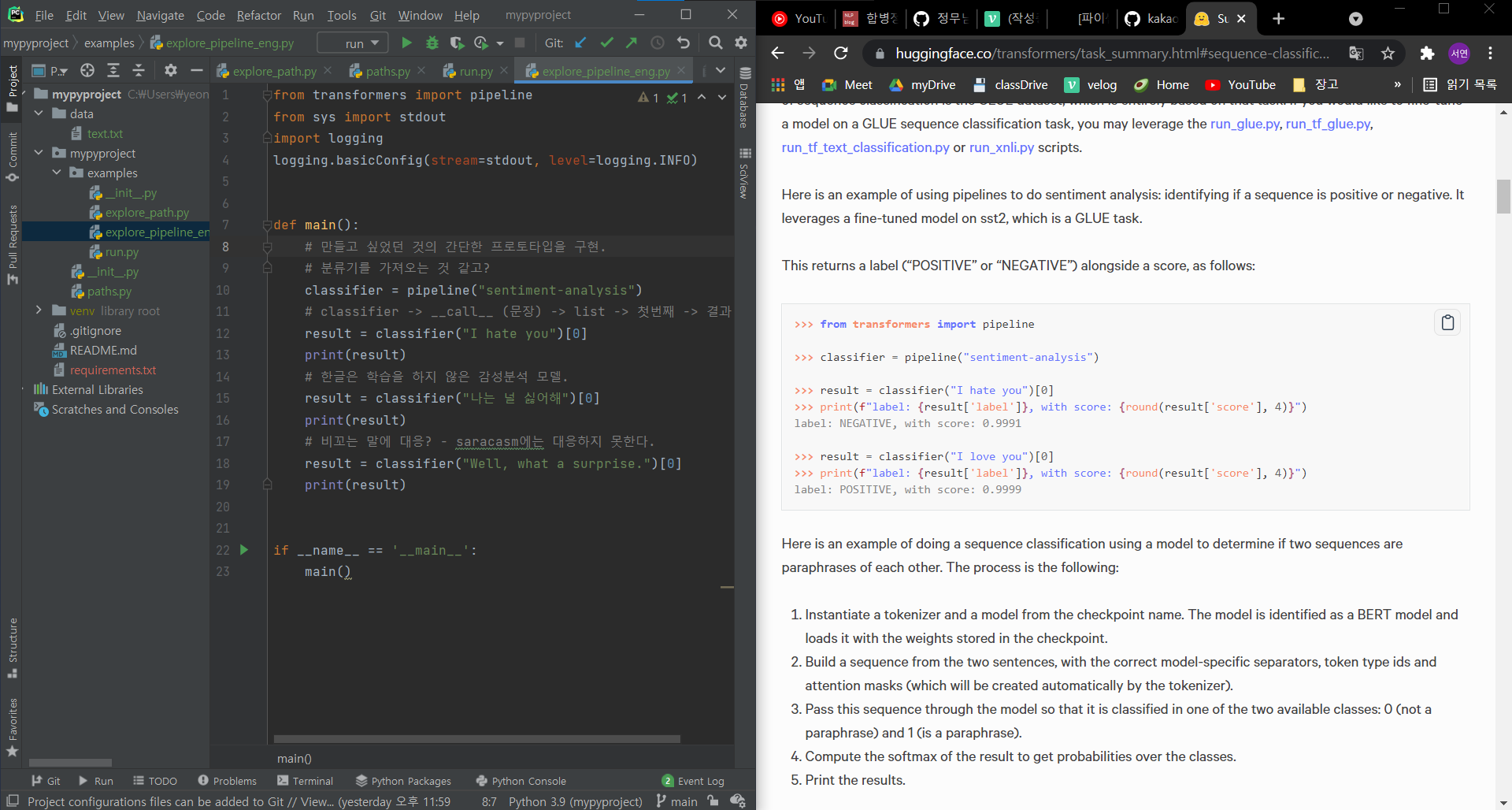
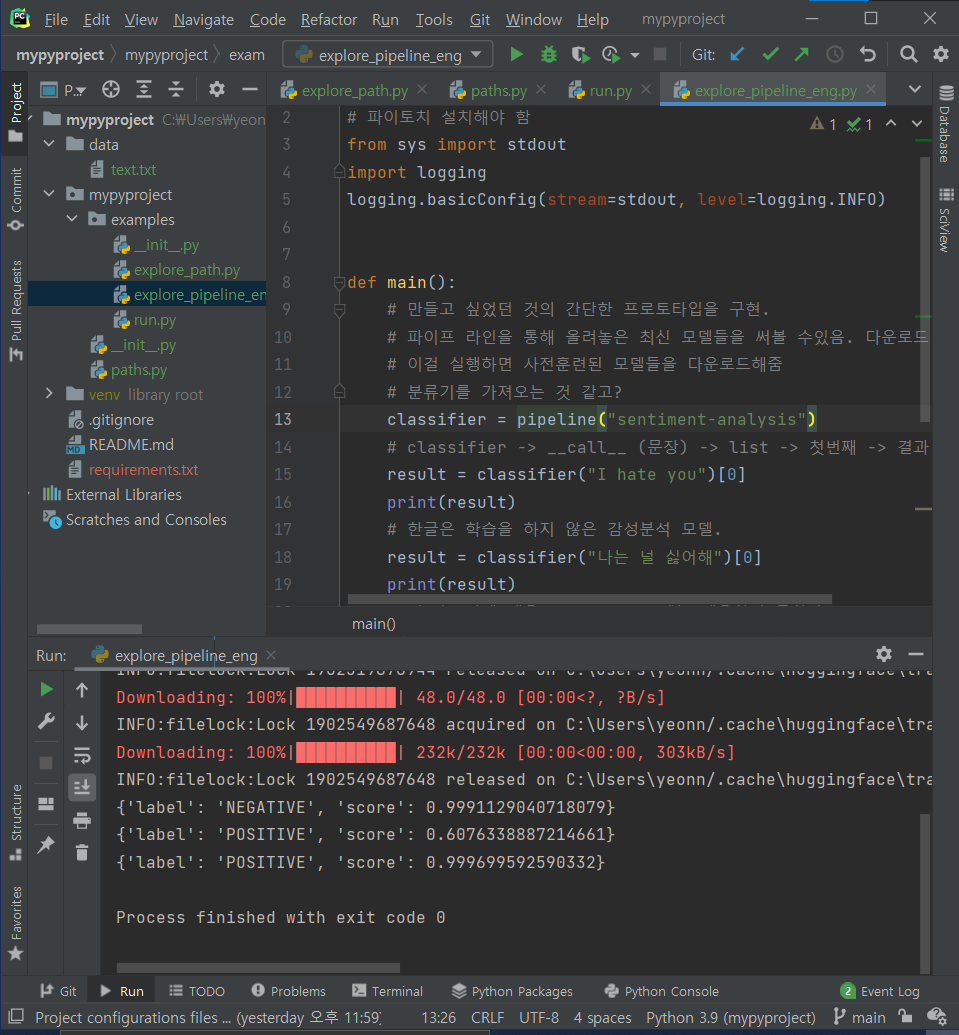
검색 - google scholar
- 해결이 되지 않는 문제는 논문을 검색해보아야 한다.
- 비꼬는 말은 어떻게 대응하지?
이렇게 깃헙의 issue 탭에서 스스로에게 질문하고, 문제를 찾고, 문제를 해결하는 과정을 일기처럼 쓰면은, 했던 고민들을 이력서에 보여주면 그게 하나의 포트폴리오가 되는 것이다.
만든 것만 보여주는 게 아니라, 어떤 과정을 거쳐서 만들어졌는지 보여지기 때문에 매우 좋다!
