아스키코드 (ASCII CODE, American Standard Code for Information Interchange) : 미국에서 각각의 문자, 즉 키보드에 등장하는 문자 -> 실제 컴퓨터에서는 이진수로 인식됨.
문자 'A'는 어떤 정수값에 대응을 시킬 것인가? 65
B = 66
...
각각의 코드 값에 대한 "이진수"가 실제 컴퓨터에 저장된다.
"+" 같은 키보드의 캐릭터도 정수 43을 부여받는다.
Null은 정수 0을 부여받는다.
이런식으로 0부터 255까지 , 즉 8비트에 키보드에 나타나는 아스키코드 값을 다 배정을 함.
물론 한글이나 한자는 8비트에 다 표현을 못하기 때문에, 여기에 한바이트 더 늘린, 즉 2바이트를 써서 코드체계를 만들었는데, 그것이 바로 유니코드임.
아스키코드는 한바이트에 다 들어가고, 유니코드는 두바이트에 들어감
이런 문자들은 고정된 비트수를 갖고, 여기에 들어가는 정수값으로 배정이 된다. 이런 코드를 고정길이코드(fixed length code)라 한다.
아스키코드는 고정길이코드임.
예를들어, 문자 100개로 구성된 파일을 아스키코드로 코딩을 하면 100개에 대해 각각 8비트씩 필요하기 때문에 800비트짜리 텍스트파일이 됨.
100개의 문자를 저장하기 위해서는 800비트가 필요함
그런데 이제, 영문자에 한해서 보면, 어떤 알파벳은 많이 쓰이고, 어떤 알파벳은 적게 쓰임.
예를들어, a,e i,o,u 같은 문자들은 일반적으로 사용빈도수가 높다. 그러나 q나 z, y는 빈도수가 낮다. 그렇다면, 많이 등장하는 모음과 같은 문자는 되도록 짧게 하면 좋잖아요! 빈도수가 얼마 안되는 문자들은 그 문자에 해당하는 코드를 좀 길게해도 상관 없고! 어차피 몇번 등장 안하니까!
이런식으로 뭔가 문자마다 할당하는 코드의 비트수가 딱 고정된 것이 아니고 변할 수 있게, 어떤 것은 짧게, 어떤 것은 길게 하는 코드를 가변길이코드(variable length code) 라고 함.
이런 가변길이코드 중에 하나가, "허프만"이라는 사람이 제시한 허프만 코드이다.
허프만코드문제는 이 허프만코드를 어떻게 할당할지 결정하는 문제가 허프만코드 문제이다!
예를 들어, a,b,c,d,e,f 로만 이루어진 전체 100개의 문자중 다음과 같이 문자가 분포되어있다고 하자.
| 문자 | 빈도수 |
|---|---|
| a | 43 |
| b | 13 |
| c | 12 |
| d | 16 |
| e | 6 |
| f | 7 |
고정길이라면, a~f를 표현하기 위해 총 3비트가 필요하다. 3비트로 8개까지 표현할 수 있으니까! 두개는 부족하고...
고정길이에서 100개의 문자를 나타내려면 총 3x100 비트가 필요하다.
가변길이에서는?
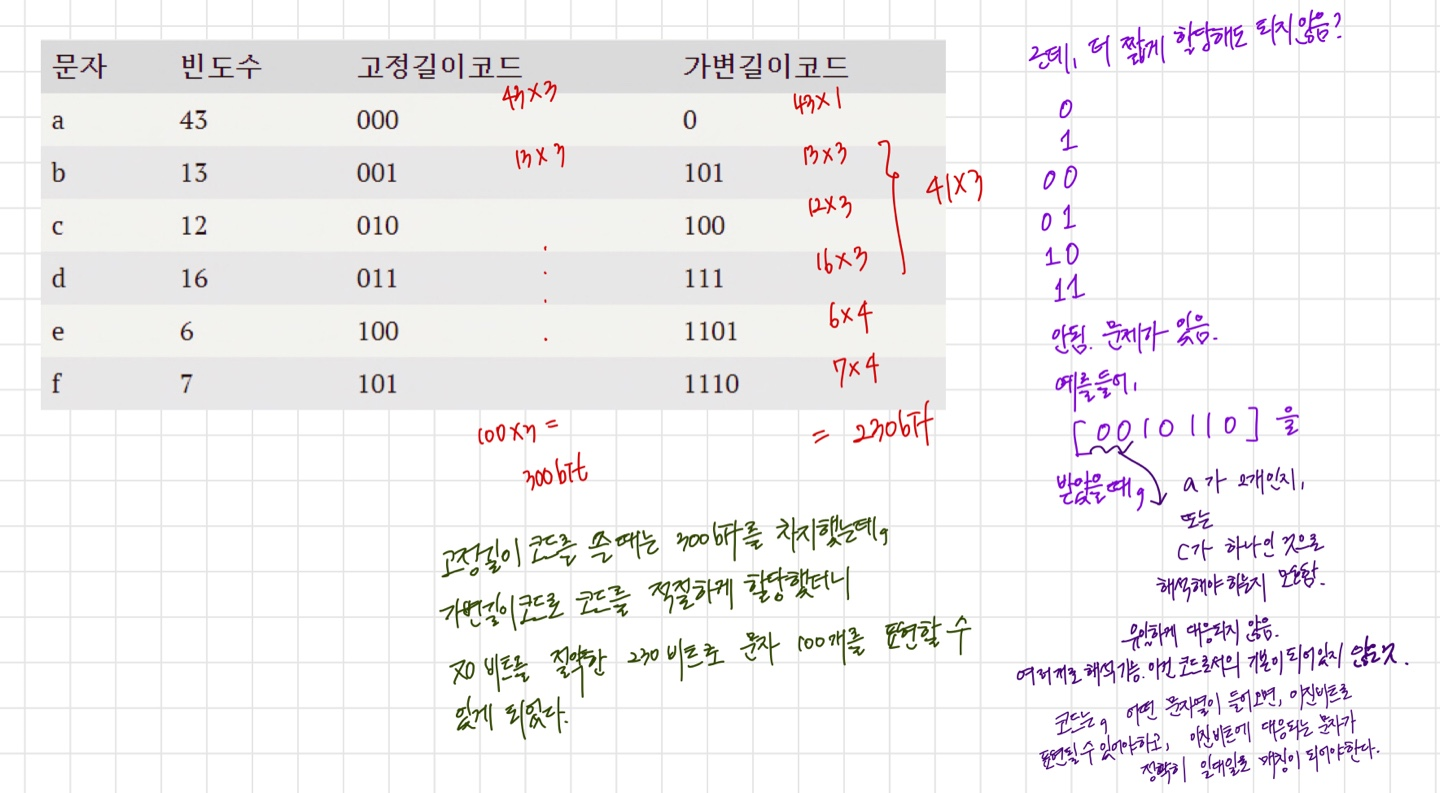
보라색처럼 코드를 할당하면 왜 문제가 발생할까?
prefix가 0, 또는 1로 똑같기 때문임. a도 0으로 시작 c도 0으로 시작 / b도 1로시작 e 도 1로 시작...
prefix-freecode : 어떤 문자의 코드가 다른 문자의 prefix가 되지 않는 코드!
보라색 코드와는 달리, 표에서의 가변길이 코드는 그들간에서 0으로 시작하는 코드나, 101로 시작하는 코드나, 100으로 시작하는 코드나, 111로 시작하는 코드나, 1101로 시작하는 코드나, 1110으로 시작하는 코드가 없다! 즉 프리픽스프리코드이다. 올바른 코드!
그래서 우리는, 이제 어떤 문자와 빈도수가 주어지면 전체 비트수를 최소로 만드는, prefix-freecode 중에서도 가변길이코드를 만들고 싶은 것!

문자와 빈도수가 주어지면, 어떤 조건을 최대화하는 가변길이 코드를 구해야 할까?
문제를 정확히 정의해보자.
가변길이코드는 여러개가 있을 수 있다. 그중에서, 위에서 보이는 것은 가변길이 코드로 할당할 수있는 예중 하나이다.
이 가변길이 코드에 대한 이진트리를 하나 만들 수 있다.
리프노드는 네모로 표시하고, 리프노드가 아닌 노드는 동그라미로 표시했다.
리프노드는 각각의 문자를 나타낸다.
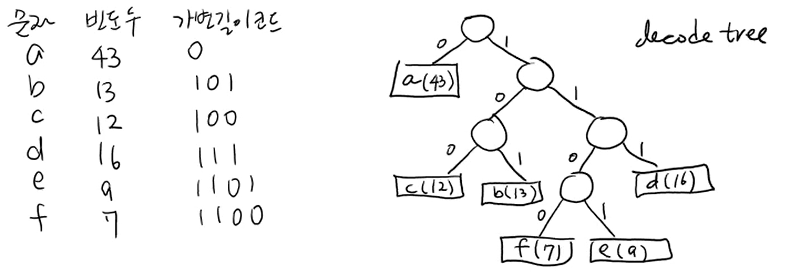
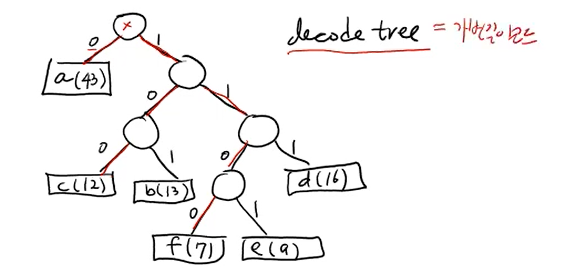
decode tree하나가 하나의 가변길이코드를 나타낸다!
각 코드가 다른문자의 prefix가 절대 될 수 없다.
decode tree가 굉장히많은데, 이중 "전체 비트수를 최소화하는 decode tree"를 만들어야 한다.

cost값이 최소가 되는 T 를 구하는 것이 목적
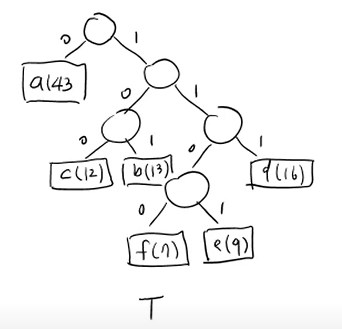
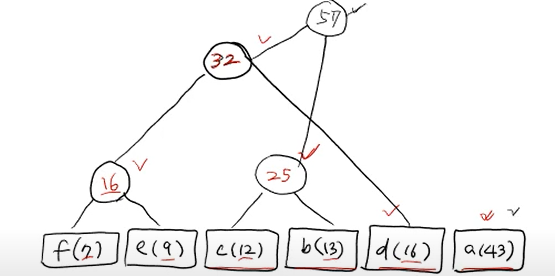
이게 앞에서 봤던 decode tree중에 하나인데, 사실 이게 정답임

허프만씨의 idea는 아래와 같다.
빈도수가 높은 문자는 루트노드에 가까이 있어야 한다.
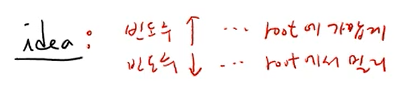
이 아이디어를 가지고 decode tree T를 만드는 것이다!
방법은 다음과 같다.
(1) 빈도수의 오름차순으로 정렬한다.
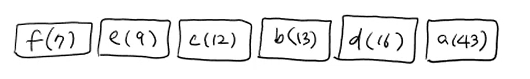
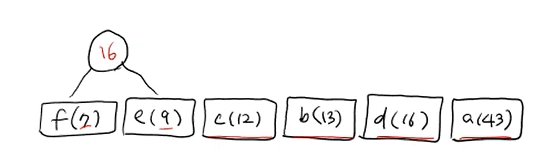
처음에는 그냥 다 리프노드만 있는 것이다. 아직 동그란 노드 없음!
(2) 가장 빈도수가 낮은 리프노드 두개를 선택한다.