◦ 분산 데이터 스트리밍 플랫폼
◦ 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산 데이터 스트리밍 플랫폼
카프카는 어디에
- 데이터 처리량이 많은곳
- 작은 프로젝트 일 때에는 안정적인 운영과 확장성을 고려해야 할 때
왜 카프카
- 데이터를 한곳에서 처리하기 때문에 편리
- 짧은 시간에 많은 데이터를 전달 할 수 있음(컨슈머로 전달 가능)
- 확장성이 뛰어남 (사용하고 있는 브로커가 있어도 새로운 브로커 서버를 추가 할 수 있고 replica가능)
- 데이터(토픽에 저장된것)은 컨슈머가 가지고 가더라도 삭제되지 않음
구성
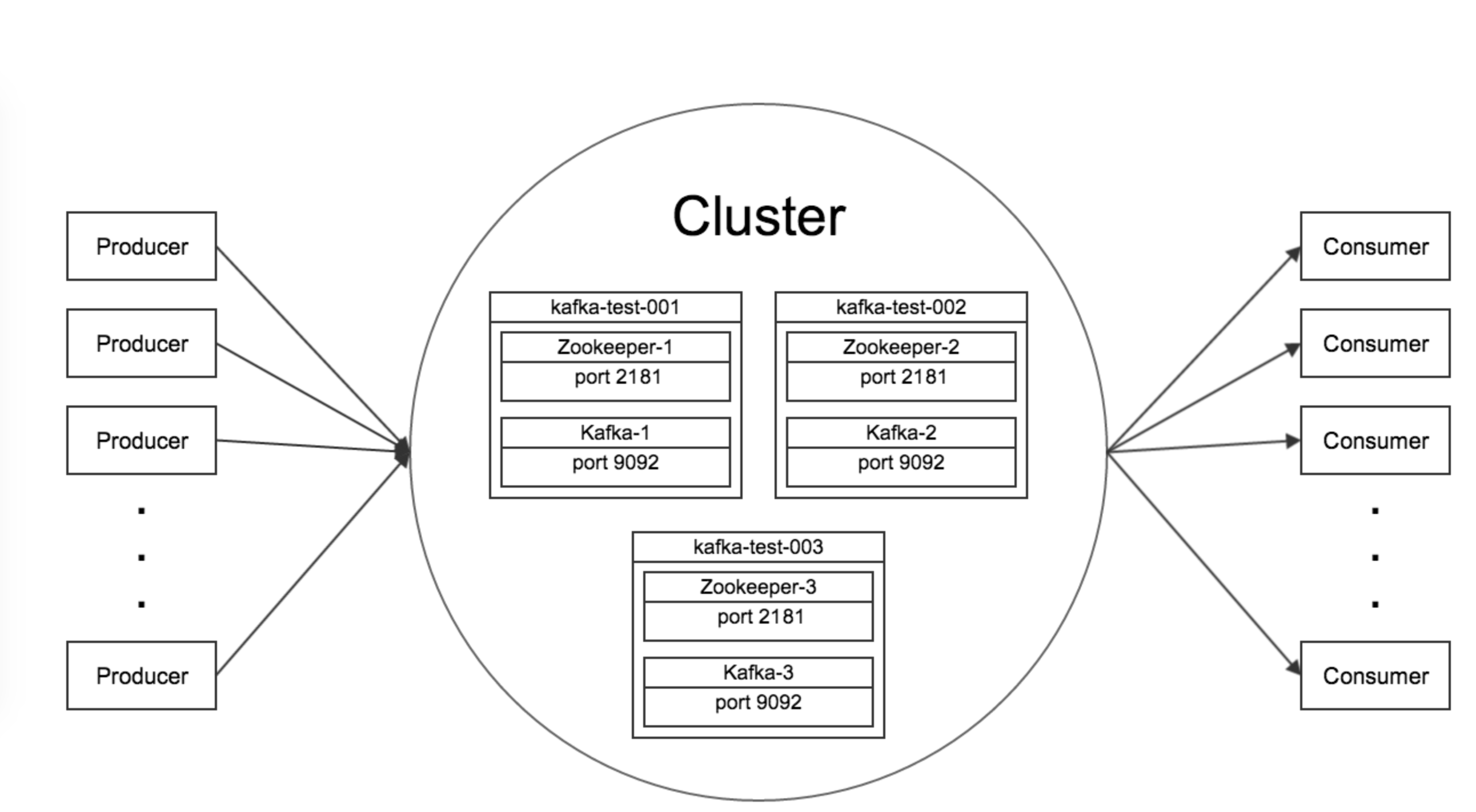
Broker
- 카프카 서버
zookeeper : 분산된 시스템에서 자원을 공유하는 방법,어떤 상태를 체크할 것인지, 동기화 잠금을 처리하기 위한 도구
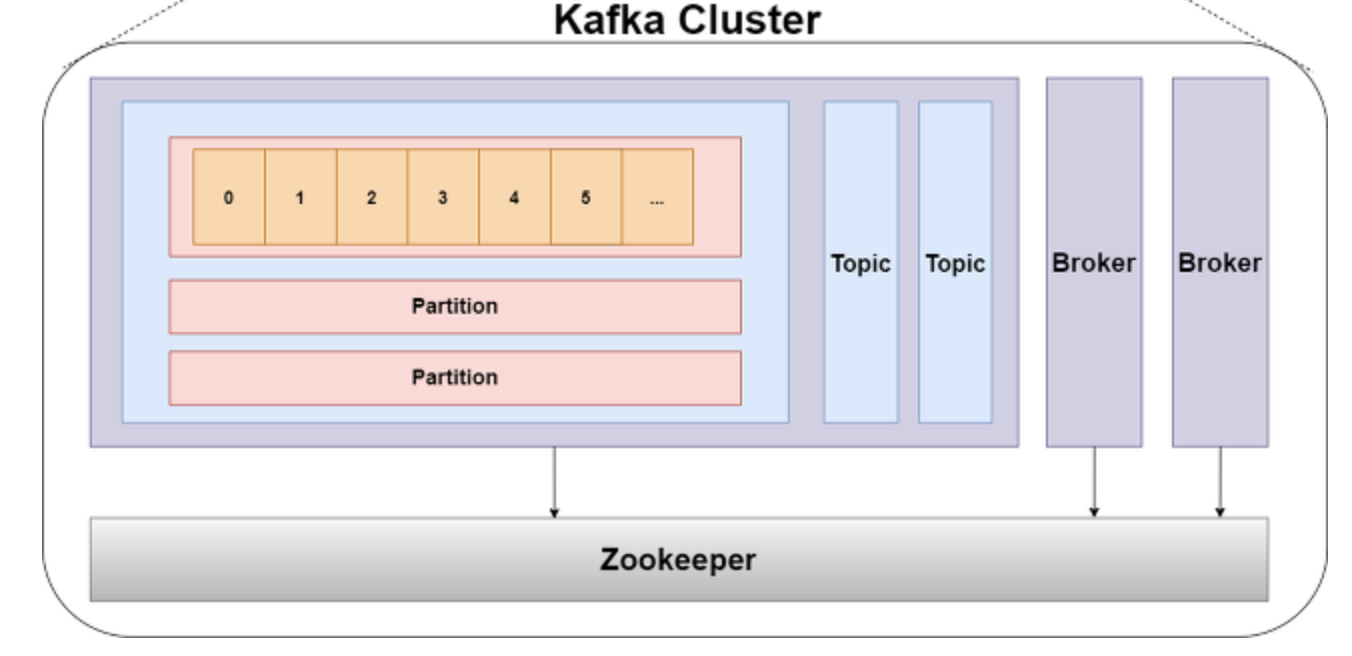
topic
- 데이터가 들어갈 수 있는 부분
- 토픽을 여러개 생성 할 수 있음
- 토픽은 데이터베이스의 테이블, 파일시스템의 폴더와 유사
- 토픽에 프로듀서가 데이터를 넣고 컨슈머가 데이터를 가지고가게된다
- 그 토픽에 click_log login_log 이런식임
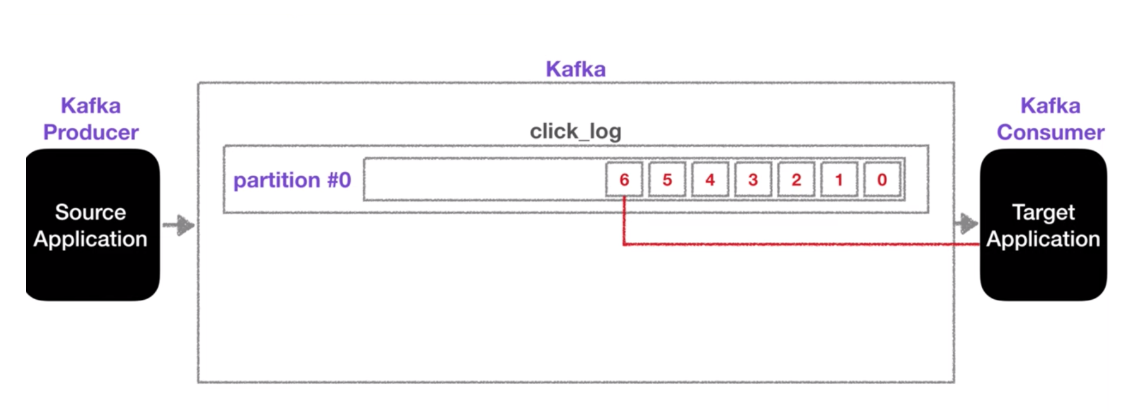
- 파티션에 데이터가 저장될 때는 key값을 기준으로 분산저장이 되며, 키가 없을 때에는 round-robbin으로 저장됨
카프카 특징 중 데이터를 가지고 가더라도 삭제되지 않는다는 점이 있는데, 데이터를 가지고가고 지우는 것이 아니라 offset으로 가지고 간 데이터를 저장해서 사용하기 때문에 삭지되지 않음
왜 좋은걸까??!
이러면 다른 컨슈머가 동일 데이터에 대해서 두번 처리 할 수 있음
그럼 언제 삭제되는걸까??
최대시간과 크기에 따라서
프로듀서
데이터를 카프카에 보내는 역할
- 토픽에 전송할 메세지 생성
- 특정 토픽으로 데이터를 퍼블리시
- broker로 전송할 때 전송 성공 여부를 알 수 있고 재시도 가능
컨슈머
파티션에 저장된 데이터를 가지고 오는 역할
- 가지고 오는 것을 polling한다고 하는데 해당 polling 단계에서 데이터를 ES나 하둡 등으로 보내는 부분을 처리
- 컨슈머는 그룹을 설정해서 병렬 처리 할 수 있음
offset in polling
offset에 어디까지 데이터까지 읽었는지를 알게하는 것
- __consummer_offset에 저장되어있음
- 그 중지된 시점을 알고있으므로 복구 가능
- 컨슈머 그룹별로 따로 저장한다
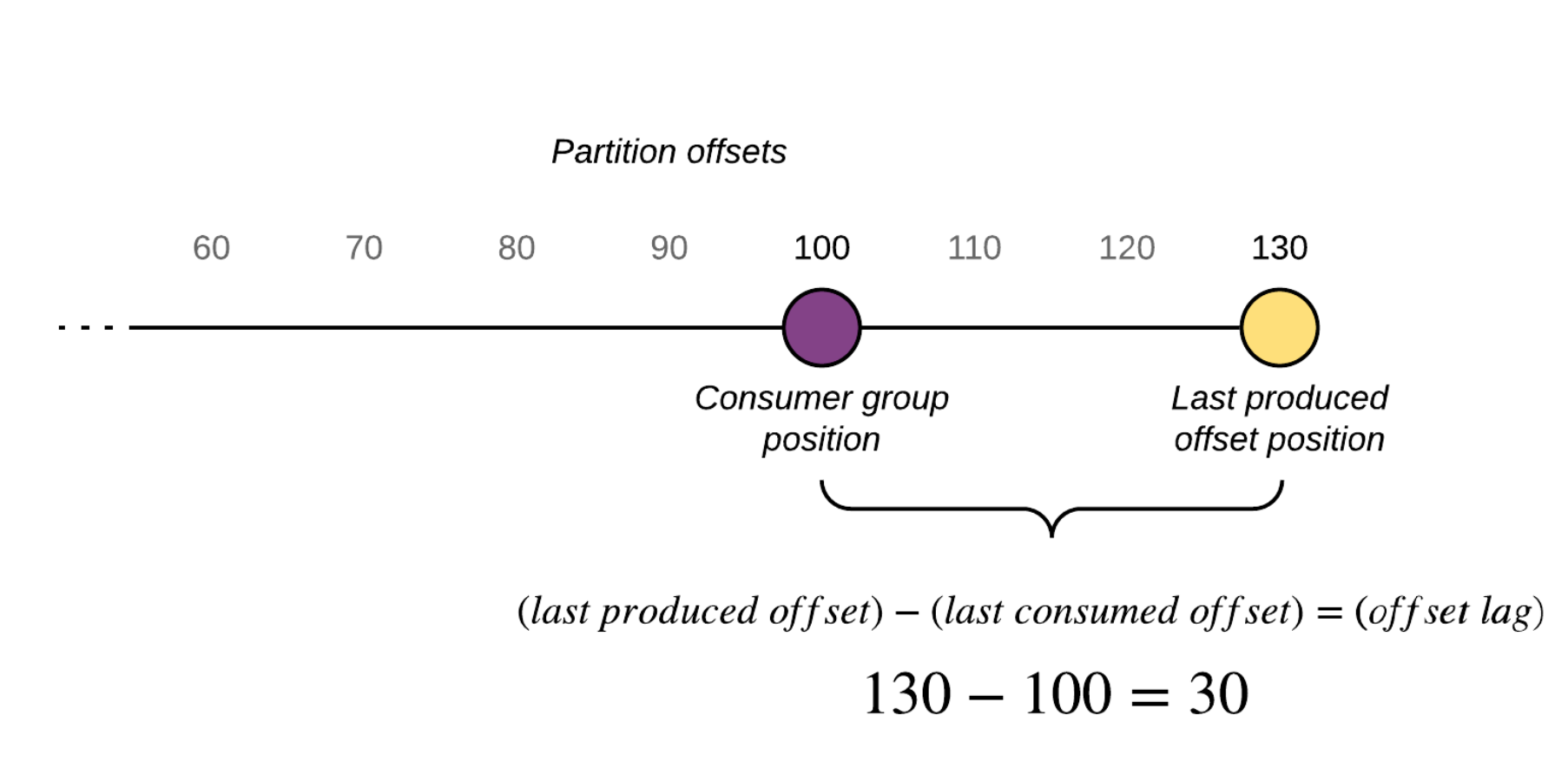
카프카 lag
카프카 모니터링 지표 중 하나로 데이터 offset으로 파악하게 되는 지표
kafka consumer lag
컨슈머가 마지막으로 읽은 오프셋과 프로듀서가 마지막으로 넣은 offset의 차이
producer와 consummer의 상태를 확인 할 수 있으며 주로 컨슈머의 상태를 확인 할 수 있다.
Records-lag-max
파티션이 여러 개 일 때 lag도 여러개 일 수 있는 데 그중 가장 높은 숫자의 lag
lag 모니터링은 어떻게?
- 컨슈머 단에서 모니터링하는 것은 위험할 수 있음
- 왜냐면 컨슈머가 비정상 종료시 모니터링도 종료되기 때문
- burrow : linkedIn에서 내놓은 카프카 모니터링 툴
quick start
brew install kafka
brew services start zookeeper
brew services start kafka
brew info kafka
/usr/local/Cellar/kafka/2.3.0
cd bin
./kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 -partitions 1 --topic topicname
dev
많은 도움 되었습니다~!