
상수 시간(리스트의 길이와 무관 ) : O(1)
선형 시간(리스트의 길이에 비례) : O(n)
🧱선형 배열(Linear Arrays)
데이터 원소들을 순서를 지어 늘어놓는다. 번호가 붙여진 칸에 원소들을 채워넣는 방식이다.
저장 공간 : 연속한 위치
특정 원소 지칭 : 매우 간편 O(1)
🔧정렬(Sorting)
- sorted() : 정렬된 새로운 리스트를 얻어낸다. 내장함수
- sort() : 해당 리스트를 정렬한다. 리스트의 메서드
오림차순이 디폴트. 내림차순은 reverse=True
🪓탐색(Searching)
- 선형 탐색(순차 탐색 Linear Search) : 순차적으로 진행한다. O(n)
- 이진 탐색(Binary Search) : 탐색하려는 리스트가 이미 정렬되어 있는 경우에만 적용 가능하다. 크기 순으로 정렬되어 있다는 성질을 이용한다.
한 번 비교가 일어날 때마다 리스트 반씩 줄인다. O(log n)
이진 탐색이 선형 탐색보다 빠른 방법이나, 항상 이진탐색을 사용하지는 않는다. 그러려면 우선 배열을 정렬해야 하는데, 한 번만 탐색하고 말 거라면, 굳이 크기 순으로 늘어놓느라 시간을 소모하는 것보다 한번씩 다 뒤지는 것이 나을 때도 있다.
💣재귀함수(Recursive functions)
하나의 함수에서 자신을 다시 호출하여 작업을 수행하는 것으로 종결 조건이 매우 중요하다.
재귀적인 방법으로 많은 문제를 풀 수 있다. ex) 이진트리, 자연수의 합 구하기, 조합의 수, 하노이의 탑, 피보나치 순열
재귀함수(recursive version) VS 반복문(Iterative version)
둘 다 O(n)이지만 재귀함수는 함수호출때문에 효율성은 떨어진다.
재귀적 이진탐색
입출력 예
L = [2, 3, 5, 6, 9, 11, 15]
x = 6
l = 0
u = 6
L[3] == 6 이므로 3 을 리턴해야 합니다.
또 다른 예로,
L = [2, 5, 7, 9, 11]
x = 4
l = 0
u = 4
리스트 L 내에 4 의 원소가 존재하지 않으므로 -1 을 리턴해야 합니다. 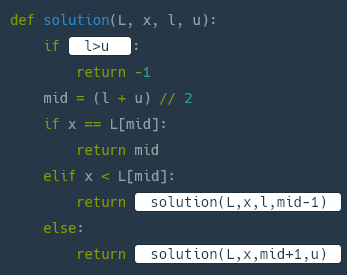
if x not in L로 했다가 효율성 검사에서 다 실패했다.
이 코드는 L을 다 돌아야해서 절반씩 삭제해 탐색하는 이진탐색의 장점을 없앤다. x가 L에 없는 경우는 low가 up보다 커지는 경우이므로 l > u
🔨알고리즘의 복잡도 (Comlexity of Algorithms)
얼마나 오래걸리느냐가 아닌 문제를 푸는데 얼마만큼의 자원을 요구하냐이다.
- 시간 복잡도 (Time Comlexity)
문제의 크기와 이를 해결하는 데 걸리는 시간 사이의 관계
- 평균 시간 복잡도 (Average Time Comlexity)
임의의 입력 패턴을 가정했을 때 소요되는 시간의 평균 - 최악 시간 복잡도(Worst-cast Time Comlexity)
가장 긴 시간을 소요하게 만드는 입력에 따라 소요되는 시간
- 공간 복잡도 (Space Comlexity)
문제의 크기와 이를 해결하는 데 필요한 메모리 공간 사이의 관계
🔫Big-O Notation
점근 표기법(asymptotic notation)의 하나로 어떤 함수의 증가 양상을 다른 함수와의 비교로 표현(알고리즘의 복잡도를 표현할 때 흔히 쓰임)
입력의 크기가 n일 때,
O(logn) - 입력의 크기의 로그에 비례하는 시간 소요
O(n) - 입력의 크기에 비례하는 시간 소요
계수는 그다지 중요하지 않음
- 선형 시간 알고리즘 - O(n)
ex) n개의 무작위로 나열된 수에서 최댓값을 찾기 위해 선형 탐색 알고리즘 적용 - 로그 시간 알고리즘 - O(logn)
ex) n개의 크기 순으로 정렬된 수에서 특정 값을 찾기 위해 이진 탐색 알고리즘 적용 - 이차 시간 알고리즘 - O(n2)
ex) 삽입 정렬(insertion sort)
Best case : O(n)
Worst case : O(n2)
✨보다 나은(낮은) 복잡도를 가지는 정렬 알고리즘
-
병합 정렬(merge sort) - O(nlogn)
정렬할 데이터를 반씩 나누어 각각을 정렬시킨다.
추상적 자료구조(Abstract Data Structures)
내부구현은 숨겨두고 밖에서 보이는 것들만 제공하는 것
-
Data
ex) 정수, 문자열, 레코드, ... -
A set of operations (일련의 연산들)
ex) 삽입, 삭제, 순회, ...
ex) 정렬, 탐색, ...
🔪연결 리스트 (Linked Lists)
- 연산 정의
- 특정 원소 참조(k번째)
- 리스트 순회
- 길이 얻어내기
- 원소 삽입
- 원소 삭제
- 두 리스트 합치기
각 원소들을 줄줄이 엮어서 관리하는 방식이다.
원소들이 링크 (link) 라고 부르는 고리로 연결되어 있어, 가운데에서 끊어 하나를 삭제하거나, 가운데를 끊고 그 자리에 다른 원소를 (원소들을) 삽입하는 것이 선형 배열보다 빠르다.
원소의 삽입/삭제가 빈번히 일어나는 응용에서는 연결 리스트가 많이 이용된다.
단점
1. 구조 표현에 소요되는 저장 공간 (메모리) 소요가 크다.
2. k 번째의 원소 를 찾아가는 데 시간이 오래 걸린다.
선형 배열에서는 데이터 원소들이 번호가 붙여진 칸들에 들어 있으므로 그 번호를 이용하면 되지만, 연결 리스트에서는 원소들이 고리로 연결되어 있으므로 특정 번째의 원소를 접근하려면 앞에서부터 하나씩 링크를 따라가야한다.
저장공간 : 임의의 위치
특정 원소 지칭 : 매우 간편 O(n)
연결리스트 원소 삽입
def insertAt(self, pos, newNode):
pos는 newNode가 들어갈 위치로 (1 <= pos <= nodeCount +1)이다.
- newNode의 뒷 쪽 link를 조정하고 (prev.next값을 newNode의 next link가 가리킨다.)
- 앞선 노드prev (pos-1)의 노드가 newNode를 가리키게 하고(prev.next가 newNode를 가리킨다.)
- nodeCount를 +1 해준다.
1,2과정의 순서를 바꿀 수 는 없다. prev.next의 값을 newNode로 먼저 바꿔버리면 원래 지정되어있던 값이 사라져서 newNode의 next값을 지정할 수 없기 때문이다.def insertAt(self, pos, newNode): prev = self.getAt(pos-1) newNode.next = prev.next prev.next = newNode self.nodeCount +=1
💡 주의 사항
-
삽입하려는 위치가 맨 앞일 때
prev없음, head 조정 필요 -
삽입하려는 위치가 맨 끝일 때(맨 앞에서 굳이 pos로 다 찾아갈 필요 없다. prev를 tail로 잡고 삽입하면 된다.)
Tail 조정 필요 -
빈 리스트에 삽입할 때
위 두 조건을 잘 처리하면 된다.
💡 연결 리스트 원소 삽입의 복잡도맨 앞에 삽입하는 경우 : O(1)
중간에 삽입하는 경우 : O(n)
맨 끝에 삽입하는 경우 : O(1)
연결리스트 원소 삭제
def popAt(self, pos):
pos가 가리키는 위치의 (1 <= pos <= nodeCount)
-
prev.next를 curr.next로 조정한다.(prev는 pos-1 curr는 pos)
-
curr(삭제값)의 data를 꺼내 리턴
-
nodeCount -= 1
💡 주의 사항
-
삭제하려는 node가 맨 앞의 것일 때
prev없음, head 조정 필요 -
삭제하려는 node가 맨 끝의 것일 때(tail을 가지고 tail 앞의 노드(prev)를 찾아낼 수 없어 처음부터 찾아와야함)
Tail 조정 필요 -
유일한 노드를 삭제할 때
-> 위 두 조건에 의해 처리되는가?!
💡 연결 리스트 원소 삭제의 복잡도맨 앞에서 삭제하는 경우 : O(1)
중간에서 삭제하는 경우 : O(n)
맨 끝에서 삭제하는 경우 : O(n)
두 리스트의 연결
def concat(self, L):
연결 리스트 self의 뒤에 또다른 연결 리스트 L을 이어 붙임
- L1.concat(L2)
- self.tail.next = L2.head # 첫번째 리스트의 tail이 두번째 리스트의 head를 가리킨다.
- self.tail = L2.tail # tail을 변경시킨다.
💉연결 리스트의 장점 살리기 (삽입과 삭제를 더 유연하게)
어떤 노드를 주고 그 뒤에 삽입,삭제 하는 방식의 메서드 생성
insertAfter(prev, newNode)
popAfter(prev)
-> 맨 앞에 삽입, 삭제할 경우를 위해 맨 앞에 dummy node를 추가한 형태로 연결 리스트를 조금 변형 시킨다. 연결리스트가 0부터 시작한다.
변형된 연결리스트 원소 삽입
def insertAfter(self, prev, newNode):
- newNode의 next는 현재 prev의 next
newNode.next = prev.next - prev가 tail이라면(제일 끝에 삽입할 경우) self.tail을 newNode로 옮긴다.
if prev.next is None:
self.tail = newNode - prev의 next는 newNode
prev.next = newNode - nodeCount를 1만큼 증가시키고 True 리턴
self.nodeCount += 1
return True
-
insertAt의 구현 : 이미 구현한 insertAfter()을 호출해 이용한다.
def insertAt(self, pos, newNode):
- pos 범위 조건 확인
- pos == 1 인 경우에는 head 뒤에 새 node 삽입
- pos == nodeCount +1인 경우는 prev를 tail로
- 그렇지 않은 경우에는 prev는 getAt(~)
변형된 연결리스트 원소 삭제
def popAfter(self, prev):
prev 의 다음 node를 삭제하고 그 node의 data를 리턴
💡 주의사항
- prev가 마지막 node일 때 (prev.next == None)
삭제할 node 없음
return None - 리스트 맨 끝의 node를 삭제할 때 (curr.next == None)
Tail 조정 필요
변형된 연결리스트 연결
첫번째 리스트의 tail을 두번째 리스트의 더미노드 뒷 노드에 이어줘야한다.
- self.tail.next = L2.head.next
원래 리스트의 tail을 옮긴다 - self.tail = L2.tail
