
JOIN
JOIN(조인)은 두 개의 테이블을 서로 묶어서 하나의 결과를 만들어 내는 것을 말한다
- INNER JOIN(내부 조인)은 두 테이블을 조인할 때, 두 테이블에 모두 지정한 열의 데이터가 있어야 한다
- OUTER JOIN(외부 조인)은 두 테이블을 조인할 때, 1개의 테이블에만 데이터가 있어도 결과가 나온다
- CROSS JOIN(상호 조인)은 한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인하는 기능이다
- SELF JOIN(자체 조인)은 자신이 자신과 조인한다는 의미로, 1개의 테이블을 사용한다
📌 INNER JOIN(내부 조인)
두 테이블을 연결할 때 가장 많이 사용하는 것이 INNER JOIN(내부 조인)이다
INNER JOIN을 JOIN이라고만 써도 INNER JOIN으로 인식한다
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인될 조건>
[WHERE 검색 조건]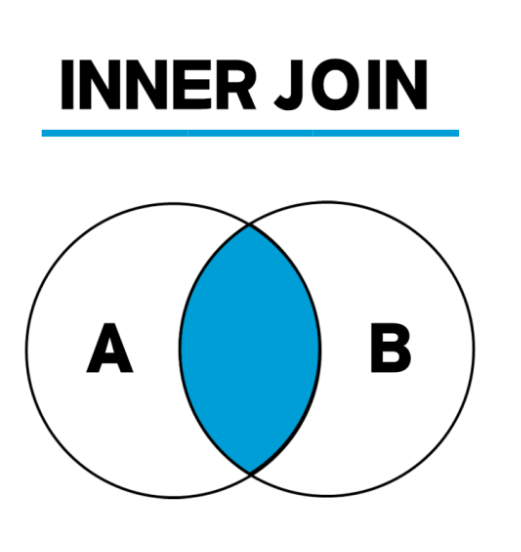
📌 OUTER JOIN(외부 조인)
INNER JOIN(내부 조인)은 두 테이블에 모두 데이터가 있어야만 결과가 나오지만,
OUTER JOIN(외부 조인)은 한쪽에만 데이터가 있어도 결과가 나온다🕹️ OUTER JOIN(외부 조인)의 종류
- LEFT OUTER JOIN : 왼쪽 테이블의 모든 값이 출력되는 조인
- RIGHT OUTER JOIN : 오른쪽 테이블의 모든 값이 출력되는 조인
- FULL OUTER JOIN : 왼쪽 또는 오른쪽 테이블의 모든 값이 출력되는 조인
SELECT <열 목록>
FROM <첫 번째 테이블(LEFT 테이블)>
<LEFT | RIGHT | FULL> OUTER JOIN <두 번째 테이블(RIGHT 테이블)>
ON <조인될 조건>
[WHERE 검색 조건]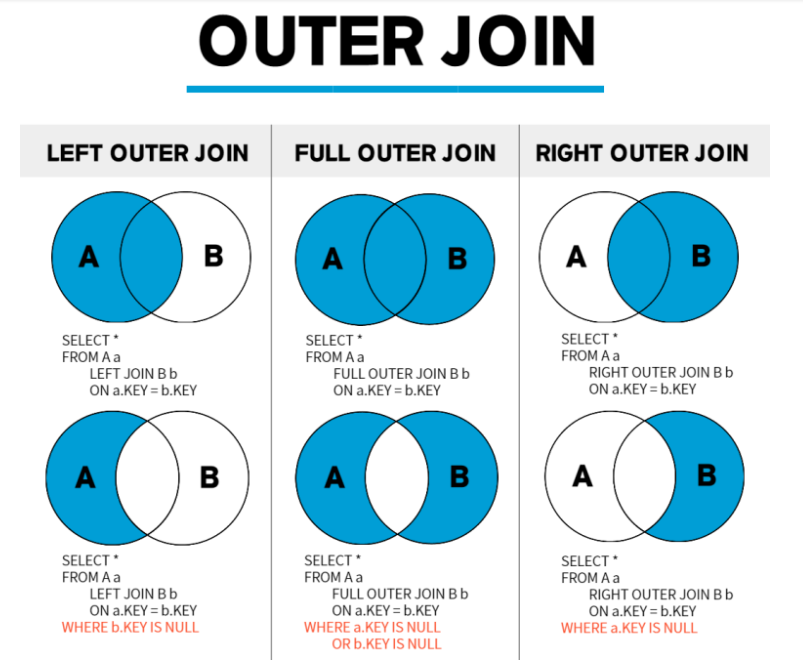
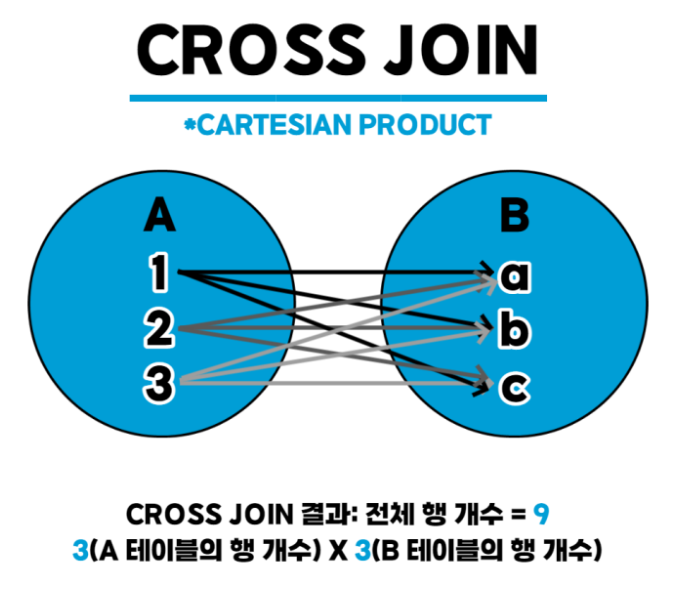
📌 CROSS JOIN(상호 조인)
카티션 곱(CARTESIAN PRODUCT)이라고도 하며,
한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시키는 기능이다
상호 조인 결과의 전체 행 개수는 두 테이블의 각 행의 개수를 곱한 수만큼 이다
SELECT *
FROM <첫 번째 테이블>
CROSS JOIN <두 번째 테이블>
📌 SELF JOIN(자체 조인)
자체 조인은 자기 자신과 조인하므로 1개의 테이블을 사용합니다.
별도의 문법이 있는 것은 아니고 1개로 조인하면 자체 조인이 됩니다.
SELECT <열 목록>
FROM <테이블> 별칭A
INNER JOIN <테이블> 별칭B
ON <조인될 조건>
[WHERE 검색 조건]
📋 JOIN 실습
SELECT C.* FROM CLASSTBL C;
SELECT S.* FROM STUDENTTBL S;INNER JOIN = 교집합
SELECT C.*, S.* FROM CLASSTBL C, STUDENTTBL S
WHERE C.CLSCODE=S.STDCLASS;[ANSI 표준 SQL] INNER JOIN
SELECT C.CLSCODE, C.CLSNAME, S.STDNO, S.STDNAME
FROM CLASSTBL C
INNER JOIN STUDENTTBL S ON C.CLSCODE=S.STDCLASS;RIGHT OUTER JOIN
SELECT S.*, C.* FROM STUDENTTBL S, CLASSTBL C
WHERE C.CLSCODE=S.STDCLASS(+);
SELECT S.*, C.* FROM STUDENTTBL S RIGHT OUTER JOIN CLASSTBL C
ON C.CLSCODE=S.STDCLASS;LEFT OUTER JOIN == INNER JOIN
SELECT S.*, C.* FROM STUDENTTBL S, CLASSTBL C
WHERE C.CLSCODE(+)=S.STDCLASS;
SELECT S.*, C.* FROM STUDENTTBL S LEFT OUTER JOIN CLASSTBL C
ON C.CLSCODE=S.STDCLASS;[ANSI 표준 SQL] FULL OUTER JOIN == RIGHT OUTER JOIN
SELECT S.*, C.* FROM STUDENTTBL S, CLASSTBL C
WHERE C.CLSCODE(+)=S.STDCLASS(+); -- 동작안됨
SELECT S.*, C.* FROM STUDENTTBL S FULL OUTER JOIN CLASSTBL C
ON C.CLSCODE=S.STDCLASS; --ANSI 표준📋 JOIN 실습
[실습1] 여러테이블 간 INNER JOIN
SELECT M.* FROM MEMBERTBL M;
SELECT I.* FROM ITEMTBL I;
SELECT O.* FROM ORDERTBL O;
-- 주문번호용 시퀀스 생성 SEQ_ORDER_NO 10001
CREATE SEQUENCE SEQ_ORDER_NO START WITH 10001
INCREMENT BY 1 NOMAXVALUE NOCACHE;
-- 제약조건 기본키=시퀀스, 외래키 2개의 제약조건
INSERT INTO ORDERTBL VALUES(SEQ_ORDER_NO.NEXTVAL, 500, 1001, 'c', CURRENT_DATE);
COMMIT;
-- INNER JOIN ORDERTBL + ITEMTBL
SELECT
O.NO, O.CNT, O.ITEMNO, O.USERID,
I.NAME, I.PRICE
FROM
ORDERTBL O
INNER JOIN
ITEMTBL I
ON
O.ITEMNO = I.NO;
-- INNER JOIN (ORDERTBL+ITEMTBL) + MEMBERTBL
SELECT OI.*, M.AGE, M.PHONE, M.GENDER FROM (
SELECT
O.NO, O.CNT, O.ITEMNO, O.USERID,
I.NAME, I.PRICE
FROM
ORDERTBL O
INNER JOIN
ITEMTBL I
ON
O.ITEMNO = I.NO
) OI INNER JOIN MEMBERTBL M ON OI.USERID = M.USERID;
-- view 에서 사용할 ORDER_ITEM_MEMBER_VIEW 생성
CREATE OR REPLACE VIEW ORDER_ITEM_MEMBER_VIEW AS
SELECT OI.*, M.AGE, M.PHONE, M.GENDER FROM (
SELECT
O.NO, O.CNT, O.ITEMNO, O.USERID, O.REGDATE,
I.NAME, I.PRICE
FROM
ORDERTBL O
INNER JOIN
ITEMTBL I
ON
O.ITEMNO=I.NO
) OI INNER JOIN MEMBERTBL M ON OI.USERID = M.USERID;
SELECT OV.* FROM ORDER_ITEM_MEMBER_VIEW OV;[실습2] 물품별 번호 부여
전체에 대해 번호 부여
SELECT
ROW_NUMBER() OVER (ORDER BY OV.NO DESC) ROWN,
OV.*
FROM ORDER_ITEM_MEMBER_VIEW OV;물품별 번호 부여(번호 : ROW_NUMBER() 순위 : RANK() )
SELECT
ROW_NUMBER() OVER (PARTITION BY OV.ITEMNO ORDER BY OV.NO DESC) ROWN,
OV.*
FROM ORDER_ITEM_MEMBER_VIEW OV;--===여기부터 수업====
페이지 네이션
Oracle은 LIMIT이 없기 때문에 수동으로 구한다
SELECT T1.* FROM(
SELECT
ROW_NUMBER() OVER (ORDER BY OV.NO DESC) ROWN,
OV.*
FROM ORDER_ITEM_MEMBER_VIEW OV
) T1
WHERE T1.ROWN BETWEEN 1 AND 3;📕 CASE = IF문
- 주문수량이 0 부터 100사이인 경우 A 등급
- 주문수량이 101 부터 200 B 등급
- 주문수량 201 이상이면 C 등급
SELECT
CASE
WHEN(OV.CNT >= 0 AND OV.CNT<=100) THEN 'A등급'
WHEN(OV.CNT >= 101 AND OV.CNT<=200) THEN 'B등급'
WHEN(OV.CNT >= 201) THEN 'C등급'
END GRADE,
OV.*
FROM ORDER_ITEM_MEMBER_VIEW OV;📕 인덱스 생성
인덱스 생성 IDX_ITEM_NAME ON 테이블명(컬럼명);- 인덱스 생성시 검색속도를 향상시켜줌
- 기본키는 인덱스를 자동설정함
CREATE INDEX IDX_ITEM_NAME ON ITEMTBL(NAME);
📋 실습
-- 부서 생성
SELECT D.* FROM DEPT D;
INSERT INTO DEPT VALUES(101, '총무부', CURRENT_DATE, '서울');
INSERT INTO DEPT VALUES(102, '영업부', CURRENT_DATE, '부산');
INSERT INTO DEPT VALUES(103, '기획부', CURRENT_DATE, '대구');
INSERT INTO DEPT VALUES(104, '홍보부', CURRENT_DATE, '서울');
COMMIT;
-- 시퀀스 생성하기
CREATE SEQUENCE SEQ_EMP_NO START WITH 10001 INCREMENT BY 2 NOMAXVALUE NOCACHE;
-- 사원 데이터 있는경우 전부 지우고 하기
DELETE FROM EMPLOYEE;
COMMIT;
--사원 10명입력하기
SELECT E.* FROM EMPLOYEE E;
INSERT INTO EMPLOYEE
VALUES(SEQ_EMP_NO.NEXTVAL, '가나다7', 101, 2750000, CURRENT_DATE, '대리');
INSERT INTO EMPLOYEE
VALUES(SEQ_EMP_NO.NEXTVAL, '가나다8', 102, 2400000, CURRENT_DATE, '대리');
INSERT INTO EMPLOYEE
VALUES(SEQ_EMP_NO.NEXTVAL, '가나다9', 103, 3200000, CURRENT_DATE, '과장');
INSERT INTO EMPLOYEE
VALUES(SEQ_EMP_NO.NEXTVAL, '가나다10', 104, 3250000, CURRENT_DATE, '대리');
INSERT INTO EMPLOYEE
VALUES(SEQ_EMP_NO.NEXTVAL, '가나다11', 102, 4550000, CURRENT_DATE, '대리');
INSERT INTO EMPLOYEE
VALUES(SEQ_EMP_NO.NEXTVAL, '가나다12', 101, 3100000, CURRENT_DATE, '사원');
COMMIT;[실습1] DEPT의 영업부를 "대전" 나머지는 "부산"으로 변경
UPDATE DEPT SET AREA = '대전' WHERE NAME = '영업부';
SELECT D.* FROM DEPT D;
COMMIT;
UPDATE DEPT SET AREA = '부산' WHERE AREA != '대전';
SELECT D.* FROM DEPT D;
COMMIT;다른 풀이
➡️ 한번에 데이터 변경하는 방법
- [풀이1] IF문 역할을 하는 CASE 이용
UPDATE DEPT03 SET AREA = CASE WHEN (DEPTNO=102) THEN '대구' ELSE '부산' END; COMMIT;
- [풀이2] 두번에 나눠 데이터 변경
UPDATE DEPT SET AREA='대구' WHERE DEPTNO=102; UPDATE DEPT SET AREA='부산' WHERE DEPTNO<>102; --WHERE DEPTNO=101 OR .. COMMIT;
[실습2] 항목 삭제
EMPLOYEE의 부서번호가 103인 항목 삭제
DELETE FROM EMPLOYEE WHERE DEPTNO = 103;
SELECT E.* FROM EMPLOYEE E;
ROLLBACK;[실습3] 데이터 조건부 변경
EMPLOYEE의 영업부 직원102과 총무부 직원101의 이름, 급여, 직급을 사원번호 순으로 내림차순으로 출력
SELECT
E.EMPNO, E.NAME, E.PAY, E.POSITION
FROM
EMPLOYEE E
ORDER BY
EMPNO DESC;다른 풀이
DEPT와 합쳐서 부서명까지도 출력이 가능하다
SELECT E.DEPTNO, E.NAME, E.PAY, E.POSITION FROM EMPLOYEE E WHERE E.DEPTNO IN(101,102);
--SELECT * FROM 테이블1 INNER JOIN(테이블)2 ON 조인조건
SELECT D.*, E.* FROM DEPT D
INNER JOIN(
SELECT E.DEPTNO, E.NAME, E.PAY, E.POSITION FROM EMPLOYEE E WHERE E.DEPTNO IN(101,102)
) E
ON D.DEPTNO=E.DEPTNO; [실습4] 데이터 조건부 조회 + 새 항목 생성
EMPLOYEE의 급여에서 0~230 이면 5%, 231~300이면 10%, 301~400 15%, 400이상은 20%의 세금을 조회(사원번호, 사원명, 급여, 세금 출력) ➡️ CASE사용
풀이
SELECT E.EMPNO, E.NAME, E.PAY,
CASE
WHEN(E.PAY >= 0 AND E.PAY<=2300000) THEN E.PAY*0.05
WHEN(E.PAY >= 2310000 AND E.PAY<=3000000) THEN E.PAY*0.1
WHEN(E.PAY >= 3010000 AND E.PAY<=4000000) THEN E.PAY*0.15
WHEN(E.PAY >= 4010000) THEN E.PAY*0.2
END TAX
FROM EMPLOYEE E;[실습5] AVG, GROUP BY 사용한 조건부 조회
EMPLOYEE의 부서별 평균 급여와 인원수 출력 GROUP BY사용
- 스프링에서는 한글로 변수 사용 불가! 영어로 써주는게 좋다
풀이
SELECT E.DEPTNO 부서번호, AVG(E.PAY) 평균급여, COUNT(*) 인원수 FROM EMPLOYEE E GROUP BY E.DEPTNO;[실습6] HAVING 사용한 조건부 조회
EMPLOYEE의 부서별 급여 평균이 250이상인 급여 조회(부서번호, 부서명, 급여 평균 출력)
- 부서번호를 기준으로 그룹화 하고 HAVING사용하여 조건을 준다
➡️ 부서명은 다른 테이블에 있기 때문에 이 결과를 기준으로 다시 조회
SELECT E.DEPTNO 부서번호, AVG(E.PAY) 평균급여 FROM EMPLOYEE E GROUP BY E.DEPTNO HAVING AVG(E.PAY)>=3000000;
SELECT D.* , E.* FROM DEPT D INNER JOIN (
SELECT E.DEPTNO, AVG(E.PAY) 평균급여 FROM EMPLOYEE E GROUP BY E.DEPTNO HAVING AVG(E.PAY)>=3000000
) E
ON D.DEPTNO = E.DEPTNO;[실습7] SUM, AVG를 사용한 조건부 조회
직급별 총급여, 평균급여, 인원수 출력
SELECT E.POSITION 직급, SUM(E.PAY)총급여, AVG(E.PAY) 평균급여, COUNT(*) 인원수 FROM EMPLOYEE E GROUP BY E.POSITION;[실습8] PARTITION, RANK() 이용하여 조회
직급별 급여가 높은 순으로 rank()출력
➡️ 파티션으로 포지션별 정렬하고 급여 높은순 정렬
SELECT
RANK() OVER (PARTITION BY E.POSITION ORDER BY E.PAY DESC) RNK,
E.*
FROM EMPLOYEE E;PL/SQL
- 일반 프로그래밍 언어 요소를 다 갖고 있으며, 데이터베이스 업무를 처리하기 위한 최적화된 언어
- BLOCK 구조로 다수의 SQL 문을 한번에 처리하므로 수행 속도가 빠르다
- PL/SQL 프로그램의 종류는 크게 Procedure, Function, Trigger 로 나뉘어 진다
📌 Procedure
Procedure(프로시저) : 자주 실행해야하는 특정 작업을 필요할 때 호출하기 위해 절차적인 언어를 이용하여 작성한 이름이 있는 프로그램 모듈(Block)을 의미한다! 하나의 프로그램과 같다
➡️ 여러명의 데이터를 추가할때 양이 많으면 프로시저 이용하면 한번에 가능하다
- 반환값이(return)이 없다 = 이게 함수와의 차이점
CREATE [OR REPLACE] PRODUCE "Produce_name"(argument1[MODE]data_type1, argument2[MODE]data_type2, ... ...) IS[AS] ... BEGIN ... EXCEPTION ... END; /
- CREATE : 구문을 이용하여 생성한다
- OR REPLACE : 같은 프로시저가 있을 때, 기존의 프로시저를 무시하고 새로운 내용으로 덮어쓰겠다는 의미이다
- MODE : 매개변수의 역할을 결정하는 자리이다. MODE에 들어갈 수 있는 변수는
IN,OUT,INOUT이 있다
- IN : 운영체제에서 프로시저로 전달될 변수의 모드
- OUT : 프로시저에서 처리된 결과가 운영체제로 전달
- INOUT : IN과 OUT, 두가지 기능 모두 수행
- IS : PL/SQL의 Block을 시작한다는 의미이며, 프로시저 내(BEGIN 뒤에 나올 SQL문)에서 사용될 변수를 선언하는 곳이다. LOACL변수는 IS와 BEGIN사이에 선언해서 사용한다
- EXCEPTION : BEGIN~END 사이에서 실행되는 SQL문 실행도중 발생한 에러를 처리하는 예외처리
- END : 실행문의 종료를 의미한다
- / : END; 뒤에 위치하는 슬래시(/)는 데이터베이스에게 프로시저를 컴파일 하라는 명령
- DECLARE :
DECLARE 변수명 변수타입 DEFAULT(기본값 설정)= 자바에서 쓰는 변수처럼 프로시저 안에서 사용할 변수를 선언
Oracle의 스크립트 출력창
= 콘솔(Console)창과 같다
SET SERVEROUTPUT ON;문자열 출력
DBMS_OUTPUT.PUT_LINE()이용하며 괄호안에 메세지를 입력한다
= System.out.print()와 같다
DBMS_OUTPUT.PUT_LINE('hello');
SET SERVEROUTPUT ON;
-- system.out.print("hello");
BEGIN
DBMS_OUTPUT.PUT_LINE('hello');
END;
/변수 생성 후 출력
숫자형 변수와 문자형 변수 출력하기
- PL/SQL의 대입연산자는
:=이다 (↔ T-SQL은 대입연산자가=이다)
DECLARE
--문자형 변수 정의!
V_STR VARCHAR2(30) := 'asdf';
--숫자형 변수 정의! 초기값 13
V_NUM NUMBER := 13;
BEGIN
DBMS_OUTPUT.PUT_LINE('STR =>' || V_STR);
DBMS_OUTPUT.PUT_LINE('NUM =>' || V_NUM);
END;
/IF문 사용하기
PL/SQL에서 IF~ELSE 사용시 IF~ELSEIF 로 작성해준다
DECLARE
V_STR VARCHAR2(2);
V_NUM NUMBER := 90;
BEGIN
IF V_NUM >=90 THEN
V_STR := 'A';
ELSIF V_NUM >=80 THEN
V_STR := 'B';
ELSIF V_NUM >=70 THEN
V_STR := 'C';
ELSE
V_STR := 'D';
END IF;
DBMS_OUTPUT.PUT_LINE('등급은 =>' || V_STR);
END;
/FOR문 사용하기
DECLARE
V_NUM NUMBER := 4;
BEGIN
FOR i IN 1..V_NUM LOOP
DBMS_OUTPUT.PUT_LINE('반복숫자 =>' || i);
END LOOP;
END;
/📋 실습
[실습1] 외부입력 받아 프로시저 실행
외부에서 점수 입력시 등급 출력
➡️ 외부에서 들어가는 값을 받기 위해IN을 사용한다
사용할 변수가 없으니DECLARE대신IS(프로시저 BLOCK시작)가 들어감
CREATE OR REPLACE PROCEDURE PROC_GRADE(
V_NUM IN NUMBER -- IN은 외부에서 들어가는 값
)
IS
V_NUM1 NUMBER := 5;
BEGIN
DBMS_OUTPUT.PUT_LINE('합은 =>' || (V_NUM+V_NUM1));
END;
/
EXEC PROC_GRADE(50); -- 테스트용! SPRING BOOT 에서 호출해야함
/[실습2] 프로시저 실행
게시판에 글번호가 존재하는 경우 UPDATE를 수행하고,
게시판에 글번호가 존재하지 않는경우 INSERT를 수행하는 프로시저PROC_BOARD_UPSERT생성
- 프로시저는 리턴이 없어서 SPRING에서 프로시저 수행결과를 알 수 없다
➡️V_RET OUT NUMBER변수 추가하여 결과에 따른 변수 값을 설정한다
프로시저 수행 후 SPRING에서V_RET값을 확인하여 프로시저 수행결과를 알 수 있게 해준다
프로시저 생성
CREATE OR REPLACE PROCEDURE PROC_BOARD_UPSERT(
V_NO IN BOARDTBL.NO%TYPE, --NUMBER라고 쓴것과 같다(TYPE명시)
V_TITLE IN BOARDTBL.TITLE%TYPE, -- VARCHAR2(100)이라고 쓴것과 같다
V_CONTENT IN BOARDTBL.CONTENT%TYPE,
V_WRITER IN BOARDTBL.WRITER%TYPE,
V_RET OUT NUMBER
)
IS
V_CHK NUMBER(1) := 0; -- 존재유무 확인용
BEGIN
--먼저 입력한 수와 일치하는 개수 구하기
--SELECT COUNT(*) FROM BOARDTBL B WHERE B.NO = V_NO;
--위의 구한 개수에 INTO넣기
SELECT COUNT(*) INTO V_CHK
FROM BOARDTBL B WHERE B.NO = V_NO;
IF V_CHK > 0 THEN -- 0보다 크다면 = 있다
--수정
UPDATE BOARDTBL SET TITLE=V_TITLE, CONTENT=V_CONTENT,
WRITER=V_WRITER WHERE NO=V_NO;
V_RET :=1;
ELSE --없는경우
--등록
INSERT INTO BOARDTBL(NO, TITLE, WRITER, HIT, REGDATE, CONTENT)
VALUES(SEQ_BOARDTBL_NO.NEXTVAL, V_TITLE, V_WRITER, 1, CURRENT_DATE, V_CONTENT);
V_RET :=2;
END IF;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
V_RET :=0;
ROLLBACK;
END;
/프로시저 실행
프로시저 실행시 결과값 확인할
V_RET변수를 생성하여 출력
SELECT B.* FROM BOARDTBL B;
--프로시저에 결과값 확인할 V_RET 변수를 생성하여 BOARDTBL에 넣어 넘겨주기
DECLARE
V_RET NUMBER;
BEGIN
PROC_BOARD_UPSERT(5, 'proc제목', 'proc내용', 'proc작성자', V_RET);
DBMS_OUTPUT.PUT_LINE('OUT 변수 값은 =>'|| V_RET);
END;
/SPRING에서 프로시저 실행
프로시저는 return값이 없기 때문에 프로시저
PROC_BOARD_UPSERT에서 결과에 따라 담아준V_RET값을 꺼내어 확인한다
📁 BoardMapper.java
package com.example.mapper;
import java.util.Map;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.mapping.StatementType;
@Mapper
public interface BoardMapper {
// 프로시저는 insert
@Insert({
"{ call PROC_BOARD_UPSERT(",
"#{map.no, mode=IN, jdbcType=NUMERIC, javaType=Long }, ",
"#{map.title, mode=IN, jdbcType=VARCHAR, javaType=String }, ",
"#{map.content, mode=IN, jdbcType=VARCHAR, javaType=String }, ",
"#{map.writer, mode=IN, jdbcType=VARCHAR, javaType=String }, ",
"#{map.ret, mode=OUT, jdbcType=NUMERIC, javaType=Integer }",
")}"
})
@Options(statementType = StatementType.CALLABLE)
public void callProcedure(@Param("map") Map<String, Object> map);
}📁 test / ProcedureTest.java
ret= 0(오류), 1(수정), 2(등록)
➡️log.info(map.toString();에서 프로시저 수행 후 결과값이 담겨있는 ret값을 꺼내어 확인한다
...
@SpringBootTest
@Slf4j
public class ProcedureTest {
final String format = "BOARDTBL => {}";
@Autowired
BoardMapper bMapper;
@Test
void contextLoads() {
log.info(format, "PROC TEST");
Map<String, Object> map = new HashMap<>();
map.put("no", 1111L);
map.put("title", "제목");
map.put("content", "내용");
map.put("writer", "작성자");
map.put("ret", 0);
bMapper.callProcedure( map );// =>여기서 프로시저 호출 후
// ret값을 확인한다
log.info(format, map.get("ret").toString());
// return 안하기 때문에 담겨있는 값을 꺼내어 확인한다
}
}