해당 글은 제가 커먼컴퓨터에서 재직 중에 작성한 글이며 회사 공식 블로그에도 올라오고 있습니다.
안녕하세요 이번에 알아볼 모델은 Kevin-Yang님의 UCK-GPT2입니다.
Kevin-Yang님은 카카오엔터프라이즈 번역기술파트에서 카카오i 번역을 개발하고 계신데요. 대학연합 머신러닝 동아리인 DeepUser 등에서 많은 활동을 하고 계십니다. Kevin-Yang님께서 이번에 공개해주신 UCK-GPT2는 SKT-AI에서 공개한 KoGPT2 모델을 대학교 커뮤니티의 글로 fine-tuning하여 대학 커뮤니티 게시글을 생성하는 모델입니다.
프로젝트를 바로 확인해 보시고 싶으신 분은 다음 링크를 참조해 주세요!
Github: https://github.com/jason9693/UCK-GPT2
DEMO: https://master-gpt2-everytime-fpem123.endpoint.ainize.ai/
API: https://ainize.ai/fpem123/gpt2-everytime
Colab: https://colab.research.google.com/drive/1HUWYNCKZuH_RUuCP4HPoJvihAeH7V4k_?usp=sharing
IT 기술의 발달로 인해 이전보다 인터넷의 접근성이 매우 높아진 요즘, 공통의 관심사를 가진 사람들이 모여 온라인 커뮤니티를 만들고 그 안에서 공통의 관심사에 대한 경험을 공유하고 토론하며 소통의 창으로 이용합니다. 이러한 공통의 관심사로 모델을 학습하여 글을 생성한다면 어떤 결과물이 나올까요?
커뮤니티 데이터의 특징
대부분의 언어모델 학습에 사용된 데이터들은 뉴스 기사, 백과사전과 같이 잘 정제되어있는 데이터들입니다. 하지만 대부분의 커뮤니티에서 사용되는 언어는 구어체 특징의 신조어가 많으며 오타, URL, 개행 문자 등의 특수한 텍스트가 등장한다는 특징이 있습니다. 따라서 모델을 학습할 때는 커뮤니티 데이터의 특성에 맞게 모델을 학습해야 합니다.
처음보는 단어를 어떻게 처리하지? Subword Tokenization
텍스트를 NLP에서 활용하기 위해서는 토큰화라는 과정이 필요합니다. 여기서 토큰화란 텍스트에서 문법적으로 더 이상 나눌 수 없는 단위인 토큰으로 분리하는 작업을 말합니다. 과거에는 POS tagging과 같은 토큰화 방법들이 사용되었습니다. 하지만 이런 토큰화 방식은 등장하는 빈도가 낮은 단어나, 처음 등장하는 단어를 처리하는 부분에서 모델에 Unknown Token이 들어가게 되어 모델의 성능이 낮아지는 것을 유발합니다. 따라서 이런 문제를 해결하기 위해 나온 방식이 Subword Tokenization입니다.
Subword Tokenization는 단어 자체를 토큰화하는 것이 아닌 복합어를 여러개의 서브워드(Subword)로 분리하여 이전에 사용하던 토큰화 방법의 문제점을 보완합니다. 여기서 서브워드란 단어는 단순히 하나의 의미로 이루어져있는 것이 아닌 작은 의미로 구성되어있는데, 이 작은 의미의 단위를 말합니다. 예를 들어 subword는 sub와 word로 나눌 수 있습니다. BPE(Byte Piece Encoding), SPM(Sentence Piece Model)이 Subword Tokenization에 포함되는데, 이를 간단히 살펴보겠습니다.
- BPE(Byte Piece Encoding)
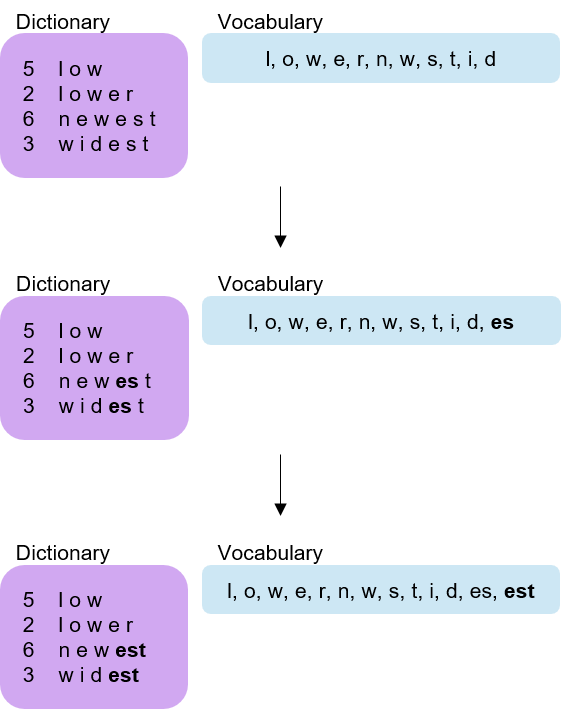
BPE의 핵심 내용은 등장하는 빈도수가 높고 이웃하는 2 byte를 1 byte로 치환하는 것입니다. 예를 들어 ababcabcd에서 빈도수가 가장 높은 ab를 x로 치환하게 되면 xxcxcd가 됩니다. 이후 빈도수가 2번째로 높은 xc를 y로 치환하여 xyyd를 얻습니다. 이 과정을 반복하는 것이 핵심 내용입니다.
이를 자연어 처리에서 사용하려면, 우선 단어들 글자 단위로 분리하여 딕셔너리에 넣어줍니다. 그 후 가장 빈도수가 높은 쌍을 딕셔너리에 추가해줍니다. 위의 경우에서는 ab를 딕셔너리에 추가하고, 이후 xc를 딕셔너리에 추가하면 됩니다. 이와 같은 과정을 반복하면 끝입니다. 자세한 내용은 여기에서 확인할 수 있습니다.
- SPM(Sentence Piece Model)
SPM은 Unigram Language Model과 BPE를 합친 기술입니다. Unigram Language Model은 학습시 문장에서 등장한 단어 빈도를 세고 전체 단어수로 나누어 문장에서 각 단어가 등장한 확률을 구합니다. 그 후 문장이 주어졌을 때, 학습할 때 구해둔 각 단어들의 등장 확률을 곱하여 이 단어들이 동시에 나타날 확률을 구합니다.
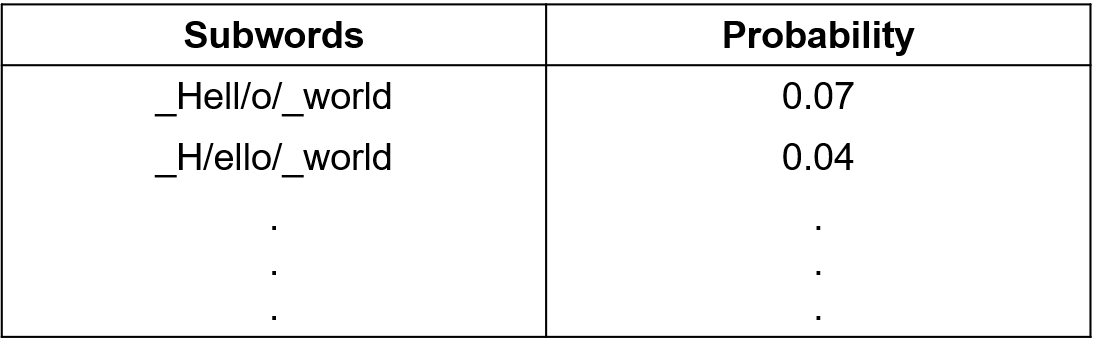
SPM은 입력 문장이 서브워드의 연속이라고 생각하고 시작합니다. 문장을 입력받으면 이 문장을 구성하는 서브단어들의 케이스는 매우 많을 것입니다. 이 케이스들을 각각 Unigram Language Model를 통해 등장 확률을 구한 후, 이 중 확률값이 가장 높은 케이스를 선택하면 끝입니다. 예를 들어, Hello world라는 문장이 있을 때 이를 서브워드들로 나눌 수 있는 방법은 많을 겁니다. 가령 _Hell/o/_world로 나눌 수 도있고 _H/ello/_world로 나눌 수도 있을 겁니다. 이와 같이 여러 케이스 중에서 가장 확률이 높은 서브워드들을 선택하는 것 입니다. 자세한 내용은 여기서 확인할 수 있습니다.
왜 영어 모델만 있고 한국어 모델은 없어? : KoGPT2
대학 커뮤니티 게시글을 생성하는 모델인 UCK-GPT2은 KoGPT2 모델을 파인튜닝한 모델입니다. 먼저 KoGPT2에 대해 설명해보겠습니다. KoGPT2는 이름에서 볼 수 있는 거처럼 GPT-2 모델을 파인튜닝한 한국어 언어모델이며 SKT-AI에서 한국어성능 한계 개선을 위해 개발하였습니다. 학습에 사용된 데이터로는 위키 문장 500만개, 뉴스 문장 1억2000만개, 기타 자료 문장 940만개로 총 20GB의 데이터를 학습에 사용하였습니다.
KoGPT2에서 사용된 토크나이저는 SPM입니다. 한글은 어미, 접사 등이 붙는 교착어의 형태이고, 단어들이 독립적인 단어로만 구성되어 있지 않기 때문에 한글 토큰화가 쉽지 않습니다. 따라서 효율적인 학습을 위해 한국어의 사전 토큰화가 필요했지만, 이는 전처리 과정을 복잡하게 만들었습니다. 하지만 SPM은 충분히 효율적이므로 사전토큰화를 수행할 필요가 없다고 합니다.
UCK-GPT2
UCK-GPT2는 University Community KoGPT2의 줄임말로 대학 커뮤니티 게시글을 생성하는 모델입니다. 학습을 할 때는 대학교 커뮤니티인 에브리타임, 캠퍼스픽 대나무숲 게시판, 캠퍼스픽 모두를 위한 연애 게시판 데이터 22만개를 이용하여 학습을 하였습니다. 학습할 때, 위에서 말한 커뮤니티 데이터의 특성을 고려하여 URL, LINK, 개행 문자를 무시하기 보단 문장의 어느 위치에 들어갈 것인가를 학습했다고 합니다. 해당 모델에서는 같은 문자를 입력하여도 선택한 커뮤니티에 따라 결과값이 다르게 나옵니다. 앞으로 소개할 사용법을 통해 각기 다른 커뮤니티의 성격을 느껴보세요!
나도 글을 써보자
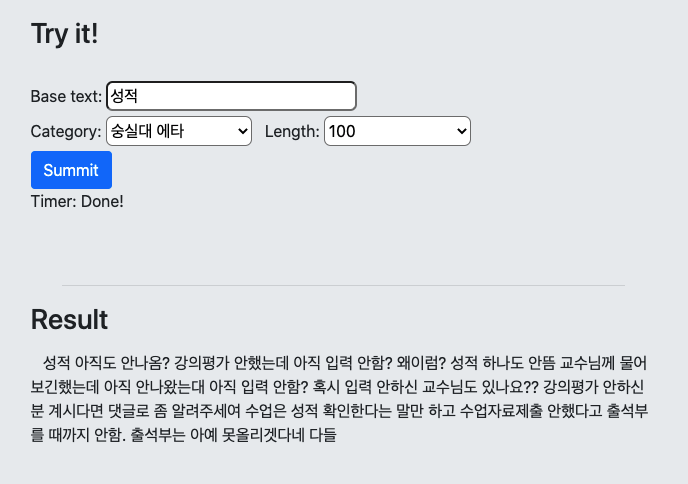
- Ainize의 UCK-GPT2 DEMO 사용하기
먼저 코드 작성없이 Ainize에서 제공하는 UCK-GPT2 DEMO를 사용해보겠습니다.
데모 페이지에 들어간 후, 원하는 문자와 카테고리를 입력하고 Summit 버튼을 누르면 결과값을 얻을 수 있습니다. 위에서 사용한 DEMO는 여기에서 사용할 수 있습니다.
- UCK-GPT2 불러와서 사용하기
이번에는 모델을 불러와 사용해보겠습니다. 커뮤니티 글 생성을 해보기 위해 우선 해당 모델을 불러옵니다. 그 다음 원하는 문자와 카테고리를 선택한 후 결과값을 생성하면 됩니다.
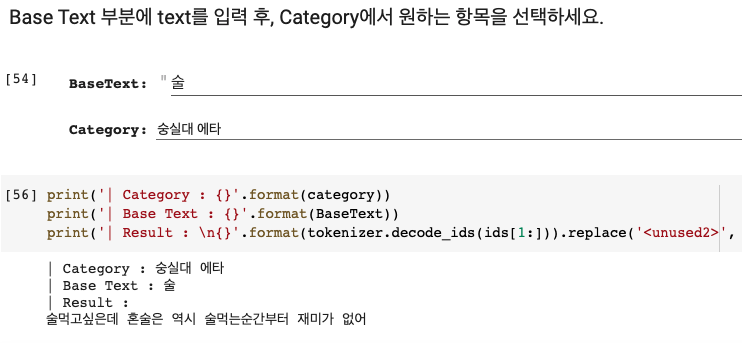
실행 환경은 colab으로 설정하였으며 여기에서 확인하실 수 있습니다.
- Ainize의 UCK-GPT2 API 사용하기
이번에는 Ainize에서 제공하는 UCK-GPT2 API를 사용하여 UCK-GPT2을 사용해보겠습니다. 해당 모델을 다른 서비스에서 활용하고 싶을 때는 이 방법을 사용하면 편할겁니다! UCK-GPT2의 API는 POST 메소드를 사용하며
curl -X POST "<https://master-gpt2-everytime-fpem123.endpoint.ainize.ai/everytime>"
-H "accept: application/json"
-H "Content-Type: multipart/form-data"
-F "text={입력할 단어}" -F "category={카테고리 종류}"
-F "length={원하는 결과물의 길이}"와 같은 방식으로 호출할 수 있습니다. 자세한 내용은 여기에서 확인할 수 있습니다.
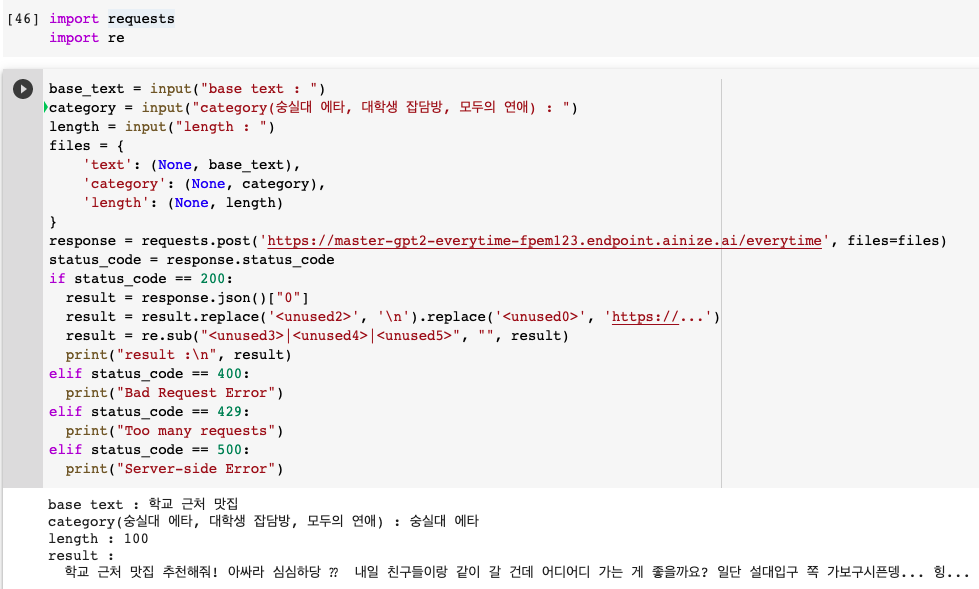
자세한 코드는 여기에서 확인할 수 있습니다.
커뮤니티의 데이터로 학습된 모델을 통해 결과값을 얻어보면 일정한 패턴을 찾을 수 있습니다. 바로 커뮤니티의 성향에 맞는 결과를 보여줬다는 점입니다. 이러한 특징을 살려 실제 서비스와 연동되면 좋을 거 같다는 생각이 드네요. 긴 글 읽어주셔서 감사합니다. 다음 시간에는 다른 모델로 찾아오겠습니다.
레퍼런스
- Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 12 — Subword Models
- A New Algorithm for Data Compression
- SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
- Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
- UCK-GPT2 Github
- UCK-GPT2 Ainize
AI 네트워크는 블록체인 기반 플랫폼으로 인공지능 개발 환경의 혁신을 목표로 하고 있습니다. 수백만 개의 오픈 소스 프로젝트가 라이브로 구현되는 글로벌 백엔드 인프라를 표방합니다.
최신 소식이 궁금하시다면 아래 커뮤니케이션 채널을 참고해주시기 바랍니다. 다시 한 번 감사합니다.
AI네트워크 공식 홈페이지: https://ainetwork.ai/
공식 텔레그램: https://t.me/ainetwork_kr
아이나이즈(Ainize): https://ainize.ai
유튜브: https://www.youtube.com/channel/UCnyBeZ5iEdlKrAcfNbZ-wog
페이스북:https://www.facebook.com/ainetworkofficial/
포럼:https://forum.ainetwork.ai/
AIN Price chart: https://coinmarketcap.com/currencies/ai-network/onchain-analysis/
![]()

👍🏻👍🏻👍🏻👍🏻👍🏻