
해당 글은 제가 커먼컴퓨터에서 재직 중에 작성한 글이며 회사 공식 블로그에도 올라오고 있습니다.
안녕하세요. 오픈소스로 배포된 AI 모델을 찾아 떠나는 모험에 참여하신 걸 축하드립니다! 제가 처음으로 소개드릴 AI 모델은 hyunwoongko님의 openchat입니다.
hyunwoongko님은 카카오 브레인에서 근무를 하시다가 최근 TUNiB이라는 스타트업에서 자연어처리를 연구하고 있으신데요, 코드 3줄이면 인공지능과 대화를 해볼 수 있는 간편하게 BlenderBot, DialoGPT 기반의 오픈도메인 챗봇을 쉽게 접해볼 수 있는 패키지를 개발하여 공개해 주셨습니다. (pip install openchat으로 손쉽게 설치할 수 있습니다.)
프로젝트를 바로 확인해 보시고 싶으신 분은 다음 링크를 참조해 주세요.
Github: https://github.com/hyunwoongko/openchat
DEMO: https://main-openchat-fpem123.endpoint.ainize.ai/
API: https://ainize.ai/fpem123/openchat
Colab: https://colab.research.google.com/drive/1rGw2GINWgLwQYkp0KWT4P6U2ci5pJ862?usp=sharing

이 대화가 어색하다고 느껴지나요? 이 대화는 Open chat을 사용하여 나눈 대화의 일부분입니다. 즉 사람과 대화를 나눈 것이 아니라 인공지능과 대화를 나눈 것입니다. 영화 아이언맨의 자비스처럼 인공지능과 인간이 자유롭게 대화하는 것은 아직 무리지만 지난 수년간 인공지능의 기술이 비약적으로 발전하면서 인공지능은 이처럼 사람과 간단하게 대화할 수 있는 수준으로 발전하였습니다.
챗봇이 뭘까?
‘시리(Siri)’하면 무엇이 떠오르나요? 20년전 이라면 여러분의 지인 중에서 시리를 찾았겠지만, 지금이라면 분명 애플이 떠오를 겁니다. 이 시리가 바로 오늘 지금까지 설명했던 챗봇 중 하나입니다. 챗봇의 시발점은 1966년에 MIT 인공지능 연구소에서 개발한 ELIZA라고 볼 수 있을 거 같습니다. 이 당시 ELIZA는 간단한 패턴 매칭 수법을 사용하였습니다. 초기형 유사 인공지능에 불과했던 이 챗봇이 발전에 발전을 거쳐 오늘날 애플의 시리가 나오게 된 것입니다. 2011년 시리가 출시되었을 때 시리의 유용성에 대한 이슈는 있었지만, 대화의 문맥을 파악하는 능력은 놀라웠고 이에 일상에 챗봇을 적용하려고 하는 움직임을 보였습니다. 시간이 흘러 알파고의 등장에 따라 인공지능이 주목 받게 되었고 자연스럽게 언어를 처리할 수 있는 인공지능 모델에 대한 관심이 높아지며 자연어 처리 모델이 많이 발전하였습니다. 이에 GPT, BERT와 같은 모델이 소개되었고, 이런 모델들의 파라미터를 새로운 목적에 맞게 파인 튜닝(Fine-tuning)하여 챗봇의 성능을 더욱 높였습니다. 앞으로의 챗봇의 성장 가능성은 매우 클 것으로 예상하고 있습니다.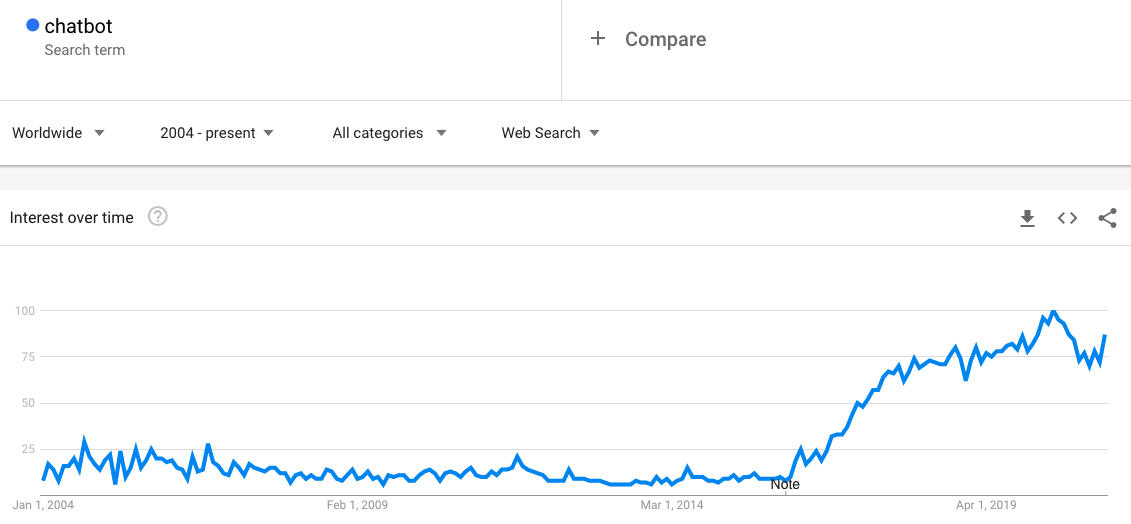 chatbot의 구글 검색 트랜드. 증가하는 추세임을 알 수 있음.
chatbot의 구글 검색 트랜드. 증가하는 추세임을 알 수 있음.
Open chat에서는 어떤 모델이 사용됐을까?
이 Open chat에서는 “BlenderBot” 혹은 “DialoGPT”이라는 언어 모델을 선택하여 대화를 할 수 있는데 여기서 언어 모델이란 학습데이터로 주어진 사람의 언어가 얼마나 자연스러운가를 수치로 계산하여 학습하고 확률을 할당하는 역할을 하는 모델을 의미합니다. 두 모델의 특징에 대해 살펴보겠습니다.
데이터 좀 섞어 볼까? : BlenderBot
BlenderBot은 Facebook에서 발표한 오픈 도메인 챗봇 모델입니다. openchat에서 사용된 BlenderBot은 파라미터의 개수가 다른 4종류의 모델인데, 각각 90M(small), 400M(medium), 1B(large), 3B(xlarge) 개의 파라미터를 가집니다. Facebook AI Research에서 개발한 NLP 프레임 워크인 Fairseq 툴킷으로 사전 학습을 진행하였고 사전 학습의 데이터 세트는 Reddit에 쓰인 글 중 조건에 맞는 글로 진행하였습니다. 파인 튜닝(Fine-tuning)을 진행할 때는 Facebook AI Research에서 개발한 ParlAI 툴킷을 사용하였으며 이는 다양한 종류의 챗봇 모델, 학습, 데이터 세트 등을 제공합니다. 미세 조정에서 사용된 데이터 세트는 ConvAI2(성격과 관련된 데이터 세트), Empathetic Dialogues (공감과 관련된 데이터 세트), Wizard of Wikipedia (지식과 관련된 데이터 세트), Blended Skill Talk(앞에 제시된 데이터 세트 혼합)를 사용하였습니다. Blended Skill Talk를 사용함으로써 이전 데이터 세트(ConvAI2, Wizard of Wikipedia, Empathetic Dialogues)의 학습 결과를 유지하는 데 도움을 줬다고 합니다.
모델에 대한 자세한 정보는 여기에서 확인할 수 있습니다.
이 모델에 대해 간략하게 요약하자면
- Facebook에서 발표한 챗봇 모델
- Fairseq 툴킷과 ParlAI 툴킷 사용
- Reddit에 쓰여진 글 중 조건에 맞는 데이터 + ConvAI2 + Empathetic Dialogues + Wizard of Wikipedia + Blended Skill Talk를 학습 데이터로 사용
GPT2에서 살짝 바꿔보자 : DialoGPT
DialoGPT은 Microsoft에서 발표한 챗봇 모델입니다. 이름에서 볼 수 있듯이 GPT-2의 아키텍처를 기반으로 설계되어 있으며 이를 대화 형식에 맞게 변형한 모델입니다. openchat에서 사용된 DialoGPT은 파라미터의 개수가 다른 3종류의 모델인데, 각각 117M(small), 345M(medium), 762M(large) 개의 파라미터로 BlenderBot의 파라미터 수에 비해 적은 것을 확인할 수 있습니다. 학습에 사용된 데이터 세트는 2005~2017년까지 Reddit에 쓰인 글 중 필터링을 거쳐 조건에 맞는 데이터를 뽑아 학습에 사용하였습니다. 소스 혹은 타겟에 URL이 있는 경우, 타겟이 적어도 3개 이상의 단어 반복이 존재하는 경우, 자주 등장하는 영단어 top 50(a, the, of …)가 하나도 포함되어 있지 않은 경우(외국어로 판단), 공격적인 단어를 포함하는 경우 등 이와 같은 조건은 필터링 조건이 되어 학습에 사용하지 않았습니다. 필터링 후 약 1억 4천 개의 대화를 구성하였습니다. 모델에 대한 자세한 정보는 여기에서 확인할 수 있습니다.
이 모델에 대해 간략하게 요약하자면
- Microsoft에서 발표한 챗봇 모델
- GPT2의 모델에서 대화체에 맞게 변형
- Reddit에 쓰여진 글 중 조건에 맞는 데이터들만 크롤링하여 학습데이터로 사용
“거인의 어깨 위에 올라선 난쟁이는 거인보다 더 멀리 본다.” — 조지 허버트
위와 같은 챗봇을 사용하기 위해서는 모델을 소개하는 논문을 보고 논문에서 제시된 방법대로 코드를 설계하여 사용해야 합니다. 또한 모델을 학습시킬 데이터를 구해야하고, 학습 환경을 조성하기위해 GPU를 준비해야합니다. 이 방법은 시간과 노력이 많이 투자되어야 하는 작업이므로 비효율적이라고 생각됩니다. 하지만 우리는 오픈소스라는 거인의 도움을 받으면 넓은 세상을 쉽게 볼 수 있습니다. 많은 오픈소스 개발자들이 이러한 작업을 대신하여 결과물을 오픈소스로 배포를 해주기 때문에 오픈소스로 배포된 챗봇을 이용하면 보다 쉽게 챗봇을 이용할 수 있습니다. 오픈소스를 배포하는 사이트로는 GitHub, Hugging Face, Ainize 등이 있습니다. Hugging Face는 AI 커뮤니티로 Facebook, Google 등과 같은 기업에서 제공하는 모델, NLP 라이브러리 등을 오픈소스로 제공해줍니다. Ainize는 오픈소스 AI 프로젝트들을 배포하고 오픈 소스 코드를 확장 가능한 API 서비스로 전환하는 등 오픈소스에 대한 다양한 기능을 제공해주는 서비스입니다.
그래서 어떻게 쓰는데요?
- pip install openchat하여 사용하기 (글에 나와있는 방법은 Open chat version 1.0 기준입니다.)
먼저 Open chat을 사용하기 위해 Open chat install을 진행합니다. 그 후 Open chat을 설치하고 원하는 모델과 사이즈를 파라미터로 넣어주고 실행하면 Open chat을 사용할 수 있습니다.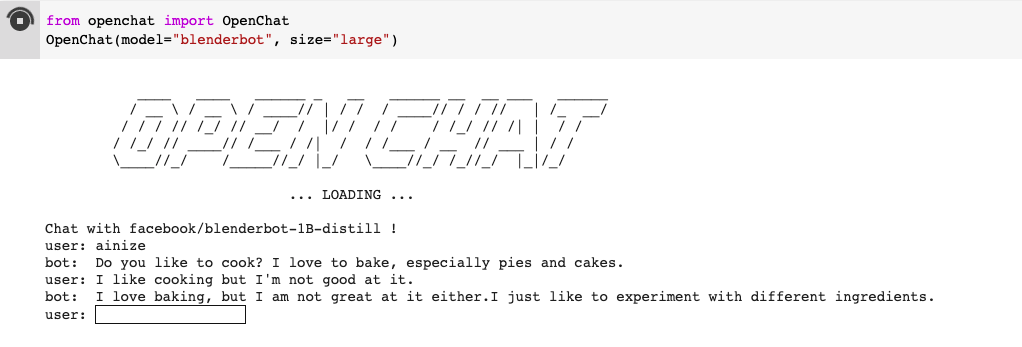 실행 환경은 colab으로 설정하였으며 여기에서 확인하실 수 있습니다.
실행 환경은 colab으로 설정하였으며 여기에서 확인하실 수 있습니다.
- Ainize의 Open chat DEMO 사용하기
이번에는 Open chat을 설치하지 않고 Ainize에서 제공하는 Open chat DEMO를 통해 Open chat을 실행해보겠습니다.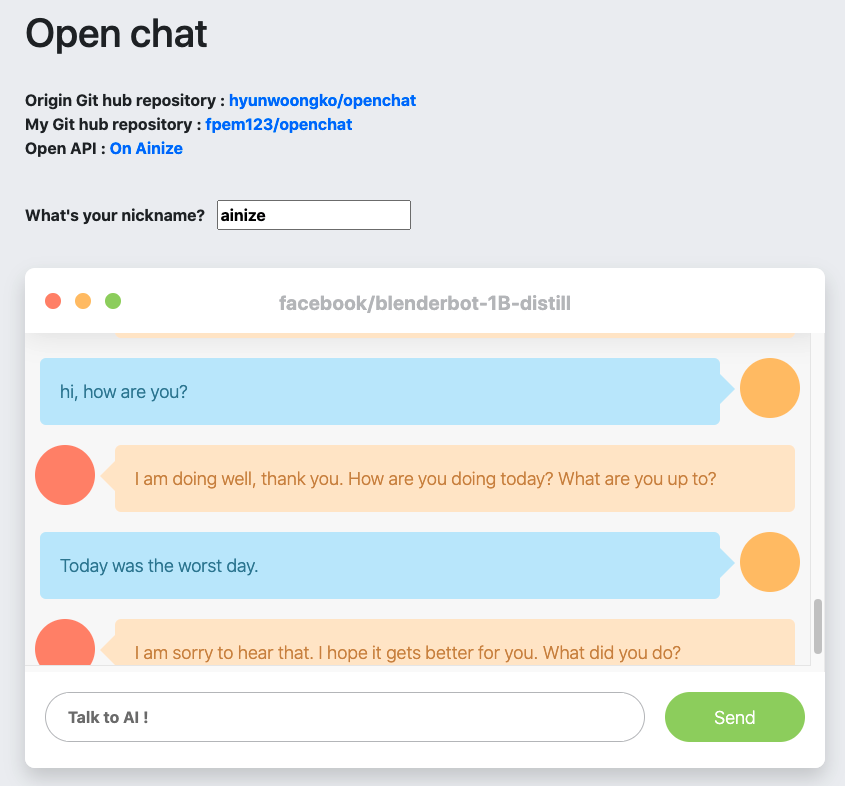 데모 페이지에 들어간 후 닉네임 작성을 완료하면 준비는 끝입니다. 그 후 원하는 말을 작성 후 Send 버튼을 누르게 되면 입력한 말이 전송되고 대답이 돌아오게 됩니다. 위에서 사용한 DEMO는 여기에서 사용할 수 있습니다.
데모 페이지에 들어간 후 닉네임 작성을 완료하면 준비는 끝입니다. 그 후 원하는 말을 작성 후 Send 버튼을 누르게 되면 입력한 말이 전송되고 대답이 돌아오게 됩니다. 위에서 사용한 DEMO는 여기에서 사용할 수 있습니다.
- Ainize의 Open chat API 사용하기
이번에는 Ainize에서 제공하는 Open chat API를 사용하여 Open chat을 사용해보겠습니다. Open chat을 다른 서비스에서 활용하고 싶을 때는 이 방법을 사용하면 편할겁니다! Open chat은 POST 메소드를 사용하며
curl -X POST “https://main-openchat-fpem123.endpoint.ainize.ai/send/{유저 닉네임}” -H “accept: application/json” -H “Content-Type: multipart/form-data” -F “text={전달하고 싶은 메세지}”와 같은 방식으로 호출할 수 있습니다. 그 후 잠시 기다리면
{“output”:” I am a teacher as well, I love my job. What kind of work do you like?”}와 같은 응답을 받을 수 있습니다. 자세한 내용은 여기에서 확인할 수 있습니다.
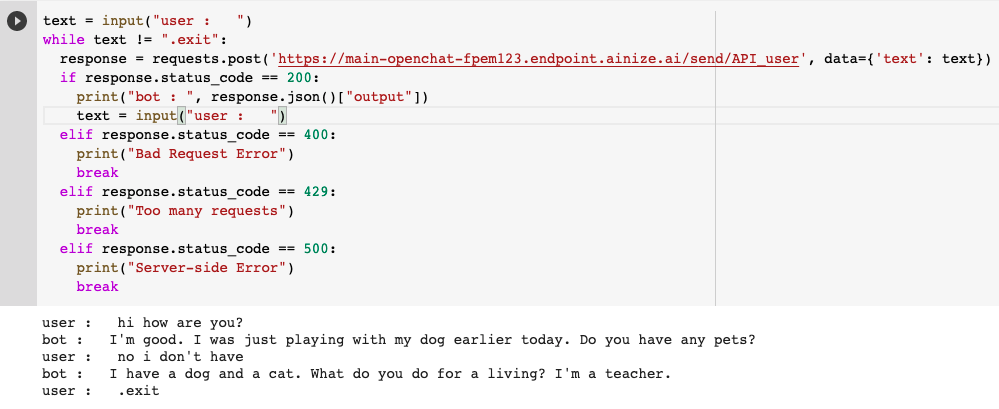 실행 환경은 colab에서 설정하였으며, 여기에서 확인할 수 있습니다.
실행 환경은 colab에서 설정하였으며, 여기에서 확인할 수 있습니다.
챗봇의 현재와 미래
현재 챗봇이 일상에 미치는 영향은 극히 일부분입니다. 이러한 이유는 크게 보면 2가지라고 볼 수 있는데 첫 번째로 챗봇이 아직 완벽하게 사람의 말을 이해하지 못합니다. 인간의 대화 방식은 매우 복잡합니다. 단지 단어의 의미를 이해한다고 대화할 수 있는 것이 아니라 대화의 상황과 맥락 또한 함께 이해해야 합니다. 이처럼 사람에게도 복잡한 대화 방식을 인공지능에 학습시키기란 매우 어렵습니다. 두 번째로 모델을 학습시킬 데이터가 부족합니다. 인공지능을 다루는 사람들 사이에서 유명한 말 중 하나가 GIGO(Garbage-In, Garbage-Out)입니다. 즉, 질이 좋지 않은 데이터로 학습을 시키면 질 나쁜 예측값이 나온다는 의미입니다. 이처럼 챗봇의 성능을 높이기 위해서는 질 좋은 데이터가 필요하지만, 현재는 그렇지 못한 상황입니다.
하지만 이런 문제점들이 개선된다면, 챗봇은 지금보다 더 많은 분야에서 활용될 가능성이 높아질 것입니다. 미래에 챗봇이 활용될 분야 중 한가지인 교육 부분에서 살펴 보자면, 대부분의 사람들은 도움을 요청하는 것을 부끄러워하는 경향을 보입니다. 아마 누군가에게 도움을 받으려고 하지 않은 것은, 이전에 도움을 받으려고 했을 때 “이것도 못해?”와 같은 소리를 들어서 그럴 것 입니다. 하지만 챗봇은 그러지 않습니다. 교육 측면에서 챗봇이 사람보다 탁월한 부분이 바로 이 부분일 것입니다. 기계는 사람을 평가할 수 없습니다. 같은 질문을 몇백번 하든, 챗봇은 불평없이 똑같은 대답을 해줍니다. 챗봇의 성능이 좋아진 후, 챗봇의 특성을 활용한다면 교육 분야에서 챗봇의 유용성은 높아질 것입니다.
아직은 완벽하지 않지만, 인공지능의 기술이 지금보다 더욱 발전하여 로봇들이 인간의 말들을 100% 구현한다면 인공지능이 인간의 삶을 편리하게 해주는 것을 넘어 친구가 될 수도 있을 거 같다는 생각이 들었습니다.
커뮤니티의 공통적인 관심사를 가지고 글을 써주는 모델로 글을 쓴다면, 여러분들은 이 글이 사람이 쓴 건지 기계가 쓴 건지 구분하실 수 있으신가요? 다음 글로 알아보도록 하겠습니다. 긴 글 읽어주셔서 감사합니다!
레퍼런스
- What is an “entity” in a chatbot?
- ELIZA
- Recipes for building an open-domain chatbot
- DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
- Open Chat Github
- Open Chat Ainize
AI 네트워크는 블록체인 기반 플랫폼으로 인공지능 개발 환경의 혁신을 목표로 하고 있습니다. 수백만 개의 오픈 소스 프로젝트가 라이브로 구현되는 글로벌 백엔드 인프라를 표방합니다.
최신 소식이 궁금하시다면 아래 커뮤니케이션 채널을 참고해주시기 바랍니다. 다시 한 번 감사합니다.
AI네트워크 공식 홈페이지: https://ainetwork.ai/
공식 텔레그램: https://t.me/ainetwork_kr
아이나이즈(Ainize): https://ainize.ai
유튜브: https://www.youtube.com/channel/UCnyBeZ5iEdlKrAcfNbZ-wog
페이스북:https://www.facebook.com/ainetworkofficial/
포럼:https://forum.ainetwork.ai/
AIN Price chart: https://coinmarketcap.com/currencies/ai-network/onchain-analysis/
![]()
