✔️ 배치란?
- 사용자와의 상호작용 없이 여러 작업을 미리 정해진 순서에 따라 중단 없이 처리하는 것
- 배치의 특징
- 대용량 데이터- 자동화
- 견고성: 잘못된 데이터를 충돌/중단 없이 처리할 수 있어야 합니다.
- 신뢰성: 로깅, 알림 등을 통해 무엇이 잘못되었는지를 추적할 수 있어야 합니다.
- 성능: 지정한 시간 안에 처리를 완료하거나 동시에 실행되는 다른 프로그램을 방해하지 않아야 합니다.
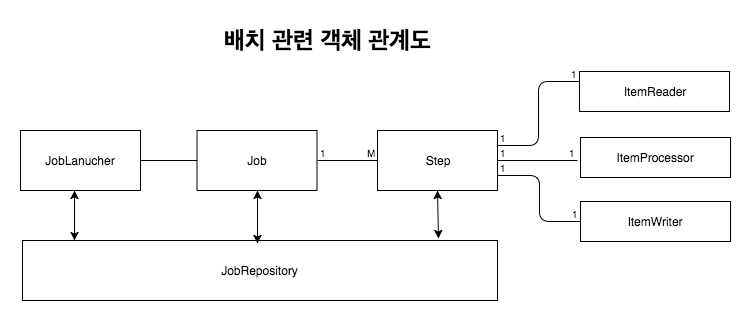
스프링 배치 구성
배치 플로우
- 읽기(read) : 데이터 저장소(일반적으로 데이터베이스)에서 특정 데이터 레코드를 읽습니다.
- 처리(processing) : 원하는 방식으로 데이터 가공/처리 합니다.
- 쓰기(write) : 수정된 데이터를 다시 저장소(데이터베이스)에 저장합니다.
Job과 Step은 1:M
Step과 ItemReader, ItemProcessor, ItemWriter 1:1
JobInstance
- JobInstance는 배치 처리에서 Job이 실행될 때 하나의 Job 실행 단위입니다.
각각의 JobInstance는 하나의 JobExecution을 갖는 것은 아닙니다. 오늘 Job이 실행 했는데 실패했다면 다음날 동일한 JobInstance를 가지고 또 실행합니다.
Job 실행이 실패하면 JobInstance가 끝난것으로 간주하지 않기 때문입니다. 그렇다면 JobInstance는 어제 실패한 JobExecution과 오늘의 성공한 JobExecution 두 개를 가지게 됩니다. 즉 JobExecution 는 여러 개 가질 수 있습니다.
JobExecution
- JobExecution은 JobIstance에 대한 한 번의 실행을 나타내는 객체입니다.
JobExecution은 JobInstance, 배치 실행 상태, 시작 시간, 끝난 시간, 실패했을 때 메시지 등의 정보를 담고 있습니다.
JobParameters
- JobParameters는 Job이 실행될 때 필요한 파라미터들은 Map 타입으로 지정하는 객체 입니다.
JobParameters는 JobInstance를 구분하는 기준이 되기도 합니다.
JobParameters와 JobInstance는 1:1 관계입니다.
Step
- Step은 실직적인 배치 처리를 정의하고 제어 하는데 필요한 모든 정보가 있는 도메인 객체입니다. Job을 처리하는 실질적인 단위로 쓰입니다.
모든 Job에는 1개 이상의 Step이 있어야 합니다.
StepExecution
- Job에 JobExecution Job실행 정보가 있다면 Step에는 StepExecution이라는 Step 실행 정보를 담는 객체가 있습니다.
JobRepository
- JobRepository는 배치 처리 정보를 담고 있는 매커니즘입니다. 어떤 Job이 실행되었으면 몇 번 실행되었고 언제 끝났는지 등 배치 처리에 대한 메타데이터를 저장합니다.
- 예를들어 Job 하나가 실행되면 JobRepository에서는 배치 실행에 관련된 정보를 담고 있는 도메인 JobExecution을 생성합니다.
- JobRepository는 Step의 실행 정보를 담고 있는 StepExecution도 저장소에 저장하여 전체 메타데이터를 저장/관리하는 역할을 수행합니다.
JobLauncher
- JobLauncher는 Job. JobParamerters와 함께 배치를 실행하는 인터페이스입니다.
ItemReader
- ItemReader는 Step의 대상이 되는 배치 데이터를 읽어오는 인터페이스입니다. File, Xml Db등 여러 타입의 데이터를 읽어올 수 있습니다.
ItemProcessor
- ItemProcessor는 ItemReader로 읽어 온 배치 데이터를 변환하는 역할을 수행합니다. 이것을 분리하는 이유는 다음과 같습니다.
- 비즈니스 로직의 분리 : ItemWriter는 저장 수행하고, ItemProcessor는 로직 처리만 수행해 역할을 명확하게 분리합니다.
읽어온 배치 데이터와 씌여질 데이터의 타입이 다를 경우에 대응할 수 있기 때문입니다.
ItemWriter
- ItemWriter는 배치 데이터를 저장합니다. 일반적으로 DB나 파일에 저장합니다.
- ItemWriter도 ItemReader와 비슷한 방식을 구현합니다. 제네릭으로 원하는 타입을 받고 write() 메서드는 List를 사용해서 저장한 타입의 리스트를 매게변수로 받습니다.
✔️ 스프링 배치를 이용한 휴먼 계정 처리
@Configuration
@RequiredArgsConstructor
@Slf4j
public class InactiveUserJobConfiguration {
private final UserRepository userRepository;
private final StepBuilderFactory stepBuilderFactory;
private final JobBuilderFactory jobBuilderFactory;
@Bean
public Job inactiveUserJob(JobBuilderFactory jobBuilderFactory, Step inactiveJobStep) {
return jobBuilderFactory.get("inactiveUserJob")
.preventRestart()
.incrementer(new RunIdIncrementer())
.start(inactiveJobStep)
.build();
}
@Bean
public Step inactiveJobStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("inactiveUserStep")
.<User, User> chunk(10)
.reader(inactiveUserReader())
.processor(inactiveUserProcessor())
.writer(inactiveUserWriter())
.build();
}
@Bean
@StepScope
public QueueItemReader<User> inactiveUserReader() {
List<User> targetUsers =
userRepository.findBylastModifiedAtBeforeAndStatusEquals(
LocalDateTime.now().minusYears(1),
true);
log.info("InActive Target User Count: " + targetUsers.size());
return new QueueItemReader<>(targetUsers);
}
@Bean
@StepScope
public ItemProcessor<User, User> inactiveUserProcessor() {
return User::toInActive;
}
@Bean
@StepScope
public ItemWriter<User> inactiveUserWriter() {
return (userRepository::saveAll);
}
}-
스프링 배치를 사용하기 위해서는 DB에 배치 처리를 위한 테이블들이 필요합니다.
-
schema.mysql.sql 파일을 통해 테이블 생성 후 실행 가능
Spring Batch 개발기 ( 4. MetaData테이블 ) -
이후 스케줄러를 적용하여 ApplicationContext에 있는 Job bean을 가져와 JobLauncher로 실행시킬 수 있습니다.
✔️ 스케쥴러란?
- 특정한 시간에 등록한 작업을 자동으로 실행시키는 것
- Spring Scheduler, Quartz
휴먼 계정 처리 - 스케쥴러 선택 이유
- 스케쥴러는 한 번에 많은 양의 데이터를 처리하려면 성능 이슈가 발생할 수 있기 때문에 대용량 데이터 처리에는 부적합합니다. 하지만 현재 서비스는 출시 직후 예상 유저가 약 200명이기 때문에 간단한 스케쥴링 작업에 적합합니다.
