
OS(권영진 교수님 강의)
- mmap 사용하면 가상주소가 리턴됨
- page fault(why 생김?) → 성능 갭이난다 → 퍼포먼스 디버깅 → 운영체제 배우는 이유
- 운영체제 탄생 → 첨엔 하드웨어가 여러개 있었음 → 운영체제 == abstraction
- 슬라이드 11장 (machine)
- 슬라이드 17장 (anonymous memory, the backed memory)
- DMA / interrupt
- 슬라이드 19장 (offset) (file system)
- 인덱스 테이블이 어떻게 생겼나?
- FAT, indirect index, Btree, Extant Tree(EXT4)
- When to allocate physical block?
- Any perfomance optimization for slow storage device → page buffer
- layer of abstraction(VFS)
- Atomicity, Durability
PintOS keyword
Project 0: PintOS
Race Condition
- Race Conidition
- 두 개 이상의 프로세스가 공통 자원을 병행적으로 읽거나 쓰는 동작을 할 때, 공용 데이터에 대한 접근이 어떤 순서에 따라 이루어졌는지에 따라 그 실행 결과가 같지 않고 달라지는 상황을 말함.
- Race의 뜻 그대로, 간단히 말하면 경쟁하는 상태, 즉 두 개의 스레드가 하나의 자원을 놓고 서로 사용하려고 경쟁하는 상황을 말함.
- Race Condition의 제어 문제
- Mutual exclusion(mutex)
- race condition을 막기 위해서는 두 개 이상의 프로세스가 공용 데이터에 동시에 접근을 하는 것을 막아야 한다. 다른 프로세스가 그 자원을 사용하지 못하도록 막으면 이 문제를 피할 수 있음. 이것을 상호 배제(mutual exclusion)라 말함.
- Deadlock
- 그러나 위와 같은 상호 배제를 시행하면 추가적인 제어 문제가 발생함. 하나는 교착상태 즉 여기서 말하는 Deadlock이다. 프로세스가 각자 프로그램을 실행하기 위해 두 자원 모두에 엑세스 해야한다고 가정할 때 프로세스는 두 자원 모두를 필요로 하므로 필요한 두 리소스를 사용하여 프로그램을 수행할 때까지 이미 소유한 리소스를 해제하지 않음. 이러한 상황에서 두 프로세스는 교착 상태에 빠지게 되는 문제가 발생함.
- Race Condition을 예방 할 수 있는 방법
- 공유된 자원에 여러 프로세스 혹은 스레드가 동시에 접근하면 문제가 발생할 수 있다. 따라서 공유된 자원은 한 번에 하나의 프로세스만 접근할 수 있도록 제한을 줘야한다. 대표적으로 세마포어와 뮤텍스가 있음.
- 세마포어와 뮤텍스
- Mutual exclusion(mutex)
virtual Machine 과 hypervisor
-
virtual
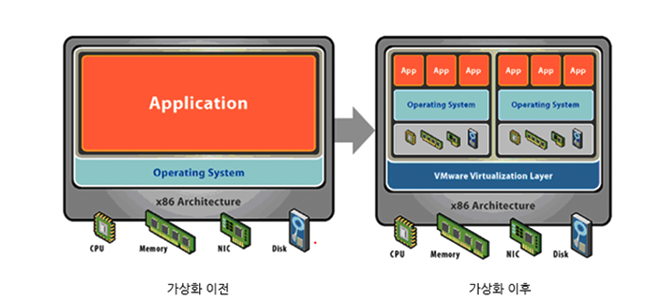
물리 하드웨어 시스템에서 여러 시뮬레이션 환경이나 전용 리소스를 생성해주는 기술
-
가상화 한다는 말의 의미
- 하나의 물리머신상에서 복수의 시스템을 동시운영한다.
- 또다른 cpu, 메모리, 하드디스크를 논리적으로 생성한다.
- 물리서버 단위가 아닌 애플리케이션단위로 전환한다.
-
어떻게 다른 OS들을 사용할까?
- 각 OS마다 커널이 존재한다. 이 커널은 리소스를 관리하고, 명령어 해석하는 역할이다. 그런데 OS마다 명령어를 해석하는 규칙도 다름.

- 각 OS마다 커널이 존재한다. 이 커널은 리소스를 관리하고, 명령어 해석하는 역할이다. 그런데 OS마다 명령어를 해석하는 규칙도 다름.
-
그럼 어떻게 이런 명령어들을 이해해서 각각 OS를 구동할까?
- 바로 hypervisor → 하이퍼바이저가 각 OS마다 말하는 명령을 하드웨어가 이해할 수 있게 하나의 명령어로 번역해줌.
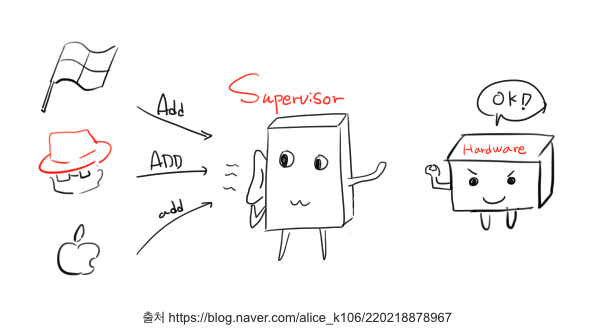
- 바로 hypervisor → 하이퍼바이저가 각 OS마다 말하는 명령을 하드웨어가 이해할 수 있게 하나의 명령어로 번역해줌.
-
hypervisor 유형
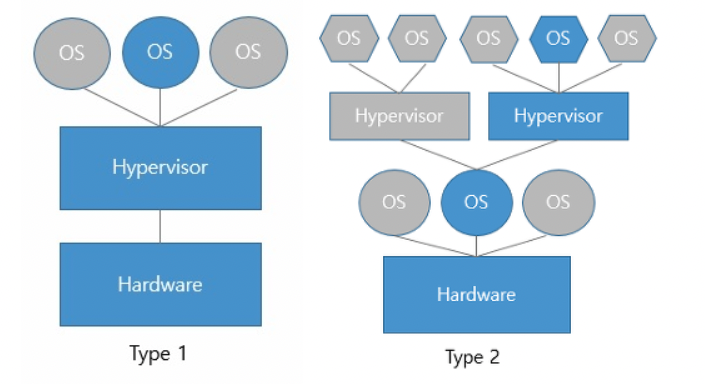
하드 웨어 위에 하이퍼바이저가 올라감, HOST OS가 없음. 직접 하드웨어에 설치됨. 하이퍼바이저가 다수의 VM을 관리하는 형태다. Type2보다 성능은 좋은데 비용이 더듬(여러 하드웨어 드라이버를 세팅해야함) → Type 1
OS 위에 하이퍼바이저가 올라감, HOST OS가 있고 그 위에 GUEST OS 올림 → Type 2
-
Project 1 : Threads
-
Time-sharing system
-
Context Switching
- 멀티프로세스 환경에서 CPU가 어떤 하나의 프로세스를 실행하고 있는 상태에서 운영체제의 스케줄러가 인터럽트를 진행하여 다음 우선 순위의 프로세스가 실행되어야 할 때 기존의 프로세스의 상태 또는 레지스터 값(context)을 저장하고 CPU가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값(Context)를 교체하는 작업을 말함
- context란?
- OS에선 CPU가 해당 프로세스를 실행하기 위한 해당 프로세스의 정보들 → Context는 프로세서의 PCB(커널 내부에 존재)에 저장됨.
- 그래서 context switching 때 PCB의 정보를 읽어 CPU가 전에 프로세스가 일을 하던거에 이어서 수행이 가능한 것.
- PCB 저장정보
- 프로세스 상태 : 생성, 준비, 수행, 대기, 중지
- 프로그램 카운터 : 프로세스가 다음에 실행할 명령어 주소 → 다음에 실행될 명령어의 주소를 가지고 있어 실행할 기계어 코드의 위치를 지정 → 간단히 코드 한줄한줄을 가리키는 주소 레지스터라 생각하면 됨.
- 레지스터 : 누산기, 스택, 색인 레지스터
- PID(프로세스 번호)
context switching 때 해당 CPU는 아무런 일을 하지 못함. 따라서 컨텍스트 스위칭이 잦아지면 오히려 오버헤드가 발생해 효율이 떨어짐
- Context Switching - 인터럽트(Interrupt)
- 인터럽트는 CPU가 프로그램을 실행하고 있을 때 실행중인 프로그램 밖에서 예외 상황이 발생하여 처리가 필요한 경우 CPU에게 알려 예외 상황을 처리할 수 있도록 하는 것을 말한다.
- 어떤 인터럽트 요청이 와야 Context Switching이 일어날까?
- I/O request(입출력 요청할 때)
- time slice expired (CPU 사용시간이 만료 되었을 때)
- fork a child (자식 프로세스를 만들 때)
- wait for an interrupt (인터럽트 처리를 기다릴 때) 등등
-
Scheduler
-
한정적인 메모리를 여러 프로세스가 효율적으로 사용할 수 있도록 다음 실행 시간에 실행할 수 있는 프로세스 중에 하나를 선택하는 역할
-
1) 스케줄링 큐 → 프로세스를 관리하는 큐
- Job Queue - 시스템 안의 모든 프로세스의 집합
- Ready Queue - ready 상태의 메인메모리 안에 상주하는 모든 프로세스의 집합
- Device Queue - I/O 장치 사용을 대기하는 프로세스들의 집합
-
2) 스케줄러 종류
- 장기 스케줄러(Long-term scheduler) / 잡 스케줄러(Job scheduler)
- degree of multiprogramming 제어
- 디스크와 메모리 사이의 스케줄링 담당
- 어떤 프로세스에 메모리를 할당하여 ready queue로 보낼지 결정하는 역할
- 단기 스케줄러(Short-term scheduler) / CPU 스케줄러(CPU scheduler)
- 메모리와 CPU 사이의 스케줄링 담당
- 어떤 프로세스를 running 상태로 전환 시킬지 결정하는 역할
- 중기 스케줄러(Mid-term scheduler) / 스와퍼(Swapper)
- degree of multiprogramming 제어
- 여유 공간을 마련하기 위해 프로세스를 통째로 메모리에서 디스크로 쫓아내는 역할(swap in/ swap out)
- 장기 스케줄러(Long-term scheduler) / 잡 스케줄러(Job scheduler)
-
-
Round Robin - 스케줄링 기법
- Round Robin Scheduling(라운드로빈 스케줄링)은 시분할 시스템을 위해 설계된 선점형 스케줄링의 하나다. → 쉽게 말해 순서대로 시간단위를 CPU에 할당하는 방식
- 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum)로 CPU를 할당하는 방식의 CPU 스케줄링 알고리즘이다.
- 응답시간이 빠르며, 모든 프로세스에게 컴퓨터 자원을 사용할 수 있는 기회를 공정하게 부여하기 위한 한 방법.
- 각 프로세스에 일정시간을 할당하고, 할당된 시간이 지나면 그 프로세스는 잠시 보류한 뒤 다른 프로세스에게 기회를 주고를 반복
- 보통 시간 단위는 10ms ~ 100ms 정도로, 시간 단위동안 수행한 프로세스는 준비 큐의 끝으로 밀려나게 되고 context switching의 오버헤드가 큰 반면 응답시간이 짧아지는 장점이 있어 실시간 시스템에 유리.
- 꽤 효율적인 스케줄링 알고리즘이지만 이 시간단위를 작게 설정하면 CPU가 조금 일하고 Context Switching을 반복하므로 효율이 떨어짐.
- 반면 할당되는 시간이 클 경우 비선점 FIFO기법과 같아지게 된다.
-
priority
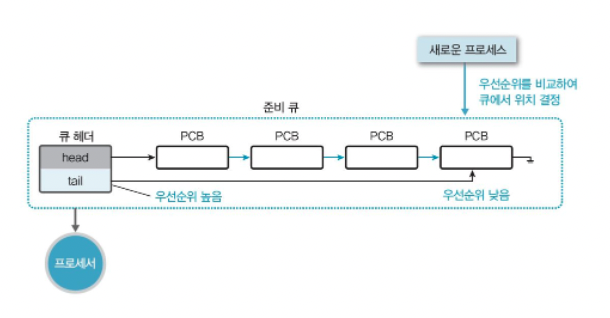
- 우선 순위는 해당 OS의 스케줄러가 우선 순위 알고리즘에 의해 정해지고 수행하게 되어있음
- 우선순위 스케줄링은 다음 그림과 같이 준비 큐에 프로세스가 도착하면, 도착한 프로세스의 우선순위와 현재 실행 중인 프로세스의 우선순위 를 비교하여 우선순위가 가장 높은 프로세스에 프로세서를 할당하는 방식이다.
- 비선점 스케줄링 vs 선점 스케줄링
- 비선점 스케줄링
- 이미 할당된 CPU를 다른 프로세스가 강제로 빼앗아 사용할 수 없는 스케줄링 기법.
- 선점 방식보다 스케줄러 호출 빈도가 낮고 문맥 교환에 의한 오버헤드도 적다.
- CPU 사용 시간이 긴 하나의 프로세스가 CPU 사용 시간이 짧은 여러 프로세스를 오랫동안 대기시킬 수 있으므로, 처리율이 떨어질 수 있다는 단점도 있다.
- 선점 스케줄링
- 하나의 프로세스가 CPU를 할당 받아 실행하고 있을 때 우선 순위가 높은 다른 프로세스가 CPU를 강제로 빼앗아 사용할 수 있는 기법
- 모든 프로세스에게 CPU 사용 시간을 동일하게 부여할 수 있으며, 빠른 응답시간을 요하는 대화식 시분할 시스템에 적합하며 긴급한 프로세서를 제어할 수 있다.
- 비선점 스케줄링
- 우선순위 결정법
- 내부적 우선순위 결정
- 제한 시간, 기억장소 요청량, 사용 파일 수, 평균 프로세서 버스트에 대한 평균 입출력 버스트의 비율
- 외부적 우선순위 결정
- 프로세스의 중요성, 사용료를 많이 낸 사용자, 작업을 지원하는 부서, 정책적 요인
- 내부적 우선순위 결정
- 우선순위 스케줄링의 단점
- 높은 우선수위 프로세스가 프로세서를 많이 사용하면 우선순위가 낮은 프로세스는 무한정 연기되는 기아가 발생한다.
- priority Inversion
- H, M, L 이라는 세 개의 스레드가 있다. 우선순위는 H > M > L 일 때, H 가 L을 기다려야하는 상황(H가 lock 요청했는데 이 lock을 L이 점유하고 있는 경우)이 생긴다면 H가 L에게 CPU 점유를 넘겨주면 M이 L보다 우선순위가 높으므로 점유권을 선점하여 실행되어서 스레드 마무리 되는 순서가 M → L → H 가 되어서 M이 더 높은 우선순위를 가진 H 보다 우선하여 실행되는 문제가 발생한다. → 이러한 문제로 priorty donation이 필요
- priority donation
- H가 자신이 가진 priority를 L에게 일시적으로 양도하여서 H 자신의 실행을 위해 L 이 자신과 동일한 우선순위를 가져서 우선적으로 실행될 수 있도록 만드는 방법.
- 진짜 정리 잘 되어 있음 - https://firecatlibrary.tistory.com/60
-
Thread Control Block
- TCB는 Thread별로 존재하는 자료구조이며, PC와 Register Set(CPU 정보), 그리고 PCB를 가리키는 포인터를 가진다.

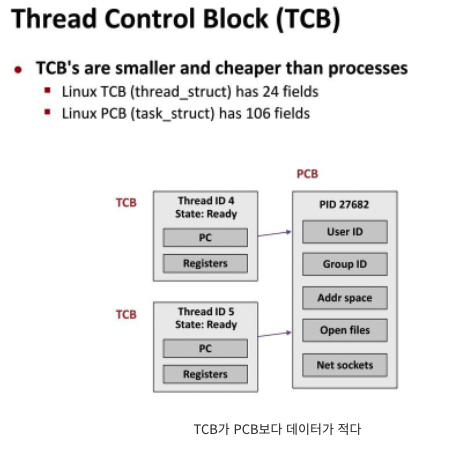
cf) 같은 프로세스에서의 스위칭에 대해서는 TCB 정보만 저장하면 된다. 하지만 다른 프로세스 간의 스위칭을 할 때에는 PCB / TCB 정보를 모두 저장해야 한다.
-
-
Timer Interrupt
-
마이크로프로세서의 내부 시계를 이용하여 일정 시간일 때 발생되는 인터럽트를 타이머 인터럽트라고 함.
-
Interrupt
- 하드웨어가 운영체제에 보내는 전기적 신호
- 운영체제의 커널은 이 신호를 받아 그 상황에 따른 대처, 일을 처리한다.(비동기적, 처리중에는 다른 프로세스 멈춤)
- 과정
- 하드웨어에서 물리적 전기신호의 형태로 발생
- 인터럽트 컨트롤러의 입력 핀으로 전달
- 컨트롤러는 프로세서에 전달
- 인터럽트를 감지한 프로세서는 진행중이던 일 중지
- 운영체제에 인터럽트 발생 전달
- 운영체제의 인터럽트 처리
- 중단되었던 프로세스 재개
- cpu가 프로세스를 실행도중 파일 읽기 같은 명령을 수행하게되면 프로세스는 block 상태에 돌입하게 되고 파일 읽기가 끝나면 다시 ready 상태로 돌아오게 된다. 그런데 파일 읽기가 끝난걸 어떻게 알까?
- 여기서 파일 읽기가 끝났다는걸 운영체제에 알려주는게 인터럽트의 역할이다.
- 이외에도 0으로 나누기 등의 예외사항 처리를 위해서도 인터럽트가 발생
- 키보드, 마우스, 프린터기 등의 이벤트에 대해서도 인터럽트가 일어나게 됨.
- 타이머 인터럽트라고 선점형 스케쥴러에서 cpu가 1초마다 프로세스를 번갈아가면서 실행한다고 가정해보자
- 이 경우 1초마다 인터럽트를 걸어주어 cpu에게 알려서 cpu가 프로세스를 바꾸게 해주는 것도 있다
- 시스템 콜도 인터럽트
-
내부 인터럽트(소프트웨어 인터럽트) vs 외부 인터럽트(하드웨어 인터럽트)
- 내부 인터럽트 → 프로그램 내부에서 잘못된 명령 등이 사용되었을 때 발생하게 된다.
- 0으로 나누기
- overflow/underflow
- 잘못된 주소 접근 → 사용자모드 상태에서 커널모드에서 접근 가능한 주소로 접근할 때
- 외부 인터럽트 → 주로 하드웨어에 의해 발생하게 된다
- 키보드, 프린터 등의 I/O 이벤트
- 타이머 이벤트
- 내부 인터럽트 → 프로그램 내부에서 잘못된 명령 등이 사용되었을 때 발생하게 된다.
-
IDT란?
- Interrupt Descriptor Table의 약자로 시스템 콜, 0으로 나누기 등의 여러 인터럽트들이 각각 번호와 실행코드로 IDT에 미리 정의되어 있다.(컴퓨터 부팅시 운영체제가 기록)
- 인터럽트가 발생하면 IDT를 확인해서 해당함수를 실행 함 → 프로세스가 실행되다가 인터럽트가 발생하면 프로세스를 잠시 중단하고 IDT를 확인하여 인터럽트에 맞는 함수를 실행 후 다시 프로세스가 재 실행 됨.
-
인터럽트 핸들러
- 인터럽트를 처리하기 위해 커널이 실행하는 ‘함수' aka 인터럽트 서비스 루틴(ISR)
- 각 장치별로 인터럽트 핸들러가 있음
- 인터럽트 함수의 특징은 인터럽트가 발생했을 때 커널이 호출한다는 점과 인터럽트 컨텍스트라는 특별한 컨텍스트에서 실행된다는 점
- 인터럽트 처리가 길면 일반 처리에 영향을 끼치므로 되도록 간단하고 최소한의 처리만을 작성하도록 주의하여야함.
-
-
Timer Sleep
- lock과 sleep
- lock
- 커널의 동기화(synchronization)에서 공유자원에 동시 접근하는 것을 막는 개념
- 아키텍쳐에 의존적이고 대부분 어셈블리로 구현 되어있음
- spin-lock과 같이 CPU 클럭을 소비하면서 busy-waiting 하는 경우도 있다.
- sleep
- 커널의 프로세스 스케쥴링에 관련되는 개념
- sleep은 busy-waiting 하지 않고, 현재 CPU에서 실행하고 있던 각종 레지스터 값 및 스택등의 정보를 메모리에 보관시킴(context switching)
- 즉, 현재 CPU에서 실행되고 있는 프로세스를 메모리로 sleep 시키는 것 → CPU는 다른 일을 할 수가 있어 다중 프로세싱이 가능한 것
- 동작 원리
- lock
- lock과 sleep
-
Synchronization
- 동기화란?
- 동기화란 프로세스 또는 스레드들이 수행되는 시점을 조절하여 서로가 알고 있는 정보가 일치하는 것을 의미합니다.
- Ex) a = 2 라는 자원이 있음 P1, P2 프로세스 두개가 있는데 같이 접근하려함
- a 는 공유 자원이라함
- 두개 이상의 프로세스 혹은 스레드가 동기화 없이 접근하려는 현상이 race condition
- 그리고 이러한 문제를 해결하는 것 즉 서로가 알고있는 정보를 일치시키는 것을 동기화라고 한다.
- 임계영역(critical section)
- 임계영역이란 공유되는 자원에서 문제가 발생하지 않도록 독점을 보장해주는 영역을 뜻한다. 이러한 임계 영역을 잘 제어해야 동기화 문제를 제어할 수 있다. 임계영역에는 한 순간에 반드시 하나의 프로세스 또는 스레드만 진입이 가능하다. 즉, 공유 자원 독점을 통해 동기화를 유지할 수 있다.
- 동기화를 제공하는 방법
- Lock
- 의미 그대로 내가 자원을 사용하는 동안 다른 프로세스가 접근하지 못하도록 잠그는 방법
- 세마포어
- 세마포어는 신호등이라는 뜻, 두가지 연산으로 이루어져 있으며 임계영역의 사용이 끝났으면 사용이 끝난 프로세스가 대기중인 프로세스에게 사용이 끝났다는 사실을 알려주는 방식 → 무한반복을 사용하지 않아서 cpu 리소스를 줄여준다
- 세마포어는 정수 값을 가지는 변수로 볼 수 있다. 이 정수 값은 접근할 수 있는 최대 허용치 만큼 동시에 사용자가 접근할 수 있다.
- 정리잘해놓은 곳 - https://rebro.kr/176
- Lock
- 동기화란?
인터럽트
- 조교님께 인터럽트에 관하여 질문
안녕하세요, 인터럽트에 대해 질문이 있습니다. 예를 들어 I/O 이벤트가 발생하면 CPU가 입출력관리자에게 입출력 명령을 보내고 입출력 관리자가 명령 받은 데이터를 메모리에 가져다놓거나 메모리에 있는 데이터를 저장 장치로 옮기고 데이터 전송이 완료되면 CPU에게 신호를 보내는 것이 인터럽트 방식의 동작 과정이고 이 신호가 인터럽트라고 알고있습니다. 인터럽트가 발생하면, CPU는 수행중이던 task를 잠시 멈추고, IVT(interrupt vector table)에서 발생한 인터럽트의 종류를 파악한 뒤 실행하던 task 정보를 TCB에 저장하고 수행할 ISR(interrupt service routine)으로 포인터를 따라 가서 인터럽트 처리가 끝난다면 task 우선순위를 따져서 task를 restore 시킨다고 이해했고 restore해서 return하는 이 시점이 context switching이라고 이해했습니다. 일단 제가 이해한 이 흐름이 맞는지 궁금하고, 제가 이해한 것이 맞다면 인터럽트 발생 시점은 입출력 관리자가 CPU에게 받았던 명령을 다 수행하고 신호를 보낼때라고 이해하면 되는지 궁금합니다. I/O가 이벤트가 발생해서 CPU가 입출력 관리자에게 입출력 명령을 보내는 시점부터가 인터럽트 방식의 동작과정이라고 제가 보는 책에 나와있는데 그럼 저 시점부터 인터럽트가 발생했다고 봐야하는 것인지 헷갈려서 질문드립니다.
- 답변
말씀하신 흐름이 정확합니다. 보다 자세한 이해를 위해 PintOS에서 Disk I/O가 처리되는 과정을 예시로 설명 드리겠습니다.
devices/disk.c의disk_read또는disk_write함수에 의해 disk 장치에게 pio command issue (link)- 이후 cpu는 semaphore를 이용해 disk 작업 완료시 까지 대기 (link)
- disk는 cpu로 부터 요청받은 작업을 완료 후 cpu에게 interrupt issue
- disk I/O의 ISR (
devices/disk.c의interrupt_handler)에서 작업 완료를 확인 후 disk에게 ack 수행 & semaphore up (link)- cpu는 전송된 데이터와 함께 disk I/O 루틴 exit
말씀드린 1~5 과정이
인터럽트 방식의 I/O 처리이고, 3 과정에서 disk에 의해 발생한 event가인터럽트라고 이해하시면 될 것 같습니다.책에서 1 과정을 포함한 1~5 과정을 전부인터럽트 방식의 동작과정이라고 표현한 것은, 단순히 인터럽트 방식이 아닌 다른 방식으로 동작하는 I/O (PIO, polling, etc...)와 구별하기 위한 의도라고 추측됩니다.
- 질문
조교님 말씀과 코치님의 조언을 듣고 흐름을 다시 정리해보았습니다. 외부(hardware) 인터럽트가 발생할 때 CPU는 인터럽트 종류를 파악 후 task 정보를 TCB에 저장을 하고 그 후엔 커널에 존재하는 "인터럽트 핸들러(혹은 ISR)"가 인터럽트 처리를 하고, 우선순위를 따져서 task를 restore해서 return 하는 순간 context switching이 일어난다 라고 이해를 했습니다. 또, 답변주신 5번의 내용은 sema_up이 될 때 context switching이 일어나는 것이 아니고 disk I/O 루틴이 종료되면서 context switching이 일어나는 것이며 그 말은 즉, 인터럽트 핸들러는 context switching 되기까지 관여하고 있고 그래서 context switching은 하드웨어(CPU)가 아닌 커널에 있는 인터럽트 핸들러가 하는 것이라고 이해하면 될까요?
- 답변
넵 맞습니다.
threads/intr-stubs.S의intr_entry루틴에서 TCB에 task context 저장 후intr_handler를 통한 ISR 호출, ISR 완료 후 본래 context restore,iretqinstruction을 사용하여 interrupt context에서 본래 실행되고 있던 program의 context로의 context switch를 순차적으로 수행하는 것을 확인할 수 있습니다.첨언드리자면,
하드웨어(CPU)가 아닌 커널에 있는 인터럽트 핸들러가 하는 것이라는 설명은 다소 오류가 있습니다. interrupt context에서의 복귀는 CPU가 앞서 말씀드린 특정 instructioniretq를 실행하면서 수행되기 때문입니다.
- 인터럽트 발생 시
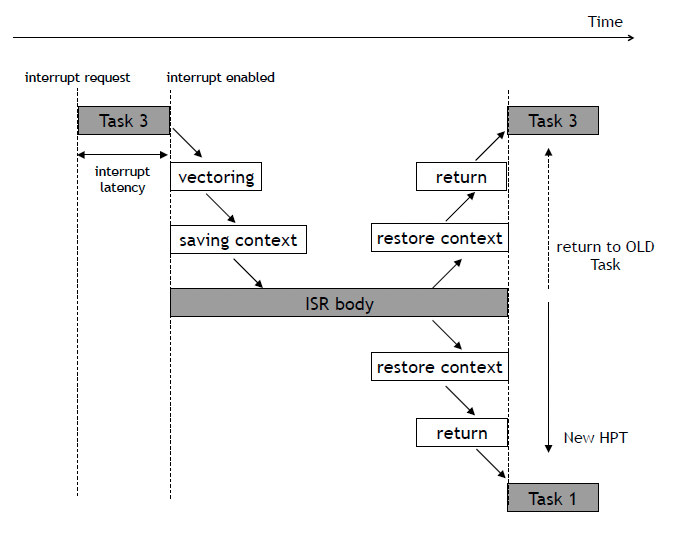
- 정리
- cpu는 인터럽트 발생 시 커널모드로 바뀜 → 어떤 인터럽트인지 인터럽트 벡터 테이블에서 확인하고 ISR 주소값 얻음 → task정보 TCB(커널에있는)에 저장(대피) → ISR호출 → ISR 완료후 본래 context restore → ISR의 끝에 IRET 명령어에 의해 인터럽트가 해제되고 명령어가 실행되면 본래실행 되고 있던(대피 시켰던) PC값을 이전 실행 위치로 복원함(인터럽트 context에서 본래 실행 되고 있던 program context로 context switch가 이루어짐)
다중 큐(multiple-queue)
- 준비 상태의 다중 큐
- CPU 스케줄러는 모든 프로세스 제어블록(PCB)을 뒤져서 가장 높은 우선순위의 프로세스에 CPU를 할당한다. → BUT 매번 모든 프로세스 제어블록을 검색하는 것은 번거로운 일
- 프로세스는 준비 상태에 들어올 때마다 자신의 우선순위에 해당하는 큐의 마지막(tail)에 삽입된다.
- 프로세스의 우선순위를 배정하는 방식
- 고정 우선순위 방식 : 운영체제가 프로세스에 우선순위를 부여하면 프로세스가 끝날 때까지 바뀌지 않는 방식 → 구현은 쉽지만, 시스템의 상황이 시시각각 변하는데 우선순위를 고정하면 시스템의 변화에 대응하기 어려워 작업 효율이 떨어짐
- 변동 우선순위 방식 : 프로세스 생성 시 부여받은 우선순위가 프로세스 작업 중간에 변하는 방식 → 구현하기 어렵지만 시스템 효율을 높일 수 있음
- 변동 우선순위 방식 예
- 우선순위가 낮은 프로세스 P1이 중요한 자원을 사용하고 있다
- 자원을 독점하고 있기에 이 자원을 사용하려는 다른 프로세스들은 P1이 작업 마칠 때까지 기다려야함
- 이때 프로세스 P1의 우선순위를 높이면 다른 프로세스보다 CPU를 더 자주 할당받게 되어 작업을 빨리 끝낼 수 있고, 그럼으로써 자원을 기다리던 다른 프로세스의 작업도 원할하게 진행됨
뭔가 이번주는 정리를 뒤죽박죽한것 같다. 키워드 위주로 공부하다보니 하나 하나는 아는데 흐름이 이어지지가 않았다. 그래서 하루는 하루종일 운영체제 책만 주구장창 파보기도 하고, 코드부터 보고 공부해보기도하고 OS 첫 주라 시행착오를 많이 겪은거 같다. priority donation을 하루 남기고 끝내서 advanced scheduler은 구현을 못할 것 같았지만 하는데까지 해보자 했는데 개념 공부 중 인터럽트에 막혀서 마지막 날을 쏟았다. 시간이 오래걸려도 이해를 해서 뿌듯했지만 그것도 잠시.. 큰 흐름만 이해한것이지 모든 것을 이해한게 아니었다. 결국 advanced scheduler는 하지 못했다.. pintos 너무 어렵다.. 으아아아아아 최고보단 최선을 다해야겠다..!!
WEEK08 과제 구현 소스 코드 - https://github.com/SWJungle4A/pintos12-team04/tree/yeopto/priority-scheduling
