API 개발 고급 - 컬렉션 조회 최적화 (xToMany)
주문 조회 V1
엔티티 직접 노출
- 비추
- orderItem, member, delivery 강제 초기화
주문 조회 V2
DTO
com.fasterxml.jackson.databind.exc.InvalidDefinitionException: No serializer found for class jpashop.api.OrderApiController$OrderDto and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS) (through reference chain: java.util.ArrayList[0])
getter 정의 해야 함
- orderDto의 orderItem은 프록시가 불러와진다.

order.getOrderItems().stream().forEach(o -> o.getItem().getName());
엔티티 강제 초기화 - Dto로 반환할 때는 Dto 안에 Entity가 있으면 안 된다. Entity와 완전히 의존을 끊어야 함. 여기서는 orderItem도 Dto로 바꿔서 반환해야 한다.
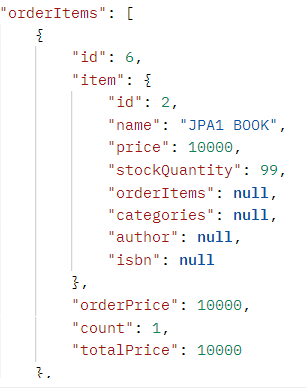

- 껍데기만 Dto로 하는게 아니라, 속에도 다 Dto로 바꾸자!
- 페이징 불가능
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
- 페치 조인을 썼는데 페이징 처리를 할거면 메모리에서 할거다.. 라는 경고
- 왜냐? 페치조인을 하면 일대다 관계는 뻥튀기 된 결과가 나오기 때문에 페이징 자체가 불가능하다.
- 메모리에서 페이징하는건 정말 매우 위험! - 컬렉션 페치조인을 1개 이상 사용하면 일대다대다 관계가 되므로 1개만 사용하자.
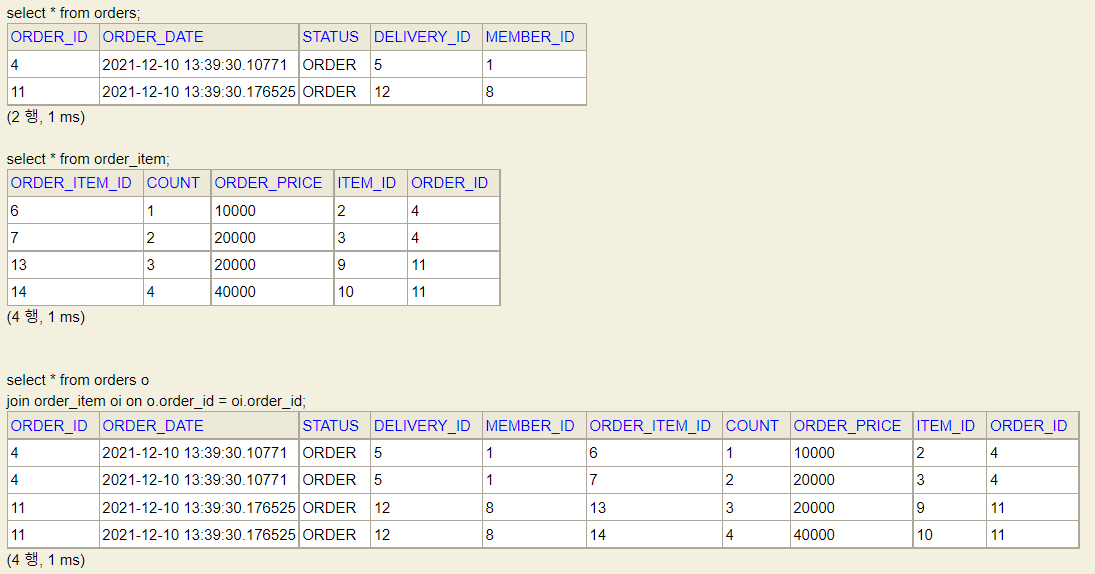
쿼리 순서
order 조회 (2개)
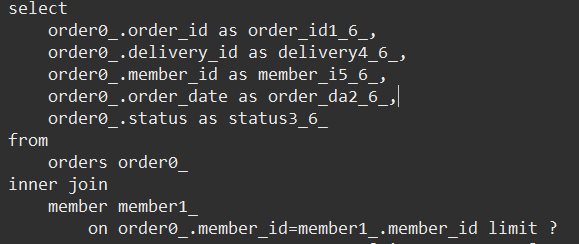
member 조회 (2번)
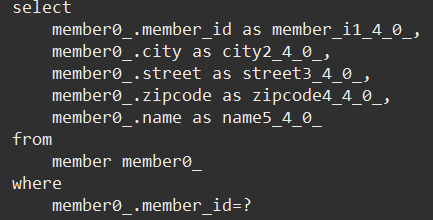
delivery 조회 (2번)
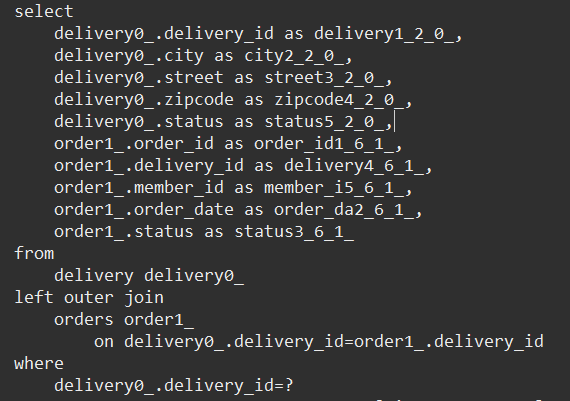
orderItem 조회 (4개)
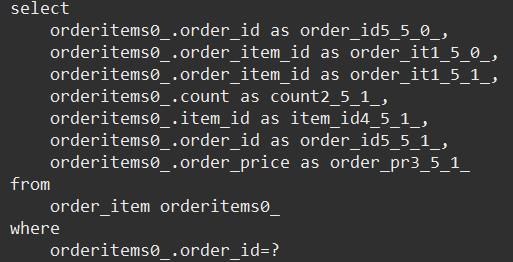
item 조회 (4개)
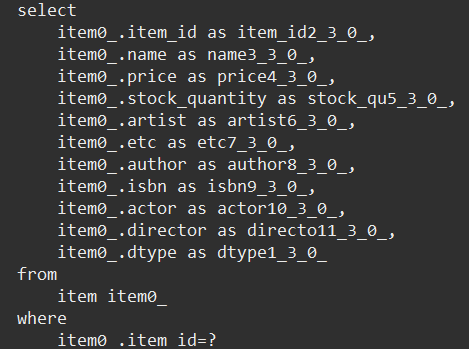
쿼리 결과
order 2개, orderitem 4개가 join 되어 결과는 4개 행이 나온다.
-
db
-
log
[
{
"orderId": 4,
"name": "userA",
"orderDate": "2021-12-10T14:32:49.804183",
"orderStatus": "ORDER",
"address": {
"city": "서울",
"street": "1",
"zipcode": "1111"
},
"orderItems": [
{
"itemName": "JPA1 BOOK",
"orderPrice": 10000,
"count": 1
},
{
"itemName": "JPA2 BOOK",
"orderPrice": 20000,
"count": 2
}
]
},
{
"orderId": 4,
"name": "userA",
"orderDate": "2021-12-10T14:32:49.804183",
"orderStatus": "ORDER",
"address": {
"city": "서울",
"street": "1",
"zipcode": "1111"
},
"orderItems": [
{
"itemName": "JPA1 BOOK",
"orderPrice": 10000,
"count": 1
},
{
"itemName": "JPA2 BOOK",
"orderPrice": 20000,
"count": 2
}
]
},
{
"orderId": 11,
"name": "userB",
"orderDate": "2021-12-10T14:32:49.866278",
"orderStatus": "ORDER",
"address": {
"city": "부산",
"street": "1",
"zipcode": "1111"
},
"orderItems": [
{
"itemName": "SPRING1 BOOK",
"orderPrice": 20000,
"count": 3
},
{
"itemName": "SPRING2 BOOK",
"orderPrice": 40000,
"count": 4
}
]
},
{
"orderId": 11,
"name": "userB",
"orderDate": "2021-12-10T14:32:49.866278",
"orderStatus": "ORDER",
"address": {
"city": "부산",
"street": "1",
"zipcode": "1111"
},
"orderItems": [
{
"itemName": "SPRING1 BOOK",
"orderPrice": 20000,
"count": 3
},
{
"itemName": "SPRING2 BOOK",
"orderPrice": 40000,
"count": 4
}
]
}
]심지어 order는 중복되어 나온다. (참조값도 같음)
- distinct는 보통 중복을 제거하는데 쓰이지만 완전히 같아야 먹히므로 효과를 기대할 순 없다.
- 하지만 JPA에서는 id 값을 참조하여 중복을 제거하기 때문에 효과가 있다.
주문 조회 V3.1 - 페이징 해결
한계 극복
1. 먼저 ToOne 관계는 모두 페치조인한다. ToOne 관계는 페이징 쿼리에 영향을 주지 않기 때문에
2. 컬렉션은 모두 지연 로딩으로 조회한다.
3. 지연 로딩 성능 최적화를 한다.
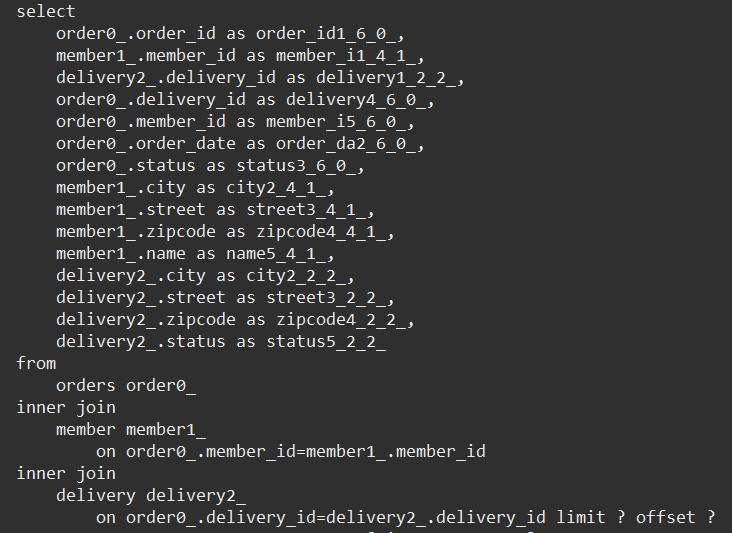
ToOne
fetch join + paging
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_page(
@RequestParam(value = "offset", defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue = "100") int limit) {
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);
List<OrderDto> collect = orders.stream()
.map(o -> new OrderDto(o))
.collect(Collectors.toList());
return collect;
}
'in' query
- application.yml에 다음 추가 (global)
jpa.properties.hibernate.default_batch_Fetch_size- 1000개가 최대임
- 결국 전체 데이터를 가져오는 것이기 때문에 메모리 사용량은 size에 상관없이 같다!
- 'in' query의 갯수 설정하는 것.
- orderItem 2개 한꺼번에 가져옴
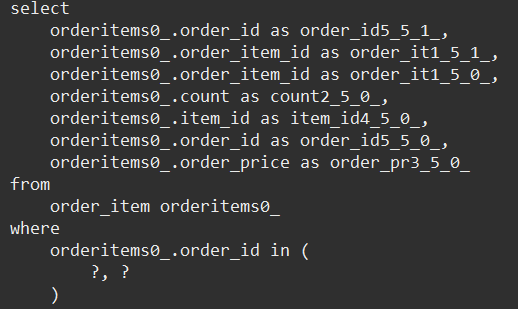
- item 4개 한꺼번에 가져옴
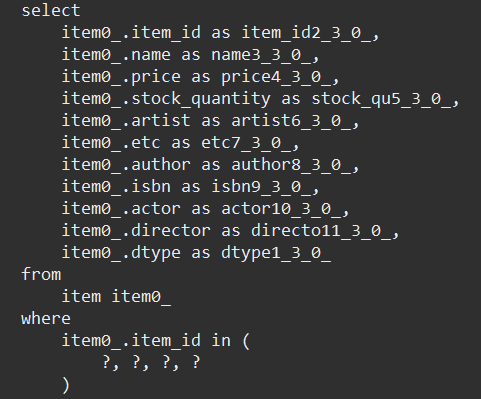
- detail하게 추가
- collection : 변수 위에 @BatchSize
- 그 밖 : 클래스 위에 @BatchSize
주문 조회 V4
JPA에서 DTO 직접 조회
OrderApiController의 OrderDto를 참조 안하는 이유
- repository가 controller를 참조하는 관계가 순환이 된다.
- repository가 dto를 알아야 하니까 같은 패키지에 만들어 준다.
orderItems
- jpql의 new 명령어에서 컬렉션을 바로 넣을 수 없다.
- 1:N의 N 부분을 해결하기 위해 orderItem을 가져오는 쿼리를 따로 만들고 Dto의 orderItem에 쿼리 결과를 반복문을 통해 넣는다.
- Order 조회(orderItem 빈 값) > orderId로 해당 order의 orderItems 조회 > order에 조회한 orderItems 채움
- ToMany 관계는 최적화하기 어려우므로 findOrderItems 같은 별도의 메서드로 조회한다.
쿼리 결과
- findOrders > query 1번 > 2개(N) 조회
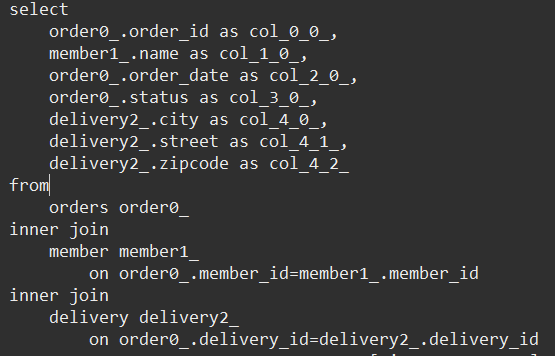
- findORderItems > query 2번(N)
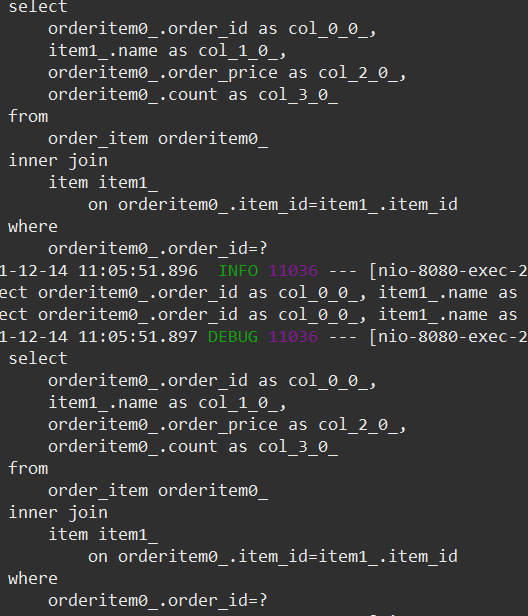
- 1 + N 문제 발생
주문 조회 V5
컬렉션 조회 최적화
과정
- 모든 order 조회 query (result)
- result의 값들을 꺼내며 해당 order의 id만 모아서 orderIds 생성
- orderIds에 있는 id를 가진 orderItem을 조회하는 query (orderItems)
- list를 map으로 바꾸어 최적화 (key는 orderId, value는 List<orderItemQueryDto>)
- result의 order에 orderitem 채우기
차이
- v4는 반복문을 돌 때마다 query 발생
- 이거는 query 한 번으로 다 가져와서 반복문 돌며 메모리에서 매칭해줌 (O(1))
orderItems
- where 절에서 '=' 대신 'in' 명령어 사용
쿼리 결과
- 모든 order 조회
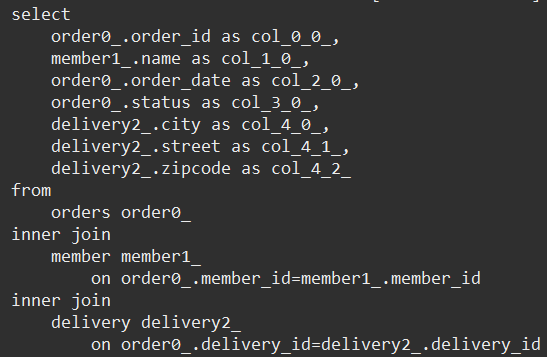
- orderitem 조회
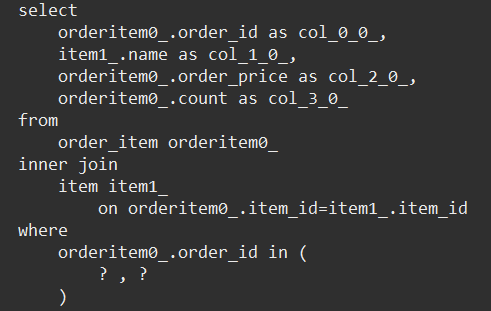
주문 조회 V6
플랫 데이터 최적화
쿼리 결과
- 모든 테이블 1번에 조회
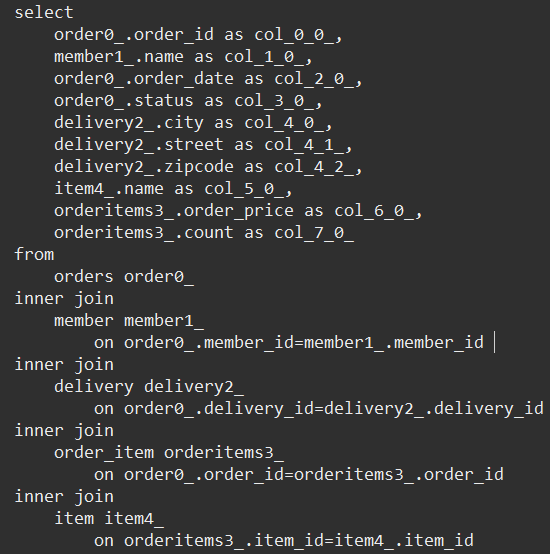
특징
- flatDto를 queryDto로 변환하는 작업이 필요하다.
- 쿼리는 한 번이지만 중복되는 데이터가 많아 느릴 수도 있다.
- order를 기준으로 페이징이 불가능하다.
정리
권장
- 엔티티 조회 방식으로 우선 접근
- 페치 조인으로 쿼리 수 최적화
- 컬렉션 : 페이징 필요시 fetch_size, 필요없으면 그냥 페치 조인
- 엔티티 조회 방식으로 해결 안되면 DTO 방식 사용
- DTO도 안되면 NativeSQL or 스프링 jdbc
차이
- 엔티티를 이용하면 코드를 거의 수정하지 않고 옵션만 약간 변경해서 성능 최적화 시도 가능
- DTO는 성능 최적화할 때 코드 변경이 많음
- 솔직히 페치 조인만으로도 거의 모든 해결이 가능하다. 페치 조인이 안되면 캐시로 해결하는게 국룰 (캐시 사용할거면 DTO 사용)
