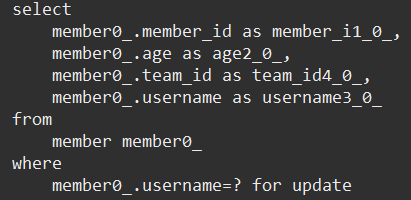
메소드 이름으로 쿼리 생성
- 이름이 'A' 이고 나이가 15 이상인 사람을 조회하는 메소드
- repository 에서 findByUsernameAndAgeGreaterThen(String username, int age) 메소드 선언
- 쿼리 결과
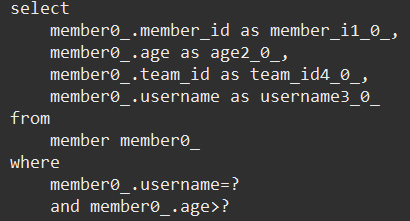
- 메소드 종류 확인
작성
- 조회 : find_By / get_By / read_By / query_By
- 카운트 : count_By (long)
- 존재여부 : exists_By (boolean)
- 삭제 : delete_By (long)
- 중복제거 : find_DistinctBy
- 제한 : findFirst3 / findFirst / fintTop3 / findTop
주의
- 엔티티의 필드명이 변경되면 인터페이스에 정의한 메소드 이름도 꼭 변경해야 한다.
- 그렇지 않을 경우 애플리케이션 시작 시점에 오류가 발생하는데, 이것 또한 장점이다.
NamedQuery
작성
-
엔티티에 어노테이션으로 작성 : @NamedQuery(name=, query=)
-
레포지토리 메소드에 @Query(name=) 선언하면 스프링 데이터 jpa가 편리하게 불러옴
-
@Query 어노테이션이 없다면 '엔티티명.메소드명' 으로 된 네임드 쿼리를 찾고, 없으면 메소드 이름으로 쿼리를 생성한다.
-
쿼리에 파라미터가 있다면 @Param으로 파라미터 설정
장점
- 애플리케이션 로딩 시점에 엔티티에 정의된 네임드 쿼리를 파싱해보고 에러를 잡을 수 있다.
@Query - 레포지토리 메소드
- 메소드 이름 쿼리는 파라미터가 많아지면 메소드 이름이 너무 길어진다.
- 이럴 경우 직접 쿼리를 정의하는게 나음
작성
@Query("select m from Member m where m.username = :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);- 레포지토리 메소드에 @Query 어노테이션 선언 후 쿼리 작성
@Query - 값, DTO 조회
값
@Query("select m.username from Member m")
List<String> findUsernameList();DTO
@Query("select new study.pr3springdatajpa.dto.MemberDto(m.id, m.username, t.name) from Member m join m.team t")
List<MemberDto> findMemberDto();- new 생성자 사용
파라미터 바인딩
위치 기반
select m from Member m where m.username :?0- 코드 가독성, 유지보수를 위해 사용하지 않는다.
- 위치가 바뀌면 에러가 발생한다.
이름 기반
select m from Member m where m.username :username- @Param("username") String name
반환 타입
- 스프링 데이터 JPA는 반환 타입을 유연하게 사용하게 해준다.
- 반환 타입 참고
컬렉션
- 값이 없으면 크기가 0인 빈 컬렉션 반환
단건
- 값이 없으면
- JPA : NoResultException 발생
- Spring Data JPA : Null 반환
단건 Optional
-
값이 있을지 없을지 모른다면 사용
-
값이 없으면 Optional.empty 반환
-
orElseThrow 사용해서 값이 없을 경우 뭐할지 설정
-
값이 2개 이상이면 NonUniqueResultException이 터지고, 스프링 데이터 JPA가 IncorrectResultSizeDataAccessException으로 바꿔서 반환
-
레포지토리는 JPA나 MongoDB일 수 있다. 이걸 사용하는 서비스 계층의 클라이언트 코드들이 JPA에 의존하는게 아니라 스프링이 추상화한 예외에 의존하게 된다면, 레포지토리를 다른 기술로 바꿔도 JPA가 아닌 스프링에 의존하기 때문에 코드를 바꿀 필요가 없다.
페이징과 정렬
JPA
- DB 방언이 바뀌어도 setFirstResult나 setMaxResults 등은 바뀌지 않는다.
Spring Data JPA
인터페이스 표준화
org.springframework.data.domain.Sort
org.springframework.data.domain.Pageable반환 타입
org.springframework.data.domain.Page - count 쿼리 포함
org.springframework.data.domain.Slice - count 쿼리 X, limit+1 조회 (페이지가 아닌 더보기 기능)TotalElements()
- DB의 모든 데이터를 count해야하기 때문에 성능이 느리다.
- 예를 들어 join을 하는 경우 조회에서 join을 하는데 count에서도 join을 하므로 성능이 느려진다.
- @Query에서 count 쿼리를 직접 정의하여 성능 최적화 가능
DTO 반환
- page.map 사용
벌크성 수정 쿼리
JPA
- JPQL로 update 쿼리 작성
- .executeUpdate()
Spring Data JPA
- @Modifying : executeUpdate를 호출할 수 있도록 하는 어노테이션
- update 쿼리인데 @Modifying 안하면 에러
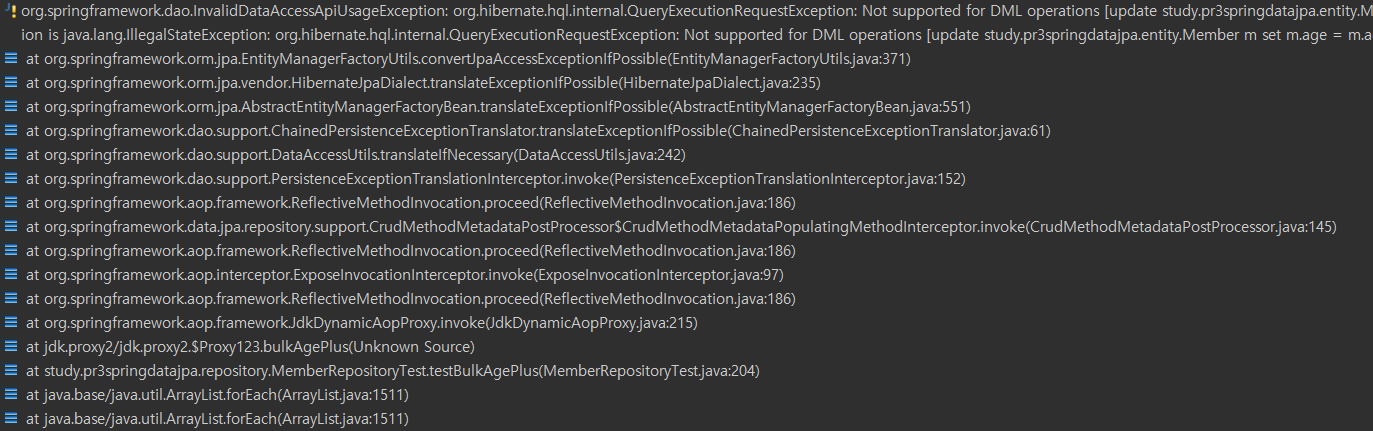
- update 쿼리인데 @Modifying 안하면 에러
주의
-
벌크 연산은 JPA가 관리하는 영속성 컨텍스트를 무시하고 DB에 쿼리를 날린다.
-
영속성 컨텍스트는 벌크 연산이 일어난 것을 모르기 때문에 벌크 연산 이후에는 영속성 컨텍스트를 초기화해야 한다.
- em.flush() + em.clear()
- @Modifying(clearAutomatically = true)
-
제일 깔끔한 상황은 영속성 컨텍스트 없이 벌크 연산만 하고 빠져나오는 것
@EntityGraph
- @Query 어노테이션과 같이 사용하거나 단독으로 사용가능
JPA
@Query("select m from Member m left join m.team")
List<Member> findMemberFetchJoin();Spring Data JPA
@Override
@EntityGraph(attributePaths = "team")
List<Member> findAll();JPA Hint & Lock
JPA Hint
-
JPA 구현체(Hibernate)에게 제공하는 쿼리 힌트
-
구현체가 JPA 표준(인터페이스의 모음)을 사용할 수 있도록 한다.
-
ex) 변경감지
- 변경감지를 위해서는 원본이 있어야하므로 객체를 2개 관리 -> 메모리를 차지하기 때문에 비효율적
- 변경 안할거고 단순 조회만 하고싶은데, 객체를 가지고 오는 순간 2개를 만들어 놓는다.
- 단순 조회에 최적화된 기능은 Hibernate에서는 제공하는데, JPA 표준은 제공하지 않는다.
-
@QueryHints를 사용하면 최적화가 되긴 하지만, 성능 변화는 크지 않다.
@QueryHints(value = @QueryHint())
- name : 패키지
ex) org.hibernate.readOnly - value :
true, false
Lock
- select for update
- 다른 트랜잭션이 건들지 못하도록 lock 거는 것
- 실시간 트래픽이 많은 서비스는 가급적 사용X
@Lock
- LockModeType
- 패키지 : javax.persistence (JPA)