
5.6 규제 선형 모델 - 릿지, 라쏘, 엘라스틱넷
규제 선형 모델의 개요
비용함수는 RSS 최소화 방법과 과적합 방지를 위해 회귀계수 크기를 제어하는 방법이 균형을 이루어야 함
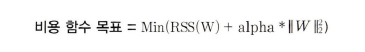
alpha: 학습 데이터 적합 정도와 회귀 계수 값의 크기 제어를 수행하는 튜닝 파라미터
- alpha=0(or 매우 작은 값): Min(RSS(w)) -> RSS 최소화 -> w 값이 커져도 어느 정도 상쇄 가능하여 적합 개선
- alpha=무한대(or 매우 큰 값): Min(RSS(w)+alpha*||w||2) -> w 최소화 -> 과적합 개선
규제
: 비용함수에 alpha 값으로 패널티를 부여해 회귀 계수 값의 크기를 감소시켜 과적합을 개선하는 방식
- L2 규제: alpha*||w||2 (w제곱에 패널티)=> 릿지 회귀
- L1 규제: alpha*||w||1 (w 절댓값에 패널티) => 라쏘 회귀(영향력이 크지 않은 회귀 계수 값을 0으로 변환)
릿지 회귀
- 파라미터: alpha: L2 규제 계수
# alpha 파라미터의 값 리스트
alphas = [0 , 0.1 , 1 , 10 , 100]
# alphas list 값을 iteration하면서 alpha에 따른 평균 rmse 구함.
for alpha in alphas :
ridge = Ridge(alpha = alpha)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5) # rmse로 평가
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores)) # 5-fold rmse 평균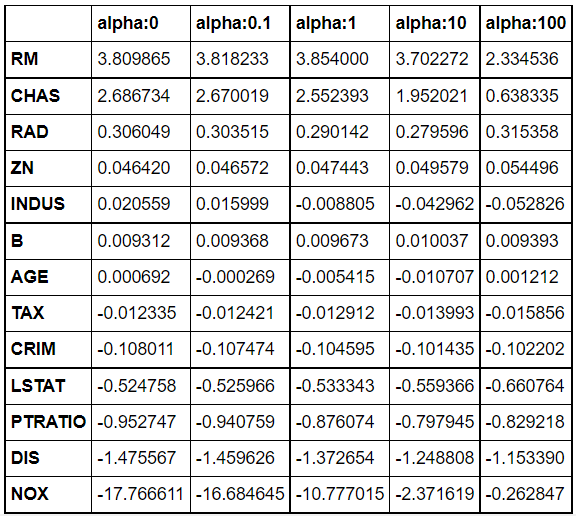
알파값이 커짐에 따라 회귀 계수들이 감소함. 하지만, 회귀 계수를 0으로 만들지는 않음,
라쏘 회귀
- 파라미터: alpha: L1 규제 계수
- L2 규제와 달리, L1 규제는 불필요한 회귀 계수를 급격하게 감소시켜 0으로 만들고 제거함. => 변수 선택의 특성
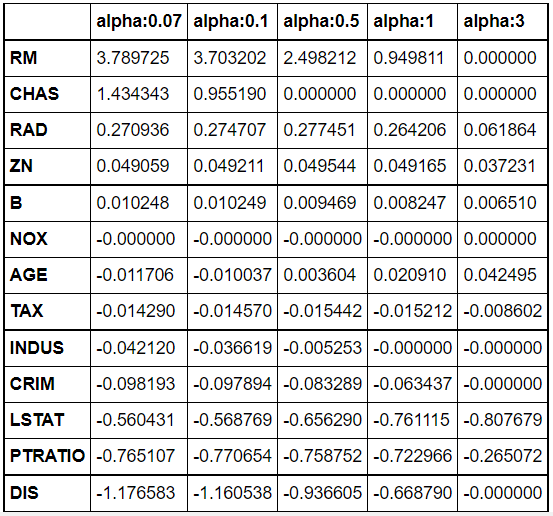
CHAS, NOX, INDUS, CRIM, DIS 변수 0으로 수렴함
엘라스틱넷 회귀
: L1, L2 규제 결합한 회귀. RSS(w) + alpha||w||2 + alpha||w||1 최소화.
- 라쏘 회귀가 서로 상관관게가 높은 피처들 중 중요 피처만을 선택하고 다른 피처들의 회귀 계수를 0으로 만드는 성향을 가져 alpha 값에 따라 회귀 계수 값이 급격히 변동할 수 있다는 단점을 완화하기 위함
- but, 수행시간이 상대적으로 오래 걸림
- 파라미터: alpha, l1_ratio
- alpha: (a+b)값. a: L1 규제 alpha값 / b: L2 규제 alpha 값
- l1_ratio = a/(a+b)
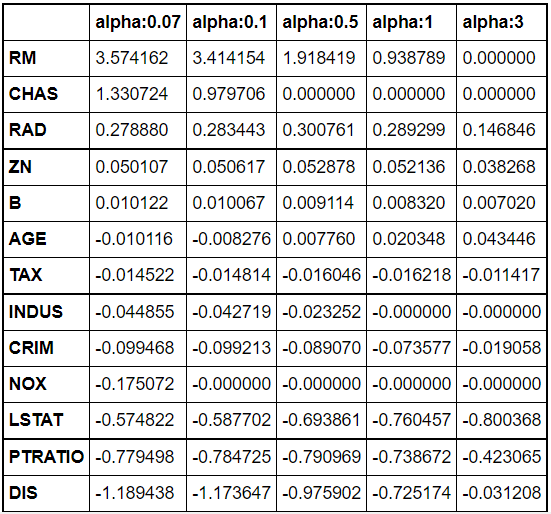
라쏘보다는 상대적으로 0이 되는 값이 적음
# 회귀 모델에 따른 회귀 계수 추정
def get_linear_reg_eval(model_name, params=None, X_data_n=None, y_target_n=None,
verbose=True, return_coeff=True):
coeff_df = pd.DataFrame()
if verbose : print('####### ', model_name , '#######')
for param in params:
if model_name =='Ridge': model = Ridge(alpha=param) # 릿지 휘귀
elif model_name =='Lasso': model = Lasso(alpha=param) # 라쏘 회귀
elif model_name =='ElasticNet': model = ElasticNet(alpha=param, l1_ratio=0.7) # 엘라스틱넷
neg_mse_scores = cross_val_score(model, X_data_n,
y_target_n, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores)) # 5-fold 평균 rmse
print('alpha {0}일 때 5 폴드 세트의 평균 RMSE: {1:.3f} '.format(param, avg_rmse))
# cross_val_score는 evaluation metric만 반환하므로 모델을 다시 학습하여 회귀 계수 추출
model.fit(X_data_n , y_target_n)
if return_coeff:
coeff = pd.Series(data=model.coef_ , index=X_data_n.columns )
colname='alpha:'+str(param)
coeff_df[colname] = coeff
return coeff_df** 선형 회귀의 경우 최적 하이퍼 파라미터를 찾아내는 것 못지 않게 먼저 데이터 분포도의 정규화와 인코딩 방법이 매우 중요
선형 회귀 모델을 위한 데이터 변환
- 피처와 타깃값 간의 선형 관계 가정
- 피처값과 타깃값의 분포가 정규분포를 따른다고 가정 -> 데이터가 심하게 왜곡되었을 경우, 스케일링 및 정규화 수행 필요
- StandardScaler() 표준화, MinMaxScaler 정규화 -> 예측 성능 향상 기대하기 어려움
- 1을 통해 예측 성능에 향상이 없을 경우, 스케일링/정규화를 수행한 데이터 세트에 다시 다항 특성을 적용하여 반환
-> 과적합 문제 발생 가능 - log 변환: 가장 많이 사용되는 방법. 타깃값은 일반적으로 로그 변환 선호(원본 타깃값으로 변환 가능하도록)
# 데이터 스케일링 함수
def get_scaled_data(method='None', p_degree=None, input_data=None):
if method == 'Standard':
scaled_data = StandardScaler().fit_transform(input_data) # 표준화
elif method == 'MinMax':
scaled_data = MinMaxScaler().fit_transform(input_data) # 정규화
elif method == 'Log':
scaled_data = np.log1p(input_data) # 로그변환
else:
scaled_data = input_data
if p_degree != None:
scaled_data = PolynomialFeatures(degree=p_degree,
include_bias=False).fit_transform(scaled_data) # 다항식
return scaled_data5.7 로지스틱 회귀
: 선형 회귀 방식을 분류에 적용한 알고리즘
- 가볍고 빠름
- 이진 분류 예측 성능 뛰어남
- 희소한 데이터 세트 분류에도 뛰어난 성능 -> 텍스트 분류에 자주 사용
시그모이드 함수
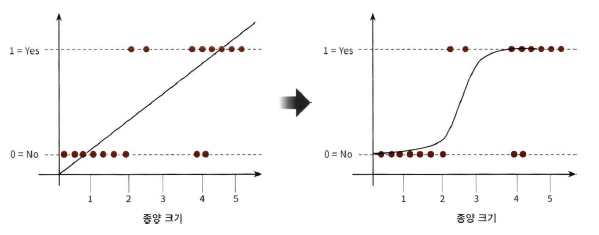
: 로지스틱 회귀는 선형 회귀와 달리 회귀 최적선을 찾는 것이 아닌, 시그모이드 함수 최적선을 찾고, 이 함수의 반환값을 확률로 간주해 확률에 따라 분류 결정
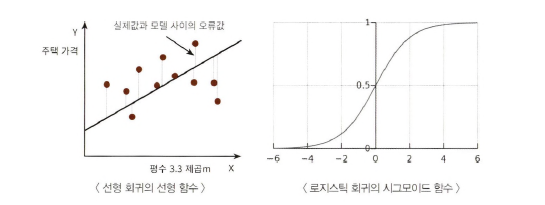
- x 값이 아무리 커지거나 작아져도 y 값은 항상 0~1 사이 값을 반환
LogisticRegression() 하이퍼 파라미터
- penalty: l1, l2(default='l2')
- C: 1/alpha. 값이 클수록 규제 강도 큼
ex. 종양 양성/음성 판단
lr_clf = LogisticRegression()
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf.predict(X_test)
# 하이퍼 파라미터 조정
params={'penalty':['l2', 'l1'],
'C':[0.01, 0.1, 1, 1, 5, 10]}
grid_clf = GridSearchCV(lr_clf, param_grid=params, scoring='accuracy', cv=3 )
grid_clf.fit(data_scaled, cancer.target)5.8 회귀 트리
: 트리 기반의 회귀. 회귀를 위한 트리를 생성하고 이를 기반으로 회귀 예측
- 분류 트리와 비슷
- 분류 트리: 레이블 결정
회귀 트리: 리프 노드에 속한 데이터 값의 평균값을 구해 회귀 예측값 계산
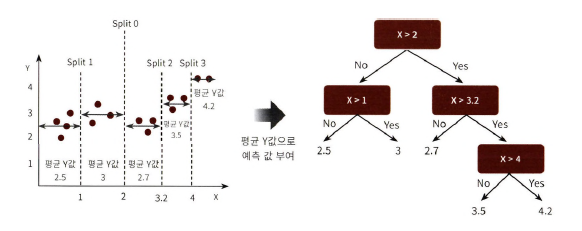
CART 알고리즘
: Classification And Regression Trees. 분류 뿐만 아니라 회귀도 가능하게 해주는 트리 생성 알고리즘

보스턴 주택 가격 예측
@
5.9 자전거 대여 수요 예측
@
5.10 캐글 주택 가격: 고급 회귀 기법
@

Data Analyst | Statistics