|| 문제설명 ||
-
수많은 마라톤 선수들이 마라톤에 참여하였는데 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였다.
-
완주하지 못한 선수의 이름을 return 하도록 solution 함수를 작성하라.
- participant : 마라톤에 참여한 선수들의 이름이 담긴 배열
- completion : 완주한 선수들의 이름이 담긴 배열
_ 마라톤 경기에 참여한 선수 : 1명 이상 100,000명 이하
_ completion의 길이 = (participant의 길이 - 1)
_ 참가자의 이름 : 1개 이상 20개 이하의 알파벳 소문자
- 동명이인 존재|| 문제해결과정 ||
- 중복 for문 사용
바깥쪽 for문(i) : participant의 처음 ~ 끝
안 쪽 for문(j) : completion의 처음 ~ 끝
- if 문
같은 이름을 찾는다면 chk를 1로 바꾸고 break
chk가 0일때, answer에 해당 선수 이름 저장 및 answer 리턴
- completion에서 participant을 찾을 경우 해당 completion 제거|| 코드 ||
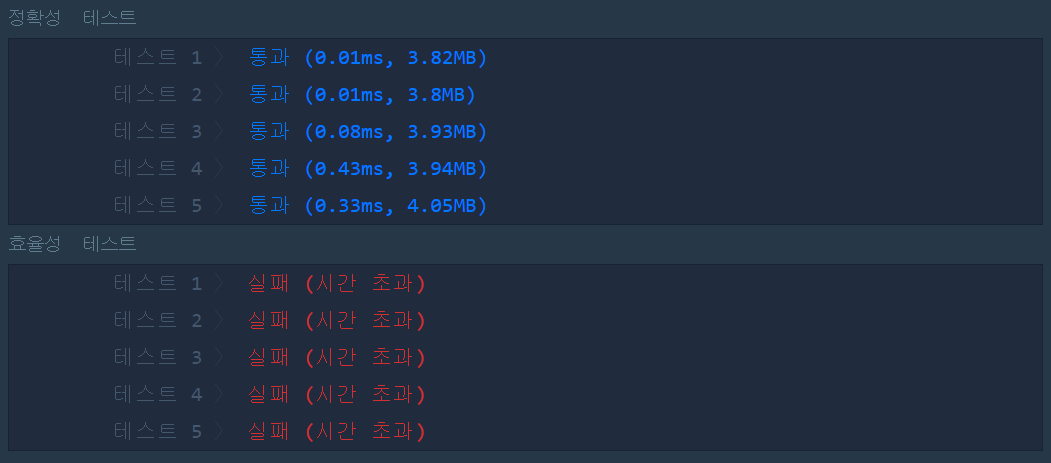
[2020.08.03] 실패
#include <string>
#include <vector>
using namespace std;
string solution(vector<string> participant, vector<string> completion) {
string answer = "";
int chk = 0;
for(auto i = participant.begin(); i != participant.end(); i++) {
for(auto j = completion.begin(); j != completion.end(); j++) {
if (*i == *j) {
chk = 1;
*j = "";
break;
}
}
if (!chk) {
answer = *i;
return answer;
}
chk = 0;
}
}
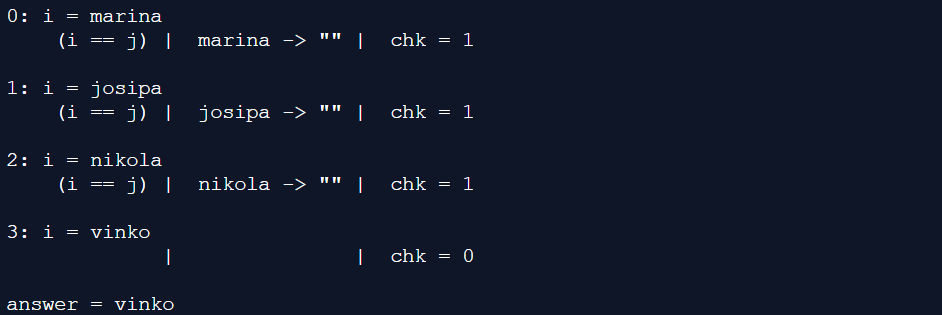
[실행과정]
[문제발견]
- 시간 초과 : 중복 for문(?)
주어진 매개변수의 길이가 최대 100,000이므로 길이가 길어질수록 중복 for문에 의해 처리해야 할게 급속도로 늘어남. 효율성이 매우 떨어진다.
→ 해시 알고리즘(속도 up)
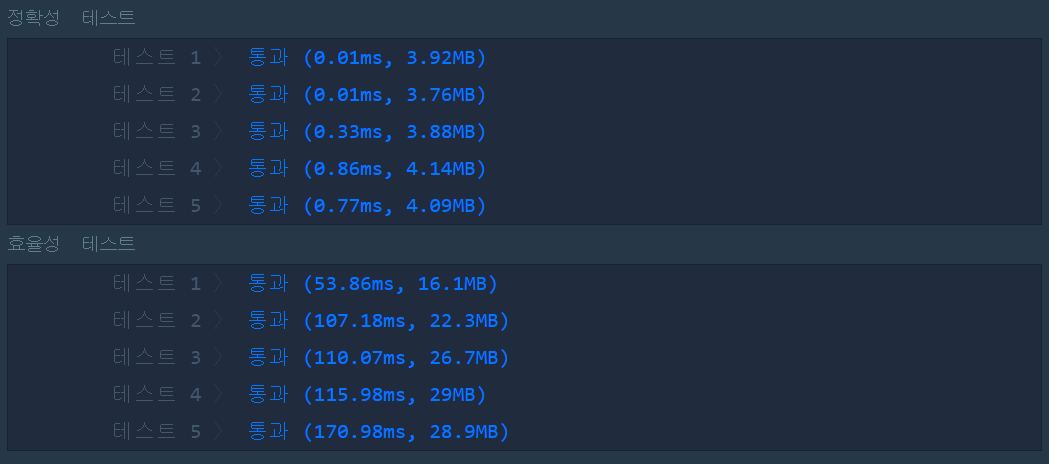
[2020.08.07] 성공
- 중복 for문 대신에 해시 사용
- map 헤더파일을 추가한 뒤에 <string, int>형 변수 추가
- 변수에 completion을 모두 추가하고, participant이 있는지 검사
- 찾을 경우: 해당 값의 value에 1을 제거(중복이 되는 값들 처리)
(value == 0)인 경우 해당 값 제거(erase)
- 찾지 못했을 경우: 해당 값 return#include <string>
#include <vector>
#include <map>
using namespace std;
string solution(vector<string> participant, vector<string> completion) {
string answer = "";
map<string, int> tmp;
for(auto i = completion.begin(); i != completion.end(); i++) {
if(tmp[*i] > 0) tmp[*i]++;
else tmp[*i]=1;
}
for(auto i = participant.begin(); i != participant.end(); i++) {
map<string, int>::iterator it = tmp.find(*i);
if(tmp.end() == it) return *i;
else if(tmp[*i] > 1) tmp[*i]--;
else {
tmp.erase(it);
}
}
}
[2021.01.23]
1) 정렬 후 처음부터 비교하며 다른 것을 리턴 : O(nlogn)#include <string>
#include <vector>
#include <algorithm>
using namespace std;
string solution(vector<string> participant, vector<string> completion) {
int answer = participant.size() - 1;
sort(participant.begin(), participant.end());
sort(completion.begin(), completion.end());
for(int i = 0; i < participant.size() - 1; i++) {
if(participant[i] != completion[i]) return participant[i];
}
return participant[answer];
}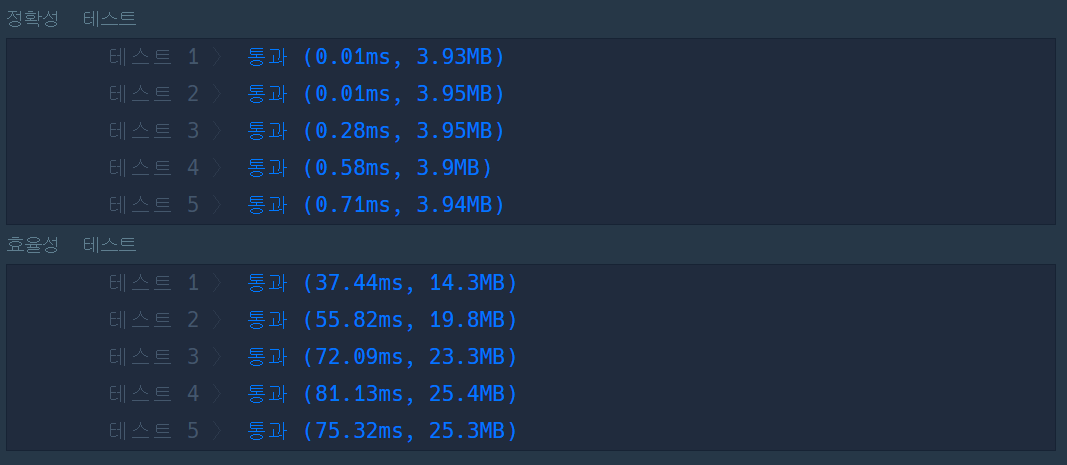
sort()는 quick sort기반의 최악의 경우(O(n^2))를 개선한 함수로 O(nlogn)의 시간복잡도를 가졌다. 이를 제외한다면 전체적인 코드는 O(n)의 시간복잡도를 가지기에 가장 효율적이다.
2) map을 활용하여 participant와 completion을 비교하여 나머지 하나 리턴 : O(nlogn)[2021.01.23]
#include <string>
#include <vector>
#include <map>
using namespace std;
string solution(vector<string> participant, vector<string> completion) {
string answer = "";
map<string, int> chk;
for(auto i : participant) {
chk[i]++;
}
for(auto i : completion) {
chk[i]--;
if(chk[i] == 0) chk.erase(i);
}
answer = chk.begin()->first;
return answer;
}
코드는 간단해졌지만 시간복잡도의 증가
예전 코드[2020.08.07]와 동일한 O(nlog)임에도 약 2배의 시간복잡도의 증가는 아마 map컨테이너의 erase에 있을 것 이라 추측
실제 map컨테이너의 삽입, 삭제, 탐색에 O(logn)만큼의 시간복잡도를 가지고 있기 때문에 n-1개의 요소를 삭제하기 위해 O(nlogn)만큼의 시간이 더 걸린다.
시간을 줄이기 위해서는 이전의 코드를 정리하거나 개선하는 방법처럼 erase()함수를 사용하지 않는 방법이 있다.
