
리액트를 다루고 공부하면서, 문득 이런 질문이 생겼습니다.
- virtual dom은 정확하게 어떻게 동작하는 것일까?
- virtual dom이 정확하게 뭐지?
- 도대체 virtual dom이 real dom보다 왜 성능이 더 좋은거지? 더 빠른거지? 이 말은 사실일까?
- 'virtual dom'의 어떤 부분이 real dom을 사용하는 것보다 성능을 더 좋게 만드는 것일까?
이 글은 저의 이런 의문점을 해결하기 위해서 탐구했던 과정을 기록한 글입니다. 탐구록이라고 할 수 있겠습니다. 저와 비슷한 고민을 가지고 계신 분들이 계시다면, 혹은 virtual dom에 대해서 더 깊게 파고 들어가 보기 원하시는 분들이라면 이 글을 읽고 함께 따라가보면 좋겠습니다.
그리고 제가 적은 글에 잘못된 내용이 있다면, 수정을 위한 댓글은 오히려 감사합니다.
먼저 Virtual dom의 의미를 파고들어가 보겠습니다.
Prerequisite :
본 글에서 언급되지만, 직접적으로 설명하지 않는 것들입니다.
- react functional component
- call stack
- event loop
- singly linked lisk
- recursive traverse
1.Virtual ?
솔직히 이 virtual이라는 단어부터 그렇게 익숙하지가 않습니다. 그래서 이것의 의미를 먼저 세세하게 따져볼 필요가 있습니다. 먼저 사전을 검색해 봤습니다.
네이버 :
1. [형용사] 사실상의, 거의 …과 다름없는
2. [형용사] (컴퓨터를 이용한) 가상의
구글 :
1.허상의
2.가상의
캠브리지 사전 :
created by computer technology and appearing to exist but not existing in the physical world
virtual의 사전적인 의미를 따져보니 이런 식으로 결론이 나는 것 같습니다. '실제로 존재하는 것은 아닌 것', 그치만 '실제와 거의 유사한 것', '컴퓨터로 구현된 사실과 거의 비슷한 것'
그러면 이런 질문으로 이어집니다. "실제로 존재하는 무언가를 컴퓨터를 통해서 허상으로 만들어 냈다는 것인데, 어떤 '실재'를 가상으로 구현한 것이지?"
뭐..dom 이겠죠?
2.Dom?
virtual dom은 dom이라는 녀석을 허상의 방식으로 만들어냈다는 의미가 될 것 같습니다. 'dom이라는 녀석은 실제로 존재하는 녀석인데, 이것의 가짜 버전인 virtual dom을 만들어냈다.' 그러면 또 질문이 이어집니다. dom이란 무엇인가?
1)Dom이 뭐냐 :
DOM(Document Object Model) 문서 객체 모델 이라는 의미를 가지고 있는 Dom. 이것이 무엇을 의미하는지는 조금만 검색하면 나옵니다.
2)Dom이 왜 필요하냐 :
DOM은 브라우저 상에서 자바스크립트가 HTML 문서를 조작하기 위한 API입니다. 자바스크립트가 직접 HTML을 동적으로 바꾸는데에는 한계가 있으니 JS가 조작하기 편하게 DOM이라는 형태로 바꾸어 놓은 것입니다. 왜 굳이 JS가 HTML을 조작해야할까요? 더 다양하고 복잡한 인터렉션을 만들고 화면을 구현하기 위해서 필요합니다.
3)Dom 어디서부터 왔냐 :
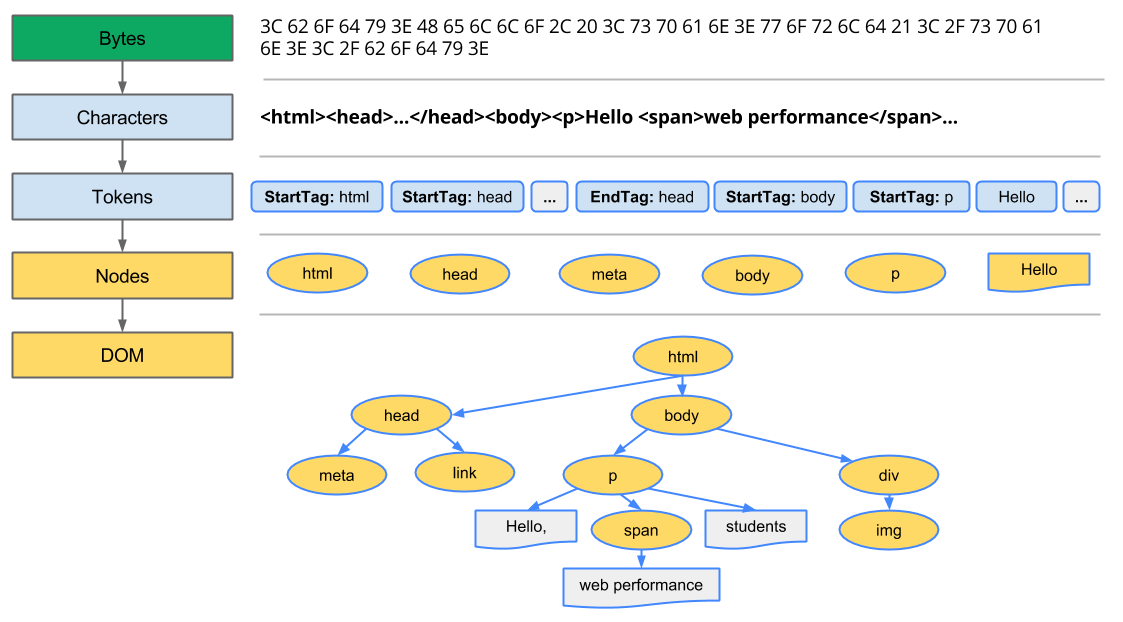
브라우저가 렌더링을 할 때 실제로 다음과 같은 과정을 거친다고 합니다. 네트워크를 통해서 HTML 문서를 불러옵니다. 아직은 raw byte에 불과한 녀석이라 브라우저가 읽기 쉽지 않겠죠? 읽기 쉽도록 변환시켜주는 과정을 거칩니다. 먼저 characterize합니다. 그리고 characterize화 해준 녀석을 tokenize화 해줍니다. 그리고 이 녀석들을 Nodes로 바꿔줍니다. 여기서 더 나아가 이것을 기반으로 DOM Tree를 생성해줍니다.
결국 DOM은 HTML로부터 온 것입니다.
아래는 금방 설명드린 과정을 그림으로 보여주고 있습니다.
4)dom 너 어쩌다 탄생했냐 :
'dom 왜 필요하냐'와 비슷한 내용일 수 있지만, 그것의 역사적 배경을 조금만 더 알아보겠습니다. dom은 어쩌다가 탄생했을까요. 역사적으로 DOM의 탄생 배경은 '브라우저 전쟁'과 연관이 있습니다. 브라우저 전쟁이란 무엇이냐? 마이크로소프트와 넷스케이프 네비게이터가 각각이 만든 브라우저의 점유율을 높이기 위해서 벌이는 전쟁이라고 보면됩니다. 브라우저의 점유율을 높인다는 것은 브라우저의 사용성을 높이는 방법이겠죠? 그들끼리 어떻게든 브라우저의 사용성을 높이기 위한 전쟁을 벌였고, 그 전쟁에 사용된 기술이 바로 JavaScript, JScript입니다. 그리고 이런 기술들은 화면에서 더 다양한 상호작용이 이루어질 수 있게 만들어주었습니다.
이전까지 웹페이지에 보여지는 것은 단순한 html이었습니다. 그것을 그냥 화면에 보여주는 것으로 끝났지만, 이제는 다릅니다. 화면에 더 많은 상호작용이 일어나야하고, 프로그래밍언어로 더 많은 조작이 가능하게 만들어져야 합니다. 그렇게 탄생하게 된 것이 DOM입니다. 전쟁 속에 탄생한 아가...DOM?
5)dom - 결론 :
이 정도면 dom이 뭔지는 감이 오는 것 같습니다. 그러니까 js가 html을 조작하기 편하게 만든 어떤 객체라는 것이라고 이해할 수 있겠네요.
그러면 아까의 맥락에 이어서 virtual + dom의 의미를 정의해보겠습니다.
'js 가 html을 조작하기 편하게 만들어진 객체(dom)를 허상으로 만든 것(virtual)'
물론 사전적 정의를 내린 것에 불과하지만, 이런 식으로 paraphrasing해볼 수 있을 것 같습니다.
여기서 다음 맥락으로 이어집니다.그냥 dom을 통해서 html을 조작하면되는데, 왜 굳이 이것을 허상으로 만들어야 했을까요? 이제 virtual dom이 무엇인지 본격적으로 알아가 봅시다.
[추가자료 : Dom은 정확히 무엇일까?]
3.Virtual dom이 뭐지?
위에서 정의해보았다시피 virtual dom은 'js가 html을 조작하기 편하도록 만들어진 객체를 허상으로 만든 것'이라고 할 수 있습니다. 그리고 저는 이런 질문들을 이어나갑니다. '이것을 왜 굳이 허상으로 만들어야 했는가?', Dom이 허상으로 만들어졌다는 것이 무슨 말인가?', '이것을 통해 얻는 유익이 뭔가?', '만약 성능의 개선이라고 한다면 도대체 왜 가상돔의 성능이 더 좋은가?'
이런 여러 의문들 가운데, 제가 가장 처음으로 접근했던 순서는 도대체 'real dom'을 조작하는 것보다, 'virtual dom'을 사용하는 것이 왜 더 좋은가? 왜 더 빠른가? 에 대한 의문이었습니다. 우선은 제가 의문을 가졌던 순서대로 접근해보려고 합니다.
3.1 Vitual dom이 왜 더 빠른가?
Virtual dom의 기본적인 원리 :
먼저는, virtual dom이 어떤 식으로 구현되어있는지가 궁금했습니다. 그래서 검색을 해보니 이런 자료가 나오더군요. 이 자료를 기반으로 이해해보았을 때, 결국에 virtual dom도 마지막에는 real dom api를 사용하고 있었습니다. 이 자료를 토대로 이해한 것이 맞는지 확인하기 위해서 virtual dom의 원리를 지속적으로 검색을 해보니, 다음과 같이 정리되었습니다.
1.real dom으로부터 virtual dom을 만든다(virtual dom은 메모리 상에 존재하는 하나의 객체다)
2.변화가 생기면 새로운 버전의 virtual dom을 만든다.
3.old 버전의 virtual dom과 new 버전의 virtual dom을 비교한다.(diff algorithm)
4.비교 과정을 통해서 발견한 차이점을 real dom에 적용한다.
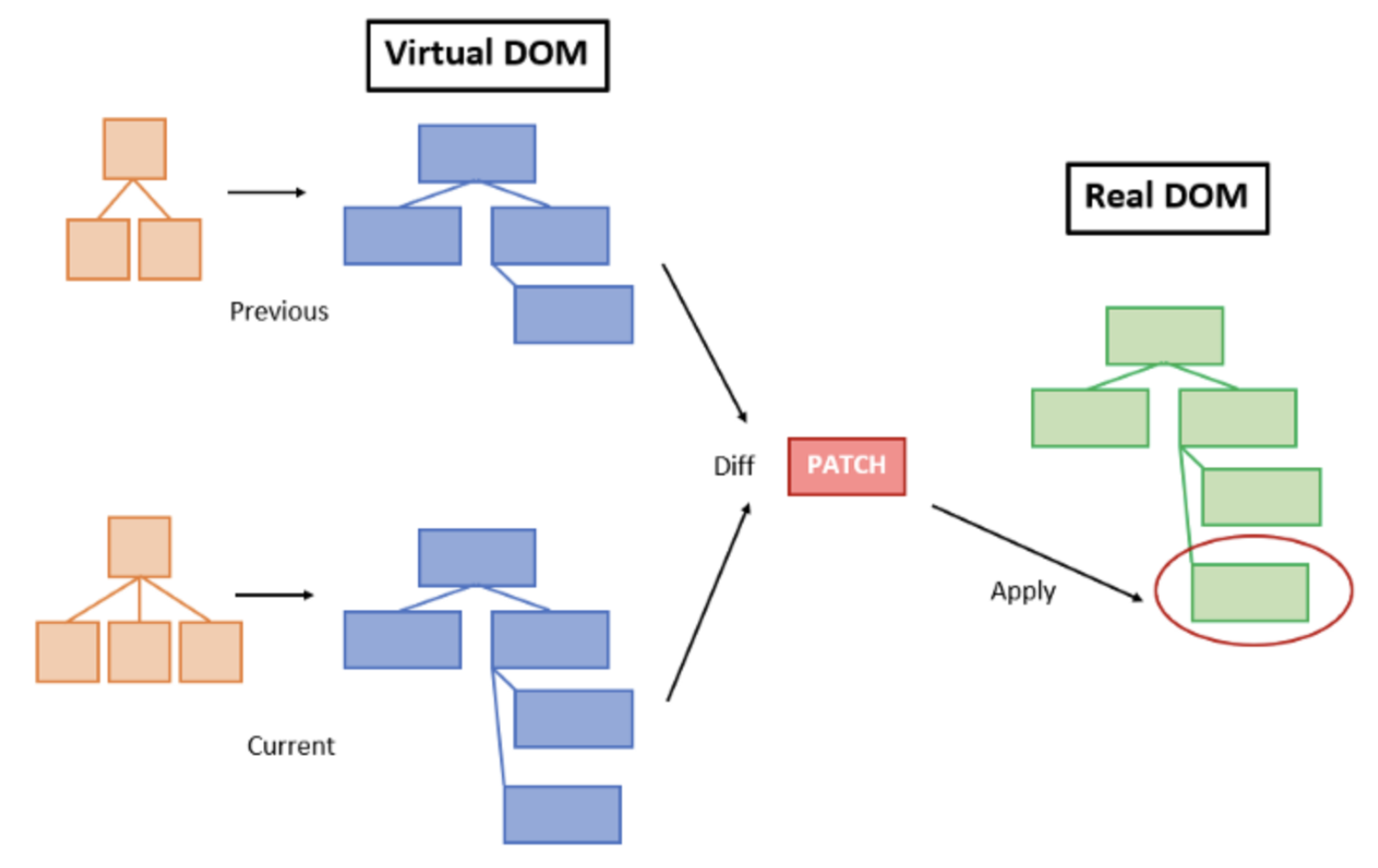
이런 순서로 적용된다는 사실을 알게 되었고, 이 과정을 reconciliation(재조정)이라고 부르는 것도 알게 되었습니다. 여기까지 이해했음에도 아직 의문이 풀리지 않았습니다. '그렇다면 마지막에 가서는 결국 dom api를 사용한다는거 아니야? 그러면 그냥 애초에 내가 변화시키고 싶은 녀석만 변화시키면 dom api를 사용하는 것과는 별다른 차이점이 없는 것인가?' 라는 의문이 남았습니다. 아직도 의문이 해결되지 않아서 계속 리서치를 하던 중 다음과 같은 대답을 얻을 수 있었습니다. virtual dom을 사용하게 된 또 다른 배경이 있었던 것입니다. 그것은 변경을 감지하는 방법에 있었습니다.
변화를 감지하는 2가지 방법 :
리렌더링이 일어난다는 것은 특정 node에 변화가 생겼다는 것입니다. 그렇다면 이 변화를 어떻게 감지하는 것일까요? 이 변화를 감지하는 방법에는 크게 2가지가 있었습니다. 그 내용들을 소개해보겠습니다.
1)dirty checking :
dirty checking은 node tree를 재귀적으로 계속 순회하면서 어떤 노드에 변화가 생겼는지를 인식하는 방법입니다. 그리고 그 노드만 리렌더링을 시켜주면 되는 방식이었습니다. 이 방법은 angular.js가 사용하던 방법인데, 이렇게 하면 변화가 없을 때도 재귀적으로 노드를 탐색함으로써 불필요한 비용이 발생하고 성능적인 측면에서도 문제가 있었습니다.
2)observable :
observable은 변화가 생긴 노드가 관찰자에게 알림을 보내주는 방식입니다. 리액트의 경우에는 state에 변화가 생겼을 때, 리액트에게 렌더링을 해줘야한다는 것을 알려주는 방식으로 이루어집니다. 그리고 리액트는 알림을 받으면 렌더링을 시키죠. 이런 방식을 사용할 경우에 변화가 생기기 전까지는 아무일도 하지 않아도 됩니다. 노드에게 변화가 생겼다는 알림을 받으면 렌더링 한다. 아주 효율적인 방식이라고 할 수 있습니다.
observable의 문제점
그렇다면 이 observable에는 문제가 없었을까요? 아니요. 역시나 observable에도 문제점이 있었으니, 변화에 대한 알림을 받으면 전체를 렌더링 시켜버린다는 것입니다. 전체를 렌더링시키는 것은 말그대로 엄청난 reflow-repaint 비용을 발생시킵니다. 이 지점에 등장한 것이 바로 virtual dom이라는 것입니다.
virtual dom의 등장
virtual dom은 말씀드렸다시피 메모리 상에 존재하는 하나의 객체입니다. 이제 리액트는 특정 state에 변화가 생겼다는 알림을 받으면 real dom 전체를 렌더링 시켜주는 것이 아니라, virtual dom을 렌더링 시킵니다. 이 말은 이렇게 표현해볼 수 있습니다.
브라우저를 렌더링 시키는 비용 vs 객체를 새로 만드는 비용
말할 것도 없이, 브라우저를 새롭게 렌더링 시키는 비용보다, 객체를 새로 만드는 비용이 훨씬 더 저렴합니다. 리액트는 이렇게 변화가 감지되면 real dom을 새롭게 렌더링 시키는 대신, virtual dom이라는 메모리상의 객체를 새로 만드는 방식을 선택했습니다. 그리고 거기서 변화가 생긴 내용을 비교해 마지막에 가서는 꼭 필요한 부분만 real dom에 적용시키는 방식으로 효율성을 높인 것입니다.
그리고 실제로 전체화면을 렌더링하는 것과 일부분만 변경시켜주는 것은 비용적인 측면에서 엄청난 차이가 있다는 것은 말할 것도 없습니다.
이 지점까지 도달했을때는 정말 기뻤습니다. 왜 real dom을 직접 조작하는 것보다, virtual dom을 이용하는 것이 더 효율적인지에 대한 더 나은 대답을 얻은 것 같았거든요. 이 지점에서 아까 제기했던 질문인 '왜 굳이 가상으로 만들어야 했는가?'에 대한 대답을 얻을 수 있었습니다.
이제 여기서 저는 조금 더 궁금해졌습니다. virtual dom이 객체로 이루어져있다고 하는데, 실제로 그것은 어떤 모습일까? 어떻게 객체로 만들어지는 것일까? 이어지는 글에서는 이 내용에 대해 알아보려 합니다.
아래는 virtual dom이 도입된 배경에 대해서 제가 참고한 자료입니다.
[참고자료 : Explain dirty checks in React.js]
[참고자료 : Why is React's concept of Virtual DOM said to be more performant than dirty model checking?]
[참고자료 : How exactly is React's Virtual DOM faster?]
[참고자료 : Why is the Virtual DOM So Fast?]
3.2 Virtual Dom은 어떻게 객체로 만들어지는가?
virtual dom이 더 빠르다는 말이 나오게 된 배경을 알아봤습니다. 그럼에도 저는 아직 완전히 virtual dom을 이해했다는 생각이 들지 않아 조금 더 질문을 던져보기로 했습니다. virtual dom은 어떻게 객체로 만들어지는가 하는 것이었습니다.
가상돔 객체는 어떻게 만들어지는가? :
일반적인 함수형 컴포넌트를 작성하면 아래와 같이 나올 것입니다.
import React from "react"
import ReactDOM from "react-dom"
const List = () => {
return (
<div>
<h1>My favorite ice cream flavors</h1>
<ul>
<li className="brown">Chocolate</li>
<li className="white">Vanilla</li>
<li className="yellow">Banana</li>
</ul>
</div>
)
}
ReactDOM.render(<List/>, document.getElementById("global"))이런 컴포넌트는 어떻게 객체로 변환되는 것일까요? 이 컴포넌트를 바벨을 거친 이후 벗겨보면 아래와 같이 표현되고 있었습니다.
import React from "react"
import ReactDOM from "react-dom"
const List = () => {
return React.createElement("div",null,
React.createElement("h1", null, "My favorite ice cream flavors"),
React.createElement("ul",null,
React.createElement("li",{ className: "brown",}, "Chocolate"),
React.createElement("li",{className: "white",},"Vanilla"),
React.createElement("li",{className: "yellow",},"Banana")
)
)
}
ReactDOM.render(React.createElement(List, null),document.getElementById("global"))
이런 내용은 리액트 공식문서에서도 소개하고 있습니다.
createElement 메서드를 사용하면 뭔가가 만들어지나봅니다. 그리고 그것을 ReactDOM.render메서드의 인자로 넘겨주네요. createElement 메서드를 거치면 반환되는 내용은 무엇일까요?
리액트의 소스코드를 확인해보니, 아래와 같은 내용이 나옵니다.
export function createElement(type, config, children) {
...중략
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}createElement의 내부적인 내용을 확인해보니 ReactElement함수의 인자에 넘겨줄 값들을 꾸려주고 있었습니다. (만약 세부적인 내용이 궁금하시면 여기를 살펴보세요.)
결론적으론 ReactElement 함수의 호출값을 반환하고 있네요. createElement 함수가 반환하는 값이 무엇인지 확인하려면 ReactElement의 반환값이 무엇인지 알아야 합니다.
const ReactElement = function(type, key, ref, self, source, owner, props) {
const element = {
// This tag allows us to uniquely identify this as a React Element
$$typeof: REACT_ELEMENT_TYPE,
// Built-in properties that belong on the element
type: type,
key: key,
ref: ref,
props: props,
// Record the component responsible for creating this element.
_owner: owner,
};
return element;
};아, ReactElement 함수의 내부를 보니 element라는 객체를 만들고 있군요! 그리고 그 객체를 반환하고 있습니다. 그렇다면 React.createElement 메서드를 통해서 element라는 어떤 객체가 만들어진다는 것을 알 수 있게 되었습니다.
아, 이런 방식으로 내가 컴포넌트에서 작성했던 내용이 객체로 만들어지는 것이구나. 깨달을 수 있었습니다.
그러면 이제 또 남아있는 질문들이 있습니다. 이것을 어떻게 렌더링하는 것일까?
4.Render 함수 내부에서 일어나는 일 : React Fiber
render 함수 내부를 살펴보고자, 야심찬 마음으로 리액트의 소스코드를 뜯어보기 시작했습니다. 살펴보다가, render 함수가 뿌리를 내리고 있는 함수의 갯수가 5개가 넘어가는 순간부터는 '이거 만만치 않겠구나' 싶었습니다. 그래서 그림판에 함수를 그려가면서 코드를 추적해가야했지만 결국 이 방대한 코드에 압도될 수 밖에 없었습니다. 우선은 이 코드들에 대해서 설명해주는 자료를 찾아보는 것이 학습에 도움이 되겠다 싶어 자료를 리서치하는 쪽으로 방향을 틀었습니다.
render 함수 내부에서 일어나는 일을 찾아보자, 가장 먼저 접할 수 있었던 개념은 바로 React Fiber였습니다. React Fiber는 react v16.0에서 소개된 리액트의 new core algorithm입니다. 항상 새로운 기술이 나올 때는 기존에 있던 특정 불편함을 해결하기 위해서 나옵니다. 과연 이 react fiber는 어떤 불편함을 해결하기 위해서 나오게 된 것일까요? 기존에는 어떤 문제가 있었을까요? 이 react fiber는 렌더링과 어떤 연관이 있을까요?
4.1 React Fiber는 왜 만들어졌나?(기존에는 어떤 문제가 있었나?)
사실 리액트 그 자체로도 매우 훌륭한 라이브러리였습니다. 리액트의 killer feature라고 할 수 있는 virtual dom과 그것의 핵심 알고리즘인 reconciliation 과정을 통해서 렌더링 효율을 매우 높였기 때문입니다. 그런데 이 reconciliation에도 한계가 있었습니다.
old reconciliation의 한계 :
이제는 old reconcilation이라고 불리게 된 이 알고리즘에는 어떤 한계가 있었을까요. virtual dom이 동작하는 과정을 다시 한번 살펴보겠습니다. 처음에는 real dom tree를 copy한 virtual tree가 만들어집니다. 그리고 변경사항이 생기면 new virtual tree가 만들어지고, old virtual tree와 new virtual tree비교합니다. 비교. 바로 이 지점에 문제가 있습니다.
두 tree를 어떻게 비교할까요? 두 virtual tree는 객체로 만들어져있습니다. 이 두 virtual tree 상에서 차이점이 있는 것을 찾아내기 위해서 diff 알고리즘이 진행될 텐데, 이 때 두 객체를 비교하기 위해선 재귀적으로 진행할 수 밖에 없었습니다.
재귀 알고리즘은 본질적으로 call stack과 연관이 있습니다. 가장 상단에 있는 함수가 호출되면 해당 함수는 call stack 가장 아래에 쌓일 것입니다. 내부적으로 함수가 호출될 때마다 반복적으로 call stack에 차근 차근 쌓여가겠죠. 그리고 함수가 반환되면 그때서야 함수는 call stack에서 pop 될 것입니다.
여러분도 아시다시피 비동기 작업들은 event loop가 call stack이 비어있는 여부를 확인한 후에야 콜백함수들을 call stack에 올려 놓고 실행합니다. call stack이 비어있지 않다면, call back queue에 대기중인 함수들은 실행될 수 없을 것입니다. 여기에 들어가 있는 함수들은 유저의 클릭이벤트가 있을 수도 있고, setTimeout, 애니메이션 등등이 있을 것입니다.
어플이 너무 방대해진 나머지, 두 virtual tree를 비교하는 재귀 알고리즘이 100ms 동안 진행된다고 해보겠습니다. 그런데, 50ms 즈음에 유저의 이벤트가 들어왔습니다. 그럼에도 불구하고 아직 재귀 알고리즘은 50ms 동안이나 순회를 해야합니다. 그러니까 call stack의 공간을 50ms나 더 차지하고 있어야한다는 말이죠. 이렇게되면 즉각적으로 user event에 대응할 수도 없을 뿐더러, 프레임 드롭이라는 문제를 일으킬 수 있습니다.
프레임 드롭 :
프레임 드롭이란 무엇일까요? 사용하는 기기에 따라 다르겠지만, 일반적인 윈도우 기기는 60프레임율을 유지한다고 합니다. 이건 뭔소린가요? 저희가 화면에서 보는 영상들은 모두 이미지로 이루어져있습니다. 그 이미지 여러 장을 빠른 속도로 보여주니, 그것이 움직이는 동영상 처럼 보이게 되는 것입니다. 60프레임율이라는 말은, 1초의 시간동안 60장의 이미지를 보여준다는 말입니다. 그렇게 화면의 영상을 표현합니다. 30프레임율은? 1초의 시간동안 30장의 이미지를 보여준다는 말이 되겠죠?
1초는 1000ms입니다. 그렇다면 60프레임을 1000으로 나누면 1프레임당 소요할 수 있는 시간은 약 16ms가 될 것입니다. 이 숫자가 중요합니다. 이 숫자에 프레임 드롭의 의미가 담겨있습니다.
한 프레임 안에서 작업을 수행하는데 걸리는 시간이 16ms가 넘어가면, smooth한 화면을 보여줄 수 없게 됩니다. 화면이 둑둑 끊이면서 보이게 될 것인데, junk라는 단어로 이것을 명명하는 것 같습니다. 저희는 프레임드롭이라고 부르는듯 합니다.
추가적으로 브라우저가 housekeeping을 위해서 필요한 시간은 6ms정도가 됩니다. (housekeeping의 의미가 무엇인지 확인해보려 했으나, 정확한 자료를 찾지는 못했습니다. 저는 브라우저가 이런저런 기본적인 작업을 하기 위한 시간으로 이해했습니다.) 그러면 저희에게 남는 시간은 10ms가 될 것입니다. 무슨 말이냐? 저희가 해야 할 작업을 10ms안에 끝내주지 않으면, 프레임 드롭이 발생할 것이라는 것입니다. 그러니까 뭔가 둑둑 끊기는 모습이 화면에 등장할 것이라는 것이죠. 이것은 UX상으로도 좋지 않은 현상입니다.
기존의 문제점 결론 :
앞서 말했듯이, 두 virtual tree를 비교하는 작업은 재귀적으로 이루어집니다. call stack에 쌓여있는 모든 함수들이 return될 때까지 call stack을 비워주지 않습니다. 다른 말로하면, 시작하면 무조건 끝을 봐야한다는 것이죠. 시작했다? 그러면 중간에 멈추지 않겠다. 이 말입니다. 그런데 이 재귀적으로 tree를 순회하는 시간이 16ms를 넘어서면, 프레임 드롭이 발생할 뿐더러, 어플의 크기에 따라 순회하는 시간이 길어지면 유저 이벤트에 즉각적으로 대응하는 하는 것이 어려워집니다.
이 지점에서 react fiber가 등장합니다. react fiber가 해결하고자 하는 것은 이런 순회 작업을 멈출 수도 있고, 재개할 수도 있고, 필요에 따라서는 그냥 내다버릴 수도 있게 만드는 것입니다. 더 나아가 우선순위에 따라 이것을 처리함으로써, 더욱 똑똑하게 렌더링을 구현합니다. 다른 말로 하면 리액트 렌더링 알고리즘에 스케줄링을 구현한 것이죠.
react fiber의 목적을 정리하면 다음과 같습니다.
- 작업을 멈추고, 나중에 다시 시작한다.
- 다양한 종류의 작업에 따라서 우선순위를 부여한다.
- 완성된 작업물을 재사용할 수 있다.
- 더 이상 필요하지 않은 작업물이면 버릴 수 있다.
4.2 React Fiber는 어떻게 스케줄링을 구현했나?
기존에 사용하던 객체 방식과, 그것을 재귀적으로 순회하는 방식은 call stack에 종속되어 있었습니다. 위에서 살펴봤듯 이런 구조는 특정 문제점을 가지고 있었습니다. 그래서 리액트 팀에선 아주 멋진 말을 합니다.
'아 이렇게 외부 환경에 종속될 수 없다. 그러면 우리가 직접 스케줄링이 가능한 stack을 만들자!'
(진짜로 이런 말을 했는지는 모르겠습니다..) 해서 리액트 팀은 자바스크립트 엔진의 call stack 대신 virtual stack을 구현했습니다. virtual dom에 이어 virtual stack이라뇨. 정말 멋집니다...🫢
virtual dom은 실제 dom이 아니라, 메모리 상에 존재하는 가상의 dom이라고 했습니다. virtual stack도 비슷합니다. 실제 stack이 아니라, 메모리 상에 존재하는 가상의 stack이라는 것이죠. 이제 더 나아가 스케줄링이 가능한.
리액트 팀은 이것을 어떻게 구현했을까요? 바로 단일 연결 리스트를 활용해 구현했습니다.
단일 연결 리스트로 구현된 react fiber
render 함수의 인자로 넘어온 element객체는 그 안에 들어오면서, 하나하나 fiber node로 변환됩니다. 그리고 그 node들은 모두 연결됩니다. 아래 예시 코드를 통해서 살펴보겠습니다.
class Node {
constructor(instance) {
this.instance = instance
this.child = null
this.sibling = null
this.return = null
}
}각각의 fiber 노드들은 3가지 필드를 가집니다.
- child : 자식 노드
- sibling : 형제 노드
- return : 부모노드 (return을 부모 노드라고 부르는것이 비직관적으로 느껴질 수 있습니다. return 하고 나면 그 다음에 접근하게 되는 노드가 부모 노드이기 때문에 return 노드라고 부르는 것 같습니다. 여기를 참고해보세요.)
그리고 인자로 받아 온 노드들을 모두 단일 연결 리스트로 연결 시켜주는 함수가 있습니다.
function link(parent, elements) {
if (elements == null) elements = []
parent.child = element.reduceRight((prev, cur) => {
const node = new Node(cur)
node.return = parent
node.sibling = prev
return node
}, null)
return parent.child
}그리고 이 link 함수는 parent 노드의 가장 첫번째 자식을 반환합니다.
const children = [{ name: "b1" }, { name: "b2" }]
const parent = new Node({ name: "a1" })
const child = link(parent, children)
child.instance.name === "b1" //true
child.sibling.instance === children[1] // true또한 현재 노드와 자식 노드들의 연결을 도와주는 helper 함수가 있습니다.
function doWork(node) {
console.log(node.instance.name)
const children = node.instance.render()
return link(node, children)
}그리고 이제 이렇게 연결된 함수들을 탐색하는 walk 함수가 있습니다. 이 탐색은 기본적으로 깊이 우선 탐색으로 이루어집니다.
function walk(o) {
let root = o
let current = o
while (true) {
let child = doWork(current)
//자식이 있으면 현재 active node로 지정한다.
if (child) {
current = child
continue
}
//가장 상위 노드까지 올라간 상황이라면 그냥 함수를 끝낸다.
if (current === root) {
return
}
//형제 노드를 찾을 때까지 while문을 돌린다. 이 함수에서는 자식에서 부모로 올라가면서 형제가 있는지를 찾아주는 역할을 하고 있다.
while (!current.sibling) {
//top 노드에 도달했으면 그냥 끝낸다.
if (!current.return || current.return === root) {
return
}
//부모노드를 현재 노드에 넣어준다.
current = current.return
}
current = current.sibling // while문을 빠져나왔다는 것은 sibling을 찾았다는 것이다. 찾은 sibling을 현재 current node에 넣어준다.
}
}중요한 점은 이 함수를 사용하면 스택이 계속해서 쌓이지 않는다는 것입니다. call stack의 가장 아래에는 walk 함수가 깔려있고, 계속해서 doWork 함수가 호출되었다가 사라지는 그림이 그려질 것입니다.
이 함수의 핵심은 current node에 대한 참조를 계속해서 유지한다는 점입니다. 때문에 이 함수가 중간에 멈춘다 할지라도, current node로 돌아와서 작업을 재개할 수 있게 되었습니다. 이런 구조를 통해서, 재귀적 순회가 가진 문제점을 해결했습니다. 재귀는 한번 시작하면 무대뽀로 끝까지 실행 해야만 하지만, 이제는 중간에 멈춰도 이전의 작업 기록이 남아있으니, 마음놓고 멈출 수 있습니다.
지금까지 살펴본 예시 코드를 통해서 어떻게 fiber가 단일 연결리스트로 구현이 되어있는지, 어떻게 중간에 하던 작업을 멈췄다가도 그것을 재실행할 수 있는지를 알아봤습니다. 그렇다면 이제는 이 작업을 언제 실행하고 언제 멈추는지도 알아봐야겠습니다. 이것을 이해하기 위해서는 하나의 프레임 안에서 일어나는 일을 알아야 합니다.
하나의 프레임 안에서 일어나는 일

일반적으로 16ms 안에 하나의 프레임이 실행될 것이라고 말씀드렸습니다. 16ms 동안에 어떤 일들이 일어나는 것일까요? 이 과정을 살펴봄으로써, fiber가 실행되는 순간과, 그것을 멈추는 순간에 대한 이해를 가질 수 있을 것입니다.
- input event : 가능하면 빠른 유저 피드백을 주기 위해서 input event가 실행된다.
- Timers : 예약된 시간에 도달했는지 확인하기 위해서 타이머를 확인한다. 그러고 나서 시간이 맞다면 대응하는 콜백 함수를 실행해준다.
- Begin Frame : Begin Frame을 확인한다.(이것은 각각의 프레임의 이벤트이다.) window.resize, scroll, media query change 등등도 같이 확인한다.
- requestAnimationFrame : rAF를 실행한다. painting이 시작되기 전에 callback 이 실행된다.
- layout : 레이아웃 작업을 수행한다. 여기서 layout을 계산하고, 업데이트한다. 다시 말해서 어떻게 element가 화면에서 styled되고 보여질지를 결정한다.
- paint : paint 작업을 수행한다. 각각 노드의 size와 위치값은 주어졌으니, 각 요소의 내용들이 브라우저에 의해 화면에 채워지는 단계다.
- idle period : 브라우저가 유휴시간에 들어간다. 할 일 없이 빈둥대는 시간이다.
하나의 프레임 동안에 일어나는 일들입니다. 여기서 저희가 주목해야 할 부분은 idle period입니다. 16ms라는 하나의 프레임 안에서 main task가 진행되고 나서 남은 시간이 있다면, 그 시간이 바로 idle period입니다. 브라우저가 할 일이 없어지는 시간.
브라우저가 할 일이 없어지는 순간에 특정 함수가 실행될 수 있도록 하는 api가 있습니다. 바로 requestIdleCallback입니다.
requestIdleCallback과 fiber
requestIdleCallback 이란? :
window.requestIdleCallback(callback, { timeout: 1000 })requestIdleCallback함수에 대해 간략히 설명드리겠습니다. 위에서 언급했듯이 이 함수는 브라우저가 빈둥대는 시간(idle time)을 노립니다. 미리 콜백 함수를 등록해두면서 브라우저에게 이렇게 말합니다. '브라우저야, 너 main task하고나서 여유 있으면, 이 callback 함수 실행할 시간좀 나눠줘'
그리고 뒤에는 timeout을 설정해두었는데, 해당 타임아웃 시간에 도달하면 idle time이 있든 없든 무조건 callback을 실행시킵니다.
이 함수의 콜백함수가 받게 될 파라미터에는 deadline이라는 객체가 있습니다. 그리고 이 객체는 2가지 속성을 가지고 있습니다.
- timeRemining : current frame에서 얼마나 시간이 남아있는지를 return 합니다.
- didTimeout : callback task의 시간이 초과했는지 여부를 return 합니다.
fiber는 requestIdleCallback을 활용한다 :
리액트 fiber는 이 api를 적극활용합니다.
fiber는 주어진 nodes를 잘게 쪼갭니다. 그리고 각각의 fiber node를 하나의 실행 단위로 여깁니다. fiber에 대한 자료를 조금 찾아보시면, 'fiber = unit of work'라는 설명을 자주 들으실 수 있을 겁니다. 이렇게 잘게 쪼갠 작업들을 idle time에 하나하나씩 실행시키는 것입니다. (이때 requestIdleCallback을 사용하겠죠?)
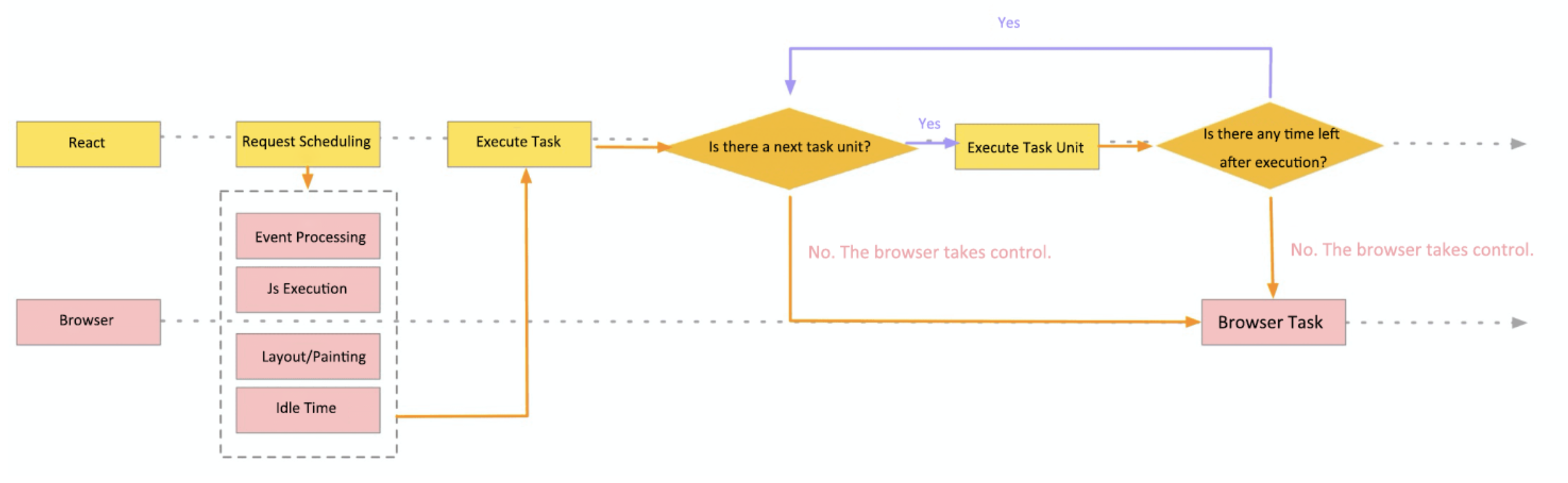
순서는 이렇습니다.
main task가 끝나고나면, 남는 시간이 있는지 묻습니다.
'브라우저야 남는 시간 없어?'
'없어😶' 라는 대답이 돌아오면,
'아.. 알겠어..! 너 할거 계속해..!🥲' 라고 리액트는 대답합니다.
만약 남는 시간이 있다는 대답이 돌아오면,
그 시간을 자신이 활용합니다. cpu를 분배받은 react는 자신이 잘게 쪼갠 작업의 단위를 하나씩 실행합니다.
그리고 하나를 실행할 때마다, 다시 브라우저에게 남는 시간이 있는지 물어봅니다.
남는 시간이 없다? 그러면 다시 브라우저에게 cpu를 넘겨줍니다.
근데 남는 시간이 있다? 그러면 자신에게 남아있는 task가 있는지 한번 더 확인해봅니다.
그렇게 확인해서 남은 작업이 없다면 브라우저에게 cpu를 넘겨주고,
남은 작업이 있으면 실행한 후 위의 과정을 반복합니다.
이런 흐름은 아래의 그림에서 확인할 수 있습니다.
이것을 통해서 우리는 fiber가 언제 실행되고, 언제 멈추는지를 알 수 있게 되었습니다. 하지만 아직도 fiber에 대해서 알아야 할 것이 남아있습니다. fiber는 크게 2단계로 나누어집니다. 바로 render phase와 commit phase입니다. 각각에 대해서 알아보겠습니다.
4.3 Fiber의 2가지 단계 : render & commit
render phase :
render 단계에서는 작업을 멈췄다가 다시 시작하는 것이 가능합니다. 이 단계에서 하게 되는 주된 일은 effect list를 모으는 것입니다. 여기서 말하는 effect란 node일어나는 변경사항을 말합니다. 예를 들어서 생성, 삭제, 속성 수정 등등이 있을 수 있습니다. render 단계에서 순회를 하면서 이런 effect들을 list로 모으는 일을 합니다. render 단계의 결과물이 바로 effect list인 것이죠.
render가 순회하는 흐름을 간단하게 알아보겠습니다.
- current node로부터 순회를 시작합니다. 만약 node에 수정이 필요하면, 그 내용에 알맞는 tag를 붙입니다. (INSERT, DELETE, UPDATE 등등)
- 자식노드에 대한 fiber를 생성합니다. 만약에 자식 fiber가 생성되지 않으면 node는 끝난 것입니다. 그러면 effect list는 부모 노드에 합쳐지고, current node의 sibling node로 순회를 갑니다. 만약 자식 fiber가 생성되면 그 node로 순회를 갑니다.
- idle time을 한번 확인합니다. 그래서 시간이 남아있다면, 다음 node로 순회를 시작합니다. 시간이 없다면, 다시 시간이 주어질 때까지 기다립니다.
- 만약에 더 이상 노드가 없다면, pendingCommit 상태로 돌아갑니다. 이 상태는 effect list가 다 수집되었다는 것을 의미합니다.
이 effect list는 linear list로 이루어져 있습니다. tree를 순회하는 방식보다 훨씬 빠르기 때문에 commit 단계에서 실제 dom에 적용할 때 효율적일 것 입니다. 이 effect list가 구성되는 그림은 다음과 같을 것입니다.
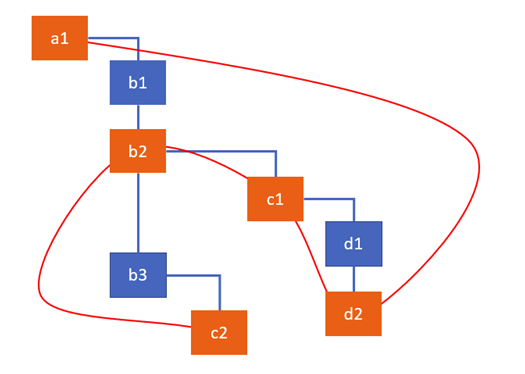
빨간색 쳐진 부분이 effect가 있는 노드들입니다. 그 effect들끼리 list가 형성되는 것입니다. 그렇게 나온 결과물은 다음과 같은 모습입니다.

이제 이렇게 effect list가 다 모아졌으면, commit phase로 넘어갑니다.
commit phase에 대한 설명으로 넘어가기 전에, 예시 코드를 살펴보겠습니다.
먼저 자식 vitual dom element 배열을 순회하면서 각각의 element를 fiber노드로 만드는 함수를 만들어보겠습니다.
const reconcileChildren = (currentFiber, newChildren) => {
let newChildIndex = 0;
let prevSibling // 이전 자식 fiber
//while문에서 순회하면서 element를 fiber 로 만든다.
while(newChildIndex < newChildren.length){
let newChild = newChildren[newChildIndex]
let tag
//여기 fiber type을 정의하기 위해서, if문에서 tag에 적절한 값들을 할당합니다.
if(newChild.type === ELEMENT_TEXT){
tag = TAG_TEXT // type 이 ELEMENT_TEXT라는 것은 text라는 것을 의미합니다.
}else if(typeof newChild.type === 'string'){
tag = TAG_HOST // string이라는 것은 native DOM이라는 의미힙니다.
}
let newFiber = {
tag,
type : newChild.type,
props : newChild.props,
stateNode : null,
return : currentFiber,
effectTag : INSERT,
nextEffect : null
}
if(newFiber){
if(newChildIndex === 0){
currentFiber.child = newFiber // 첫번째 child라는 것을 의미한다.
}else{
prevSibling.sibling = newFiber // 첫번째 자식의 형제를 두번째 자식을 가리키게 한다.
}
prevSibling = newFiber
}
newChildIndex++
}
}그리고 fiber node가 가지고 있는 effect를 모으고, effect list를 만들어내는 함수를 만들어보겠습니다.
아, 각각의 fiber는 2가지 속성을 가지고 있습니다.
- firstEffect : effect를 가지고 있는 첫번째 자식을 가리킨다.
- lastEffect : effect를 가지고 있는 마지막 자식을 가리킨다.
그리고 nextEffect는 각각의 자식 fiber를 연결하고, 연결 리스트를 만드는데에 사용됩니다.
const compleUnitOfWork = (currentFiber) => {
let returnFiber = currentFiber.return
if(returnFiber){
//만약에 부모 fiber의 firstEffect가 값을 가지고 있지 않다면, 이것이 currentFiber의 firstEffect를 가리키게 합니다.
if(!returnFiber.firstEffect){
returnFiber.firstEffect = currentFiber.firstEffect
}
//만약 currentFiber의 lastEffect에 값이 있다면
if(currentFiber.lastEffect){
if(returnFiber.lastEffect){
returnFiber.lastEffect.nextEffect = currentFiber.firstEffect
}
returnFiber.lastEffect = currentFiber.lastEffect
}
const effectTag = currentFiber.effectTag
if(effectTag){
if(returnFiber.lastEffect){
returnFiber.lastEffect.nextEffect = currentFiber // nextEffect는 두 자식 fiber 사이를 연결짓습니다.
}else{
returnFiber.firstEffect = currentFiber
}
returnFiber.lastEffect = currentFiber
}
}
}마지막으로 모든 fiber node를 순회하고 effect list를 만들어내는 함수를 만들어보겠습니다.
const performUnitOfWork = (currentFiber) => {
beginWork(currentFiber)
//자식 node가 있으면 자식 먼저 순회하도록
if(currentFiber.child){
return currentFiber.child
}
//자식이 이제 없다면, effect 수집. 자신 -> 형제 -> 부모순으로
while(currentFiber){
completeUnitOfWork(currentFiber)
if(currentFiber.sibling){
return currentFiber.sibling
}
currentFiber = currentFiber.return // 만약 형제 node가 없으면 부모 node로 이동.
}
}commit phase :
commit phase에서는 중간에 작업을 멈출 수 없습니다. 이 단계에서 실제로 dom에 변형이 일어납니다. 이전 단계에서 모아졌던 effect list를 한 번에 dom에 적용하는데, 이때는 멈추는 일 없이 한번에 적용합니다. 이 단계 또한 예시코드로 살펴보면 좋을 것 같습니다.
아래 코드는 commitWork 함수로, currentFiber가 가지고 있는 effectTag에 따라서 실제 dom에 적용해주고 있습니다.
const commitWork = currentFiber => {
if (!currentFiber) return
let returnFiber = currentFiber.return
let returnDOM = returnFiber.stateNode // 부모 요소
if (currentFiber.effectTag === INSERT) {
returnDOM.appendChild(currentFiber.stateNode)
} else if (currentFiber.effectTag === DELETE) {
returnDOM.removeChild(currentFiber.stateNode)
} else if (currentFiber.effectTag === UPDATE) {
if (currentFiber.type === ELEMENT_TEXT) {
if (currentFiber.alternate.props.text !== currentFiber.props.text) {
currentFiber.stateNode.textContent = currentFiber.props.text
}
}
}
currentFiber.effectTag = null
}이렇게 commitWork 함수를 정의해줬습니다. 그러면 실제로 effect list를 순회하면서 commitWork를 호출하는 함수가 필요합니다. 그 함수는 commitRoot입니다.
const commitRoot = () => {
let currentFiber = workInProgressRoot.firstEffect
while (currentFiber) {
commitWork(currentFiber)
currentFiber = currentFiber.nextEffect
}
currentRoot = workInProgressRoot // Assign the current root fiber that is successfully rendered to currentRoot
workInProgressRoot = null
}이제 마지막입니다. requestIdleCallback에 넣어줄 workloop 함수를 정의해보겠습니다. 이 함수 안에서 render phase와 commit phase의 작업이 이루어질 것 입니다.
const workloop = (deadline) => {
let shouldYield = false // 작업을 할지 말지
while (nextUnitOfWork && !shouldYield) { // 여기가 render phase
nextUnitOfWork = performUnitOfWork(nextUnitOfWork)
shouldYield = deadline.timeRemaining() < 1 // performUnitOfWork작업을 한 후에 1ms도 남지 않았으면, 브라우저에게 다시 통제권을 넘길 것이다.
}
if (!nextUnitOfWork && workInProgressRoot) {
console.log('The end of the render stage ')
commitRoot() // 여기가 commit 단계. 여기서 effect list에 있는 모든 변경 사항을 view에 적용한다.
}
// Request the browser to reschedule another task
requestIdleCallback(workloop, { timeout: 1000 })
}결론 :
지금까지 저는 왜 'virtual dom의 성능이 더 좋은가'에 대한 질문에 대답하기 위해서 공부한 과정을 기록해보았습니다. 이 과정을 통해서 virtual dom이 무엇인지, 그것의 작동원리는 무엇인지 , 내부적으로는 어떻게 작동하는지, 그것이 탄생하게 된 배경은 무엇인지도 알아보았습니다.
추가적으로 virtual dom이 실제로 객체로 만들어지는 과정부터, 만들어진 객체가 실제 dom에 적용되는 순간까지 이루어지는 작업들도 알아보게 되었습니다.
이런 여정을 통해서 virtual dom의 성능이 더 나은 이유라고 던졌던 질문을 조금 더 가다듬을 필요가 있겠다는 생각이 들었습니다. '리액트의 렌더링 성능은 왜 좋은가?' 라는 질문이 훨씬 더 적합해보입니다.
이 질문에 짤막한 결론을 내려보자면 다음과 같습니다.
1.dom 전체를 렌더링시키지 않고, 메모리 상에서 필요한 부분만 찾아내 실제 dom에 적용시키기 때문에 좋다.
2.렌더링 작업을 스케줄링 할 수 있기 때문에 좋다.
virtual dom이라는 이름. 계속 사용해도 되는가?
자료를 찾다보니 virtual dom이라는 이름이 여러 의미로 혼용되어 사용되고 있다는 것을 알게 되었습니다. 심지어 dan abramov는 더 이상 이 이름을 사용하지 않는 것을 권한다고 합니다. 애시당초 이 virtual dom이라는 단어를 사용하게 된 것은, 2013년 당시 매번 render 할 때 마다 dom을 만든다고 착각할까봐 사용했던 단어라고 합니다. 이제는 그렇게 이해하고 있는 사람이 없는 것 같으니, 더 이상 사용하지 않는 것을 권하고 있었습니다. 굳이 사용하지 않을 것을 권하는 이유인즉, dom에 뭔가 문제가 있어서 virtual dom을 만든 것처럼 보이기 때문입니다. 사실상 그런 의미에서 virtual dom을 만든 것은 아닌데 말입니다.
그래서 dan abramov가 리액트에 대해 비유하는 단어가 있다면, 'Value UI'입니다. 제 생각에 이 단어를 권하는 이유라면, virtual dom 객체가 하나의 변수에 담겨있기 때문입니다. 변수 안에 리액트가 표현할 UI가 담겨있으니, 그렇게 사용하는 것을 권하는 것이 아닐까. 그런생각이 들었습니다.
남은 공부거리 :
사실 리액트 fiber를 공부하는 여정은 만만치 않았습니다. 그리고 지금 글을 다쓰고 나서도 아직도 이해하지 못한 개념이 많은 것 같습니다. 흐름만 파악한 상태이고, 리액트의 소스코드를 직접 확인하고 이해한 것이 아니다보니, 아직도 추상적으로 이해되는 부분들도 있는 것 같다는 생각입니다. 추가적으로 더 공부해보아야겠다는 생각이 들어 리스트로 정리해보았습니다.
- fiber는 우선순위를 어떻게 결정하는가?
- 완성된 작업물을 재사용한다고 했는데, 어떻게 재사용하는가?
- fiber 각각 프로세스의 소스코드 이해해보기
그리고 이런 내용들을 공부한 후 추가 글을 쓰던지, 이 글을 수정하는 방향으로 계속 나아가야겠습니다.
소감 :
저는 이번에 리액트를 공부하면서 머릿속을 떠나지 않았던 질문 'virtual dom 뭐가 그렇게 좋은거지?' 에 대답하고자 여러 자료를 탐독하는 시간을 가졌습니다. 이 과정을 통해서 느낀 점을 간단히 기록해보려합니다.
1.알고리즘과 자료구조 공부의 중요성 :
프론트엔드 개발자인데, 알고리즘과 자료구조 공부는 왜 해야하는걸까라는 의문을 종종 가질 때가 있었습니다. 그러나, 이번에 리액트의 작동원리를 이해하기 위해 노력하는 시간 동안 알고리즘과 자료구조의 중요성을 이해할 수 있었습니다. 내가 사용하는 라이브러리 내부에는 여러 자료구조와 알고리즘으로 구현되어 있습니다. 라이브러리를 더 잘 활용하고자 한다면 그 동작원리를 이해해야만 합니다. 그런데, 그 동작원리가 자료구조와 알고리즘으로 이루어져있는데, 그것을 알지 못하고 어떻게 동작원리를 제대로 이해할 수 있을까요?
또한 훗날 시니어 개발자가 되어 이런 라이브러리를 직접 구현하고자 한다면, 나 또한 이런 자료구조와 알고리즘을 자유자재로 활용하여 라이브러리를 구현할 줄 알아야 할 것입니다.
때문에 다시 한번 더 느끼게 되었습니다. 자료구조와 알고리즘, 기초는 잘 닦아두자.
2.영어공부의 중요성 :
virtual dom의 성능이 더 좋다는 것을 증명하는 글부터, react fiber의 원리를 설명하는 글까지 한글로 된 글은 몇 개 없을 뿐더러 제대로 된 글을 찾기가 어려웠습니다. 90%이상의 자료를 영어로 읽어야 했는데, 갈수록 영어공부의 중요성을 많이 느끼게 되는 것 같습니다.
한편으로 감사한 것은, 개발을 시작한 지 1년이 지난 지금, 영어 '독해' 실력이 정말 많이 늘었다는 것입니다. 요즘에는 한글로 된 글을 읽는 시간보다, 영어로된 글을 읽는 시간이 더 많은 것 같습니다.
지금까지 긴 글을 읽어주셔서 감사합니다. 잘못된 내용이 있다면 수정 댓글은 언제나 환영입니다!🙋🏻♂️
참고자료 :
현재로써 기억나는 참고자료만 남겨보겠습니다.
React Fiber Architecture
A Closer Look at React Fiber
The how and why on React’s usage of linked list in Fiber to walk the component’s tree
Inside Fiber: in-depth overview of the new reconciliation algorithm in React
what is react fiber
react-reconciler
reconciliation
What is the use of the Virtual DOM in React?
Reactjs | Virtual Dom
ReactJS | Introduction to JSX

15개의 댓글



글 잘 읽었습니다! 궁금한 점이 생겼는데요
"3.1 Vitual dom이 왜 더 빠른가?" 제목은 마치 Virtual DOM을 사용하는 것이 Real DOM만을 사용하는 것 보다 빠르다는 오해가 생길 수 있을것 같습니다.

와 이걸 다 정리하다니 대단하네요 ㄷㄷ 사족을 붙이자면 Virtual DOM 은 Real DOM 보다 빠르지 않습니다. '충분히 빠를' 뿐인거죠. Svelte 팀이 작성한 'Virtual DOM is pure overhead'(https://svelte.dev/blog/virtual-dom-is-pure-overhead) 를 읽어보시면 좋은데 'diffing + Real DOM' 이 Real DOM 보다 빠를 수는 없는거죠. Virtual DOM 이 빠르다! 라는 말이 나온건 그당시 존재했던 다른 프레임워크에 비해서 빠르다는 뜻이었습니다. 물론 그렇다고 리액트보다 Svelte 가 더 좋다! 라고 말할 순 없습니다. 도구의 유용함은 단순히 속도만 따지는 게 아니니까요.


와! 양질의 좋은 자료 너무 좋네요!! React를 쓰면서 왜 이렇게 동작 할 수 있는건지 궁금해하면서도 깊이있게 설명하는 자료는 많지 않았는데 잘 읽고 갑니다~