Node.js 에서 웹 크롤링하기

이번에 회사에 입사를 하게 되면서 사내 토이 프로젝트로 뉴스 게시판을 만들기로 하였습니다.
그에 따른 준비로 뉴스 데이터를 가지고 올 웹 크롤러를 Node 기반으로 만들었는데 이 경험을 공유하고자 합니다.
📚 목차
- 크롤링(Crawling)이란?
- 필요한 Library
- Examples
- 참고한 블로그들
1. 크롤링(Crawling)이란?
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. - Wiki
( 웹 스크래핑, 웹 수집 또는 웹 데이터 추출은 웹 사이트에서 데이터를 추출하기 위해 데이터를 가져오는 것을 말한다. - 위키 )
웹 크롤링(Web crawling)의 정식 명청은 Web Scraping 으로 주로 웹 페이지를 방문해서 필요한 데이터를 가져오는 것을 의미합니다. 주로 웹 크롤링에 대해 구글에 검색하면 Python을 통한 예제가 많이 나왔지만 저는 JavaScript만으로 구현하고 싶어 Node 환경에서 크롤러를 구현하는 것에 대해 조사하고 구현하였습니다.
2. 필요한 Library
제가 웹 크롤러를 구현하면서 사용한 라이브러리는 다음과 같습니다.
-
Axios : 브라우저와 Node 환경에서 사용하는 Promise 기반의 HTTP Client로 사이트의 HTML을 가져올 때 사용할 라이브러리입니다.
-
Cheerio : Node.js 환경에서 JQuery 처럼 DOM Selector 기능들을 제공합니다. Axios의 결과로 받은 데이터에서 필요한 데이터를 추출하는데 사용하는 라이브러리 입니다.
3. Examples
바로 예제로 들어가 보겠습니다.
우선 라이브러리들을 설치 합니다.
npm init -y
npm -i --save axios cheerio그리고 가져올 데이터를 정합니다.
저는 뉴스 기사들을 가져와 보겠습니다.
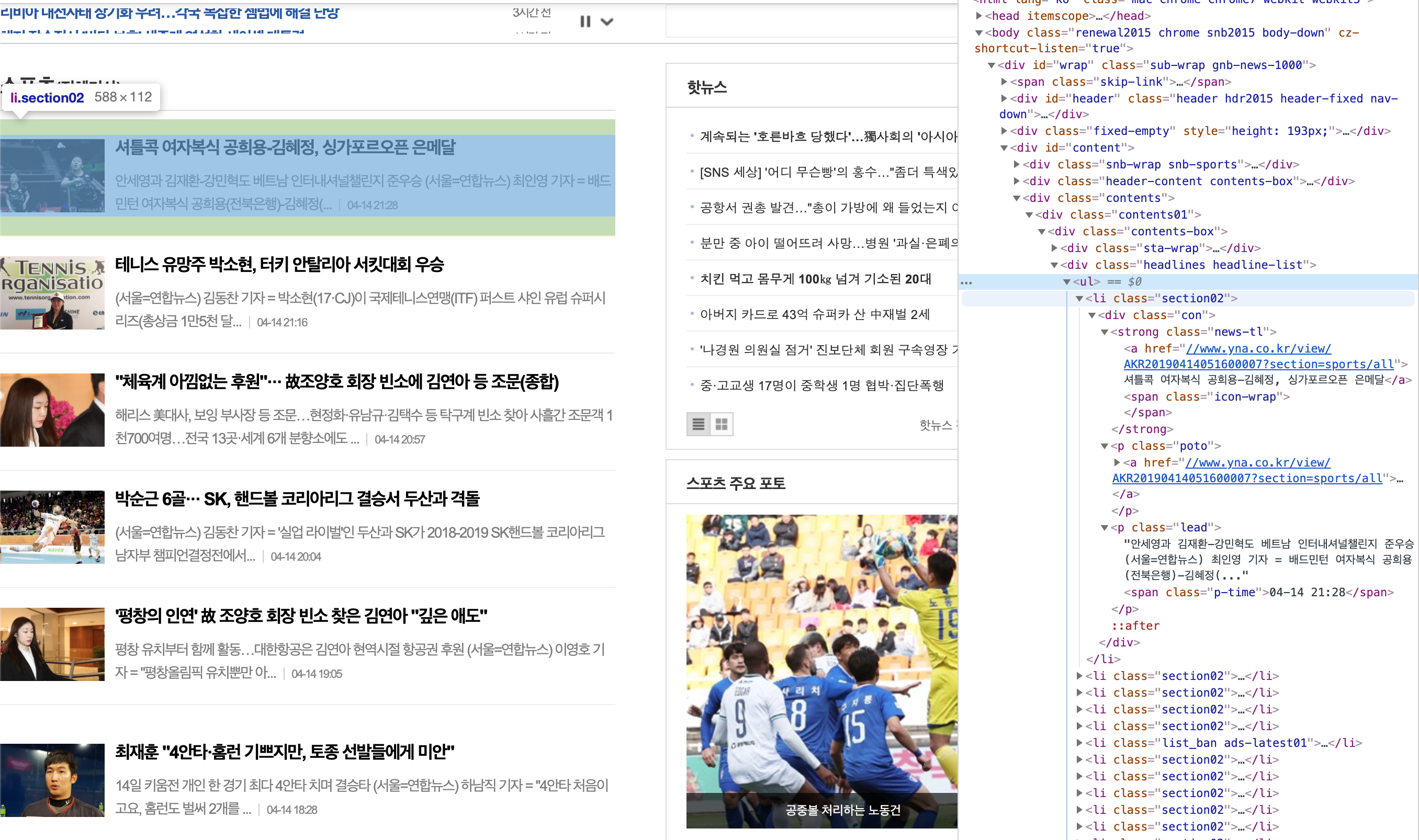
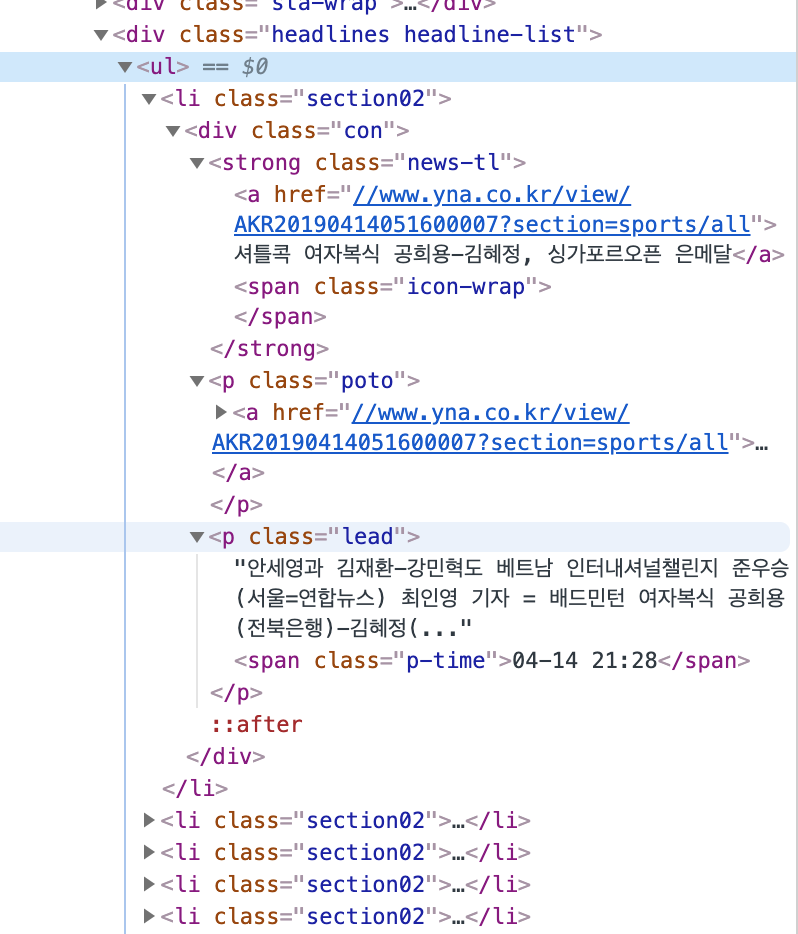
뉴스 목록에서 요소 검사를 눌러서 데이터를 가져올 HTML의 태그 이름과 Class 이름 목록을 정리합니다.
div.headlines
ul
li.section02저는 headlines라는 클래스 이름을 가지고 있는 div 태그 안의 ul 태그에서 section02라는 클래스 이름을 가진 li 태그들의 데이터를 가져오기로 하였습니다.
이제 axios와 cheerio를 사용하여 데이터를 가져오는 코드를 작성해 보겠습니다.
const axios = require("axios");
const cheerio = require("cheerio");
const log = console.log;
const getHtml = async () => {
try {
return await axios.get("https://www.yna.co.kr/sports/all");
} catch (error) {
console.error(error);
}
};
getHtml()
.then(html => {
let ulList = [];
const $ = cheerio.load(html.data);
const $bodyList = $("div.headline-list ul").children("li.section02");
$bodyList.each(function(i, elem) {
ulList[i] = {
title: $(this).find('strong.news-tl a').text(),
url: $(this).find('strong.news-tl a').attr('href'),
image_url: $(this).find('p.poto a img').attr('src'),
image_alt: $(this).find('p.poto a img').attr('alt'),
summary: $(this).find('p.lead').text().slice(0, -11),
date: $(this).find('span.p-time').text()
};
});
const data = ulList.filter(n => n.title);
return data;
})
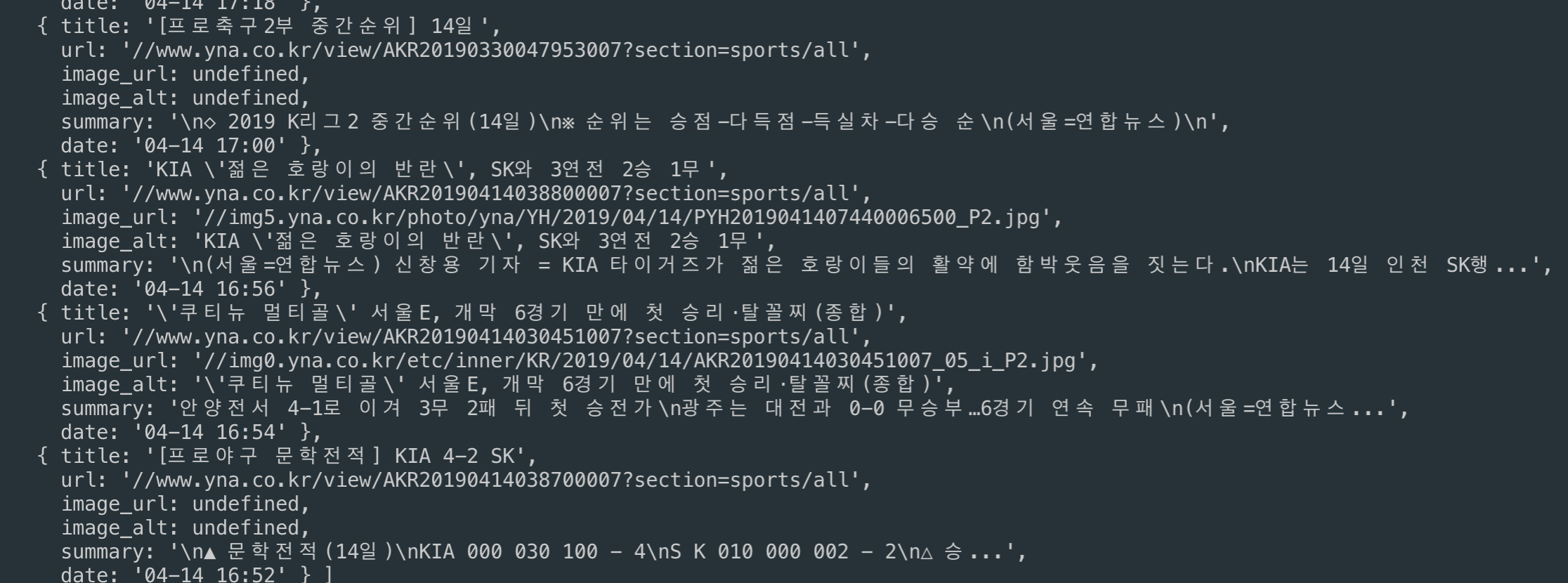
.then(res => log(res));코드를 설명 드리자면 getHtml 함수는 axios.get 함수를 이용하여 비동기로 스포츠 뉴스의 html 파일을 가져옵니다. 그 후 반환되는 Promise 객체에 cheerio를 이용하여 데이터를 가공합니다.
getHtml함수의 then 메서드의 내부 동작을 설명하기 전에 cheerio의 함수들의 기능들을 설명하겠습니다.
- load : 인자로 html 문자열을 받아 cheerio 객체를 반환합니다.
- children : 인자로 html selector를 문자열로 받아 cheerio 객체에서 선택된 html 문자열에서 해당하는 모든 태그들의 배열을 반환합니다.
- each : 인자로 콜백 함수를 받아 태그들의 배열을 순회 하면서 콜백함수를 실행합니다.
- find : 인자로 html selector 를 문자열로 받아 해당하는 태그를 반환합니다.
저는 이 cheerio의 함수들을 사용하여 뉴스의 html 페이지에서 제가 필요로 하는 뉴스 목록만을 반환 받아 log 함수로 출력하였습니다.
이로써 Node.js 환경에서 cheerio와 axios를 이용한 웹 크롤링을 해보았습니다.
4. 참고한 블로그들

8개의 댓글

안뇽하세요! 글 잘 읽었고 직접 해보고 성공해보기도 했네요ㅎㅎ
그런데 const $ = cheerio.load(html.data);
title: $(this).find('strong.news-tl a').text(),
에서 왜 $에 cheerio 객체반환을 한 것인지?
그리고 $(this)는 무엇인지 물어볼 수 있을까요?
$(this)는 제 실력부족인지 무슨 방식의 문법인지를 모르겠네요
답변 부탁드리겠습니다!


최신 상태로 업데이트 해 보았습니다.
const axios = require("axios");
const cheerio = require("cheerio");
const log = console.log;
const getHtml = async () => {
try {
return await axios.get("https://www.yna.co.kr/sports/all");
} catch (error) {
console.error(error);
}
};
getHtml()
.then(html => {
let ulList = [];
const $ = cheerio.load(html.data);
const $bodyList = $("div.list-type038 ul.list li").children("li div.item-box01");
$bodyList.each(function(i, elem) {
ulList[i] = {
title: $(this).find('div.news-con a.tit-wrap strong.tit-news').text(),
url: $(this).find('div.news-con a.tit-wrap').attr('href'),
image_url: $(this).find('figure.img-con a img').attr('src'),
image_alt: $(this).find('figure.img-con a img').attr('alt'),
summary: $(this).find('p.lead').text().slice(0, -11),
date: $(this).find('div.info-box01 span.txt-time').text()
};
});
const data = ulList.filter(n => n.title);
return data;
})
.then(res => log(res));$ node sports_news.js
[
{
title: `[올림픽] '피겨퀸' 김연아 곁에 선 피겨 후배들…"도핑 반대"`,
url: '//www.yna.co.kr/view/AKR20220215048400007?section=sports/all',
image_url: '//img0.yna.co.kr/photo/yna/YH/2022/02/14/PYH2022021423730001300_P2.jpg',
image_alt: `[올림픽] '피겨퀸' 김연아 곁에 선 피겨 후배들…"도핑 반대"`,
summary: "김예림, 최다빈, 이시형…김연아 '반도핑 메시지' 공유\n직간접적으로 발리예바의 올림픽 출전 허용 ",
date: '02-15 09:58'
},
{
title: '"시진핑 등 중국 지도부 안 보여…집단격리 중인듯"',
url: '//www.yna.co.kr/view/AKR20220215049300074?section=sports/all',
image_url: '//img1.yna.co.kr/photo/yna/YH/2022/02/04/PYH2022020425250001300_P2.jpg',
image_alt: '"시진핑 등 중국 지도부 안 보여…집단격리 중인듯"',
summary: '\n(홍콩=연합뉴스) 윤고은 특파원 = 베이징 동계올림픽 개막식 전후로 대면 외교를 펼친 시진핑(習近平) 주석 등 ',
date: '02-15 09:56'
},
{
title: "'여자부 최고' 라시츠케네와 찰칵…우상혁, 높이뛰기 월드클래스",
url: '//www.yna.co.kr/view/AKR20220215047600007?section=sports/all',
image_url: '//img3.yna.co.kr/etc/inner/KR/2022/02/15/AKR20220215047600007_02_i_P2.jpg',
image_alt: "'여자부 최고' 라시츠케네와 찰칵…우상혁, 높이뛰기 월드클래스",
summary: "우상혁은 2021-2022시즌 실내육상 세계랭킹 1위\n(서울=연합뉴스) 하남직 기자 = 육상 높이뛰기 여자부 '현",
date: '02-15 09:55'
},
{
title: "[올림픽] 스노보드 경기에서 잇따른 판정 논란…'선수 인생이 걸린 문제'",
url: '//www.yna.co.kr/view/AKR20220215048500007?section=sports/all',
image_url: '//img9.yna.co.kr/photo/ap/2021/12/19/PAP20211219093301009_P2.jpg',
image_alt: "[올림픽] 스노보드 경기에서 잇따른 판정 논란…'선수 인생이 걸린 문제'",
summary: '슬로프스타일·하프파이프·빅에어에서 계속되는 판정 시비\n(베이징=연합뉴스) 김동찬 기자 = 2022 베이징 동',
date: '02-15 09:54'
},
{
title: '우즈가 불러 모은 세계 톱10…제네시스 인비테이셔널 17일 개막',
url: '//www.yna.co.kr/view/AKR20220215047000007?section=sports/all',
image_url: '//img4.yna.co.kr/etc/inner/KR/2022/02/15/AKR20220215047000007_01_i_P2.jpg',
image_alt: '우즈가 불러 모은 세계 톱10…제네시스 인비테이셔널 17일 개막',
summary: '세계랭킹 10위 이내 전원 출전…임성재·김시우·이경훈, 시즌 첫 우승 도전장\n(서울=연합뉴스',
date: '02-15 09:51'
},
{
title: "美 TV에 뜬 공짜 비트코인 QR코드…접속 폭주에 앱사이트 '먹통'",
url: '//www.yna.co.kr/view/AKR20220215044000075?section=sports/all',
image_url: '//img6.yna.co.kr/etc/inner/KR/2022/02/15/AKR20220215044000075_01_i_P2.jpg',
image_alt: "美 TV에 뜬 공짜 비트코인 QR코드…접속 폭주에 앱사이트 '먹통'",
summary: "가상화폐거래소 코인베이스, '15달러 비트코인 증정' 슈퍼볼 광고\n(로스앤젤레스=연합뉴스) 정윤섭 특파원 = 미국",
date: '02-15 09:49'
},
{
title: '[올림픽] WADA "러시아측이 발리예바 신속 검사 요청 안했다"',
url: '//www.yna.co.kr/view/AKR20220215042600007?section=sports/all',
image_url: '//img1.yna.co.kr/photo/yna/YH/2022/02/14/PYH2022021422570001300_P2.jpg',
image_alt: '[올림픽] WADA "러시아측이 발리예바 신속 검사 요청 안했다"',
summary: '\n(서울=연합뉴스) 장현구 기자 = 도핑 검사에서 양성 반응을 보인 카밀라 발리예바(16·러시아올림픽',
date: '02-15 09:36'
},
{
title: '[올림픽] 일본 10-5로 꺾은 한국 컬링 시청률 23.7%',
url: '//www.yna.co.kr/view/AKR20220215041500005?section=sports/all',
image_url: '//img6.yna.co.kr/photo/yna/YH/2022/02/15/PYH2022021500230001300_P2.jpg',
image_alt: '[올림픽] 일본 10-5로 꺾은 한국 컬링 시청률 23.7%',
summary: '\n(서울=연합뉴스) 강애란 기자 = 2022 베이징 동계올림픽에서 일본을 꺾은 한국 여자 컬링 대표팀의 경기 ',
date: '02-15 09:35'
},
{
title: `[올림픽] 마리화나 검출로 '도쿄 불발' 리처드슨 "발리예바는 백인이니까"`,
url: '//www.yna.co.kr/view/AKR20220215030400007?section=sports/all',
image_url: '//img9.yna.co.kr/etc/inner/KR/2022/02/15/AKR20220215030400007_02_i_P2.jpg',
image_alt: `[올림픽] 마리화나 검출로 '도쿄 불발' 리처드슨 "발리예바는 백인이니까"`,
summary: "리처드슨은 모친상 슬픔에 마리화나 복용해 도쿄올림픽 출전권 반납\n발리예바의 개인전 출전에 '인종 차별' 주장하며 ",
date: '02-15 08:46'
},
{
title: '생일 맞은 에릭센, 심장마비 8개월 만에 친선전 출전…도움 기록',
url: '//www.yna.co.kr/view/AKR20220215031200007?section=sports/all',
image_url: '//img9.yna.co.kr/etc/inner/KR/2022/02/15/AKR20220215031200007_01_i_P2.jpg',
image_alt: '생일 맞은 에릭센, 심장마비 8개월 만에 친선전 출전…도움 기록',
summary: '\n(서울=연합뉴스) 최송아 기자 = 심장마비로 쓰려졌다가 회복해 그라운드 복귀를 준비해 온 미드필더 크리스티안 에릭',
date: '02-15 08:45'
},
{
title: '[올림픽] 日언론 "또 한국에…여자 컬링 한국에 설욕 못 해"',
url: '//www.yna.co.kr/view/AKR20220215025100073?section=sports/all',
image_url: '//img8.yna.co.kr/photo/yna/YH/2022/02/14/PYH2022021424980001300_P2.jpg',
image_alt: '[올림픽] 日언론 "또 한국에…여자 컬링 한국에 설욕 못 해"',
summary: '\n(도쿄=연합뉴스) 박성진 특파원 = 14일 열린 베이징 동계올림픽 여자 컬링 경기에서 일본 대표팀이 한국에 패하자 ',
date: '02-15 08:31'
},
{
title: '[올림픽] 깜박이지 않는 컬링 스톤…전자장치 결함에 작동 중단',
url: '//www.yna.co.kr/view/AKR20220215025700007?section=sports/all',
image_url: '//img7.yna.co.kr/photo/yna/YH/2022/02/14/PYH2022021424120001301_P2.jpg',
image_alt: '[올림픽] 깜박이지 않는 컬링 스톤…전자장치 결함에 작동 중단',
summary: '\n(서울=연합뉴스) 임순현 기자 = 14일 한국과 일본의 2022 베이징동계올림픽 컬링 여자 풀리그 6차전에',
date: '02-15 08:23'
},
{
title: '여자핸드볼 SK 슈가글라이더즈, 광명 홈 경기에 팬 초청 행사',
url: '//www.yna.co.kr/view/AKR20220215021800007?section=sports/all',
image_url: '//img4.yna.co.kr/etc/inner/KR/2022/02/15/AKR20220215021800007_01_i_P2.jpg',
image_alt: '여자핸드볼 SK 슈가글라이더즈, 광명 홈 경기에 팬 초청 행사',
summary: '\n(서울=연합뉴스) 김동찬 기자 = 여자 실업핸드볼 SK 슈가글라이더즈가 경기도 광명시 홈 팬들을 위한 행사',
date: '02-15 07:57'
},
{
title: "'이강인 교체 투입' 마요르카, 빌바오에 3-2 승리…15위 도약",
url: '//www.yna.co.kr/view/AKR20220215020800007?section=sports/all',
image_url: '//img2.yna.co.kr/photo/etc/epa/2022/02/15/PEP20220215078501009_P2.jpg',
image_alt: "'이강인 교체 투입' 마요르카, 빌바오에 3-2 승리…15위 도약",
summary: '\n(서울=연합뉴스) 장보인 기자 = 이강인(21)이 후반 교체 투입된 스페인 프로축구 마요르카가 빌바오에 극적인 승',
date: '02-15 07:50'
},
{
title: "AFC U-23 아시안컵 17일 조 추첨…'2연패 도전' 한국 1번 포트",
url: '//www.yna.co.kr/view/AKR20220215018700007?section=sports/all',
image_url: '//img2.yna.co.kr/photo/yna/YH/2021/10/31/PYH2021103114060001300_P2.jpg',
image_alt: "AFC U-23 아시안컵 17일 조 추첨…'2연패 도전' 한국 1번 포트",
summary: '\n(서울=연합뉴스) 배진남 기자 = 우리나라가 대회 2회 연속 우승을 노리는 올해 아시아축구연맹(AFC) ',
date: '02-15 07:31'
},
{
title: '[월드&포토] 슈퍼볼 우승에 과격해진 LA 팬들, 약탈에 총격까지',
url: '//www.yna.co.kr/view/AKR20220215005400075?section=sports/all',
image_url: '//img3.yna.co.kr/etc/inner/KR/2022/02/15/AKR20220215005400075_01_i_P2.jpg',
image_alt: '[월드&포토] 슈퍼볼 우승에 과격해진 LA 팬들, 약탈에 총격까지',
summary: '경찰 "승리 더럽혀선 안 돼"…시위진압 무기 동원해 강제 해산\n(로스앤젤레스=연합뉴스) 정윤섭 특파원 = 지난 13',
date: '02-15 07:10'
},
{
title: '권순우, 카타르 엑손모바일오픈 테니스 대회 16강 진출',
url: '//www.yna.co.kr/view/AKR20220215013100007?section=sports/all',
image_url: '//img6.yna.co.kr/photo/etc/af/2022/02/11/PAF20220211050801009_P2.jpg',
image_alt: '권순우, 카타르 엑손모바일오픈 테니스 대회 16강 진출',
summary: '\n(서울=연합뉴스) 김동찬 기자 = 권순우(55위·당진시청)가 남자프로테니스(ATP) 투어 카타르 엑손모바일오',
date: '02-15 06:54'
},
{
title: "[올림픽] 한국 쇼트트랙, 16일 여자 1,500m·남자 계주서 '마지막 질주'",
url: '//www.yna.co.kr/view/AKR20220215001600007?section=sports/all',
image_url: '//img4.yna.co.kr/photo/yna/YH/2022/02/14/PYH2022021424720001300_P2.jpg',
image_alt: "[올림픽] 한국 쇼트트랙, 16일 여자 1,500m·남자 계주서 '마지막 질주'",
summary: "한일전 쾌승 거둔 컬링, 스위스·덴마크와 2연전…4강행 '분수령'\n(베이징=연합뉴스) 안홍석 기자 = 여러 난관을",
date: '02-15 06:18'
},
{
title: '[올림픽] 피겨 유영·김예림, 오늘 쇼트프로그램…상위권 도전',
url: '//www.yna.co.kr/view/AKR20220215001700007?section=sports/all',
image_url: '//img8.yna.co.kr/photo/yna/YH/2022/02/14/PYH2022021422560001300_P2.jpg',
image_alt: '[올림픽] 피겨 유영·김예림, 오늘 쇼트프로그램…상위권 도전',
summary: '\n(베이징=연합뉴스) 안홍석 기자 = 피겨 여자 싱글 유영과 김예림(이상 수리고)이 15일 상위권 도전에 나선',
date: '02-15 06:17'
},
{
title: '◇내일의 올림픽(16일)',
url: '//www.yna.co.kr/view/AKR20220214126500007?section=sports/all',
image_url: '//img1.yna.co.kr/etc/graphic/YH/2022/02/14/GYH2022021400230004400_P2.jpg',
image_alt: '◇내일의 올림픽(16일)',
summary: '\n◆16일(수)\n△컬링= 여자 단체전 한국-스위스(10시05분) 한국-덴마크(21시05분·이상 국립 아쿠',
date: '02-15 06:16'
},
{
title: '◇오늘의 올림픽(15일)',
url: '//www.yna.co.kr/view/AKR20220214126400007?section=sports/all',
image_url: '//img6.yna.co.kr/etc/graphic/YH/2022/02/14/GYH2022021400190004402_P2.jpg',
image_alt: '◇오늘의 올림픽(15일)',
summary: '\n◆15일(화)\n△빙상= 스피드스케이팅 남자 팀 추월 5-6위전 한국-캐나다(15시30분·국립 스피드스케',
date: '02-15 06:15'
},
{
title: '◇내일의 경기(16일)',
url: '//www.yna.co.kr/view/AKR20220214150700007?section=sports/all',
image_url: undefined,
image_alt: undefined,
summary: '\n◆16일(수)\n△프로농구= DB-KCC(19시·원주종합체육관)',
date: '02-15 06:15'
},
{
title: '◇오늘의 경기(15일)',
url: '//www.yna.co.kr/view/AKR20220214150600007?section=sports/all',
image_url: undefined,
image_alt: undefined,
summary: '\n' +
'◆15일(화)\n' +
'△프로농구= 인삼공사-kt(안양체육관) 현대모비스-SK(울산동천체육관) 삼성-한국가스공사(잠실실내체육관·이상 19시)',
date: '02-15 06:15'
},
{
title: "-올림픽- '또 너냐'…여자 아이스하키, 베이징서도 미국-캐나다 결승 격돌",
url: '//www.yna.co.kr/view/AKR20220215001500007?section=sports/all',
image_url: '//img5.yna.co.kr/photo/reuters/2022/02/15/PRU20220215006401009_P2.jpg',
image_alt: "-올림픽- '또 너냐'…여자 아이스하키, 베이징서도 미국-캐나다 결승 격돌",
summary: '미국·캐나다, 각각 핀란드·스위스 따돌리고 17일 결승서 또 만나\n(서울=연합뉴스) 신창용 기자 = 2022 베이징',
date: '02-15 00:35'
},
{
title: '-올림픽- 한국 컬링, 일본에 10-5 완승…3승 3패로 공동 5위(종합)',
url: '//www.yna.co.kr/view/AKR20220214168751007?section=sports/all',
image_url: '//img3.yna.co.kr/photo/yna/YH/2022/02/15/PYH2022021500060001300_P2.jpg',
image_alt: '-올림픽- 한국 컬링, 일본에 10-5 완승…3승 3패로 공동 5위(종합)',
summary: '\n(베이징=연합뉴스) 김동찬 기자 = 한국 여자 컬링 대표팀이 일본을 꺾고 2022 베이징 동계올림픽 4강 진',
date: '02-15 00:23'
}
]
웹 애플리케이션을 만들때에, get 방식으로 rest api 를 만드는데, 타 웹사이트에서 크롤링 한 결과값으로 json 을 만들어서 반환해서 줄 수도 있나요? 방법을 모르겠다기 보다는 가능한지 불가능한지 여부를 여쭙고 싶습니다!