
IDA 대구소프트웨어마이스터고등학교 입학 원서 서비스
우리학교에 들어오려면 모든 학생이 한번쯤은 겪는 사이트가 있다.
IDA 입학 원서 사이트이다.
입학시즌에 맞춰 개발 및 유지보수를 하고 서비스를 진행하는데 원서 접수 기간에 동시다발적인 원서 접수가 발생하고 트래픽이 급증한다.
이를 안정적으로 처리하여 2달간 인프라를 담당하는게 이번 나의 임무가 되겠다!
대용량 트래픽 처리

이렇게라도대용량트래픽처리를경험해야지..나도이제중고신입할래
대용량 트래픽 처리를 안정적으로 하기 위하여는 인프라를 잘 설계할 필요가 있다.
먼저 우리 서버를 사용하는 인원을 파악해보자.
내가 입학한 2023년 기준 학교 입학 경쟁률은 3:1 인원을 74명을 뽑았으니 대략 200명 정도가 사이트를 이용한다고 생각을 하고 안정적으로 500명정도로 인원을 잡겠다.
(2024년 기준으로 접수된 원서는 184개라고 한다)
원서 접수 사이트 특성상 특정시간에 트레픽이 급증하니 이를 안정적으로 처리하는게 강권이다.
이를 어떻게 안정적으로 처리할까?
쿠버네티스를 사용하자!
쿠버네티스의 특징을 구글에 검색하면 아래와 같은 글을 볼 수 있다.
-
컨테이너화된 애플리케이션 배포 컨테이너로 패키징된 애플리케이션을 여러 대의 컴퓨터 또는 클라우드 인프라에 쉽게 배포할 수 있습니다.
-
자동 스케일링(auto scaling) 애플리케이션의 부하에 따라 자동으로 서버를 늘리거나 줄일 수 있어 트래픽 증가에 대처하기 용이합니다.
-
고가용성(high availability) 애플리케이션을 여러 서버에 복제하여 하나의 서버에 장애가 발생해도 시스템이 계속 동작할 수 있게 합니다.
-
자동 복구(self-healing) 애플리케이션의 문제 또는 장애가 발생하면 자동으로 복구하거나 롤백할 수 있어 시스템 신뢰성을 높입니다.
어쩌면 우리 IDA 같은 서비스에 적합한게 아닐까...? 라고 생각을 했지만
난 데브옵스 엔지니어가 아니다! (원래는 그냥 서버개발자)
그리고 제한된 예산과 짧은 기간안에 쿠버네티스를 완벽하게 습득하여 서비스를 할 수도 없을 뿐더러 2달이라는 서비스기간에 모놀리스서버를 쿠버네티스를 사용해 돌린다..?
이건 오버엔지니어링이라 판단되어 다른방법을 찾아보았다.
서버를 여러 대 두고 로드밸런싱을 하자!
급증하는 트래픽을 분산 처리하기 위해 로드밸런서를 앞단에 두고, 뒤에 여러 서버를 배치하여 트래픽을 분산 처리하려고 한다.
로드밸런싱에는 Nginx를 사용할 예정이다. 다양한 로드밸런서가 있지만, Nginx는 가장 많이 사용되며, 가볍고 빠르게 설정할 수 있기 때문에 선택하였다.
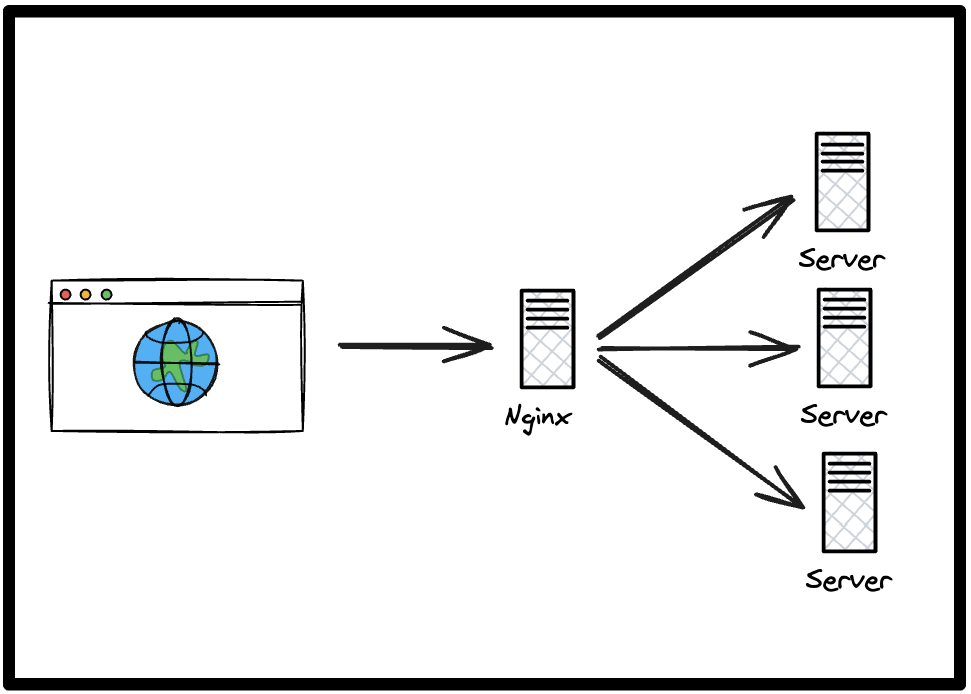
위와 같이 Web에서 요청이 들어오면 Nginx가 트래픽을 각 서버에 분산하여 요청을 보내고, 한 서버가 중단되더라도 다른 서버가 요청을 감당할 수 있다. 또한, 이슈가 발생했을 때 무중단 배포가 가능하여 이러한 방식을 채택하였다.
500명의 트래픽을 견딜 서버 스팩을 구성해보자!
선배에게 작년엔 어떻게 인프라를 구성했는지 여쭤보았다.
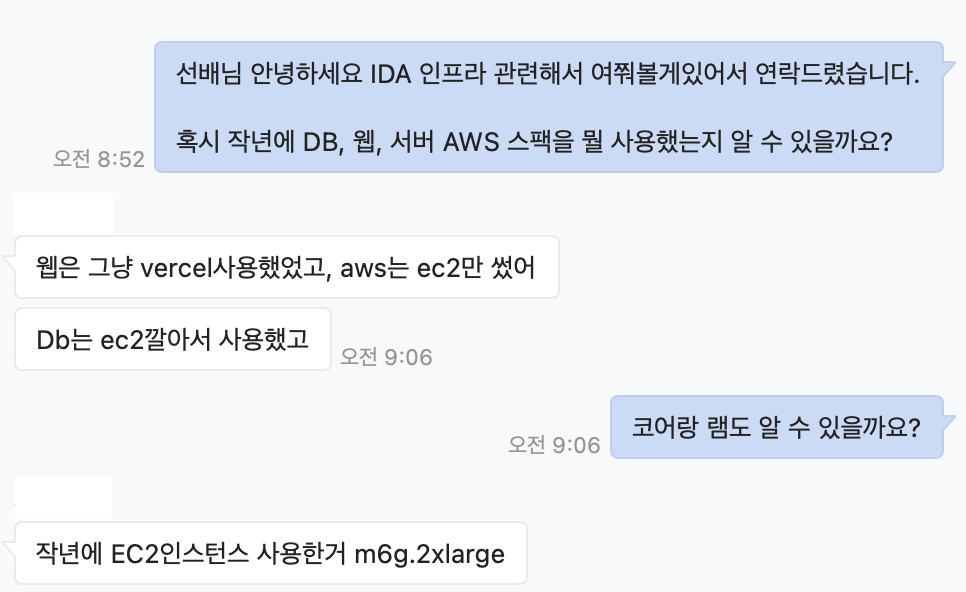
AWS m6g.2xlarge는 8코어 32기가로 괴물같은 녀석이다...
저 서버 1대로 디비, 메인 was 서버로 사용했다고 전달받았다.
(사실은 저렇게 세팅하고 작년 원서 기간때 CPU와 램이 한참 남아돌았다고한다..)
큼큼
하지만 이번엔 로드밸런서를 두고 분산처리를 하는게 목적이니 이에 맞는 구성을 찾을 필요가 있었다.
대략적으로 필요한 서버 갯수는
로드밸런서 (1대), 메인서버 (2대), 모니터링서버(1대), 디비(1대)
총 5대로 스팩은
t4g.medium [2c 4g 0.04] 2대 (메인서버)
t4g.small [2c 2g 0.02] 2대 (로드밸런서, 모니터링)
db.t4g.medium [2c 2g 0.1] 1대 (디비)
으로 결정하였다.
[ ] <- 순서대로 코어 램 시간당 가격($)
RDS가 동일 스팩 EC2와 비용차이가 5배 이상 나는걸 확인했고, EC2에서 도커로 디비를 올릴까 생각했는데 백업이나 안정성 때문에 그냥 RDS를 사용하기로 했다.
또한 안정적인 서버 운영을 위해 로드밸런서 서버와 메인서버를 모니터링하기 위한 독립서버도 구축하고자 한다 (Prometheus & Grafana 사용예정)
2달간 서버운영 예상비용은 대략 60만원 정도 잡았고 이는 학교에서 지원해준다.
(서버 세팅도 경험하고 운영도 경험하고 내가하고싶은대로 세팅하는데 돈을 지원해준다? 이거 못참지 ㅎㅎ)
서버 플로우
그래서 대략적으로 구성한 서버 플로우는 다음과 같다.
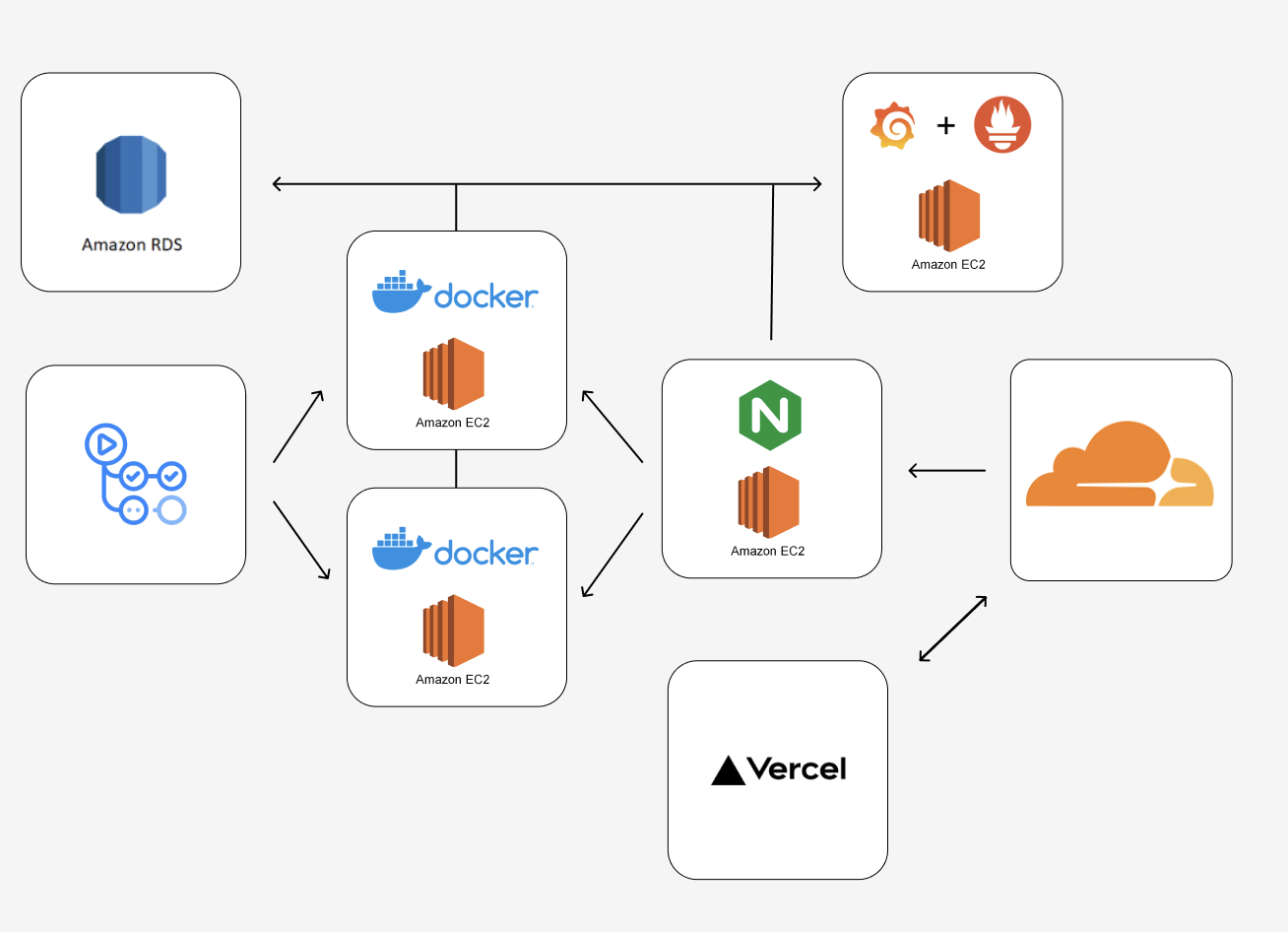
프론트는 Vercel에 배포하기로 하였고, 도메인을 묶기 위해 Cloudflare에 도메인을 두고 Vercel 혹은 서버로 요청이 가도록 하였다.
서버로 가는 요청은 Nginx를 통해 로드 밸런싱되며, 뒷단에 2개의 서버에 라운드로빈 알고리즘으로 각각 요청을 처리하여 분산 처리를 하도록 구성하였다. 각 서버는 독립 서버에 Prometheus로 메트릭을 보내고, 이를 Grafana를 통해 시각화하는 모니터링 서버를 구축하였다.
모니터링 및 알림 시스템 구축기
안정적인 서버 운영을 위해서 모니터링은 꼭 있어야 하는 존재라 생각하여 모니터링 서버 외 다른 시스템 구축도 하였다.
먼저 오류가 발생했을때 누구보다 먼저 이 문제들을 해결해야하는게 개발자인 만큼 오류보고 시스템을 어떻게 구성하였는지 알아보자!
Sentry
Sentry는 어플리케이션에서 오류가 발생하면 알려주는 에러 트래킹 서비스이며 Spring Boot 에 간편하게 적용할 수 있다.
보통은 개발과정에선 알람을 안보내게 설정하지만 무료체험기간이라 그냥 보내도록 설정해뒀다.
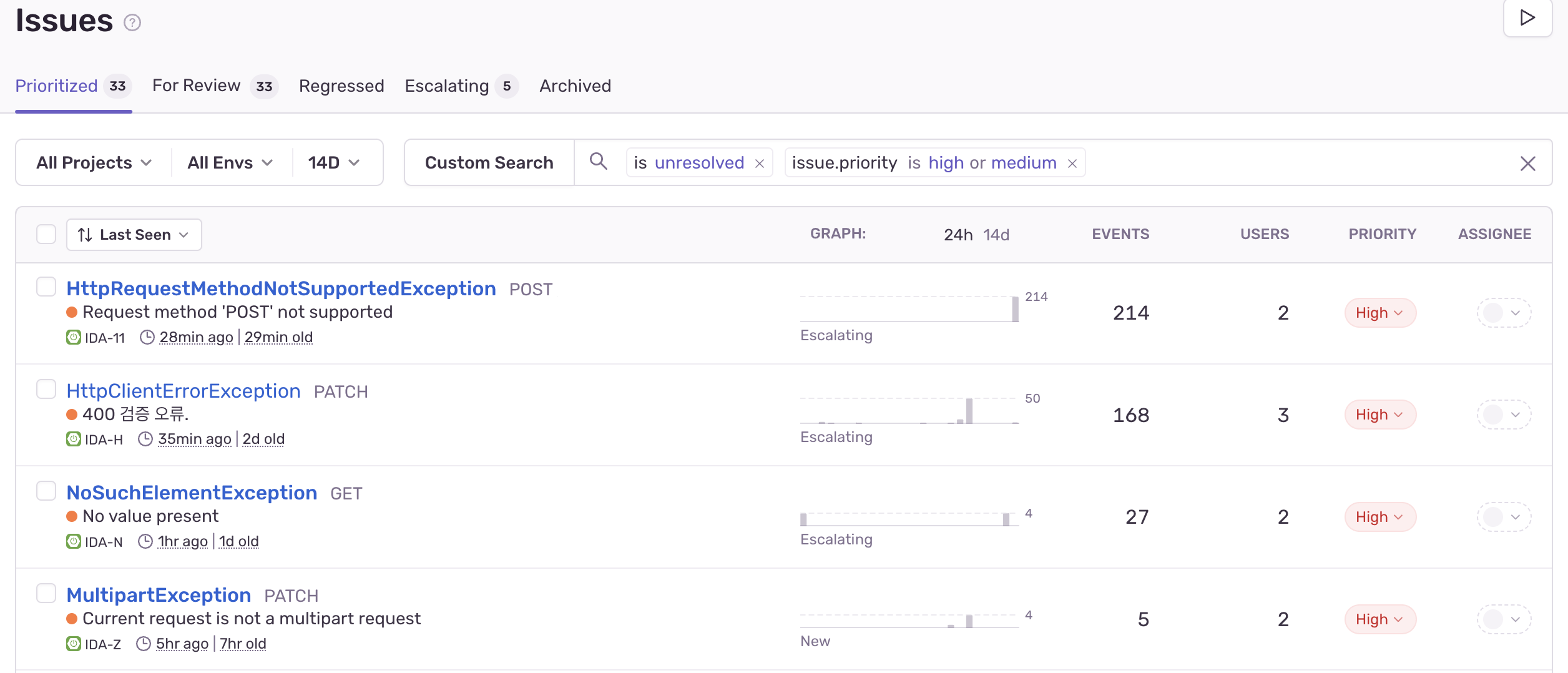
위와 같이 어떤 오류가 발생했는지 확인 가능하며
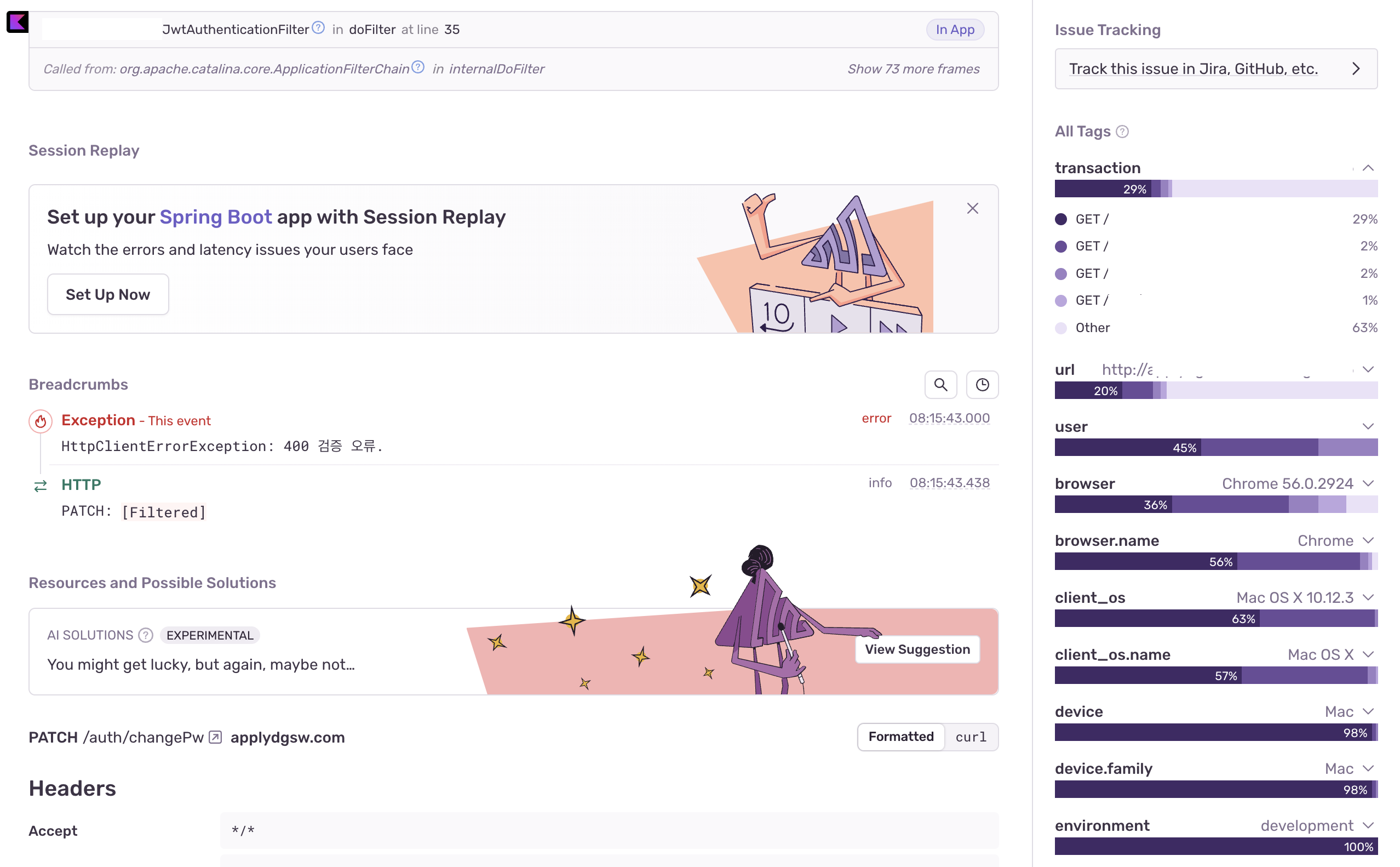
코드의 어느부분에서 오류가 생겼는지, 어떤 요청들에서 발생했는지, 요청 url, 요청한 유저의 IP, 요청한 브라우저, 요청한 사람의 OS 정보까지 알 수 있다.
Discord Alert
디스코드의 웹 훅 기능을 이용하여 오류보고 챗봇을 스프링에 붙혀두었다.
오류가 발생하면 설정해둔 디스코드 채널로 오류보고를 진행하여 프론트, 서버 모두 빠르게 오류를 확인 가능하다.
오류가 발생시 디스코드 알림이 오게하여 누구보다 빠르게 문제를 확인한 후 Sentry로 가 자세한 정보 분석 후 코드를 수정하도록 하여 직접 서버에 접속하지 않도록 하는게 이 시스템 구축 목적이다.
Prometheus + Grafana
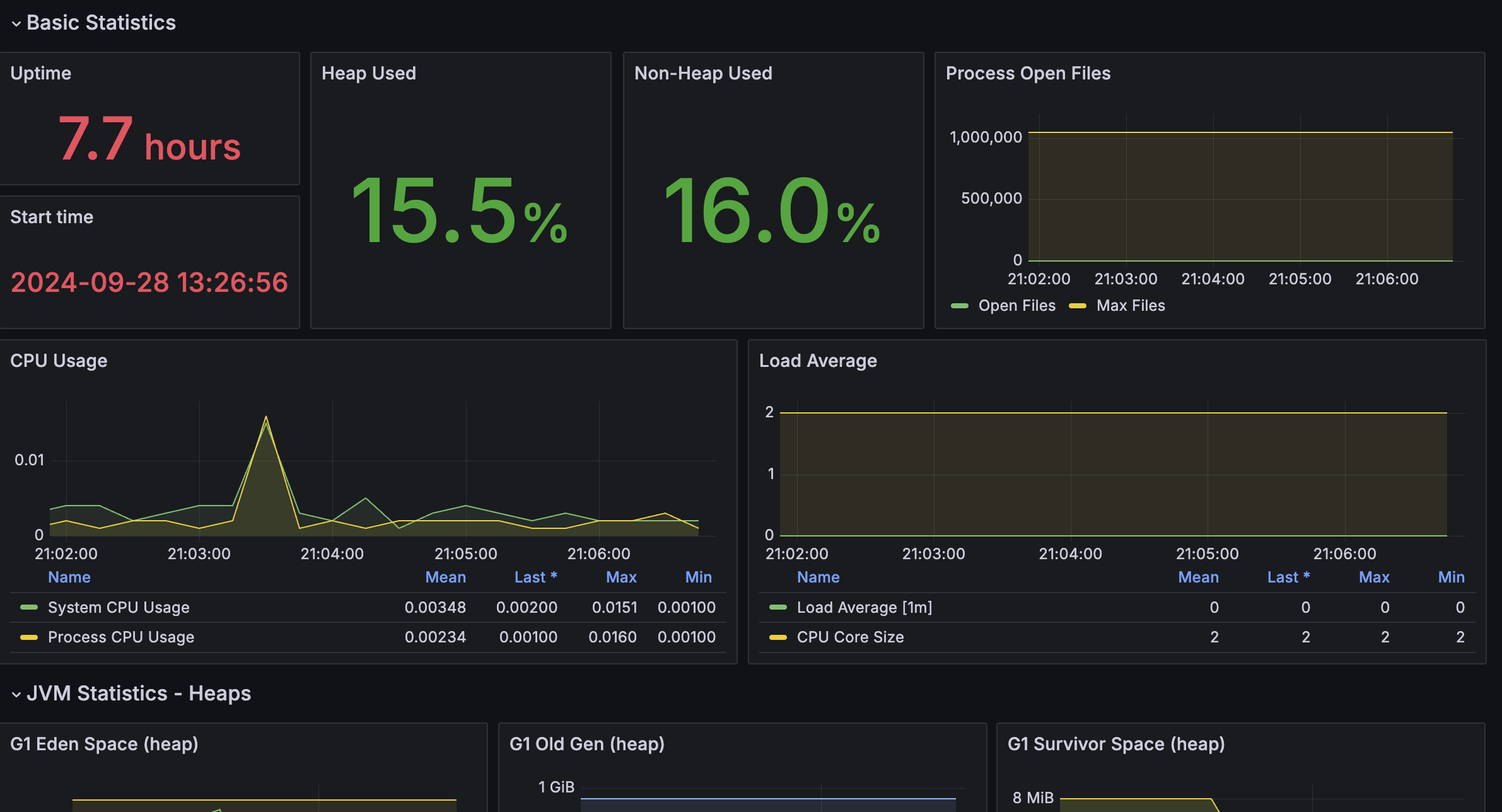
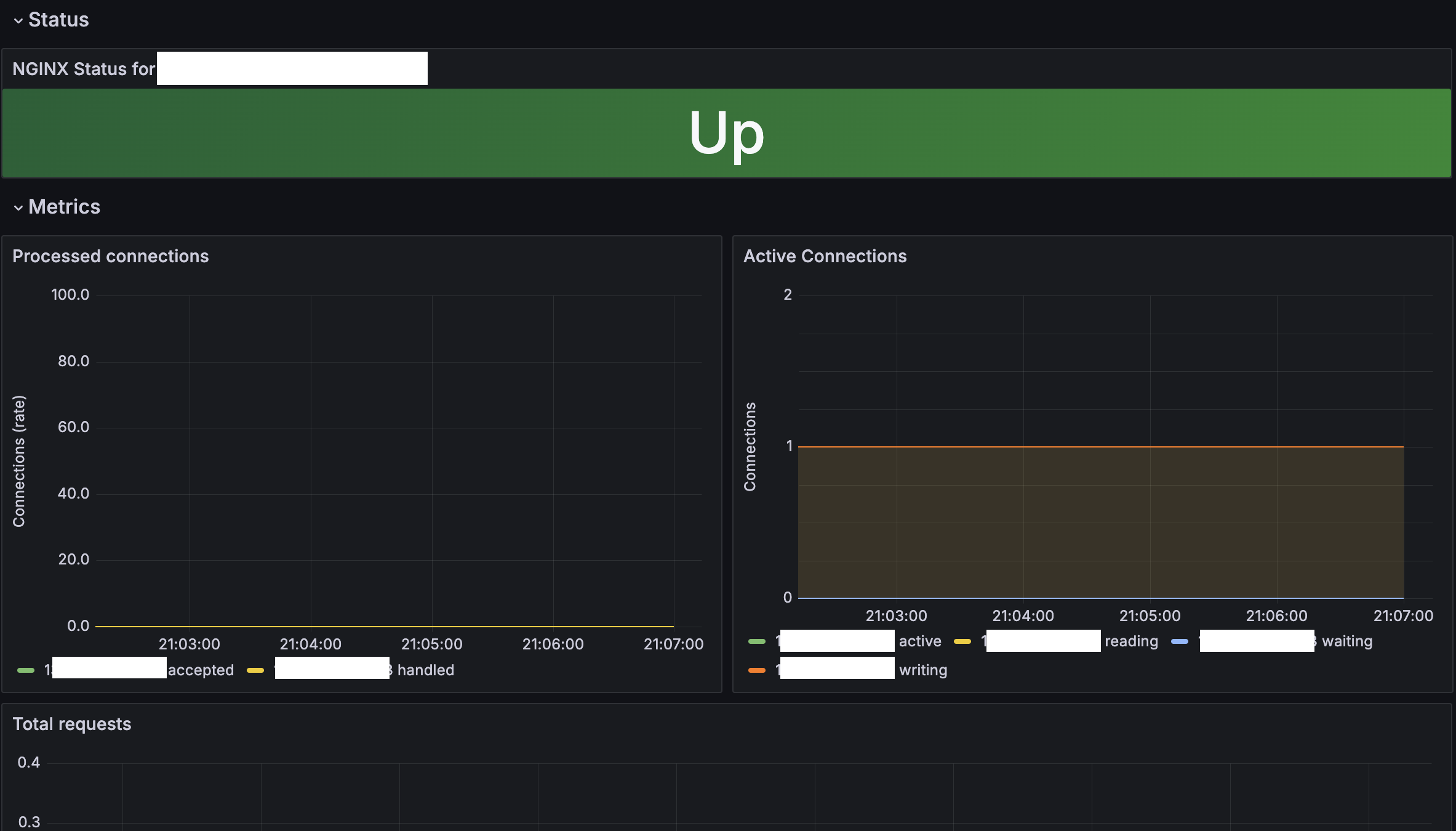
Spring Acturator 다양한 메트릭을 수집하여 시각화 하기 위하여 위 기술을 사용했고 Nginx의 메트릭도 같이 수집하여 한눈에 서버 상태를 확인 할 수 있도록 하였다.
이로서 인프라 담당자가 아니여도 서버를 모니터링할 수 있는 환경을 만들었다.
실제로 트래픽을 견뎌보자!
저렇게 인프라 구성을 빵빵하게 해둬도 테스트를 해보지 않으면 말짱 도루묵
K6 + Grafana + InfluxDB 를 통해 테스트 + 시각화를 해보았다.
K6 테스트 환경은 로컬에서 실행했으며 M3 pro 32g 인 맥북프로로 테스트를 진행하였다.
맥북 -> Cloudflare -> Nginx -> EC2 순이다.
500명의 유저가 자신의 정보를 수정하고 조회한다 해보자.
응답 요청값은
const payload = JSON.stringify({
1: getRandom1(),
2: `User-${Math.floor(Math.random() * 10000)}`,
3: getRandom2(),
4: `010-${Math.floor(Math.random() * 1000)}-${Math.floor(Math.random() * 10000)}`,
});매번 다르게 나오도록 설정하고 요청하였다.
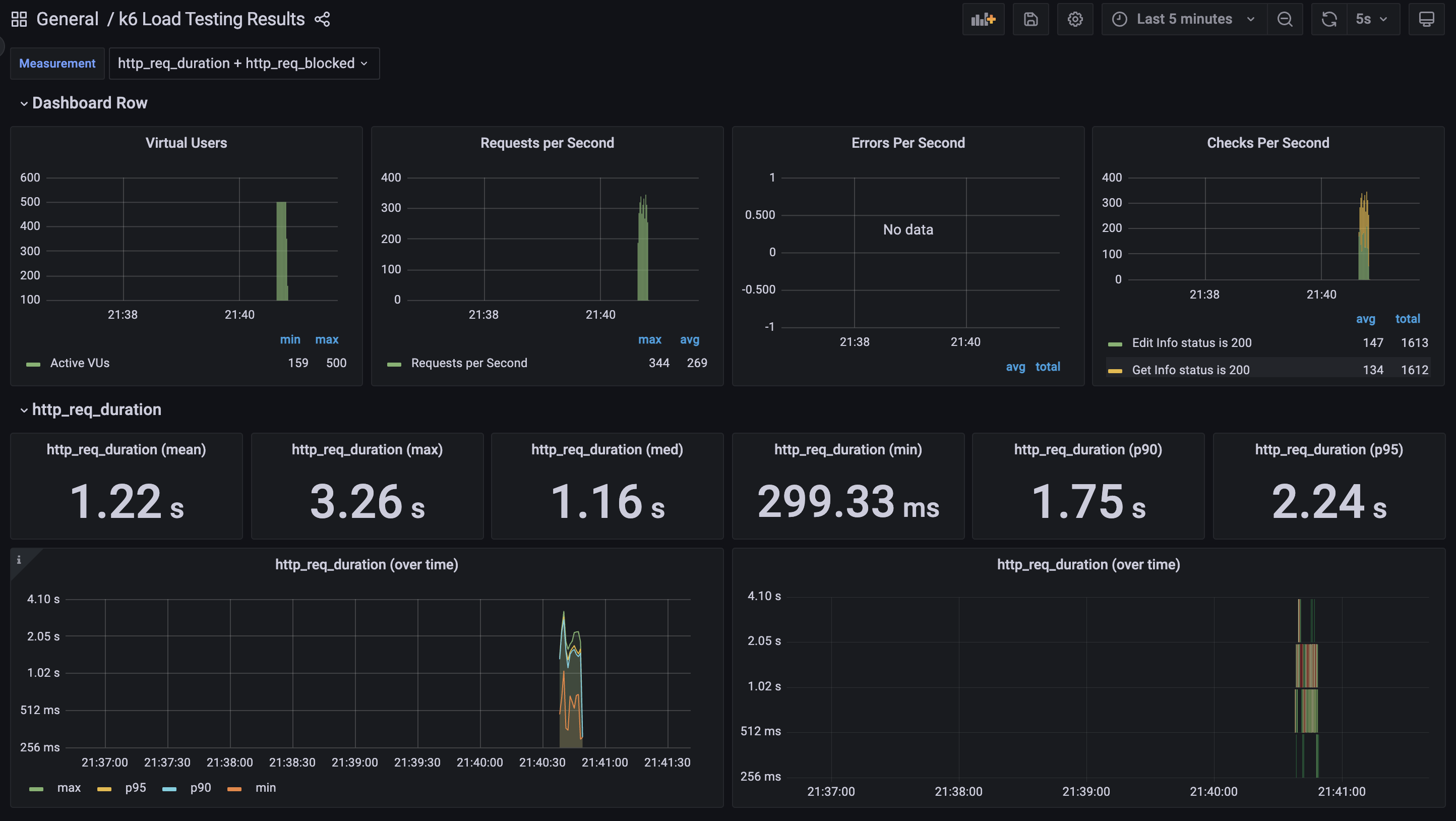
500명의 유저가 데이터를 수정하고 조회한 결과값이다.
평균 1.22초의 응답시간을 가지며 최대 3.26s, 최소 299.33ms 인걸 볼 수 있다.
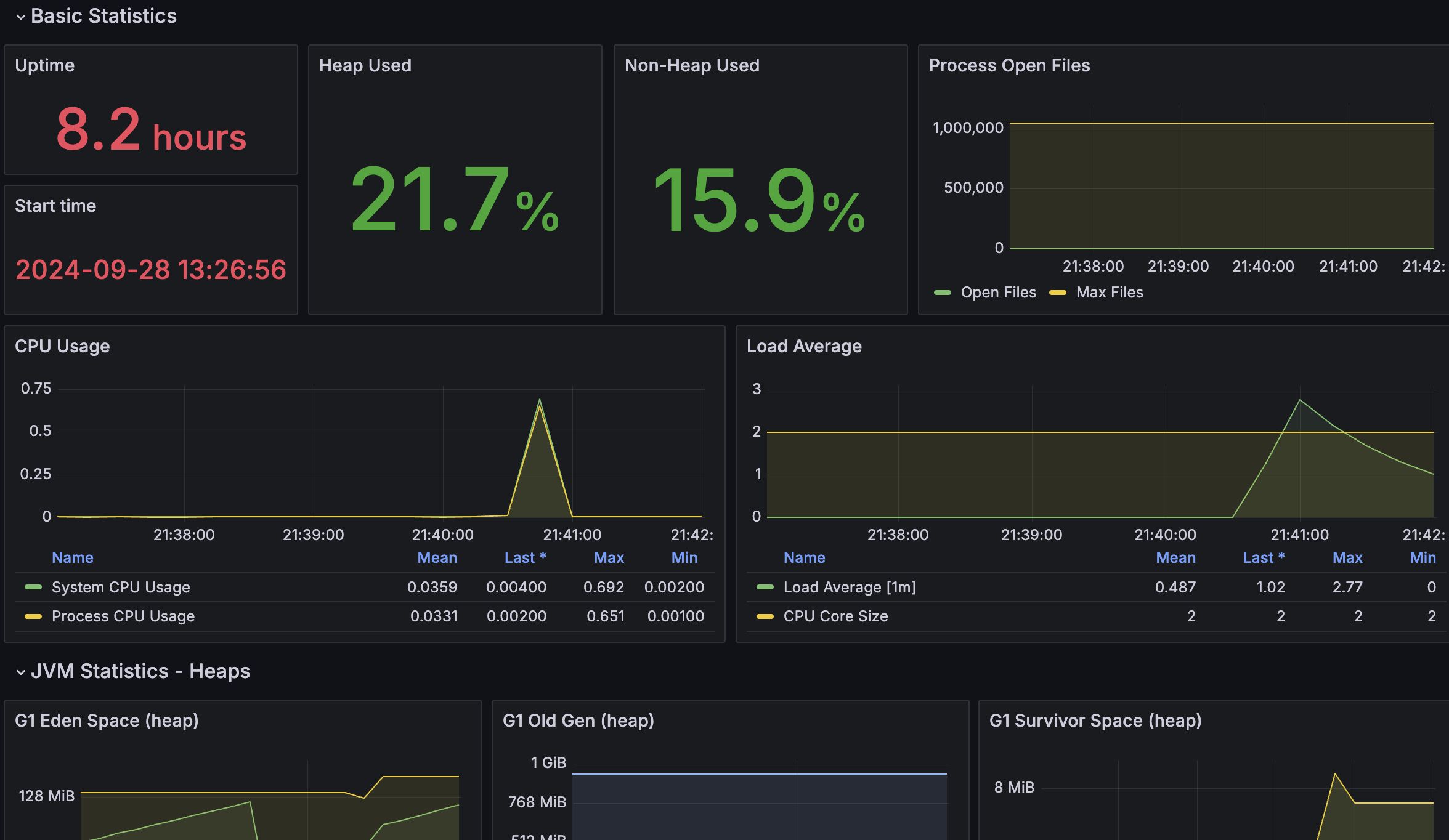
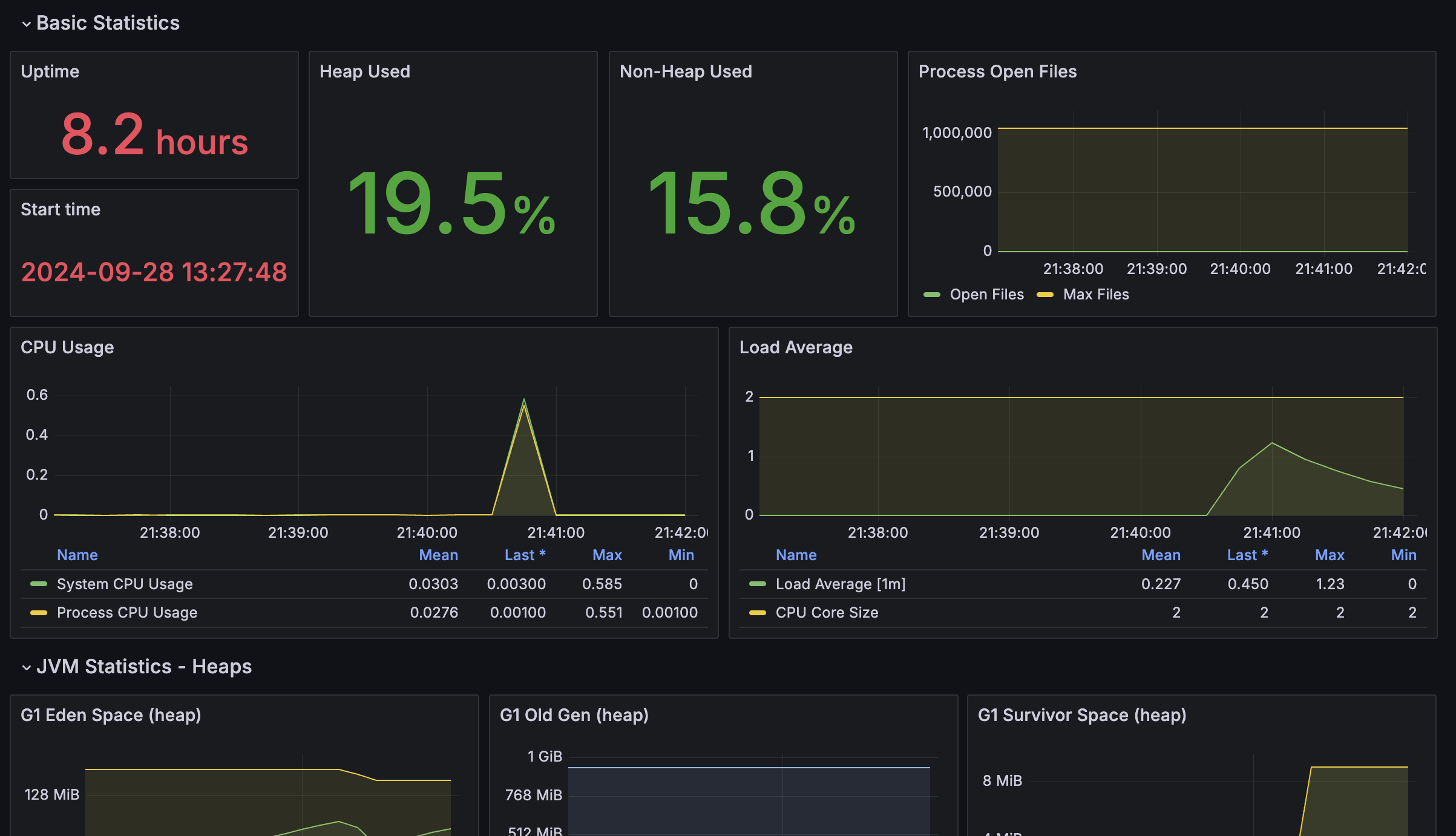
메인서버1 Heap Used 9.1% -> 21.7%
메인서버2 Heap Used 10.4% -> 19.5%
까지 올라갔다 다시 안정화 되는걸 확인 할 수 있었다.
흠... 그럼 과연 어디까지 버틸 수 있을까?
Q&A를 등록하는 로직에서 동시의 2000명의 유저가 요청을 보냈을때도 안정적으로 요청을 버티는지 테스트 해보겠다.
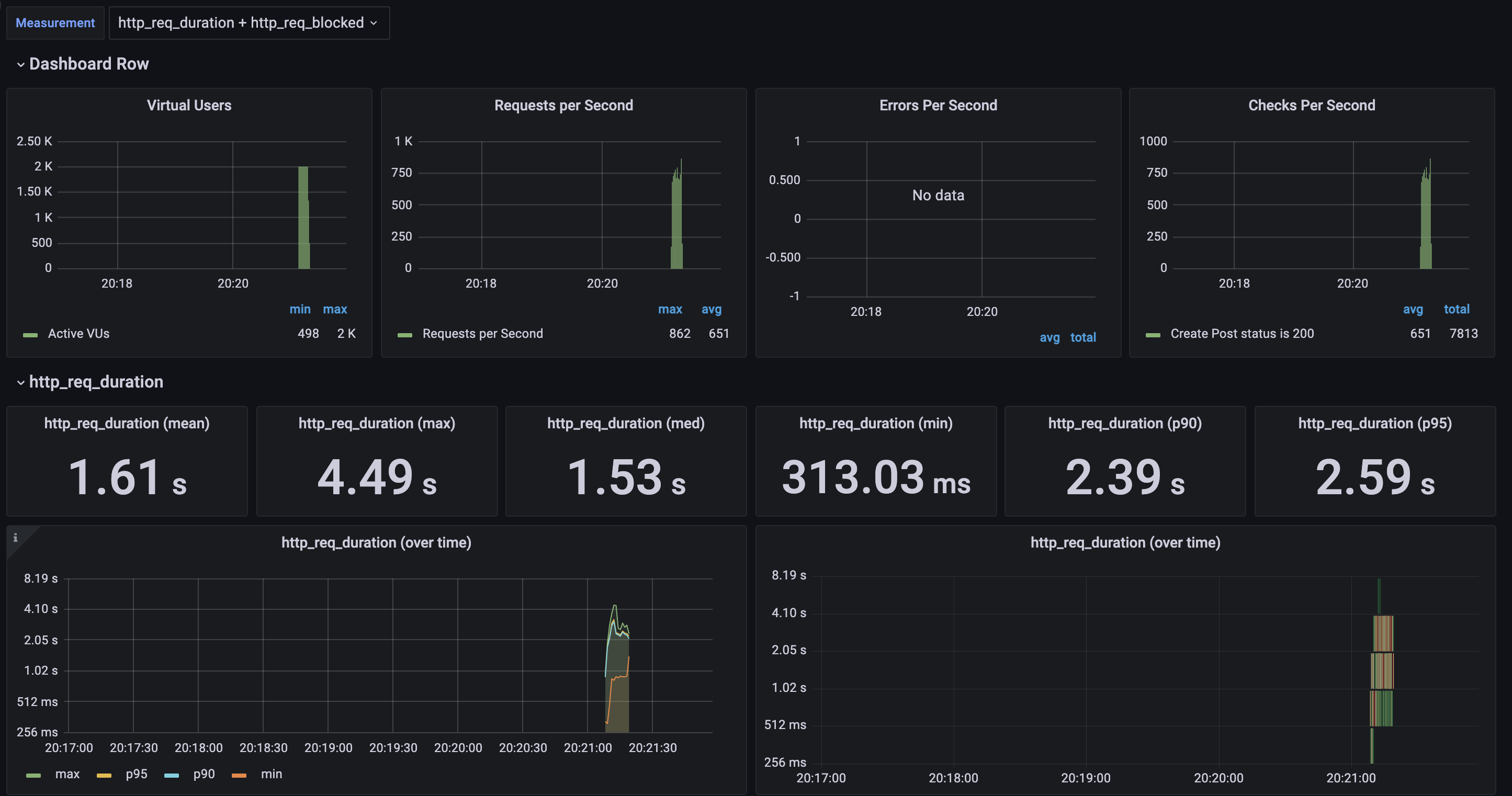
평균 1.61초 최대 요청은 4.49초 중간값 1.53초 최소는 313.03ms 가 걸렸다.
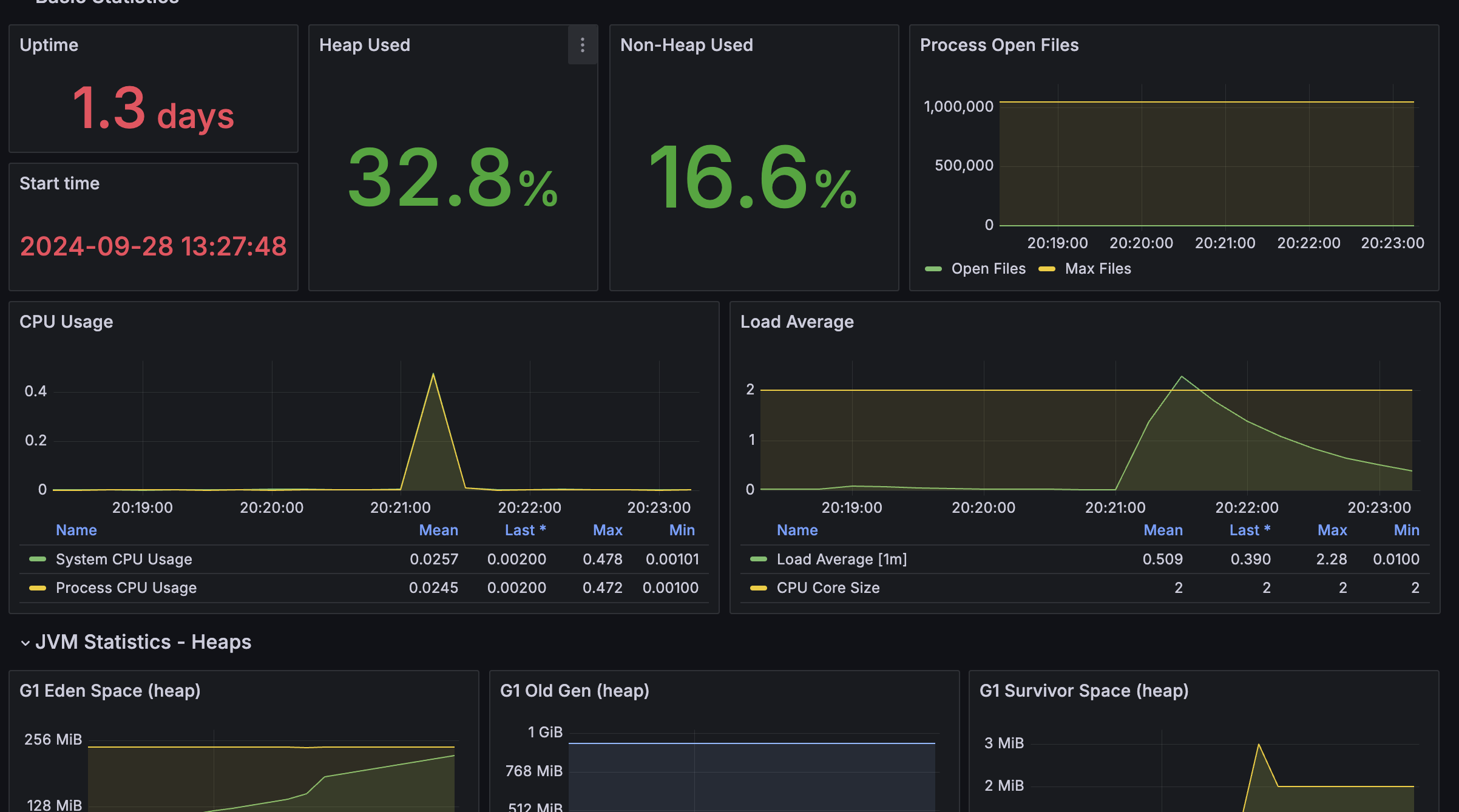
Heap Used 32.8% 까지 올라가는걸 볼 수 있었다.
다행히 2000명이 쓰기 작업을 해도 충분히 버틴다 생각했고 이정도면 충분히 안정적으로 서비스 할 수 있겠다 생각하였다.
근데 최대 요청시간 4.49초 평균 1.61초는 느리다 판단했고, infra 관점에서 요청을 빠르게 만들 수 있는 방법이 뭐가 있을지 고민했다.
서버를 업그레이드하자!
물리서버를 업그레이드 하는 방법도 있지만 2코어 2기가 서버 한대를 더 세팅하기로 하였다.
진짜 최악에 상황에서 서버 2개 보단 조금 작은 서버를 포함해 총 3대를 운영하는게 훨 안정적이라 생각해서 t4g.small 한대를 더 세팅하였다.
Nginx 가중치는 서버 스팩을 생각해 2코어 4기가인 t4g.medium 은 3, 2코어 2기가인 t4g.small은 2를 주어 1:1.5의 처리량을 가지도록 하였다.
비슷한 환경에서의 결과값을 내기 위하여 서버를 돌린뒤 요청을 몇번 하고 몇시간 뒤에 테스트를 진행하였다.
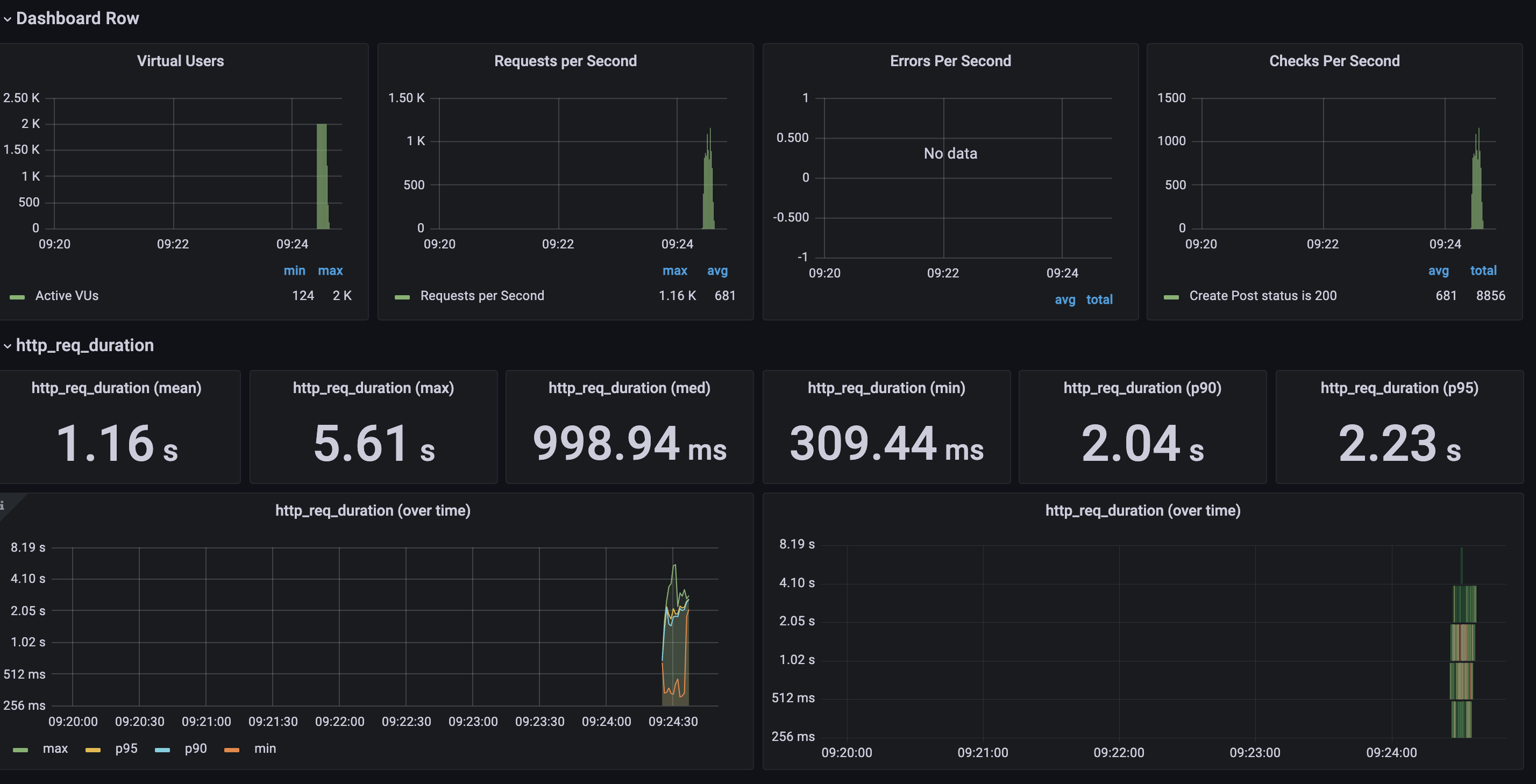
2대의 서버로 테스트를 진행했을때와 비교한다면
평균 1.61초 -> 1.16초로 0.45초 줄었고
최대 요청은 4.49초 -> 5.61초로 늘었지만
중간값 1.53s -> 998.94ms 0.5초 이상 줄였으며
최소는 313.03ms -> 289.92초 23ms 줄였다
p90 (90%의 요청이 이 시간보다 더 짧게 완료)는 2.39초 -> 2.04초로 0.35초 줄였다.
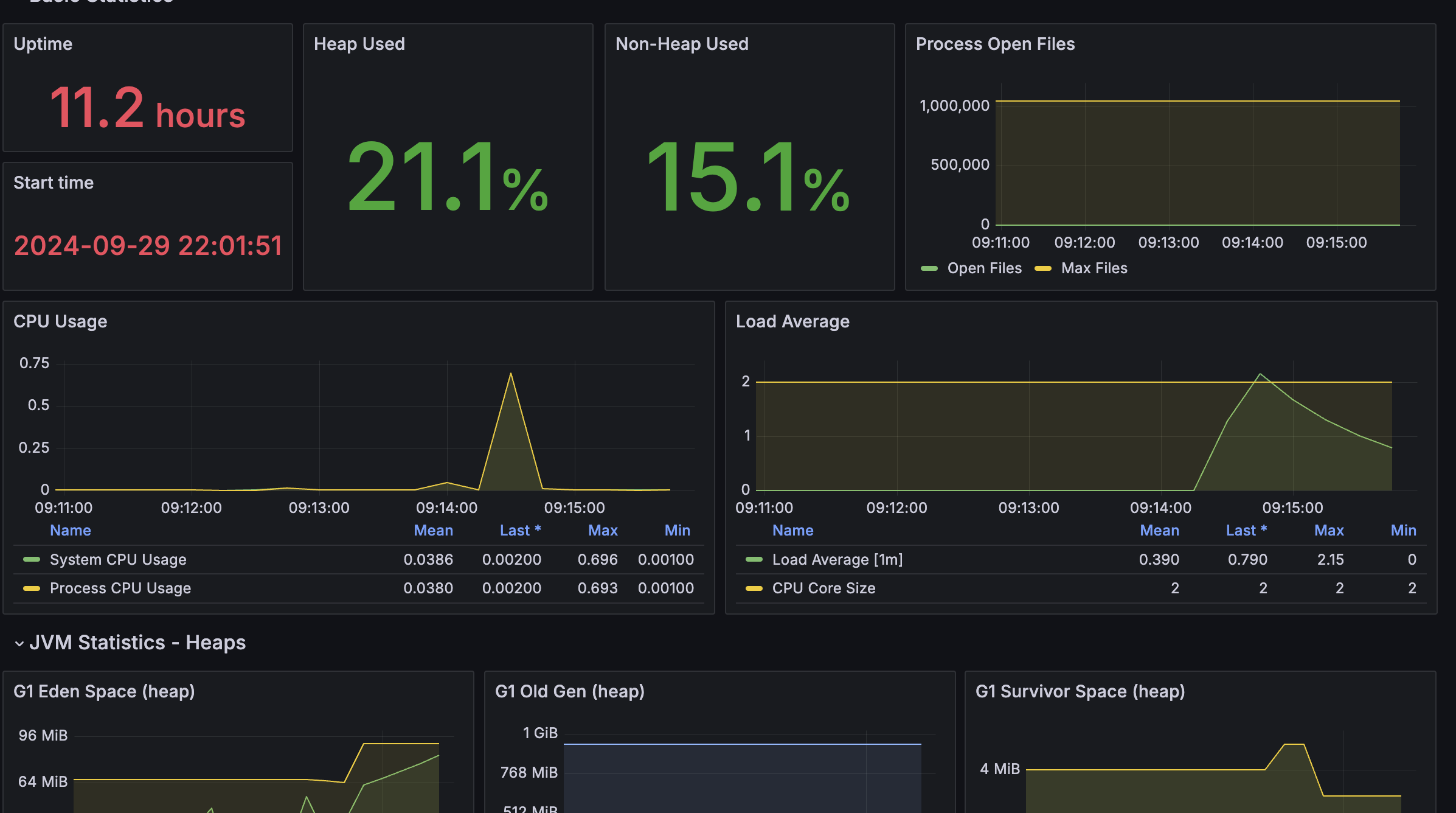
또한, Heap Used 값이 메인 서버에서 32.8%에서 21.1%로 눈에 띄게 감소한 것을 볼 수 있었다.
이 분석을 통해 서버 한 대 추가로 얻을 수 있는 이점을 확실히 확인할 수 있었습니다. 인프라 관점에서 보면, 서버를 하나 더 추가하는 것만으로도 요청 처리 속도와 시스템 안정성을 크게 향상시킬 수 있다는 점이 입증된 것이다.
지금은 개발용으로 RDS도 db.t3.micro 를 사용중인데 이걸 배포때 db.t4g.medium로 올린다면 더 빠른 속도, 안정적인 서비스를 제공할 수 있을꺼다.
결론적으로 완성된 서버 인프라는 아래와 같다.
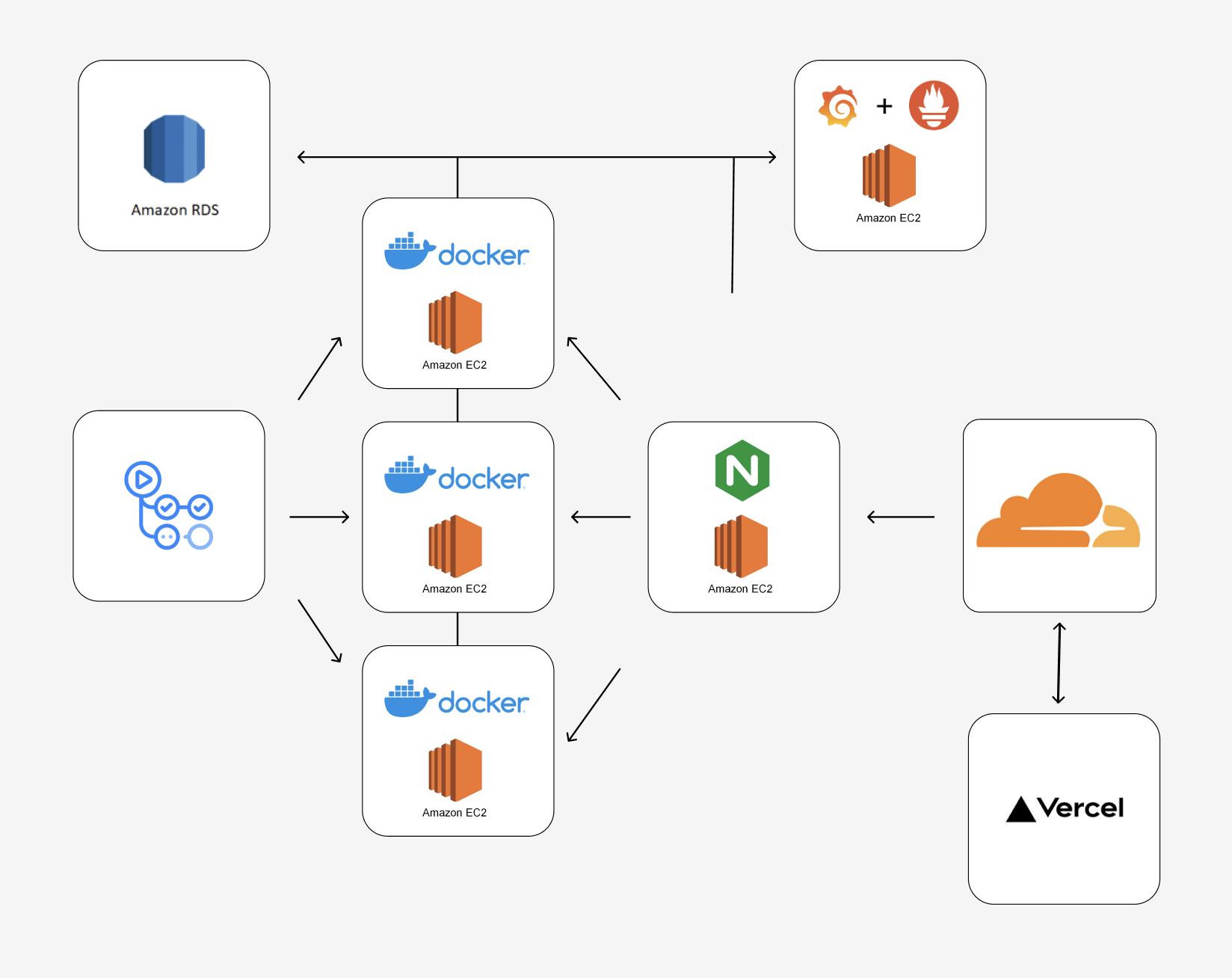
제안된 예산안에서 극한의 효율을 낼 수 있는 인프라 구성 끝!
진짜진짜진짜 * 58000 안정적으로 서비스 운영을 해보겠슴당~
어느날 온 의문의 요청...
어느 평화로운 토요일이였다..
평화로운 정적을 깨는 알림음을 확인한 뒤 나는 충격에서 헤어나오지 못했다.
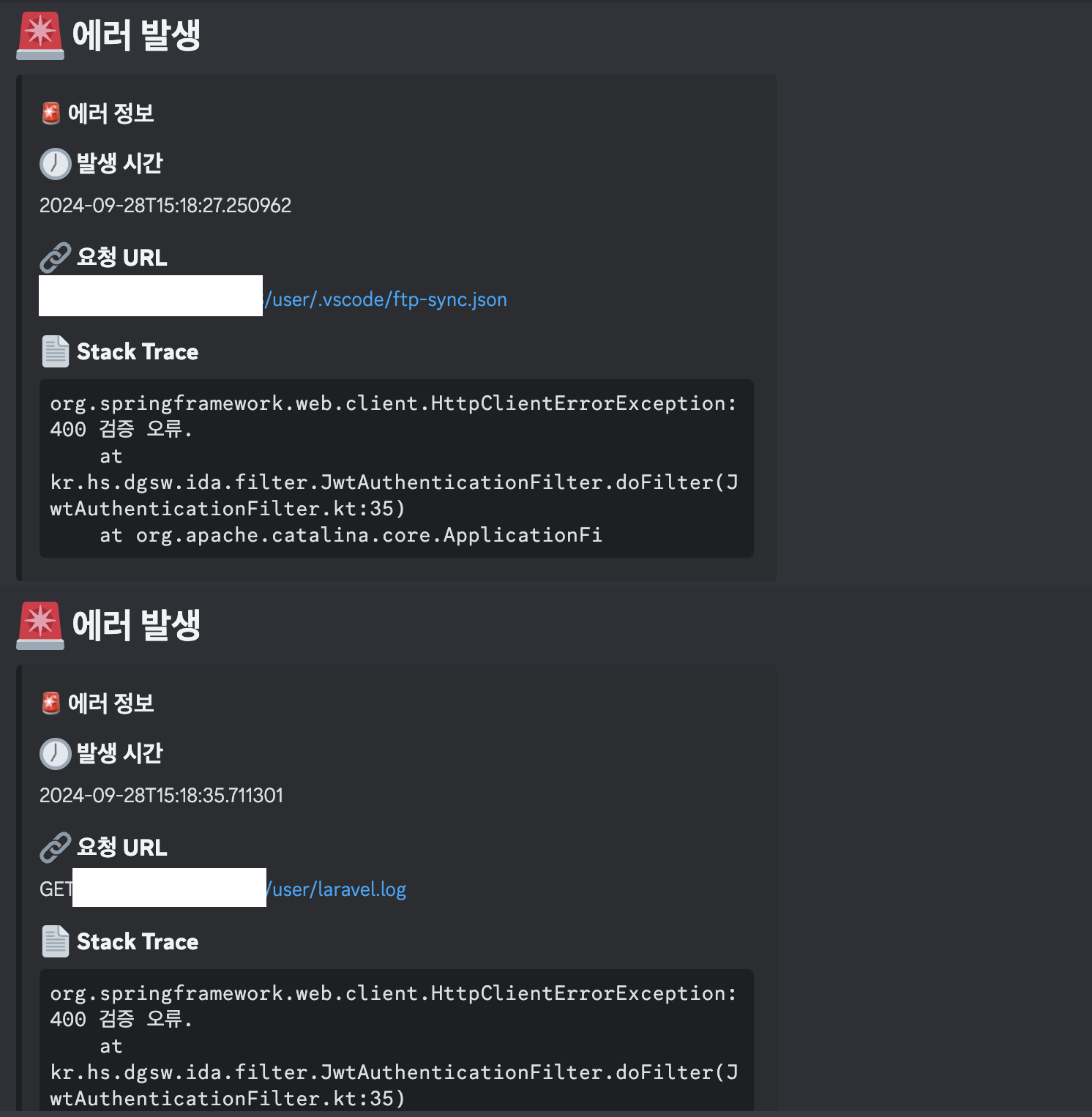
누군가 우리 서비스를 대상으로 해킹시도를 한 듯 보였다.
일단 상황을 판단한 뒤 빠르게 할 수 있는 행동을 한 후 선배에게 상황을 보고했다.
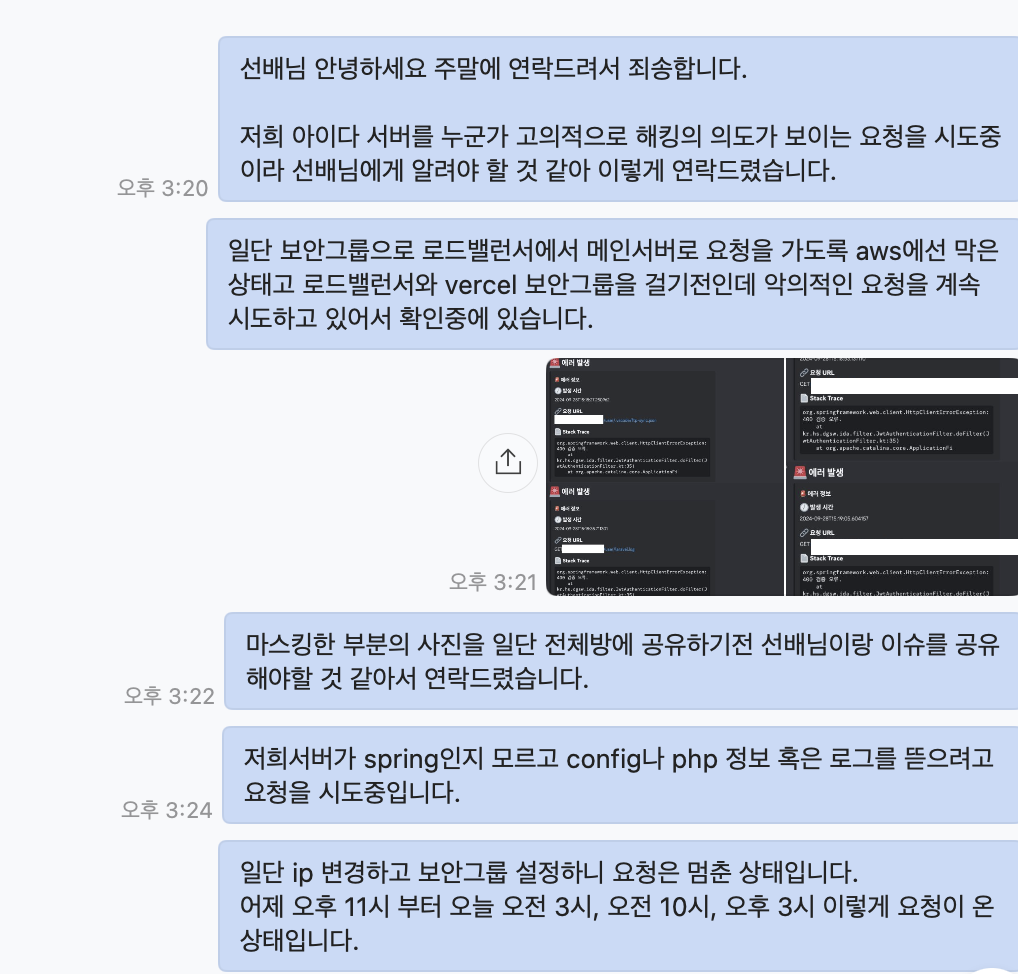
의문이었다. IP나 도메인을 외부에 유출한 적이 없는데 어떻게 이런 시도를 할 수 있었던 것일까?
일단 의문은 접어두고 보안그룹을 엔진엑스에서만 요청할 수 있도록 한 뒤 ip를 바꿨다.
하루정도 잠잠했다 다시 요청하기 시작했다. 이건 도메인의 문제다 판단했고, 클라우드 플레이어 로그를 뜯어보았다.
해커 아이피를 꼭 숨겨줘야할까..?
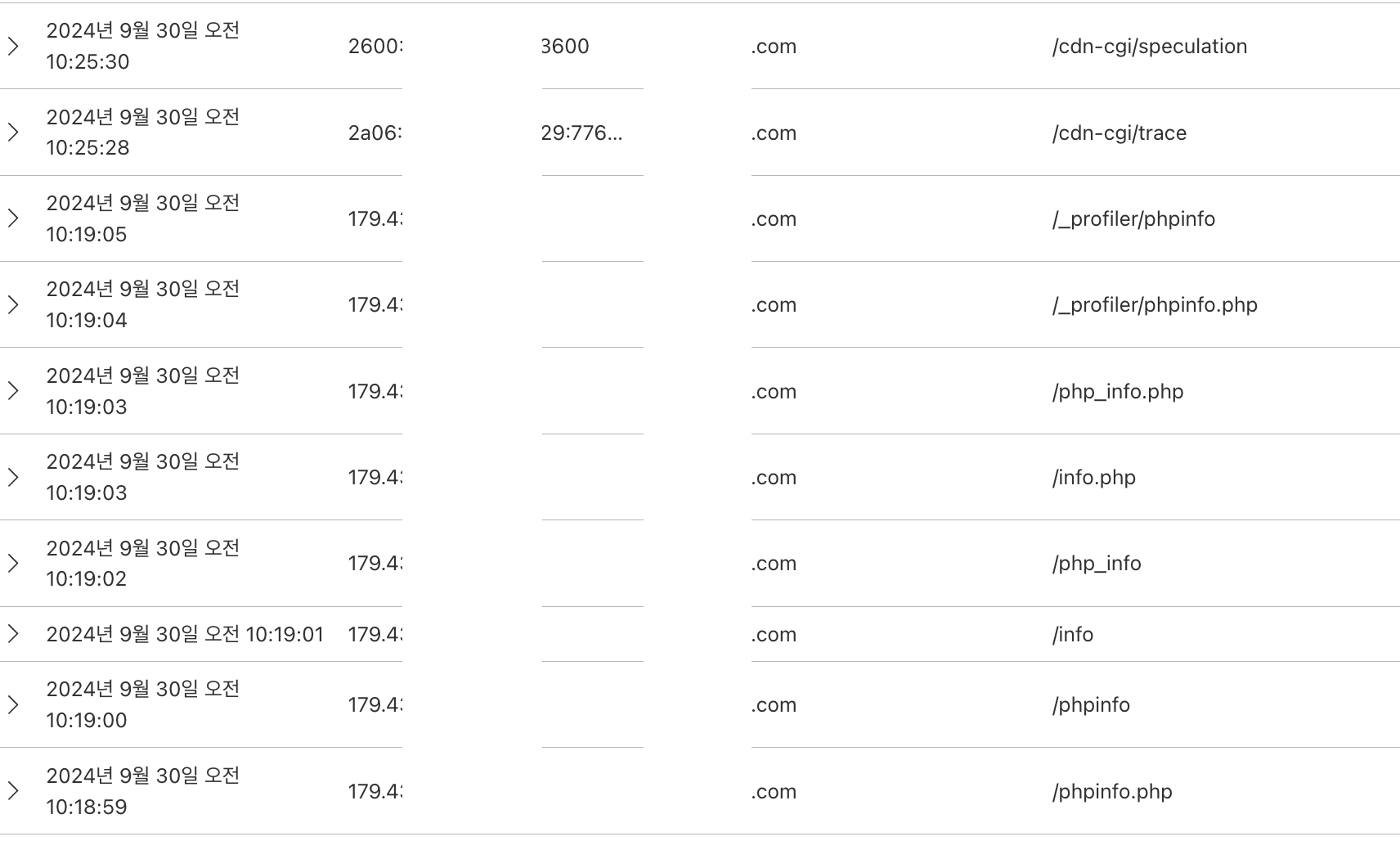
서버 뿐만 아니라 웹에도 공격한 흔적을 발견했고, 다른 대응책을 생각했다.
클라우드 플레어 기능
클라우드 플레어를 사용한 이유가 여기서 빛을 발하다니...
클라우드 플레어는 보안에 대한 다양한 기능을 제공해준다. 위에서 본 로그라던가 캡차 인증이라던가.. 등등
일단 공격을 받는다는 걸 인지했고, 초 단위로 요청하는 걸 봐선 봇으로 공격한다 판단하였고, 동일인이라 판단은 클라우드 플레어의 아이피 조회 기능을 활용했다.
클라우드 플레어의 조사기능을 활용하면 해당 아이피가 어떤 사이트에서 확인되었는지 확인이 가능하다.
이로서 우리서버에 요청을 가한 의심되는 아이피를 하나씩 검색해보자.
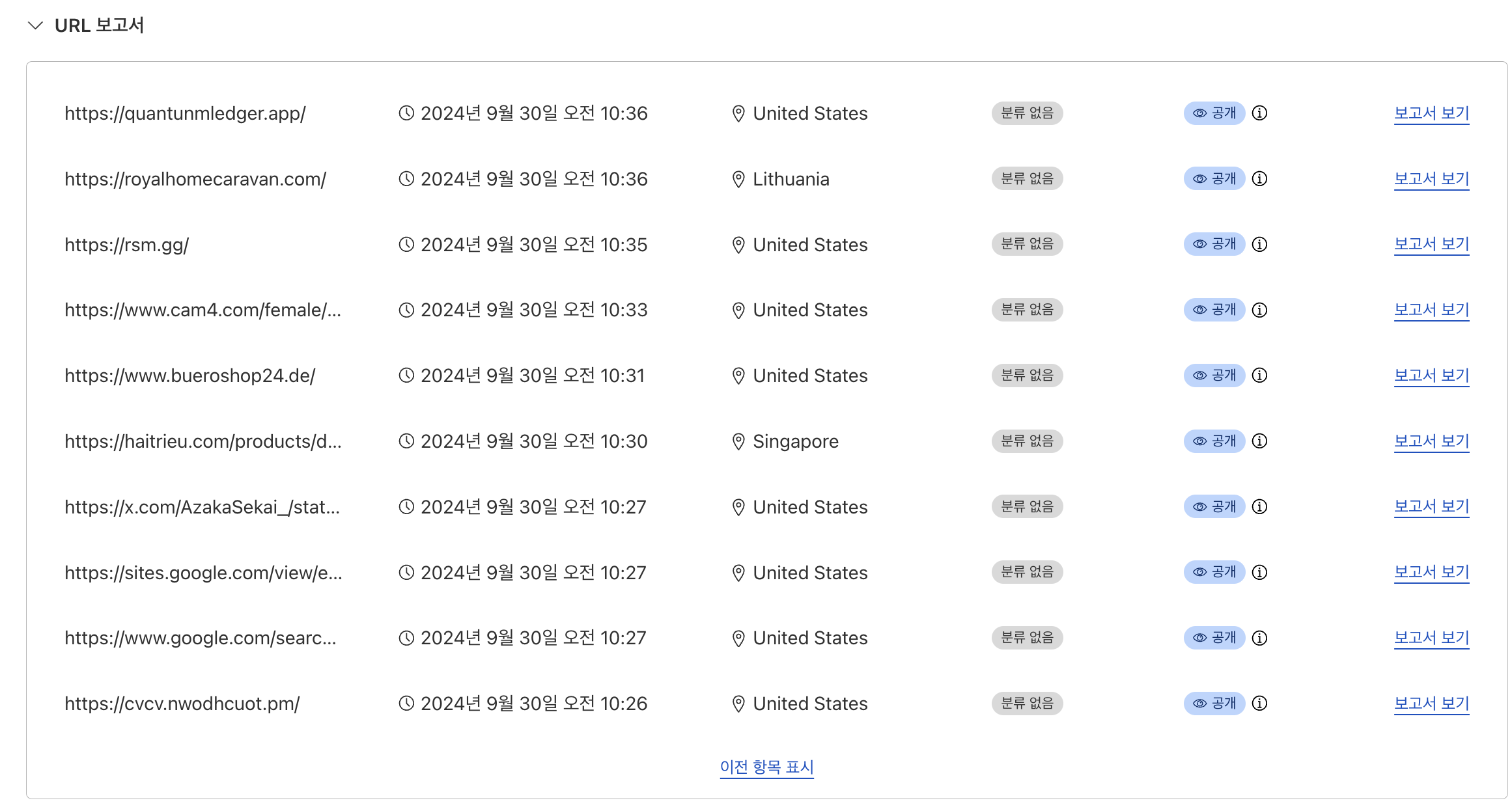
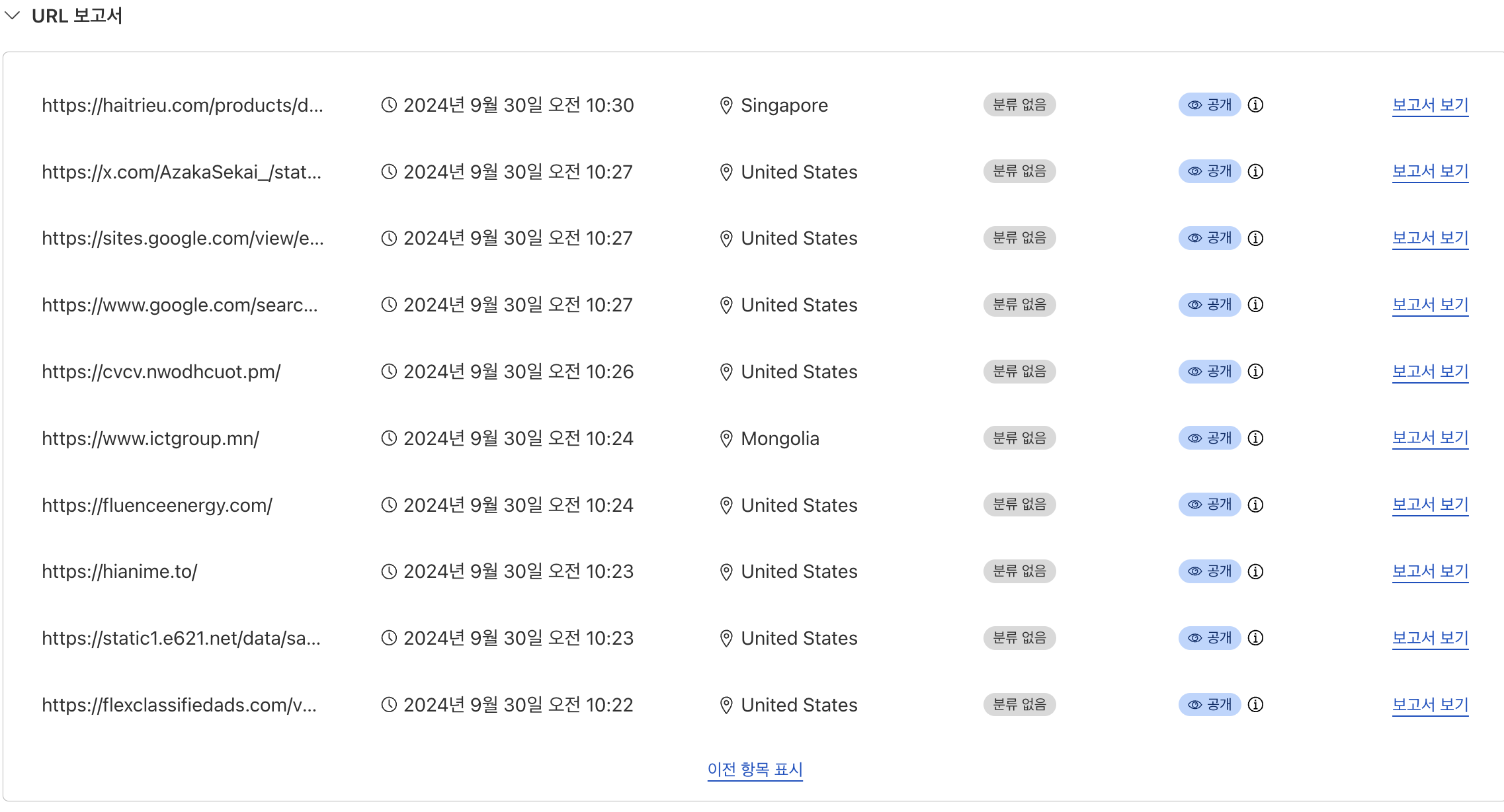
서로 다른 IP 값을 검색하였는데, 이중에서 겹치는 URL이 쫌 많이 보였고, 사이트는 겹칠 수 있지만, 동일 트위터의 어떤 게시글을 조회한 걸 봐선 동일인이라 확신했다.
검색할 때 마다 국가가 바뀌는건 VPN을 사용하여서 그런것 같다.
그래서
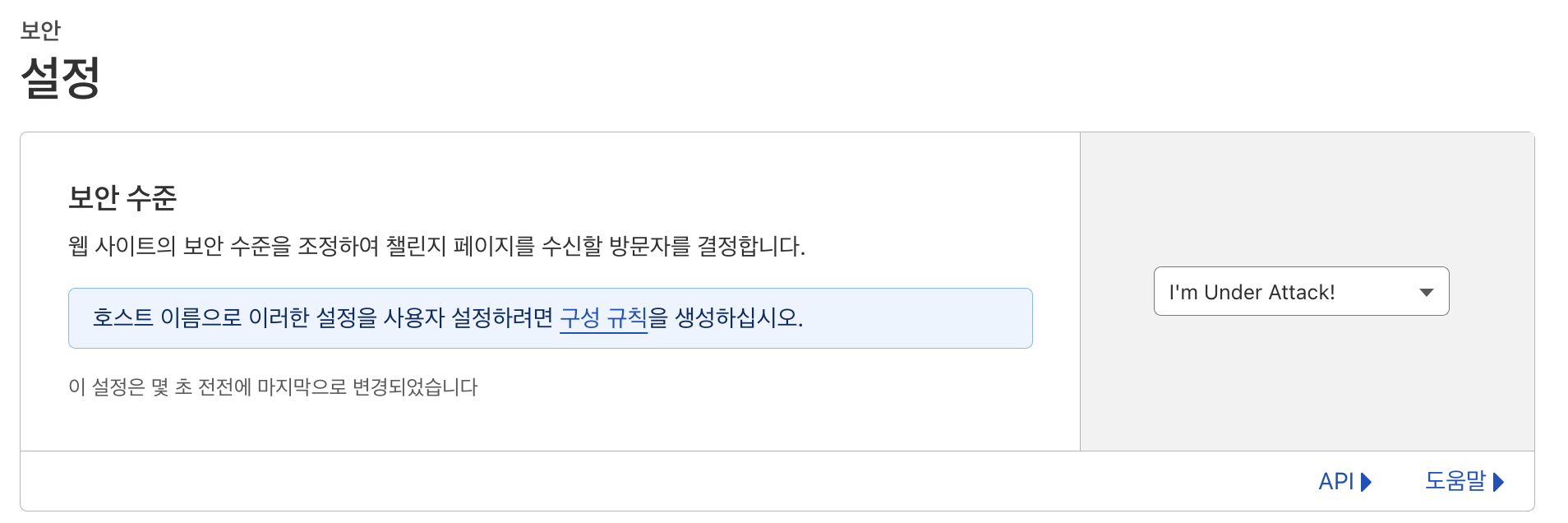
모든 요청에 대한 캡차인증을 걸었다.
그리고 HTTP/1 으로 오는 요청이 2/3 라 HTTP/2 이상만 요청가능하도록 설정을 변경하였고
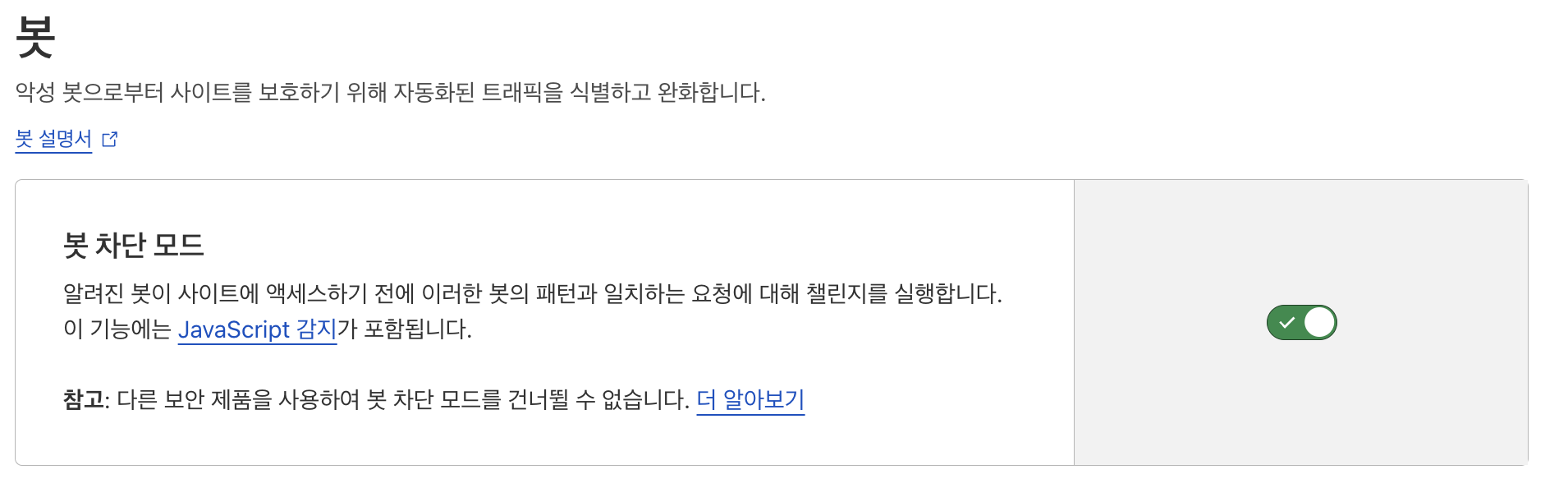
봇차단모드 활성화까지 하였다.
이러니 계속해서 요청을 시도하던 요청을 봇으로 판단하고 클라우드 플레이어가
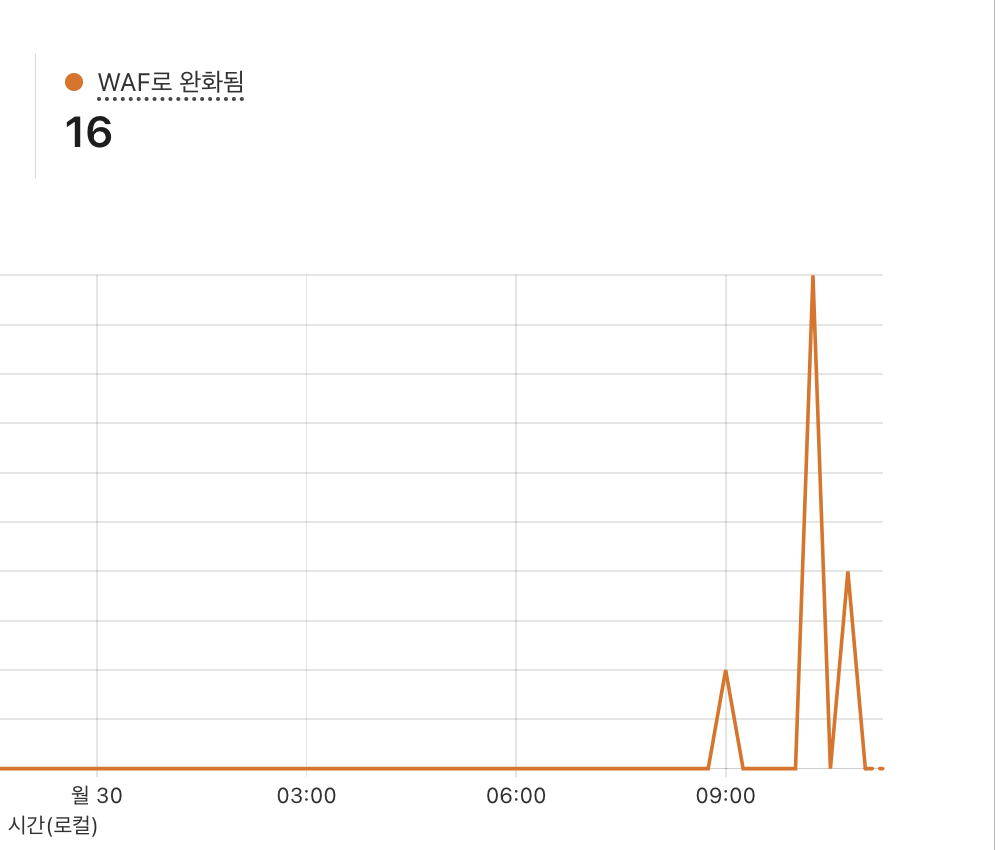
요청을 막았다!
하지만 문제가 있었으니...
모든 요청에 대하여 검증을 진행하다보니 postman에서도 검증이 발생했다.
그래서 I'm Under Attack! -> 높음으로 보안수준을 변경하였고,
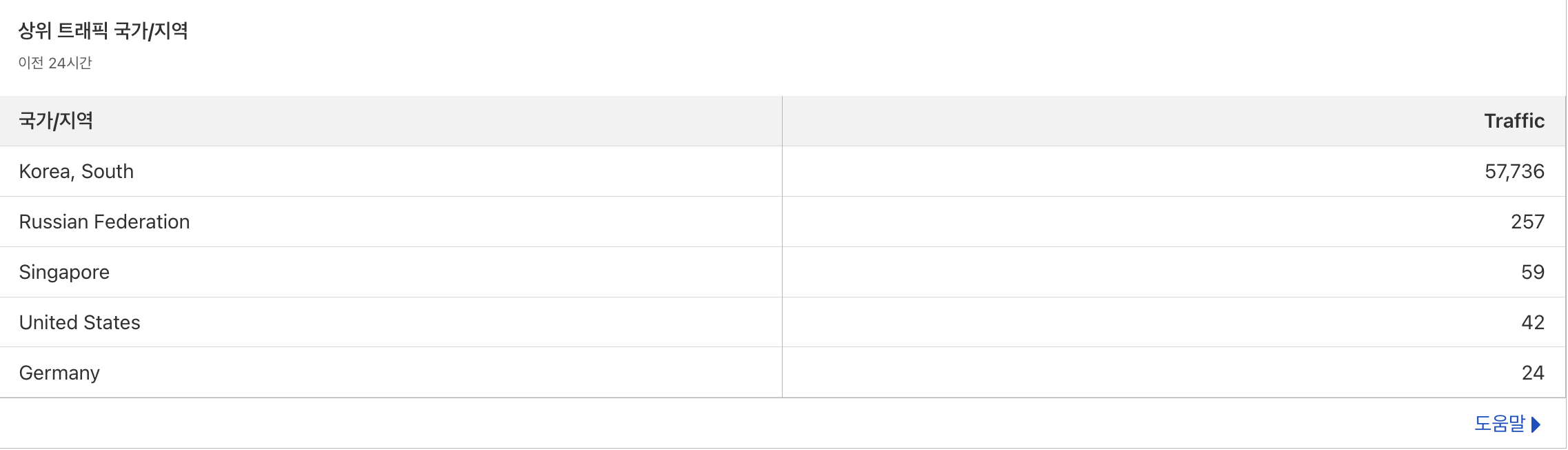
한국이 아닌 외국에서 봇이 요청을 하는것 같아
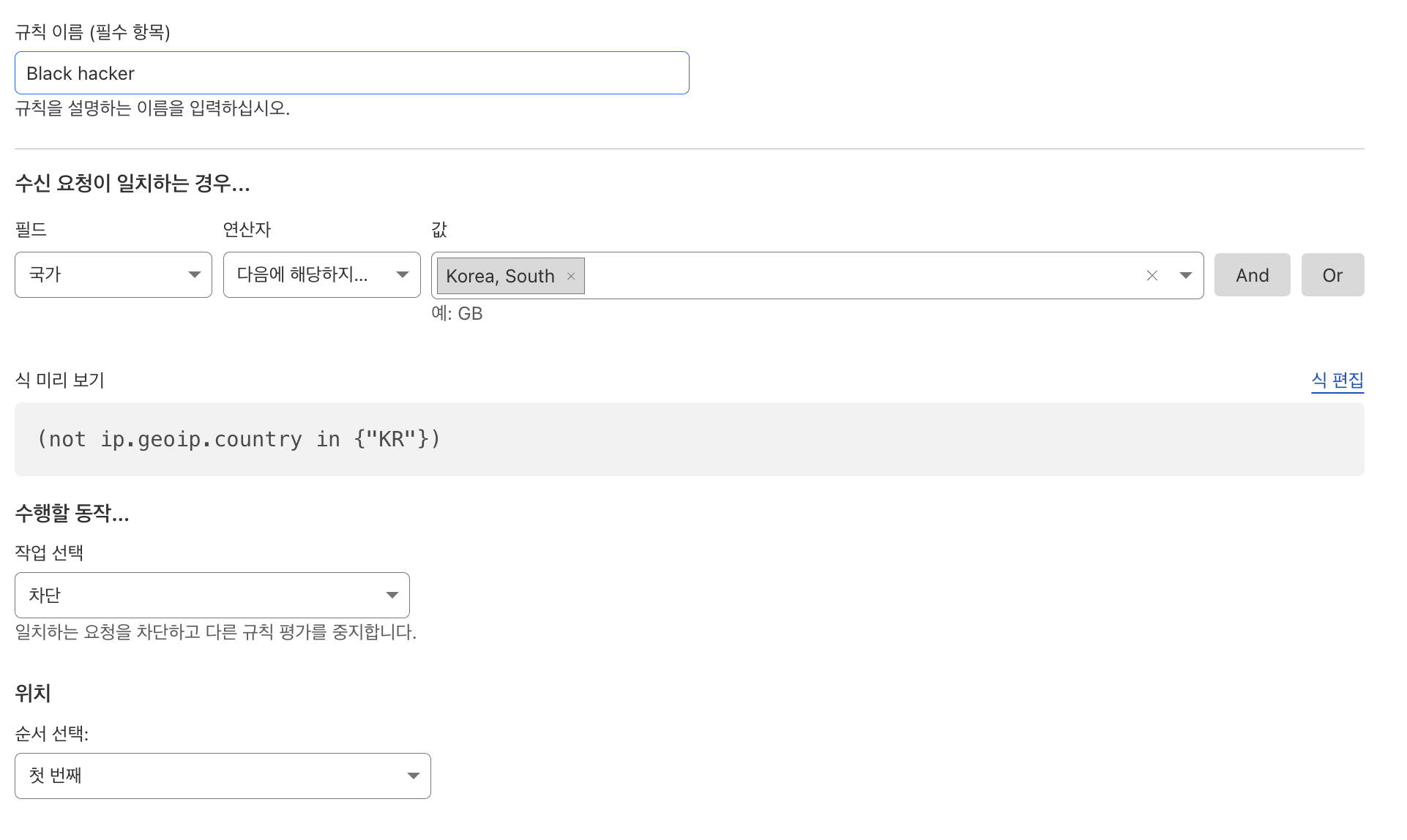
글로벌 서비스도 아니고 대한민국 고등학교 입학원서 사이트인데 VPN 키고 지원하진 않을꺼 아니야 라는 판단하에 한국에서만 요청이 가능하도록 막았다.
다행히 적용을 하고 나니 요청이 멈춘걸 확인할 수 있었다.
무료 요금제인데도 이렇게 다양한 보안기능을 제공해준다니..
사랑해요 클라우드 플레어
이로써 일주일간 고등학생 개발자가 대용량 트래픽 처리를 안정적으로 하기 위해 고민하고 세팅을 한 일대기를 적은 글을 마치겠다.
긴 글 읽어주셔서 감사합니다 !
여담
아직 서비스전이다.
실 서비스까진 일주일 정도 남았고 그전까진 아마 서버 오류가 생긴다면 거기 투입되어 서버를 고쳐야 하지 싶다.
실서비스를 해보라는 이유를 알 것 같다.
개발만 하고 실서비스를 하지 않았다면 나도 저런 경험을 하지 못했을 것이다.
무중단 배포 자동화를 해보고, 이슈 모니터링 장치도 만들면 뭐하나? 실제 사용을 해봐야 좋은 경험이 될껀데, 또 저런 의문의 해킹경험도 실서비스를 하지 않으면 경험해보지 못하는 좋은 경험이라 생각한다.
토스 Next 지원
아잇 또 내가 이번에 토스 지원해보려는 건 어떻게 알고 이렇게 포폴을 잘 쓸 수 있도록 다양한 상황을 경험하게 해주는지.. 해커 친구... 어쩌면 고맙다.(????)
대구소프트웨어마이스터고등학교
원서접수를 10월 14일부터 시작한다.
혹시나 관심이 있으면 학교 홈피 방문해보는 것도....

입학시즌에 맞춰 개발 및 유지보수를 하고 서비스를 진행하는데 원서 접수 기간에 동시다발적인 원서 접수가 발생하고 트래픽이 급증한다. https://www.my-labcorp.com