google-cloud-speech 오류 해결
포스트 작성 시기 : 2021-01-24
0. 레이원님의 Google STT API 사용법
Google Speech to Text(한국어 stt)사용방법, (feat.python)
-> 구글 SpeechToText API를 사용하는 영상을 올려주신 레이원님께 감사하고 또 감사하다는 말씀을 드리고싶다 :)
레이원님의 영상을 보다가 나도 겪고, (댓글 창을 열어보니..) 많은 분들이 겪고 있는 오류들이 공통적으로 존재하고 있었다.
1년 전에 올려주신 영상이지만, 여전히 많은 분들이 이용하고 있는데, 그 사이 많은 코드들이 변경되어 패키지 자체를 update해야할 경우가 생겨 오류가 나는 것이다. 레이원님의 코드가 잘못된 것이 아니다.
다른 분들이 내가 겪은 오류들을 빠르게 해결하기를 바라는 마음을 가지고 글을 작성해본다.
1. pip install pyaudio 오류
가상환경 env가 깔려있는 폴더로 세팅하자.
필자의 환경은 아래와 같다.
C:\Users\User\speechspeech 폴더 안에 env폴더가 있어야 한다.
1. SpeechRecognition을 깔아준다
C:\Users\User\speech>pip install SpeechRecognition2. 여기서 자신의 파이썬 버전을 확인한 후에 해당 주소에서 자신의 버전과 맞는 .whl 파일을 다운받는다.
(python 버전을 확인하고 싶으면 터미널 창에 python 이라고 입력해보자)
ex )
python 3.8.0 이상의 사용자 -> PyAudio-0.2.11-cp38-cp38m-win_amd64.whl
python 3.7.0 이상의 사용자 -> PyAudio-0.2.11-cp37-cp37m-win_amd64.whl
3. C:\Users\User\downloads 에 내려받아진 파일을 C:\Users\User\speech에 복사 혹은 이동한다. 이후에 install을 해준다.
C:\Users\User\speech>pip install PyAudio-0.2.11-cp37-cp37m-win_amd64.whl이후에, 다시 문제의 코드를 실행해보면
C:\Users\User\speech>pip install pyaudio
Requirement already satisfied: pyaudio in c:\users\user\speech\env\lib\site-packages (0.2.11)잘 설치가 됐다고 한다.
오류 해결!
2. cannot import name 'enums' from 'google.cloud.speech' 오류
( 빠르게 오류만 고치고 싶으신 분들은 굵은 글씨만 읽으시면 됩니다! )
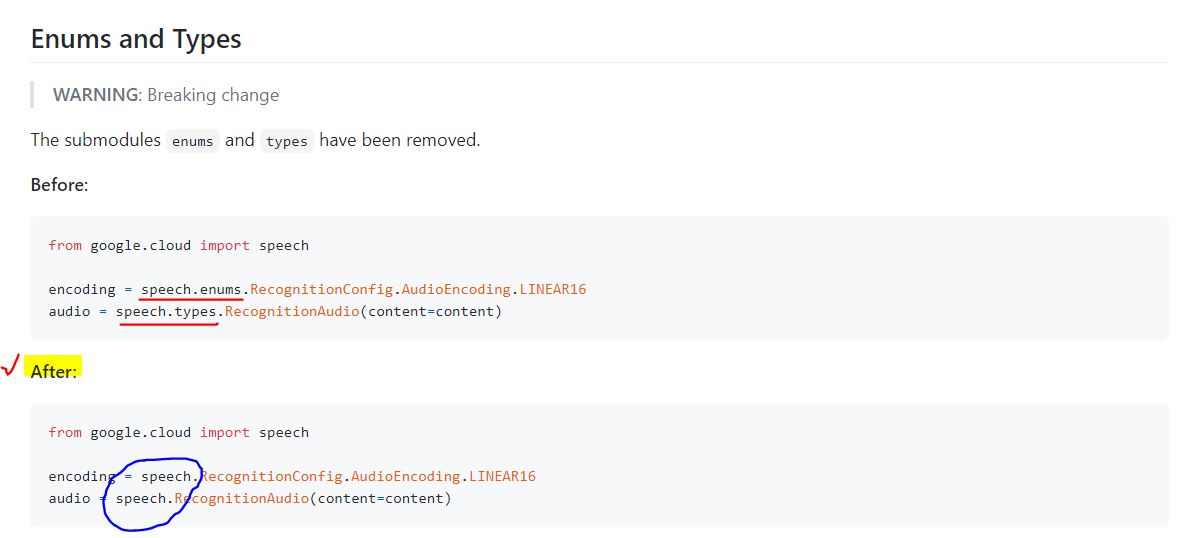
오류 메세지를 확인해보면, from google.cloud.speech import enums 이다. 참고로 한 줄 한 줄 읽다보니 enums에만 오류가 뜬 것이지 실은 import types에도 오류가 발생했을 것이다. enums과 types를 import하는 과정에서 생긴 문제같은데, 자세한 내용은 여기서 확인해 볼 수 있다.
개발자들은 쉽게 읽힐 수 있지만 코드 작업을 깊게 해보지 않은 분들은 위의 깃헙 내용이 어려울 수 있다. (사실 필자도 깊게 알지는 못한다..!)
오잉하신다면, 아래 사진만 잠깐 보시면 될 거 같다.
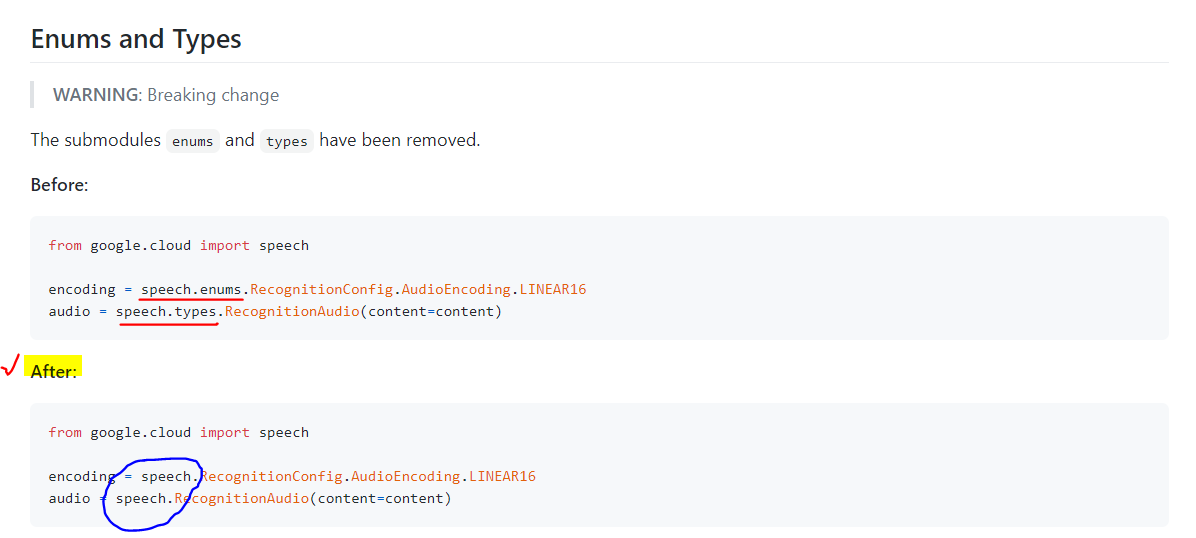
google-cloud-speech가 2.0.0 버전으로 업그레이드되면서 enums와 types가 사라졌다. 코드를 작성하는 과정에서 speech 안에 있던 enums,types의 내부함수, 객체들이 그냥 speech로 모두 포함된 것 같다. 쉽게 말해서 구글의 판단 하에 enums와 types을 코드 자체에서 사라지게 했다.
우리는 레이원님께서 올려준 파일 stt_test1.py을 사용하기 때문에, 이 코드에 맞추어 설명을 하겠다!
1.파이썬 파일을 열고 32, 33번째 줄을 과감히 지워버린 후, 저장한다.
31 : from google.cloud import speech
32 : #from google.cloud.speech import enums
33 : #from google.cloud.speech import types2. 끝난게 아니다! main 함수에 enums과 types 부분을 모두 speech로 바꾸고 저장한다.
def main():
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
language_code = 'ko-KR' # a BCP-47 language tag
client = speech.SpeechClient()
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=RATE,
language_code=language_code)
streaming_config = speech.StreamingRecognitionConfig(
config=config,
interim_results=True)
with MicrophoneStream(RATE, CHUNK) as stream:
audio_generator = stream.generator()
requests = (speech.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator)
responses = client.streaming_recognize(streaming_config, requests)
# Now, put the transcription responses to use.
listen_print_loop(responses)끝.. 이제 더이상 오류 나지 않을 것이다!
3. 403 오류
간혹 이러한 오류가 뜰 수 있는데..
Forbidden: 403 POST Speech-to-Text API has not been used in
project # before or it is disabled.
Enable it by visitng [url] then retry.
If you enabled this API recently, wait a few minutes for the action to
propagate to our systems and retry.써있는 url에 들어가서 api를 사용하면된다. 사용 모드로 되어있어야한다.
