배치
= 일괄처리
ex) 은행의 정산작업, 파일정보 일괄 삭제, 통계 및 집계기능 등
스케쥴링
일정한 시간 간격 또는 일정한 시각에 특정 로직을 돌리기 위해 사용
Spring Batch VS Quartz
Spring Batch
배치가 실패하여 작업을 재시작하게 된다면 처음부터가 아닌 실패한 지점부터 실행하게 됨
Spring Scheduler
1번 스케줄이 끝나지 않으면 2번 스케줄 시작 시간이 되었다고 해도 시작되지 않음
비동기 방식으로 실행하고 싶으면 @EnableAsync 어노테이션을 이용
주의? + 이건 좀더 알아봐야 할듯.
return type이 void일 것
parameter가 없을 것
Quartz
좀 더 Scheduling의 세밀한 제어가 필요할 때, 그리고 만들어야하는 Scheduling 서비스 노드가 멀티이기 때문에 클러스터링이 필요할 때
배치를 구현하기 위해선 스캐줄러가 필요함. 비교대상이 아님.
참고 velog
https://velog.io/@smallcherry/%EB%B0%B0%EC%B9%98%EC%99%80-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%9F%AC
더 알아보기
대용량 데이터에서 배치 성능은 어떻게 올릴까?
Reader 개선
QueryDsl + ZeroOffsetItemReader
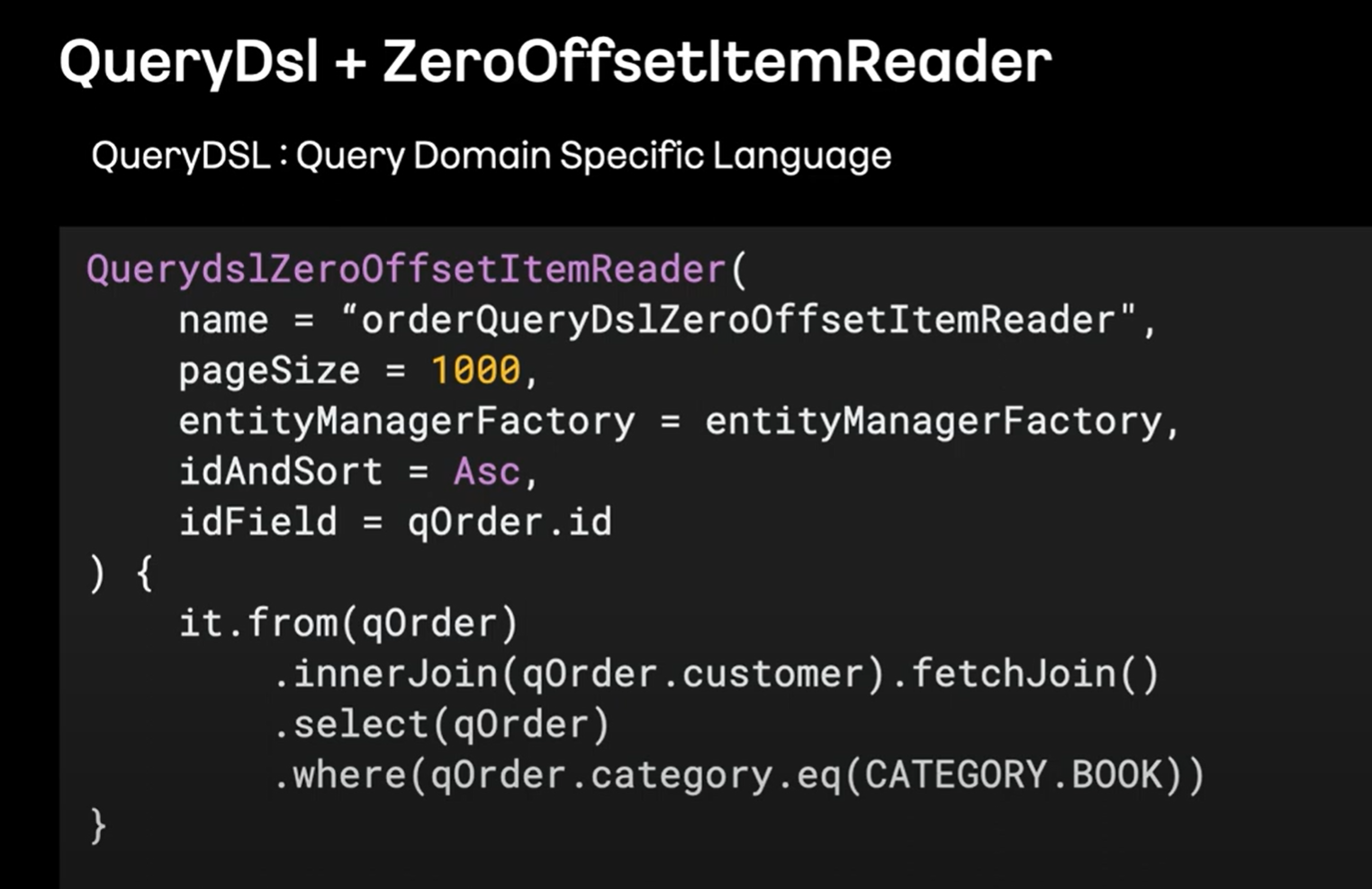
제로 오프셋 말고 다른 방법은 없을까?
Cursor를 이용하자!

그런데 jdbcCursorItemReader와 HibernateCusorItemReader는 HQL, Native Query를 사용해야하는 부담이 있음.
안전하고 세련된 쿼리로 구현할수 없을까?
영상에 잘 나와있습니다. 추천!
참고영상
Batch Performance 극한으로 끌어올리기: 1억 건 데이터 처리를 위한 노력
https://www.youtube.com/watch?v=2IIwQDIi3ys
