%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
이번학기 알고리즘 pdf 보기
목적
효율적인 탐색을 위한 자료구조
준비물
linked list, hash code function, key (문자열 혹은 다른 어떤 자료형도 가능)
과정
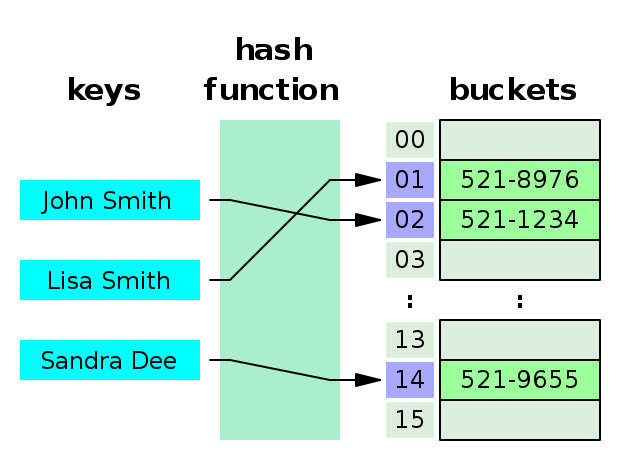
1. key 의 hash code 계산 (key의 갯수는 무한하지만 int 갯수는 유한해서 서로 다른 두개의 키가 같은 hash code 가리킬 수 있음.)
2. ex) hash(key) % array_length 으로 배열의 인덱스를 구함
3. 배열의 각 인덱스가 linked list(key-value)를 가리킴. (두개의 key가 같은 hash code 가리키거나 / 서로 다른 두개의 hash code가 같은 인덱스 가리키는 충돌에 대비해야하기 때문)
복잡도
n은 키의 갯수
- worst : O(N)
- 일반적 : O(1) (충돌을 최소화 하도록 잘 구현된 경우)
왜 복잡도는 O(N) 또는 O(1)일까
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
https://velog.io/@superyodi/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%95%B4%EC%8B%9C
후 설명하기
최악의 경우 : 사람이 5명 있는데, 5명이 모두 같은 해쉬 값을 가지게 될 경우!
충돌이 최소화 되도록 '효율적'으로 저장된 경우는 무엇일까?
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
hash function
비둘기집의 원리
%%%%%%%%%%%%%%%%%%%%%%%%%%%
hash 들이 충돌 되는 이유에 대해서 정리해두기

Sometimes you win, sometimes you learn 🏃♀️