[AAAI 22] Design of Explainability Module with Experts in the Loop for Visualization and Dynamic Adjustment of Continual Learning
Abstract
2가지 어려움
1. 새롭게 수집된 novelties에 continual learning에 방해가 되는 anomalies를 포함할 수 있음.
-> anomalies는 업데이터 대상으로 볼 것이 아니라, filtering 할 수 있어야 함.
2. continual learning의 explainability의 연구가 많이 되지 않음.
-> 설명 가능성은 실무자에게 판단할 수 있는 근거를 마련해줌.
따라서 본 연구에서는 explainability module의 conceptual design을 제안함.
1. Introduction
- Continual Learning은 source domain과 target domain의 distribution이 시간의 흐름에 따라 변화할 수 있는 task-changing contexts 상황에서 성능이 유지되도록 하는 해야 함.
- 즉 castastrophic forgetting problem을 극복하는 것을 목적으로 함. - Novelties는 pre-trained 신경망에서 보지 못한 샘플들을 의미함.
- concept drift를 만드는 concept drift는 신경망의 성능 하락을 이끔.- 일반적으로 신경망은 고정 학습 하이퍼 파라미터를 사용하여 여러 작업을 순차적으로 학습하며, 직관 또는 전문가 사전 지식으로 사전 검색함.
- 이후 업데이트된 모델은 알려진 작업이 포함된 검증 데이터 세트에서 평가됨.
- continual learning을 위한 표준 평가 지표는 이해할 수 있지만 거의 포괄적이지 않은 정확도 및 정밀도와 같은 기존 딥 러닝 실험과 동일함.
[Real-world application시 성능 하락을 일으키는 요인]
1. Confusing anomalous and novel examples.
- 현재 신경망이 정확하게 예측할 수 없는 샘플은 신규성으로 정의할 수 있음.
- 네트워크는 데이터가 축적됨에 따라 지식 메모리를 업데이트하는 방법을 지속적으로 배워야 함.
- 그러나 이상, 즉 지속적인 학습에 의미가 없는 샘플도 새로움 그룹에 속함.
- 이상 현상은 일반적으로 특정 조건에서 손상된 센서 및 정지된 에너지 발전기와 같은 예상치 못한 사고에 의해 발생함.
- 의미 있는 novelites를 학습하면 신경망에 비정상적인 데이터 스트림을 처리할 수 있는 새로운 능력을 심어줄 수 있음.
- 제한 없이 이상을 학습하는 것은 신경망을 잘못된 수렴 상태로 오도하고 성능을 저하시킬 수 있음.
2. Fixed hyperparameters
- 고정 하이퍼 파라미터를 사용하여 모든 작업을 학습하는 것은 알고리듬이 선택한 하이퍼 파라미터에 대해 견고해야 한다는 것을 나타냄.
- 하이퍼 파라미터 선택은 일반적으로 사전 지식과 직관에 의해 수동으로 조정되거나 현재 사용 가능한 데이터 세트를 기반으로 그리드 검색 또는 무작위 검색과 같은 최적화 방법에 의해 검색됨.
- 그러나 상수 하이퍼파라미터는 알 수 없는 작업에 민감할 수 있으며 장기적으로 신경망의 진화를 방해함.
3. A lack of comprehensive evaluation metrics.
- 분류 문제에 대한 정확도 및 F1 점수와 같은 표준 평가 메트릭은 특정 시점, 즉 마지막 훈련 기간 이후의 수렴에서 주어진 데이터 세트에 대한 신경망의 성능만 반영할 수 있음.
- 우리는 일련의 포괄적인 측정 기준이 정확성 외에도 다양한 관점에서 업데이트 결과를 평가해야 한다고 생각함.
- 예를 들어, 분산 표현의 중복을 정량화하여 치명적인 망각의 정도를 계산하거나(1992), 후속 작업이 지속적이고 성공적으로 학습될 수 있는지 여부를 결정하는 신경망의 남은 자유 공간을 추정하기 위해 자유 뉴런을 계산함(2020).
- 일련의 comprehensive한(?) 지표는 관리자가 만족하지 않는 업데이트에 대응하도록 적시에 경고할 수 있음.
4. Assessment with access to old datasets.
- 경우에 따라 학습 및 평가를 위해 오래된 데이터 세트에 대한 의존성은 잠재적인 데이터 개인 정보 보호 문제를 해결하기 위해 유럽 연합이 도입한 일반 데이터 보호 규정과 같은 일부 규정을 위반할 수 있음.
- 규정에 따르면 데이터 주체는 개인 데이터의 삭제를 요청할 권리가 있으며, 이는 일부 상황에서 이전 데이터 세트에 액세스하지 않고 학습 및 평가를 요구함.
5. A lack of visualization methods.
- 수치 평가는 탐지된 이상 징후 또는 업데이트된 신경망에 대한 추상적인 점수만 제공할 수 있음.
- 정교한 시각화가 부족하면 식별된 이상 징후 또는 업데이트된 모델에서 연구자가 불확실해짐.
- 또한, 훈련 시대에 걸쳐 손실의 하향 추세를 관찰하여 신경망의 일반화 성능을 분석할 수 있음에도 불구하고, 신경망의 숨겨진 계층의 동적 진화에 관한 진전은 여전히 불투명함.
- 인간은 적절한 시각화 방법 없이 복잡한 고차원 데이터를 이해하고 해석할 수 없음.
⇒ 따라서 본 논문에서는 위에서 언급한 문제를 해결하기 위해 루프에 전문가가 있는 설명 가능 모듈의 개념적 설계를 제안함. ⇒ 설명성 모듈의 목표는 식별된 이상 징후와 모델 업데이트의 세부 사항에 대해 전문가에게 충분한 설명을 제공하는 것임.
⇒ 설명 모듈과 전문가의 상호 작용을 기반으로 지속적인 학습을 통해 신경망에 대한 실시간 모니터링 및 동적 관리를 달성할 수 있을 것으로 기대함.
2. Design of Explainability Module
-
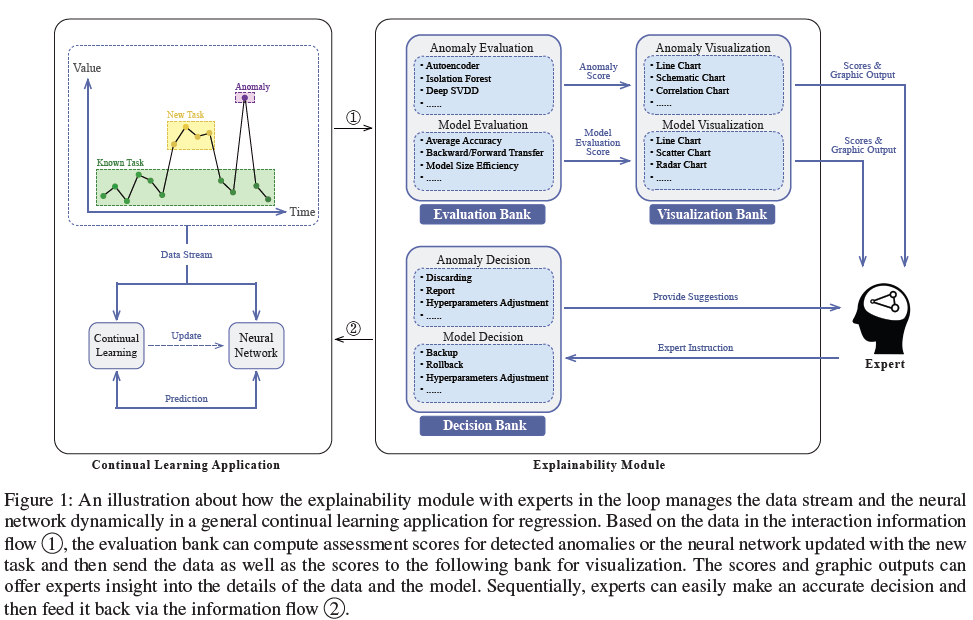
그림 1은 전문가와의 지속적인 학습 애플리케이션과 제안된 설명 가능 모듈 간의 상호 작용을 보여줌.
-
New task는 continual learning의 연구 커뮤니티에서 다르게 정의됨.
- NI와 NC는 동일한 클래스의 새로운 훈련 패턴과 서로 다른 클래스에 속하는 새로운 훈련 패턴을 각각 참조함.
- NIC는 NI와 NC, 즉 알려진 클래스와 새로운 클래스에 속하는 새로운 훈련 패턴의 조합임.
-
신경망은 알려진 작업을 예측하고 지속적인 학습을 통해 새로운 작업과 함께 진화할 수 있음.
- 식별된 이상 징후는 정확한 평가를 위해 상호작용 정보 흐름 1을 통해 설명 가능 모듈로 전달됨.
- 이상 징후 외에도 흐름 1은 데이터 스트림의 샘플, 해당 예측, 학습의 하이퍼 매개 변수, 업데이트된 신경망, 정교한 업데이트 로그 등을 포함한 다른 애플리케이션 관련 세부 정보로도 구성됨.
- 이상이 감지되거나 업데이트가 수행되면 상호 작용이 발생할 수 있음.
-
그림 1과 같이 Explainability module은 evaluation bank, visualization bank, and decision bank의 3개의 주요 서브 module을 포함하며, 각각은 2개의 블록을 가짐.
- Anomaly Decision block은 데이터 스트림에서 식별된 잠재적인 이상을 분석하도록 설계되었으며, Model Decision 블록은 업데이트된 신경망을 평가할 수 있음.
-
전문가는 데이터 스트림에 양의 참 이상 징후가 존재하는지 관찰하고 판단하고 이를 처리하는 방법을 결정할 수 있음.
- 또한 전문가는 평가 지표 및 시각화를 기반으로 업데이트 품질을 평가한 후 성공적으로 업데이트된 모델의 백업을 유지하거나 하이퍼 파라미터를 조정하여 실패한 업데이트 모델을 복원할 수 있음.
- 전문가들은 전문적인 지식과 경험을 가진 최종 의사결정자임.
- Explainability module의 주요 기능은 전문가가 결정을 내리는 데 도움이 되는 제안과 설명을 제공하는 것임.
- 이상 및 업데이트된 모델에 대한 최종 결정은 상호 작용 정보 흐름 2를 통해 전달됨.
2.1. Evaluation Bank
Anomaly Evaluation
Anomaly evaluation block은 이상 점수를 계산하여 잠재적인 이상을 평가하는 역할을 하며, 이는 전문가의 의사 결정에 도움이 됨.
- 기존의 딥 러닝 설정에서는 부족한 데이터의 부정적인 영향을 제거하고 훈련 결과를 효율적으로 개선하기 위해 이상 징후를 폐기하여 실험 전에 훈련 및 검증 데이터 세트를 사전 처리함. (= 전처리를 거친다.)
- 그러나 실제 응용 프로그램의 이상은 피할 수 없으며, 훈련 과정에 높지만 의미 없는 엔트로피를 가져오고 마지막으로 업데이트 결과를 방해함.
- 따라서 의미 있는 샘플을 유지하고 novelties에서 anomalies를 걸러내는 것은 지속적인 학습 애플리케이션에서 신경망의 성능을 유지하는 데 중요한 역할을 함.
감독 및 비감독 방법을 포함하여 많은 기계 학습 기반 이상 탐지 방법이 제안됨.
- 심층 SVDD(Deep Support Vector Data Description)는 신경망을 사용하여 입력 공간에서 출력 공간으로 샘플을 매핑한다. 표본과 클러스터 중심 사이의 거리로 인한 이상 징후를 식별한다(Ruff 등 2018). 정상 샘플의 클러스터 중심에서 멀리 떨어진 샘플은 이상으로 표시된다.
- (Ding 및 Fei 2013)은 IFASD(Isolution Forest Algorithm for the Stream Data)라고 불리는 이상 감지를 위한 비지도 방법을 제안한다. 다차원 시계열에 초점을 맞춘 다양한 고립의 숲이다. 또한, (Meng et al. 2019)는 원래 시계열과 재구성된 시계열 간의 오류를 비교하여 이상을 감지하는 변압기 기반 비지도 방법을 제시한다. 이러한 방법은 점수를 계산하고 점수를 미리 정의된 임계값과 비교하여 탐지된 이상 징후의 품질을 평가한다. 점수가 임계값 이상이면 해당 신규성은 지속적인 학습을 위한 새로운 작업이 아닌 이상 징후로 표시된다.
- 감독 방법의 경우 샘플에 수동으로 레이블을 지정해야 하며, 이는 시간이 많이 걸리고 실제 애플리케이션에서 비용이 많이 든다(Siddiqui et al. 2018). 이에 비해 감독되지 않은 방법을 사용하면 추가적인 수동 레이블과 계산 오버헤드를 피할 수 있다. 그럼에도 불구하고, 훈련된 모델은 매우 높은 거짓 양성 비율을 가질 수 있으므로 식별된 이상 징후에 대한 추가 전문가 검증이 필요하다(Atenberg 및 Provost 2011).
Model Evaluation
model evaluation는 포괄적인 메트릭을 기반으로 평가 점수를 제공하여 업데이트된 모델의 품질을 평가할 수 있음.
- 우리는 포괄적인 평가 지표가 새로운 작업에 대한 향상된 예측 정확도뿐만 아니라 지속적인 학습 중에 망각이라고도 알려진 오래된 작업에 대한 감소 정확도도 고려함.
- 새로운 작업에서 지식을 얻는 것과 오래된 작업에서 지식을 유지하는 것 사이의 절충, 이른바 plasticity stability
dilemma (2013)는 특정 응용 시나리오에 따라 달라짐. - 예를 들어, 재생 에너지 예측의 적용에서, 발전기의 노화는 느리게 변화하고 돌이킬 수 없는 과정이다. 이 경우 신경망이 어떻게 새로운 데이터를 잘 맞추고 저장된 메모리를 약간 폐기할 수 있는지에 더 많은 관심을 기울일 수 있다.
- 그러나 기상 시계열 예측의 적용에서 데이터의 확률 분포가 시간이 지남에 따라 주기적으로 변화하는 계절적 기상 조건이 변화한다. 신경망이 새로운 데이터를 학습하는 동안 과거 데이터와 관련된 메모리를 통합해야 한다.
- 즉, 상황에 따라 과거 데이터를 어떻게 보관할지/폐기할지가 달라짐
(2017)는 지속적인 학습 실험을 평가하기 위한 세 가지 메트릭을 정의한다: Average Accuracy, Backward Transfer, and Forward Transfer.
- 메트릭의 목표는 이전 및 미래 작업을 포함하여 알려진 모든 작업과 관련하여 새로운 작업을 학습하는 것이 훈련된 네트워크의 성능에 미치는 영향을 평가하는 것임.
- (2018)은 Model Size Efficiency, Sample Storage Size Efficiency, and Computational Efficiency이라는 추가적인 세 가지 메트릭을 제안하여 이 작업을 확장함.
- 모델 메모리 크기의 증분, 재생 기반 전략을 위한 샘플의 스토리지 오버헤드 및 모든 작업 학습을 위한 계산 오버헤드를 측정하는 효율성. 순위를 매기는 목적을 위해, 이러한 메트릭은 서로 다른 가중치 체계를 가진 연속 학습 점수로 요약됨.
- 또한 (2021)은 예측 오류, 적합 오류, 망각 비율 및 훈련 시간 측면에서 회귀 문제의 맥락에서 지속적인 학습 전략을 평가함.
2.2. Visualization Bank
Anomaly Visualization
Anomaly visualization를 사용하여 이러한 이상 징후의 시각화 출력을 생성하며, 이는 추상적인 이상 징후 점수를 신뢰할 수 있고 이해할 수 있는 방식으로 설명할 수 있음.
-
고차원 데이터는 일반적으로 여러 데이터 소스, 예를 들어 복잡한 시스템에 통합된 여러 센서를 나타내며, 이는 이상 탐지에 대한 두 가지 주요 과제를 가져옴.
1) 로컬 및 글로벌 아키텍처 정보를 손실하지 않고 고차원 데이터를 수동으로 분석하고 시각화하는 것은 어려움.
2) 둘째로, 일부 데이터 소스는 종속적이며, 이는 하나의 결함 소스가 다른 정상 소스에 영향을 미칠 수 있음을 의미함.
- 종속성으로 인해 정확한 결함 원인과 결함이 발생하는 시기를 식별하기가 너무 어려움. -
따라서 제안된 이상 징후 시각화 모듈은 다음 질문을 파악하여 이러한 문제를 해결하는 것을 목표로 함.
• 차원 축소 기술을 활용하여 고차원 데이터의 시각화를 이해할 수 있는 방법은 무엇입니까?
• 탐지된 이상 징후에 대한 합리적인 설명을 제공하기 위해 여러 데이터 소스 간의 종속성을 시각화하는 방법은 무엇입니까?
• 사용 가능한 방법 또는 메트릭이 여러 개인 경우 이상 탐지 방법의 순위를 어떻게 정합니까?
Model Visualization
Model Visualization는 무작위 초기화에서 수렴으로의 모델 매개 변수 변경을 포함하여 업데이트된 모델의 동적 진화 프로세스를 시각화하는 데 중점을 둠.
- 각 지점이 각 시점의 예측 오차를 나타내는 learning curve에 비해, 우리는 continual learning 동안 dynamic evolution에 대한 시각화에 의해 더 확신할 수 있으며, 이는 더 자세한 진행 상황을 보여줄 수 있음.
- 이러한 목표를 달성하기 위해서는 차원 축소 과정에서 데이터의 정보를 최대한 보존하는 방법을 고려할 필요가 있음.
- 주성분 분석(PCA), 확산 맵(Coifman 및 Lafon 2006), 다차원 스케일링(MDS)(Cox 및 Cox 2008), t-SNE(Van der Maaten 및 Hinton 2008)과 같은 공통 차원 축소 기법은 로컬 또는 글로벌 구조 정보를 효율적으로 보존할 수 있음.
- (Moon et al. 2019)는 로컬 및 글로벌 구조를 모두 드러내면서 고차원 데이터를 시각화할 수 있는 방법인 PHATE를 제안함. PHATE를 기반으로 (Gigante et al. 2019)는 시대에 따라 숨겨진 표현의 변화를 추출하여 신경망의 동적 진화를 시각화하는 M-PHATE를 제안함.
- 또한 (미르자데, 파라자바, 가셈자데 2020)는 직관적이지만 거대 신경망에는 적용할 수 없는 열 지도를 사용하여 각 작업의 활성 뉴런을 선택적으로 시각화함. 이상 시각화와 유사하게, 우리는 또한 앙상블 학습에서 서로 다른 알고리듬이나 신경망 아키텍처를 비교하기 위해 모델 시각화를 위한 다양한 평가 지표 하에서 연속 학습 알고리듬의 순위를 매길 필요가 있음.
- 레이더 차트 및 라인 차트(D'az-Rodr'iguz et al. 2018)와 같은 일반적인 시각화 방법은 직관적이며 순위를 매기는 목적으로 쉽게 구현됨. 업데이트된 모델을 보다 투명하고 신뢰할 수 있게 해줌.
- visualization bank의 입력은 상호작용 정보 흐름 1과 evaluation bank의 출력의 interaction 임.
- 그들의 그래픽 출력은 데이터와 모델의 잠재적 표현에 대한 전문가의 통찰력을 제공하고 의사 결정에 있어 전문가를 지원함.
- 게다가, 우리는 그래픽 출력이 정적이기보다는 interactive이라고 예상함.
- 예를 들어 확대/축소, 정확한 값 표시, 쉽게 내보내고 읽을 수 있는 형식으로 저장할 수 있음.
2.3. Decision Bank
Anomaly Decision
처음 두 banks의 이상 징후 점수와 그래프는 수동 분석을 위해 전문가에게 전송됨.
- (Gruhl et al. 2021)에 따르면 novelties는 sensor failure, component failure, system failure, and concept drift의 네 가지 등급으로 분류할 수 있음.
- Decision bank은 해당 결정뿐만 아니라 novelties의 범주에 대한 전문가들에게 다음과 같은 제안을 제공할 수 있음:
• 센서 중 하나만 비정상적으로 작동하는 Sensor Failure의 맥락에서, 고장 센서의 데이터를 이러한 모든 데이터를 폐기하는 대신 관련성이 높은 센서의 데이터로 대체할 수 있음.
• Component Failure은 구성 요소의 여러 low-correlated 센서가 동시에 비정상적으로 작동함을 나타냄. 상관 관계가 낮다는 것은 이러한 센서가 친밀한 관계를 갖지 않을 수 있다는 것을 의미하므로 구성 요소의 결함을 나타냄. 부품이 다른 부품과 연결되면 전체 시스템이 고장날 수 있음. 이러한 novelties는 업데이트보다는 추가 분석과 물리적 시스템 유지보수를 위해 이상 데이터베이스에 저장되어 함.
• System Failure은 여러 구성 요소에서 고장이 감지되는 다중 구성 요소 고장과 유사함. system failure은 여러 개의 고장 난 구성 요소 또는 단일 고장 구성 요소로 인한 연쇄 반응으로 인해 발생할 수 있음. component failure과 마찬가지로 이러한 system failure도 학습하는 대신 이상 데이터베이스에 저장해야 함. 또한 수동 개입으로 인해 시스템 장애가 발생할 수도 있습니다. 예를 들어, 풍력 터빈은 상당한 손상을 피하기 위해 높은 풍속 조건에서 차단 메커니즘에 의해 정지되어야 한다. 수동 개입이 장기적이고 주기적인 경우, 그러한 시스템 장애는 신경망에 의해 학습될 수 있다.
• Concept Drift는 신경망 예측과 센서 측정 사이의 오차가 소스 또는 대상 데이터 분포의 변화로 인해 어느 시점부터 증가하기 시작한다는 것을 의미함. 예를 들어 센서 또는 장치를 교체하거나 센서 매개변수를 조정하거나 환경 및 시간적 변화가 있을 때 종종 발생함. 이런 종류의 novelties는 업데이트를 위한 새로운 과제로 봐야 함.
→ 모듈이 제시한 분석과 제안에 따라 전문가들은 이러한 이상 현상을 폐기하거나 모델 업데이트에 사용할 수 있음. 이상 평가에서 잘못 분류된 신규성이 너무 많은 경우, 전문가는 임계값과 같은 관련 매개 변수를 조정하거나 이상 탐지기를 업데이트하여 거짓 양성 비율을 줄일 수 있음.
Model Decision
업데이트된 신경망에는 backup, rollback, and hyperparameters adjustment이라는 세 가지 중요한 결정이 있다. 이 결정들은 관련이 있다.
backup은 성공적인 업데이트 후 신경망과 데이터 세트를 저장하는 것을 의미함. rollback은 업데이트가 실패할 경우 업데이트된 모델이 새 업데이트의 초기화 상태로 백업 상태로 돌아간다는 것을 나타냄.
여기서, 성공적인 업데이트는 손실 함수가 오래된 작업에 대한 신경망의 성능이 눈에 띄게 저하되지 않고 알 수 없는 작업을 학습하는 데 있어 점차 낮은 상태로 수렴됨에 따라 정의됨. 성공적으로 업데이트된 모델의 매개 변수는 backup으로 저장되어야 함. replay-based continual learning algorithms의 유형에 따라 데이터 backup은 알려진 작업에 대한 훈련 데이터 세트를 원래 형식으로 저장하거나 현재 작업으로 생성 적대적 네트워크를 훈련시켜 가짜 데이터를 생성하는 것을 의미할 수 있음.
반대로, 실패한 업데이트는 손실이 주어진 훈련 기간 내에 수렴될 수 없거나 업데이트된 모델이 평가 단계에서 오래된 작업에 대한 대부분의 지식을 잃는다는 것을 의미함. common continual learning algorithms을 사용한 최적화 프로세스는 확률적 경사 하강으로 목표 손실 함수를 최소화하고 있음. 따라서 훈련 과정의 확률성은 업데이트 실패를 초래하여 치명적인 망각으로 이어질 수 있음.
또한 training dataset의 부적절한 하이퍼 파라미터 또는 탐지되지 않은 이상 징후도 업데이트 실패로 이어질 수 있음. 따라서 decision bank은 모든 adjustmentable hyperparameters를 전문가에게 표시하고 해당 설명과 함께 명시적인 제안을 제공할 수 있음. 전문가들은 업데이트 결과를 받아들일 수 없는 경우 미래의 애플리케이션 또는 새로운 업데이트에 대한 직관과 전문적 경험을 통해 하이퍼 파라미터를 조정할 수 있음.
3. Use Case & Outlook
3.1. Use Case: The CLeaR Framework
CLEaR(continual learning for regression problems)은 non-stationary 회귀 애플리케이션 시나리오(He and Sick 2021)에서 치명적인 망각 문제를 극복하기 위한 적응형 프레임워크임.
- 실시간 데이터 스트림의 샘플은 novelties과 familiarities으로 분류됨.
- novelties은 훈련된 신경망이 정확하게 예측할 수 없는 샘플인 반면, familiarities은 네트워크가 친숙한 샘플임.- CLeaR은 진실과 예측 사이의 오류를 계산하고 오류를 임계값과 비교하여 두 가지 유형을 구별하는데, 이는 훈련 후 네트워크의 수렴에 따라 동적으로 조정할 수 있음.
- novelties과 familiarities은 지속적인 학습을 위해 두 개의 독립적인 buffer에 저장됨.
Introduction에서 언급한 5가지 문제점은 현재 CLeaR 설계에 존재함.
1. novelty and anomaly의 경계는 분류에 따라 모호하며, 잘못된 분류로 인해 업데이트 실패로 이어질 수 있음.
2. (He and Sick 2021)과 (He, Huang, and Sick 2021)의 CLeaR의 실험 설정은 동일함. 즉, 사전에 최적화된 고정 매개 변수 세트를 사용하여 탐지된 모든 알 수 없는 작업을 학습함.
3. CLEaR 프레임워크의 두 가지 초 매개 변수, 즉 신규 버퍼 크기와 임계값 요인이 학습 성과에 미치는 영향은 (He and Sick 2021)에서 분석됨. 두 매개 변수는 트리거된 업데이트의 빈도를 제어하고 새로움 감지를 위한 판단 메커니즘을 각각 조정하여 모든 작업에서 업데이트된 모델의 성능을 균형 있게 조정하고 응용 프로그램의 계산 오버헤드에 영향을 미침. 그럼에도 불구하고, 이러한 초 매개 변수의 견고성에 대한 포괄적인 평가는 이전 연구에서 여전히 누락되어 있음. 신경망의 유형과 연속 학습 알고리듬과 같은 프레임워크의 이러한 구성 요소, 버퍼의 크기 및 신규성 감지 방법은 특정 애플리케이션의 요구 사항에 따라 사용자 정의할 수 있기 때문임.(?) 이러한 하이퍼 파라미터는 다양한 작업을 효율적으로 학습하기 위해 애플리케이션 중에 동적으로 조정되어야 함.
5. 제안된 모듈은 시각화 및 포괄적인 평가를 제공하여 CLEaR 프레임워크의 설명 가능성과 투명성을 향상시킬 수 있음.
3.2. Outlook
- 본 논문에서는 real world 상황에서 continual learning을 적용할 때의 문제점을 분석함.
- 이러한 문제를 해결하기 위해 다양한 딥러닝 관련 기술과 통합된 설명 가능 모듈의 conceptual design을 제안함.
- 향후에는 제안한 design을 구현하고 확장하여 기존 CLeaR framework에 적용할 것임.
- 모듈의 시각적이고 설명 가능한 출력을 기반으로 전문가는 continual learning에 의해 구동되는 신경망을 동적으로 관리할 수 있으며, 작업 업데이트를 통해 신뢰할 수 있는 평가를 수행할 수 있음.
