성능 데이터 모델링의 개요
- 성능 데이터 모델링의 정의
- 성능 저하의 원인 중 하나는 데이터 모델링의 근복적인 디자인이 잘못되어 있는 경우도 많다
- 따라서 성능 데이터 모델링을 통해 성능향상을 도모해야한다
- 성능 데이터 모델링이란?
- 데이터베이스 성능향상을 목적으로 설계단계의 데이터모델링 때부터 성능과 관련된 사항이 모델링에 반영될 수 있도록 하는 것
- 성능 데이터 모델링 수행시점
- 사전에 성능 모델링을 할수록 성능 향상을 위한 비용은 적게 든다
- 분석/설계 단계에서 성능을 고려해 데이터 모델링을 수행할 경우 재업무 비용을 최소화할 수 있다
- 따라서 분석/설계 단계에서 처리성능을 향상시킬 방법을 고려해야한다
- 성능 데이터 모델링 고려사항
- 성능 데이터 모델링 프로세스
- 정규화 → 정규화가 1등
- DB 용량 산정
- 트랜잭션의 유형 파악 → 테이블 수직 분할 할 때(반정규화)
- 용량과 트랜잭션의 유형에 따라 반정규화
- 이력모델 조정, PK/FK 조정, 슈퍼타입/서브타입 조정
- 성능관점에서 데이터 모델을 검증
- 성능 데이터 모델링 프로세스
정규화
정규화란?
: 엔티티를 작은 단위로 분리하는 과정
→ 큰 엔티티를 작은 엔티티들로 분리하고 관계 맺음
: 논리 데이터 모델에서 행하는 과정이다.(개념 모델링 X, 물리 모델링 X)
정규화의 특징 및 하는 이유와 개념 = 장점
- 데이터의 무결성을 위해 수행
- 최소한의 데이터만을 하나의 엔티티에 넣는 과정, 데이터 분해 과정
- 데이터 일관성 확보
- 데이터 독립성 확보 → 데이터 중복 제거
- 데이터 유언성 확보 → 필요 데이터들의 분할로 인해 유연하게 접근 가능
- 입력, 수정, 삭제 성능은 일반적으로 향상
- → 조회 성능이 저하 될 수 있음
정규화의 단점
- 엔티티 갯수 증가
- 이로 인한 관계 증가
- 데이터 조회 시 여러번의 조인이 요구
- 조회 성능의 저하
- 식별자, 비식별자랑 헷갈리지말자 → 식별자 = join 최소화
정규화의 종류
각 정규화를 통해 이루어지는 행위가 있는데
이 행위를 만족하는 엔티티 구조는
제 1 정규형 릴레이션
제 2 정규형 릴레이션
제 3 정규형 릴레이션 이라고 칭한다.
제 1 정규화
: 테이블 칼럼들이 원자성(특성의 중복을 방지) 갖게 하기 위해 엔티티 분해
→ 하나의 인스턴스가 비슷한 속성을 여러개 가지지 않게 하기 위해 분리하는 것
제 2 정규화
: 엔티티의 모든 일반 속성은 반드시 주 식별자의 모든 속성들에
‘부분 종속’이 아닌 ‘완전 종속’을 가져야한다.
이 때 만약 ‘부분 종속’을 가지는 일반 속성이 있다면 해당 속성과 해당 속성의 결정자인 부분 종속을 이루고 있는 주 식별자의 속성을 따로 떼어내 추가적인 엔티티를 만들어 제 2 정규형을 만족하는 릴레이션을 구축하는 것
: 또는 주 식별자의 속성이 아닌 일반 속성 끼리 종속 관계를 맺어도 이에 대해 해당 일반 속성이 새로운 엔티티에서 제 2 정규성을 만족하도록 엔티티를 추가적으로 만들어준다.
ex) 엔티티 1에서 일반속성A→일반속성B 이면
일반속성 B는 엔티티 1에서 제거하고 A는 엔티티 1에 남겨둔 채로
엔티티 2를 만들고 일반속성 B를 엔티티 2의 일반속성으로 엔티티 1의 일반속성 A를 FK로 사용하여 엔티티 2의 주식별자 로서 엔티티를 구축하고 릴레이션을 유지하게하는 것
제 3 정규화
: 정규화된 엔티티의 일반 속성들은 주 식별자에만 함수적 종속을 가져야한다.
그런데 만약 주 식별자의 속성들끼리 종속 관계를 가지고 그 이후에 또 일반 속성에 대해 결정자가 되던지 일반 속성끼리 종속성을 가지는데 이 때의 결정자가 주 식별자 속성에 종속되어있는등
A → B, B → C 와 같은 이행적 종속 을 이루는 TABLE(엔티티) 일 때
이러한 ‘이행적 종속’을 깨도록 추가적인 엔티티를 만들고 관계를 형성해주는 것이
제 3 정규화 이다.
BCNF 정규화
: **모든 결정자가 후보키가 되도록 테이블을 분해**하는 것
→ 후보키 : 식별자의 ‘유일성’, ‘최소성’ 을 만족하는 속성 집합(or 단일 속성)제 4 정규화
: 여러 칼럼이 하나의 칼럼 종속시킬 때 분해해서 ‘**다중값 종속성’ 제거** 제 5 정규
: **조인에 의해 새로운 종속성 발생** 시 이를 막기 위해 엔티티 재 분해관계와 조인의 이해
관계란?
: 부모 엔티티의 식별자를 자식에 상속하고, 상속된 속성을 매핑키(조인키)로 활용
관계의 분류
- 존재 관계
- 행위 관계
조인이란?
: 데이터 중복을 피하기 위해 테이블은 정규화에 의해 분리
→ 이렇게 분리된 테이블을 동시에 출력하거나 관계가 있는 테이블 참조 위해서는 테이블 연결
→ 이 때 이러한 연결 과정을 JOIN 이라 칭한다.
계층형 데이터 모델
: 하나의 엔티티 내에서 인스턴스 끼리 계층 구조를 가지는 경우
→ 계층 구조를 갖는 인스턴스끼리 연결하는 조인을 셀프 조인이라 한다.
(같은 테이블 내에서 여러 번 조인 되는 것)
ex) 인스턴스 A를 긁었는데 그 안에 속성 B에 대한 값이 해당 엔티티 내의 다른 인스턴스에 있는 값이여서 이들을 두 속성을 같이 SELECT 하고, WHERE & AND로 조건 먹인다음 긁어낼 때 두 SELECT에 의해 하나의 엔티티 내에서 여러번 조인이 발생
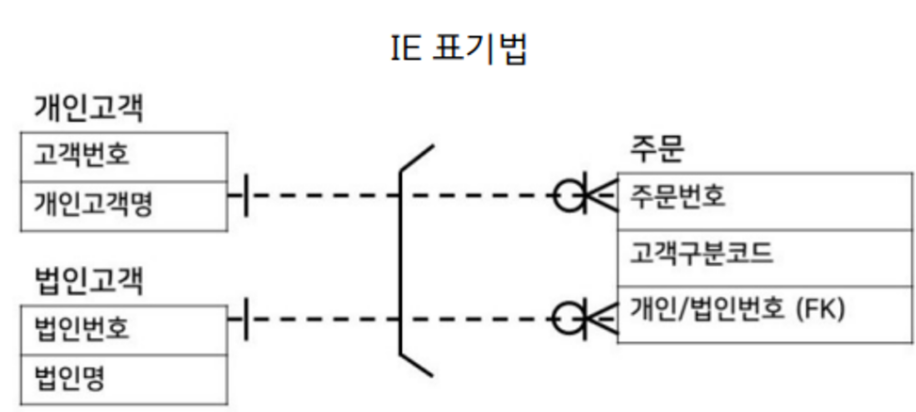
상호배타적 관계
: 하나의 부모가 2개의 자식 엔티티를 가질 때 행위 조건에 따라 두 자식 중 하나의 자식만 관계를 가질 수 있는 것을 상호배타적 관계라 칭한다.
- 두 테이블 중 하나만 가능한 관계를 말함
ex) 주문 엔터티에는 개인 또는 법인번호 둘 중 하나만 상속될 수 있음 => 상호배타적 관계
즉, 주문은 개인고객이거나 법인고객 둘 중 하나의 고객만이 가능
모델이 표현하는 트랜잭션의 이해
트랜잭션의 특징
- 하나의 연속적인 업무 단위를 뜻함
- 트랜잭션에 묶인 엔티티들은 ‘필수적 관계’ 가짐
- 하나의 트랜잭션에 속한 동작들은 모두 성공하거나, 모두 취소(UNDO)되어야한다. → 트랜잭션의 ‘원자성’
- 서로 독립적으로 업무가 발생하면 안됨, 순차적으로 함께
- 부분 커밋 불가, 동시 커밋&롤백
● 필수적, 선택적 관계와 ERD
- 두 엔터티의 관계가 서로 필수적일 때 하나의 트랜잭션을 형성
- 두 엔터티가 서로 독립적 수행이 가능하다면 선택적 관계로 표현
IE 표기법)
- 원을 사용하여 필수적 관계와 선택적 관계를 구분
- 필수적 관계에는 원을 그리지 않는다.
- 선택적 관계에는 관계선 끝에 원을 그린다.
바커표기법)
- 실선과 점선으로 구분
- 필수적 관계는 관계선을 실선으로 표기
- 선택적 관계는 관계선을 점선으로 표기
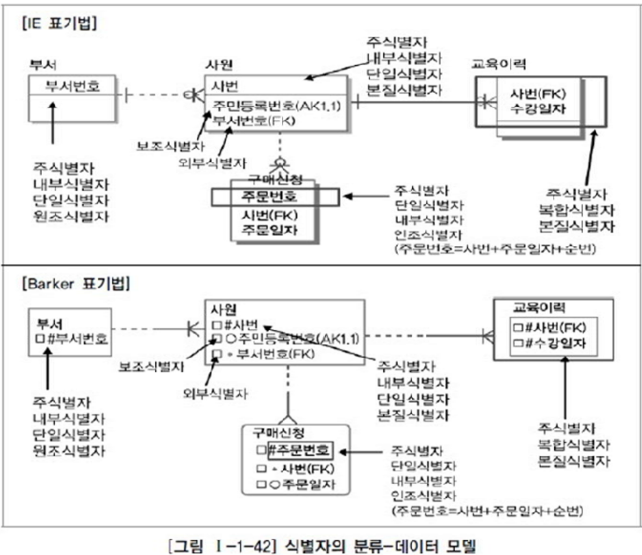
본질 식별자와 인조 식별자
원조(본질) 식별자
: 업무에 의해 만들어지는 식별자(꼭 필요한 식별자)
인조(대리) 식별자
: 원조 식별자가 PK 2개 이상인 복합 식별자 일 때
속성들을 하나의 속성으로 묶어서 사용하면 이것이 인조 식별자
: 꼭 필요하진 않지만 편의성을 위해 인위적으로 만들어지는 것
인조 식별자의 단점
- 중복 데이터 발생 가능성 → 데이터 품질 저하
- 불필요한 인덱스 생성 → 저장 공간 낭비 및 DML 성능 저하
- 개발 편의성이 줄어들 수 있음
