CPU 스케줄링
이전 시간에 우리는 CPU를 스케줄링하는 알고리즘인 FCFS(first come first served)를 배웠다. 오늘은 CPU 스케줄링 알고리즘인 shortest job first와 priority scheduling, round-robin 알고리즘을 배울 것이다.
Shortest-Job-First(SJF)
Shortest-Job-First(SJF) : 이름 그대로 CPU 실행 시간이 가장 짧은 프로세스부터 먼저 CPU서비스를 받게 하는 알고리즘이다.
- SJF를 Average Waiting Time의 측면에서 FCFS와 비교하기.

ready queue에 위와 같은 프로세스가 대기하고 있다고 가정해 보자. SJF와 FCFS를 AWT의 측면에서 효율성을 비교하려면 각 알고리즘별로 AWT가 얼마나 걸리는지 도출해 내어야 한다. 먼저 SJF 알고리즘부터 살펴보자.
( 1 ) 이 ready queue에서 SJF 알고리즘을 사용해 CPU 스케줄링을 한다면 Average Waiting Time이 얼마나 걸릴 것인가?
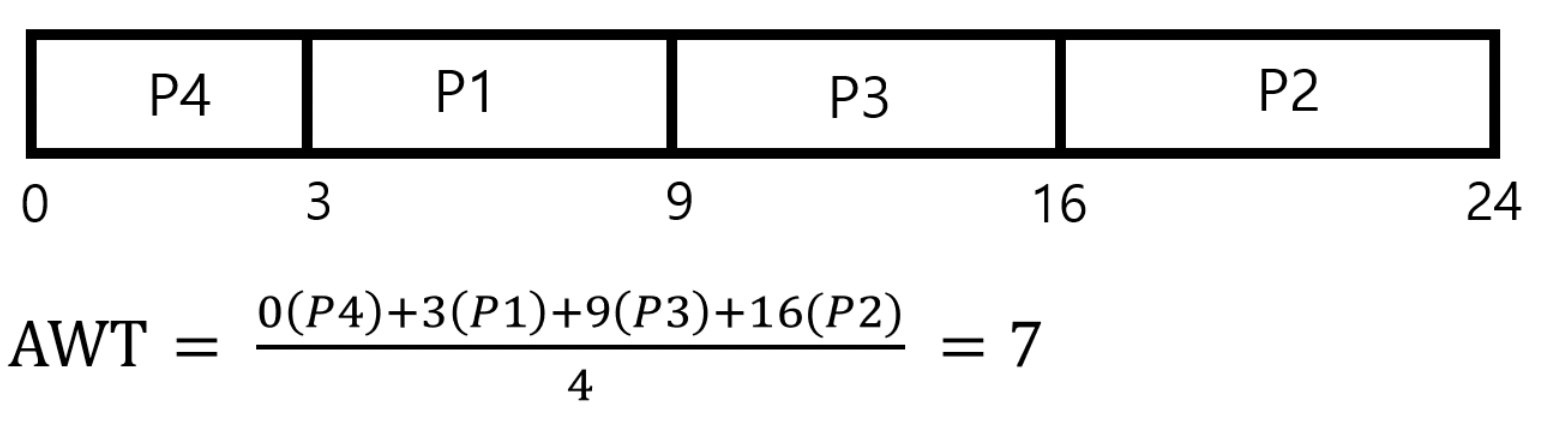
SJF 알고리즘은 CPU 실행 시간이 짧은 프로세스 순서대로 실행되기 때문에 P4->P1->P3->P2 의 순서대로 실행된다. 그려면 각 프로세스 당 대기시간이 p1부터 3, 16, 9, 0이기 때문에 평균 대기시간(Average Waiting Time)은 7 msec이 된다.
그렇다면 FCFS 알고리즘의 경우를 살펴보자.
( 2 ) 아까의 ready queue에서 FCFS 알고리즘을 사용해 CPU 스케줄링을 한다면 AWT는 얼마나 걸릴 것인가?
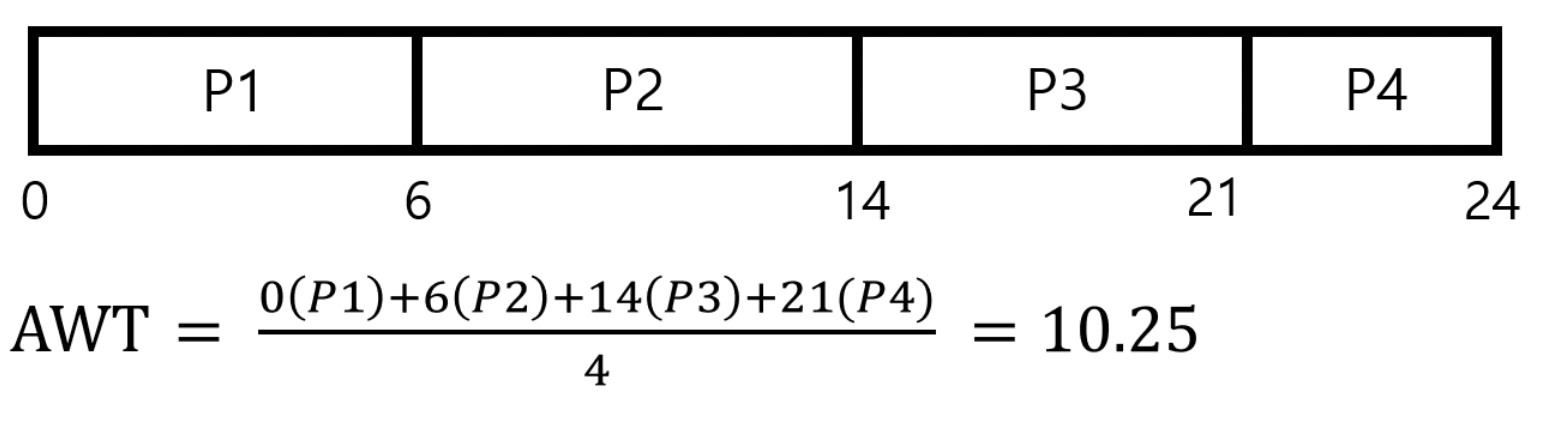
FCFS 알고리즘은 ready queue에 들어온 프로세스 순서대로 실행되기 때문에 P1->P2->P3->P4의 순서대로 실행된다. 그러면 각 프로세스 당 대기시간이 P1부터 0, 6, 14, 21이기 때문에 평균 대기시간(Average Waiting Time)은 10.25 msec이 된다.
두 AWT 값의 비교를 통해 SJF 알고리즘이 FCFS 알고리즘보다 AWT 측면에서 더 효율적인 것을 알 수 있다.
-
SJF 알고리즘은 대기 시간을 줄이는 측면에서 가장 효율이 좋은 알고리즘이라는 것이 증명되었다. (Provably optimal)
-
그러나 not realistic하고, prediction이 필요하다.
실제로 각 프로세스의 CPU 실행 시간이 얼마나 될 지는 모르고, 이를 예측할 수 있기는 하나 context switching이 많아 overhead가 있다. -
선점 방식과 비선점 방식 모두 가능하다. 선점 방식(preemptive)의 경우 최소잔여시간을 우선시한다. 프로세스 실행 중에 더 실행 시간이 짧은 프로세스가 오면 원래 실행 중인 프로세스를 중단하고 더 짧은 프로세스를 실행하기 때문에 최소잔여시간으로 고려한다.
-
선점 방식의 SJF와 비선점 방식의 SJF 알고리즘의 효율성 비교하기
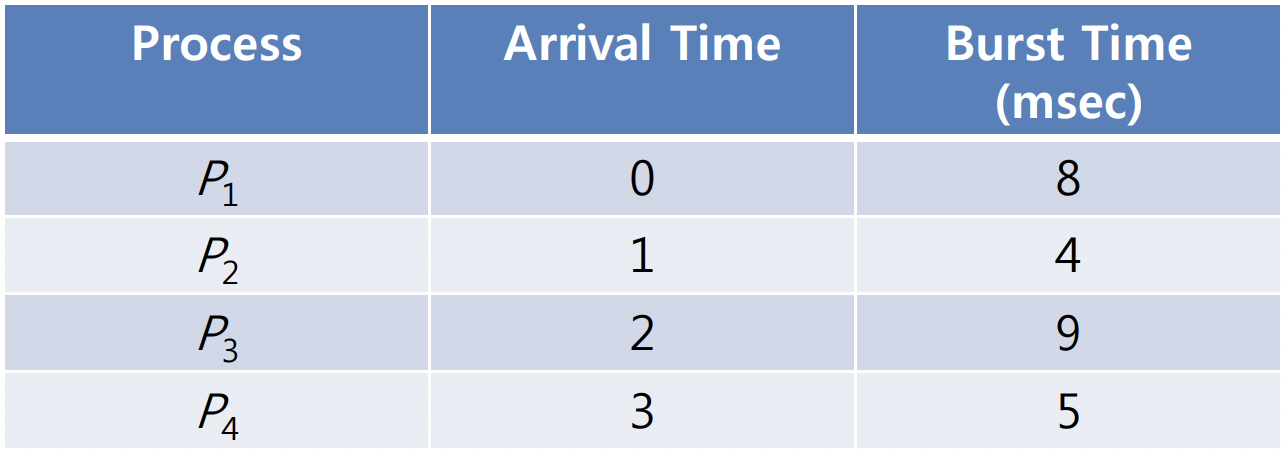
위와 같이 ready queue에 프로세스가 대기 중이라고 할 때 선점 방식과 비선점 방식에서 AWT 측면에서 효율성을 비교해 보기 위해 각 방식에서 AWT가 얼마가 도출되었는지 확인한다.
( 1 ) 선점 방식에서의 SJF 알고리즘
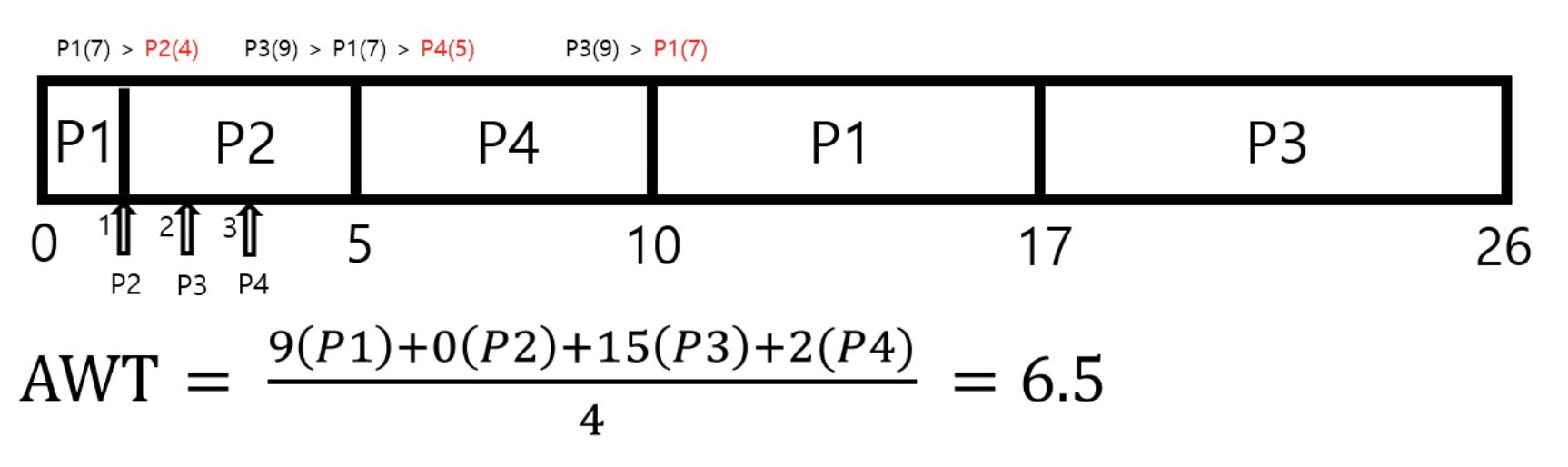
선점 방식에서는 각 프로세스가 ready queue로 들어왔을 때 가장 짧은 CPU 실행시간을 가진 프로세스, 즉 최소잔여시간을 고려해서 가장 최소인 잔여시간을 가진 프로세스가 CPU 서비스를 받는다.
가장 처음에는 P1만 ready queue안에 들어있기 때문에 P1이 실행되는데, 1 msec에 P2가 들어오므로 P2로 context switching된다. 2msec와 3msec에 각각 P3와 P4가 들어오는데 P3와 P4는 각각 burst time이 9msec와 5msec로 잔여 시간이 3msec과 2msec이 남은 P2보다 길기 때문에 P2가 가장 먼저 종료된다.
P2가 종료된 이후로 가장 잔여시간이 짧은 프로세스는 P4로 5msec이 남아 있다. 이 이후로는 프로세스가 새로 들어오지 않으므로 P4가 종료되었다.
P4 종료 이후에는 P3와 P1이 남아 있는데 P3는 9msec, P1은 7msec이 남아 있으므로 P1이 먼저 실행되고 종료된 뒤에 P3가 실행된다.
이 때의 AWT를 계산해 보면 6.5msec이 걸린다. 각각의 프로세스가 ready queue에 들어온 시간과 종료된 시간을 잘 고려해서 대기시간을 도출하면 된다. 최종 AWT는 6.5 msec이다.
( 2 ) 비선점 방식에서의 SJF 알고리즘
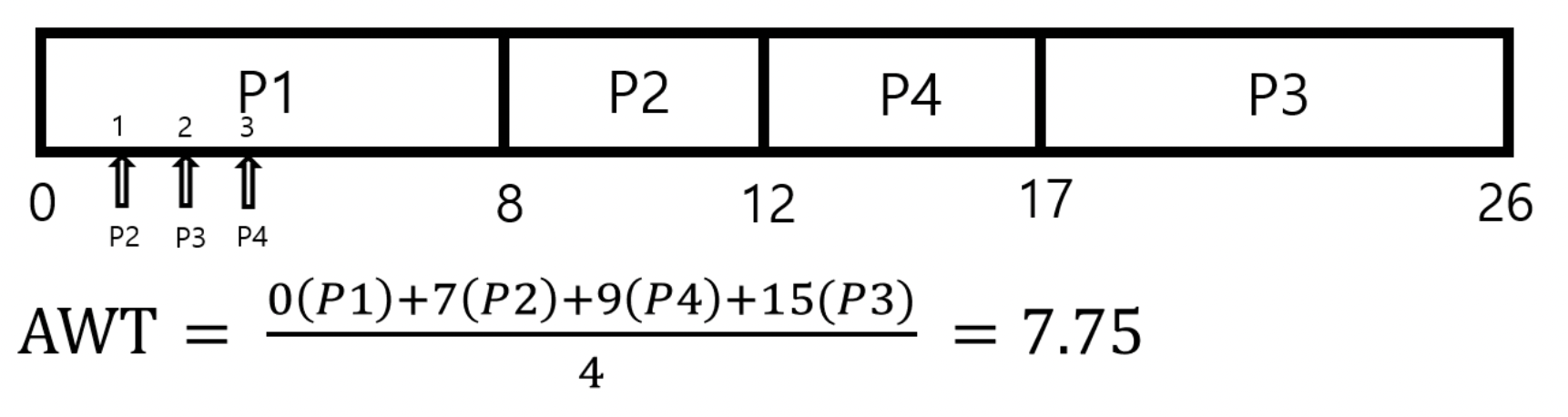
비선점 SJF 알고리즘에서는 ready queue에서 job이 나갈 때, 가장 짧은 CPU 실행시간을 가진 프로세스 먼저 실행된다. 선점 방식의 SJF 알고리즘과의 차이점은 context switching이 일어날 수 있다는 점이다.
P1만 ready queue에 있으니 먼저 P1이 실행되고, 이후 1msec, 2msec, 3msec에 P2,P3,P4가 ready queue에 들어왔다. 8msec에 P1이 종료되어 가장 짧은 burst time을 가진 P2가 실행되고, 그 뒤에 P4, P3가 실행된다.
이 때의 AWT를 계산해 보면 7.75 msec이 걸린다. 이 때도 주의할 점은 각 프로세스가 ready queue에 들어온 시간까지 고려해야 한다는 것이다.
AWT측면에서 비교한 결과 선점 SJF 알고리즘이 비선점 SJF 알고리즘보다 더 효율적이라는 것을 알 수 있었다.
Priority Scheduling
Priority Scheduling : 우선순위가 높은 프로세스를 먼저 실행한다.
Unix/Linux 등 일반적인 상황에서 우선순위 숫자가 낮은 프로세스가 우선순위가 높다.
-
Priority Scheduling에서 AWT 측정하기.
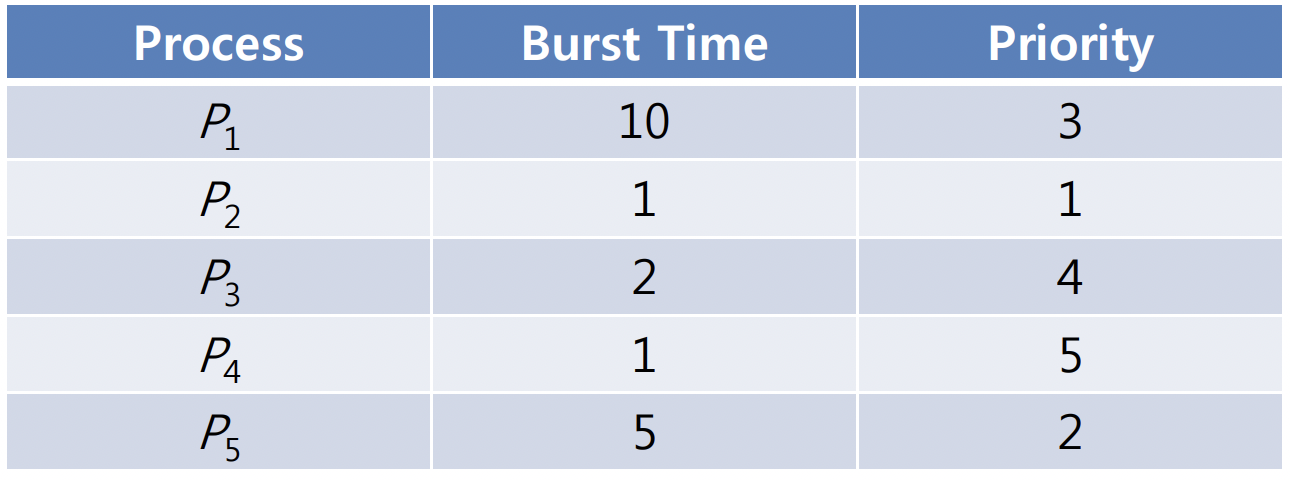
ready queue 안에 위와 같은 burst time(cpu 실행시간)과 우선순위를 가진 프로세스가 있을 때 AWT를 계산해보자.
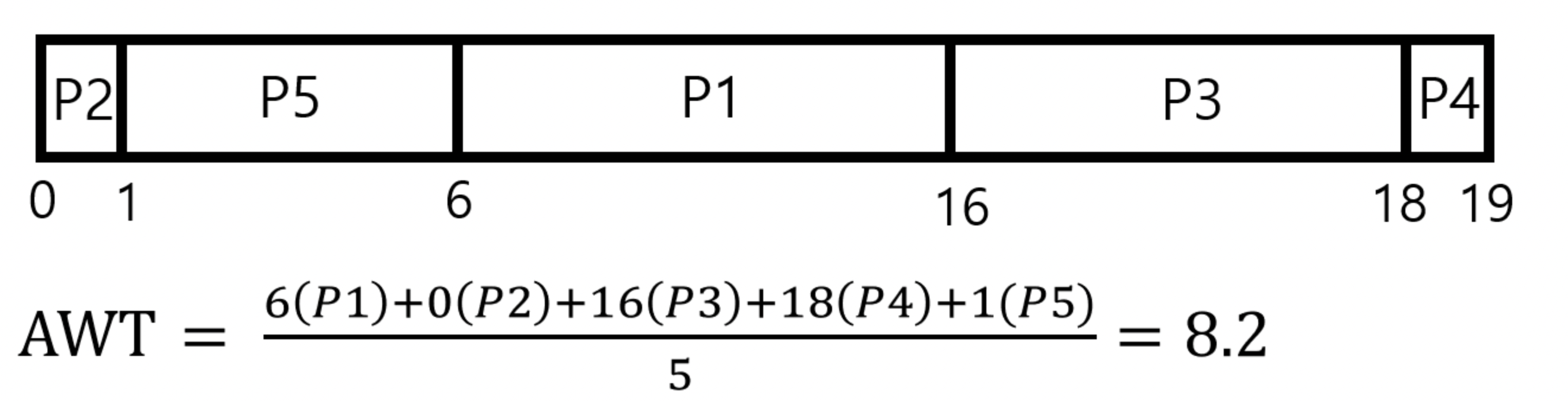
위와 같이 우선순위가 높은 순서대로, 즉 P2->P5->P1->P3->P4의 순서대로 프로세스가 실행되며, 대기 시간을 구해 평균을 구하면 8.2 msec 이 나온다. -
Priority는 어떻게 정할까?
internal : time limit, memory requirement, i/o to CPU burst(i/o또는 cpu 실행시간이 낮은 것부터)
external : amount of funds being paid, political factors -
선점 방식과 비선점 방식 모두 가능함.
-
문제점
Indefinite blocking : starvation(기아) - 우선순위가 가장 높은 프로세스가 CPU의 서비스를 받는데, 우선순위가 높은 프로세스가 ready queue로 계속 들어와 프로세스가 CPU 서비스를 못받는 상황.
Solution : aging - aging이 높을수록 우선순위를 높여주어 기아 현상이 일어나지 않도록 함.
Round-Robin
Round-Robin : 시분할 시스템을 위해 만들어진 스케줄링
-
TSS(Time Sharing System)에서 주로 사용.
-
Time Quantum(시간 양자 = time slice, 기호 : Δ)로 시간을 쪼갠다.
-
항상 선점 방식이다. 시간을 쪼개서 이 time slice가 다 되면 다른 프로세스로 넘어가기 때문에 선점 방식이다.
-
Round-Robin 스케줄링에서 time quantum이 4msec일 때, AWT 시간을 구해보자.

위와 같이 ready queue에 3개의 프로세스가 대기 중이고, 각각의 burst time이 나와 있을 때 AWT를 구해 보자.
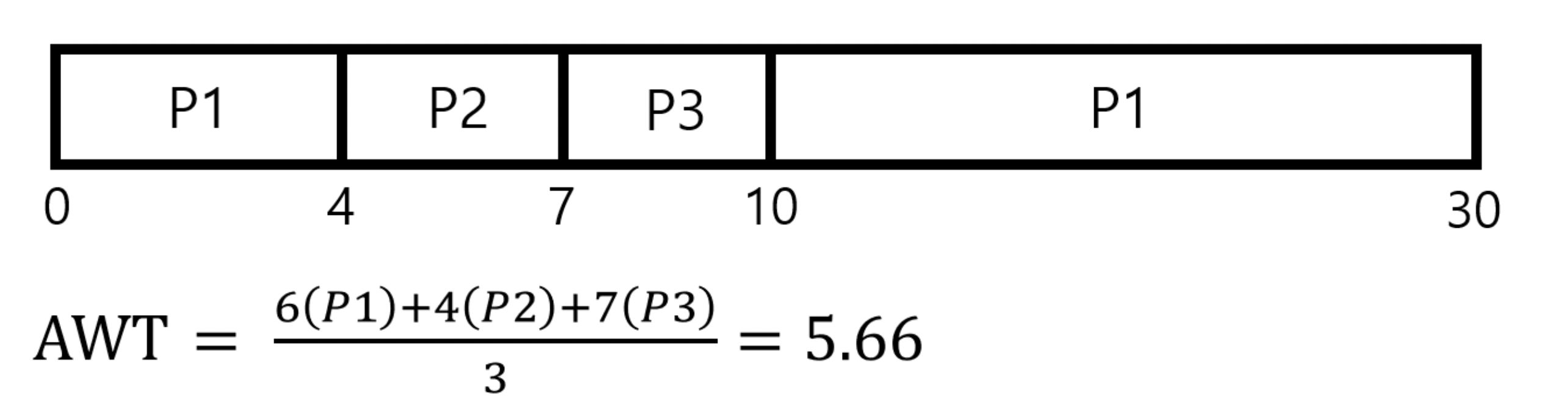
time slice가 4 msec이므로 P1은 4 msec에서 P2로 context switching이 일어난다. 그러나 P2는 burst time이 3 msec이므로 time slice인 4 msec보다 작아 7msec에서 종료되고, P3가 실행된다. P3 또한 burst time이 3msec으로 time slice보다 작아 10 msec에서 종료되며, 이후 ready queue에는 P1만 남아있어 P1이 실행되고 종료된다.이 상황을 AWT로 계산해보면, P1은 대기 시간이 총 6msec이고, P2는 4, P3는 7이다. 따라서 평균 대기시간은 5.66 msec이다.
그러나 이 time slice의 값에 따라 AWT와 같은 척도가 달라진다.
-
Performance depends on the size of the time quantum(time quantum에 굉장히 의존적이다.)
1 ) Δ -> ∞ : FCFS(First Come First Served), Δ가 무한대라면 ready queue에 들어온 순서대로 cpu 서비스된다.2 ) Δ -> 0 : Processor sharing (context switching overhead 증가), switching이 매우 활발하게 일어나 process들이 거의 같이 돌고 있는 것처럼 느껴짐(TTS처럼). dispatch(이전 process의 PCB 저장, 이후 실행될 process의 PCB 복원) -> 시간 소요, 스케줄링 ==> overhead 증가.
-
time slice의 값(Δ)에 따른 ATT의 척도 변화 관찰하기.
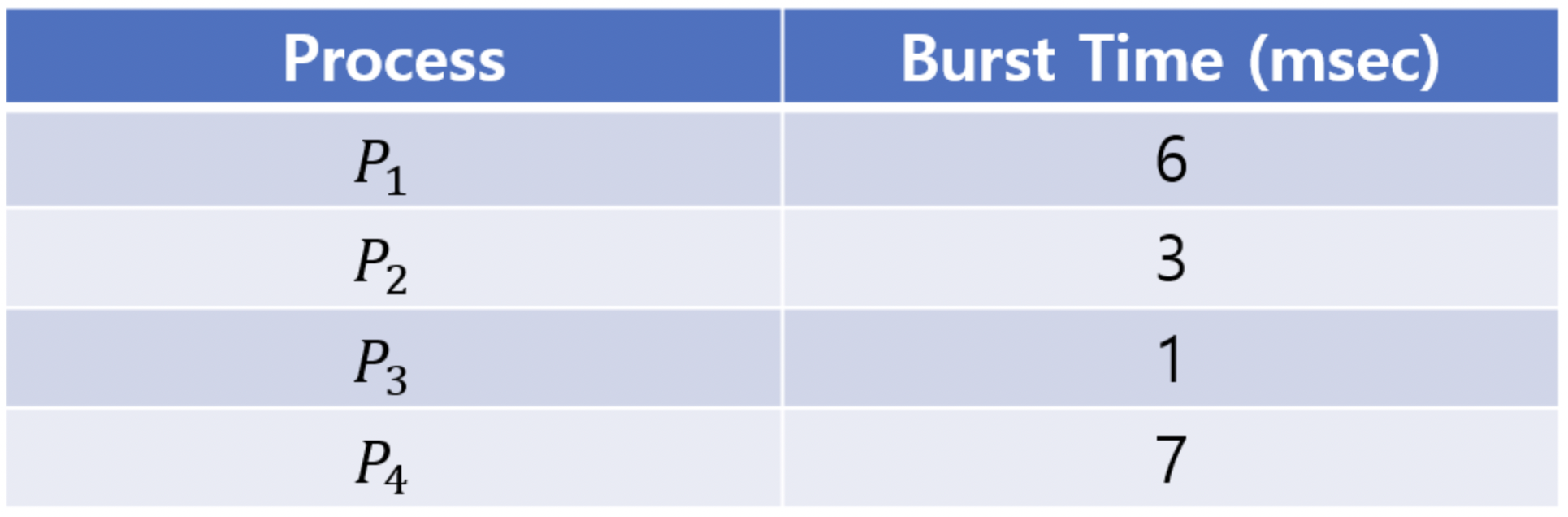
위와 같이 ready queue에 4개의 프로세스가 대기 중이라고 할 때, time slice가 각각 1, 5일 때의 ATT값을 구해 보자.1 ) time slice(Δ) = 1일 때 ATT의 값은?
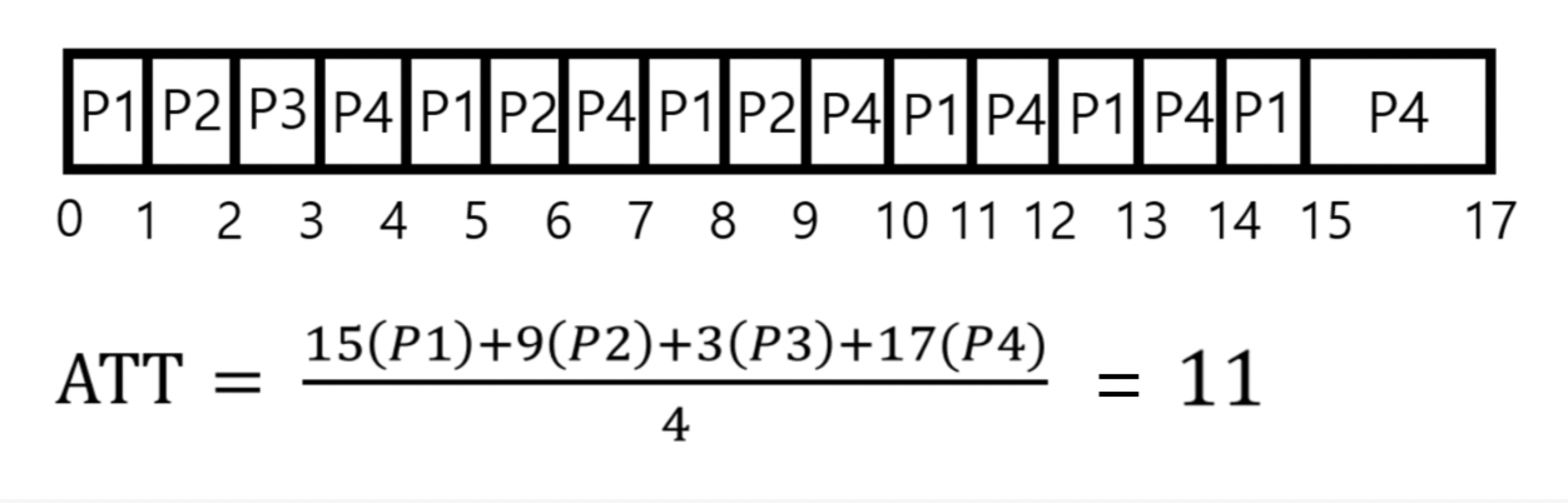
time slice가 1이니, 각 프로세스들은 1 msec이 지나면 context switching이 일어난다. CPU burst time을 모두 소진한 프로세스는 종료되며, 아직 소진되지 않은 프로세스들은 다시 실행된다.이번에는 AWT가 아닌 ATT로 비교한다는 것을 주의한다.
P1이 종료되기까지는 15 msec, P2는 9, P3는 3, P4는 17 msec이 걸렸기 때문에 평균 반환시간(Average Turnaround Time)은 11 msec이 걸린다.
2 ) time slice(Δ) = 5일 때 ATT의 값은?
time slice가 5이니, 각 프로세스는 cpu burst time이 모두 끝나 종료되거나, time slice가 모두 소진되기 전까지 실행된다. 따라서 P1의 burst time이 6이니 5msec동안 실행되다가 time slice가 소진되어 P2로 context switching한다. P2는 cpu burst 가 3이니 3msec동안 실행되고, P3는 cpu birst time이 1이니 1msec동안 실행된다. P4는 cpu birst가 7이니 time slice인 5msec만큼 실행되다가 P1으로 context switching하고, P1은 잔여시간이 1msec이니 실행되고 종료되다가 P4또한 실행되고 종료된다.
이번에도 AWT가 아닌 ATT로 계산한다.
각 프로세스가 종료되기 까지의 시간을 더해 평균을 내면 12.25 msec이 걸린다.
Round-Robin은 time slice에 따라 척도가 달라져 효율이 변화한다.
일반적으로 time slice에 따른 ATT의 변화는 다음 표와 같다.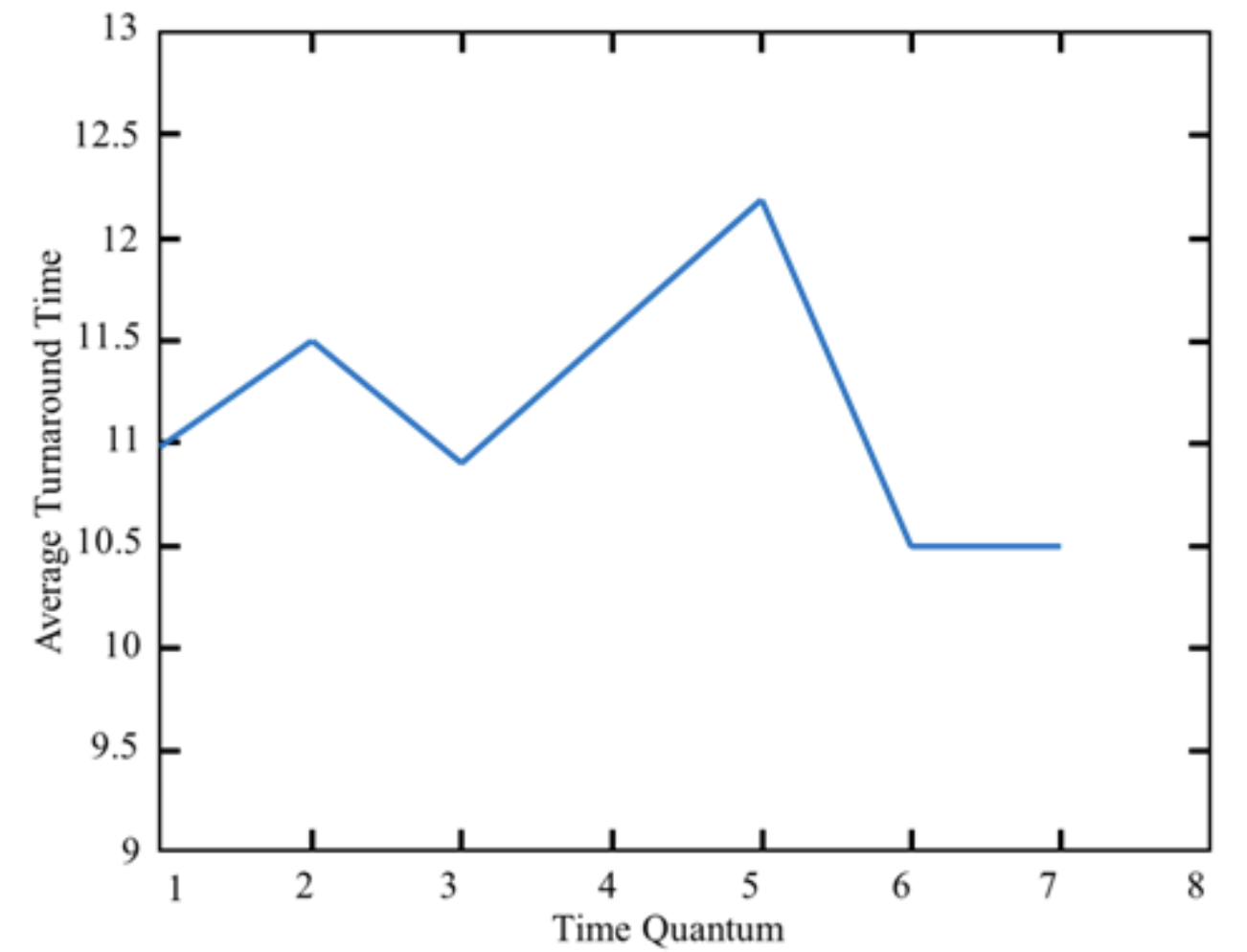
Multilevel Queue Scheduling
핵심 : 성격이 다른 그룹의 프로세스들끼리 같은 ready queue에 들어가는 게 맞지 않다고 여겨서 나온 스케줄링 기법.
Multilevel Queue Scheduliing : 각 process의 성격에 맞는 (queue의 그룹에 따라)Queue에 배정하는 스케줄링. 이전까지와는 다르게 여러 개의 ready queue가 존재한다.
-
Process groups(프로세스가 갖는 그룹)
1 ) System processes : OS가 하는 프로세스(가장 긴급히 처리될 필요가 있음)
2 ) Interactive processes : 사용자와 대화하는 프로세스. 대화형이 아닌 묶음으로 처리하는 batch process보다 먼저 처리될 필요가 있다.
3 ) Interactive editing processes : 대화형 edit 프로세스.
4 ) Batch processes : 대화형이 아닌, 묶음으로 일괄적으로 처리하는 프로세스.
5 ) Student processes
-
Single ready queue -> Several separate queues
- queue가 여러 개 존재한다.
- 각각의 Queue에 절대적인 우선순위가 존재한거나 CPU time을 각 queue에 차등적으로 배분한다.
- 각 queue는 독립된 스케줄링 정책을 가진다. 즉 각 process가 메모리에 올라올 때, group에 따라 다른 queue에 대기하고, 다른 스케줄링을 한다.
Multilevel Feedback Queue Scheduling
Multilevel Feedback Queue Scheduling : multilevel queue scheduling과 같이, 여러 개의 queue를 둔다는 점에서 같지만, 다른 큐로 프로세스가 옮겨갈 수 있다는 점에서 다르다.
- 복수 개의 queue
- 다른 queue로의 점진적 이동.
- 모든 프로세스는 하나의 입구로 진입
- 너무 많은 CPU time 사용 시 다른 queue로 이동.
- 기아 상태 우려 시 우선순위 높은 queue로 이동.
대부분의 운영체제는 다양한 큐를 두고 다양한 스케줄링 방법을 이용해 작업에 맞게 운용한다.
