NLP Pipeline
- Text Processing : 텍스트 정규화
- Feature Extraction : 벡터화
- Modeling : ML, DL
Text Processing
NLP를 위한 사전 작업
- Raw : 원본
"Jenna went back to University. - Normalize : 정규화
"jenna went back to university. - Tokenize : 토큰화
['jenna', 'went', 'back', 'to', 'university'] - Stopwords : 불용어 제거
['jenna', 'went', 'university'] - Lemmatize/Stemming : 표제어(사전형)/어간 추출
['jenna', 'go', 'univers']
Feature Extraction
Bag of Words (BoW)
- Normalized text의 corpus(말뭉치)를 vector화한 것
- 가장 단순한 자연어 표현 모델 중 하나
- 텍스트의 문법과 순서 무시, 다중성 유지
- 사용 분야
- 유사도 측정 : cosine similarity로 계산
- 감정 분석 :
len(matching_words)/len(corpus)비교로 텍스트의 긍정적/부정적 감정 파악
TF-IDF
- Term Frequency-Inverse Document Frequency
- 어떤 단어()가 문서군의 특정 문서() 내에서 얼마나 중요한지를 나타내는 휴리스틱
TF (단어 빈도)
- = 단어 가 문서 에서 나타난 빈도
- 과다 반복되는 무의미한 단어의 가중치를 낮춰야 한다.
- 방법: 에 를 취함
IDF (역 문서 빈도)
- = 단어 가 등장한 문서 수
- = 총 문서 수(상수)
- = 총 문서 중 단어 가 등장한 문서 비율
- 문서 빈도의 역수
- 단어 가 unique할수록 높아지고, common할수록 낮아진다.
- 문서 빈도의 역수
TF-IDF (단어 빈도-역문서 빈도)
-
TF-IDF는 휴리스틱이므로, 다양한 형태로 정의할 수 있다.
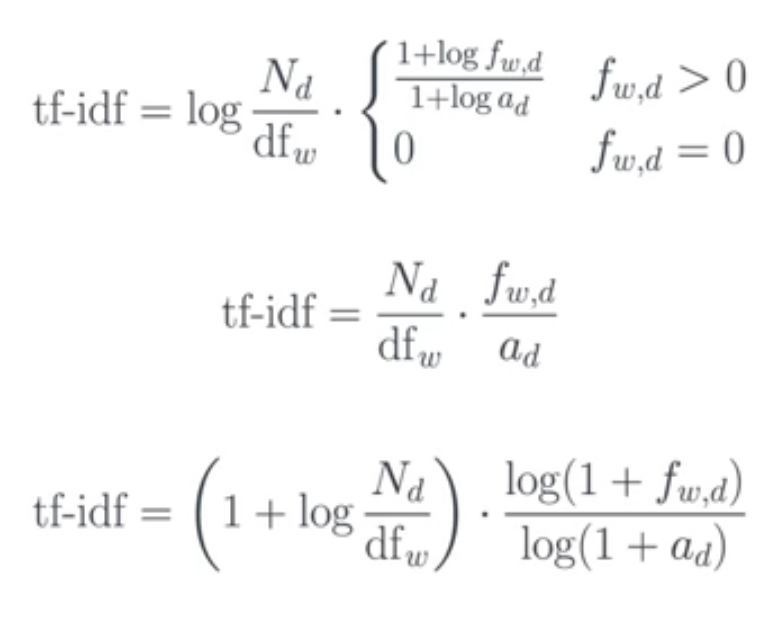
-
각 문서의 corpus 내 단어들을 TF-IDF로 변환하여, 각 문서를 vector화할 수 있다.
Similarity Analysis
- TF-IDF로 벡터화한 두 문서 벡터 (or ), (or )에 대해 유사도를 계산해 볼 수 있다.
Cosine Similarity 코사인 유사도
Jaccard Similarity 자카드 유사도
- 으로 해석 가능
