팁
- help(): 인자로 받는 함수, 기능, 클래스 등에 대한 도움 문서 출력
- dir(): 함수가 가지고 있는 모든 attribute에 대한 문자열 리스트 반환
- type(): 인자의 클래스 반환
제어문
if문
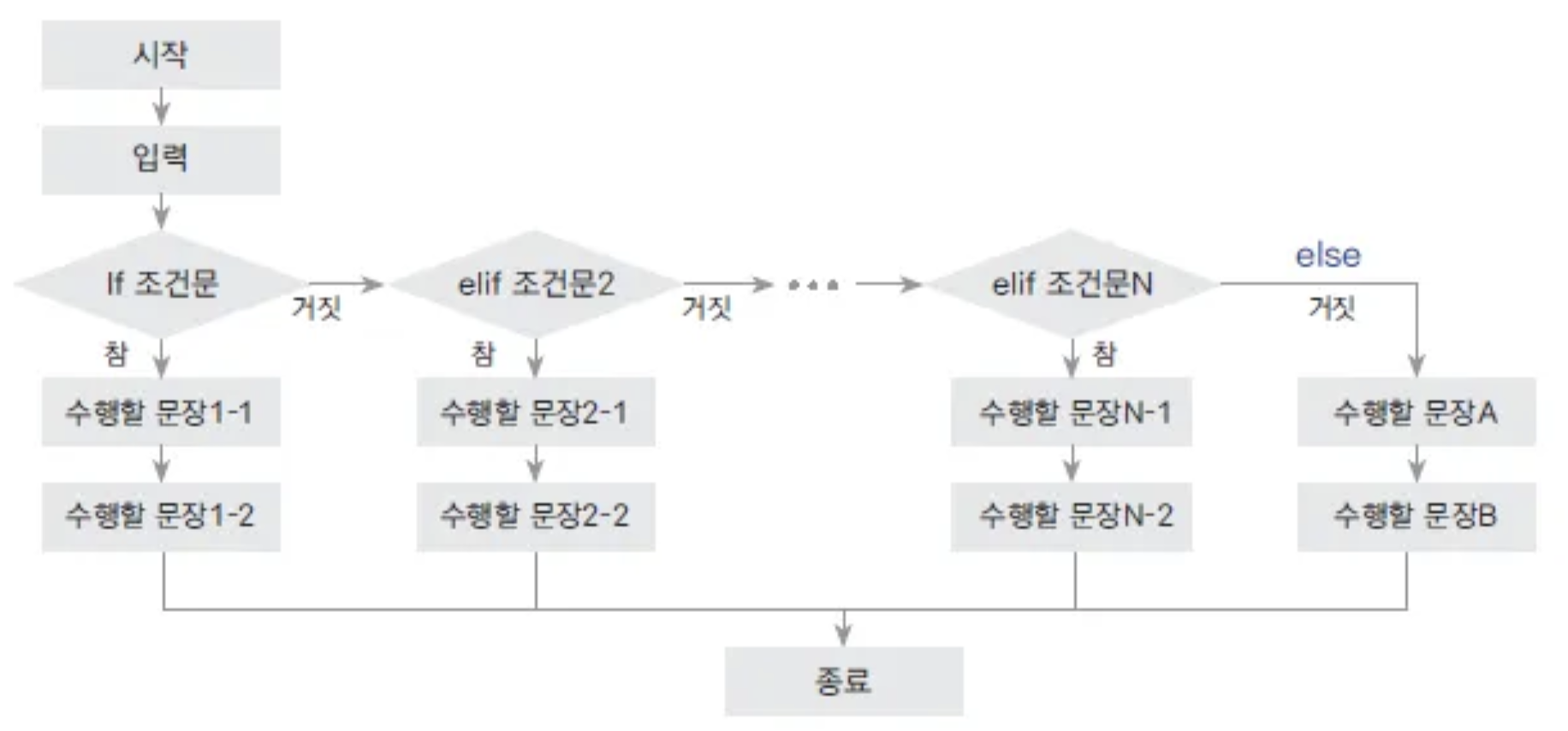
if money<=3000:
print("걸어가라")
elif money<=4000:
print("버스타라")
elif money<=10000:
print("택시타라")
else:
print("비행기 타라")- if문을 pass하고 싶을 때
pocket = ['paper', 'money', 'cellphone']
if 'money' in pocket:
pass
else:
print("카드를 꺼내라")
# -> 아무런 값이 나오지 않음for문
- 정해진 범위나 컬렉션의 항목을 순차적으로 처리할 때 사용
- 반복 대상이 끝나면 자동 종료
- 기본 구조 : 리스트에 있는걸 하나씩 변수로 담음
for 변수 in 리스트(또는 튜플, 문자열):
수행할_문장1
수행할_문장2- 리스트 활용 예시
marks = [90, 25, 67, 45, 80] # 학생들의 시험 점수 리스트
number = 0 # 학생에게 붙여 줄 번호
for mark in marks: # 90, 25, 67, 45, 80을 순서대로 mark에 대입
number = number +1
if mark >= 60:
print("%d번 학생은 합격입니다." % number)
else:
print("%d번 학생은 불합격입니다." % number)- range(start, stop[, step]) : 리스트를 자동으로 만들어주는 함수
- continue : for 문의 처음으로 돌아감
marks = [90, 25, 67, 45, 80]
number = 0
for mark in marks:
number = number +1
if mark < 60:
continue
print("%d번 학생 축하합니다. 합격입니다. " % number)- % : 문자열 포매팅에 사용되는 연산자 (f스트링으로 대체 가능)
%d: 정수
%s: 문자열
%f: 실수
%x: 16진수
while문
- 조건문이 참이면 계속 반복 실행(무한 루프)
*조건을 만족하지 않으면 즉시 종료, 무한 루프에 빠지지 않도록 탈출 조건 명시 필요 - break : 강제로 while 문을 빠져나가고 싶을 때
coffee = 10
money = 300
while money:
print("돈을 받았으니 커피를 줍니다.")
coffee = coffee -1
print("남은 커피의 양은 %d개입니다." % coffee)
if coffee == 0:
print("커피가 다 떨어졌습니다. 판매를 중지합니다.")
break- continue 사용
# 홀수만 출력
a = 0
while a < 10:
a = a + 1
if a % 2 == 0: continue
print(a)pandas
데이터 구조
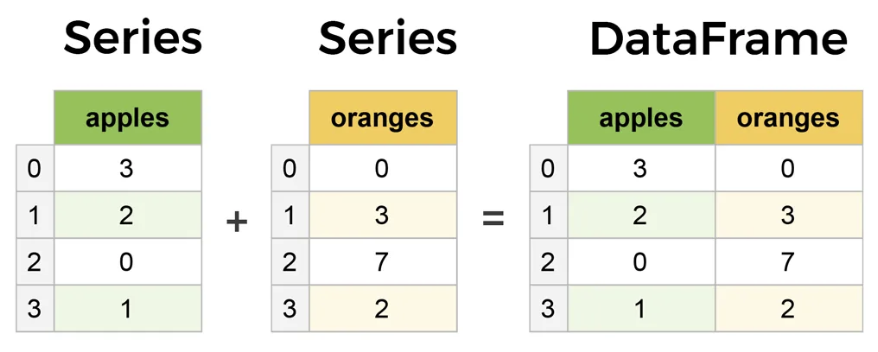
-
Series : 1차원 배열, 분석 작업에서 데이터와 관련된 추가 정보가 필요한 경우 사용
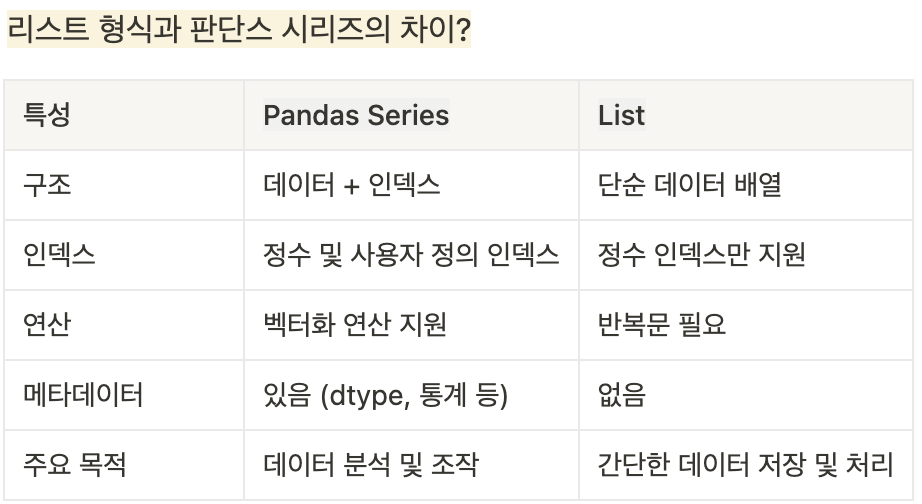
-
DataFrame : 2차원 데이터 구조(Excel 데이터 시트)
-index : index(기본 값으로 RangeIndex)
-columns : column명
-values : numpy array형식의 데이터 값
-dtypes : column 별 데이터 타입
-T : DataFrame을 전치(Transpose)
-shape : 데이터 형
데이터 불러오기
# 만약 한글이 깨진다면? encoding 지정 필요
# 높은 확률로 utf8 or cp949면 한글 깨지지 않음
df = pd.read_csv('train.csv', encoding='utf8')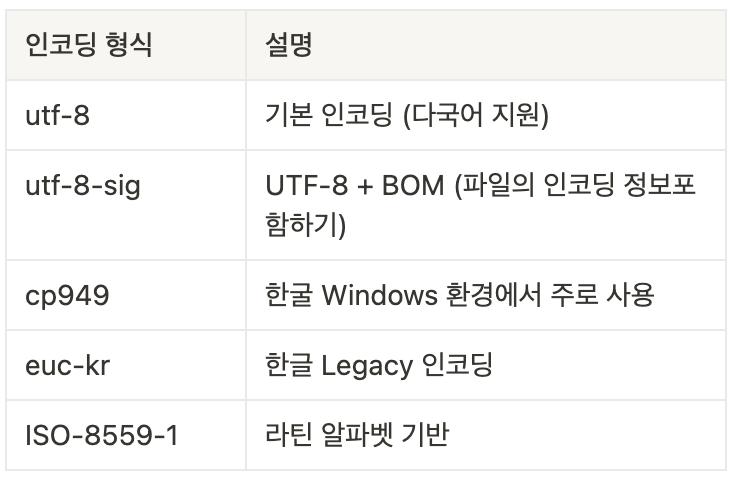
DataFrame 메서드
- 조회 및 탐색 : 데이터를 탐색하고, 정보를 얻기 위한 메서드
head(),tail(),describe(),info() - 데이터 선택 및 필터링 : 특정 조건에 맞는 데이터를 선택하거나 필터링하기 위한 메서드
loc[],iloc[],query(),filter() - 데이터 조작 및 변형 : 데이터를 추가, 삭제, 수정하거나 특정 조건에 맞게 변형하는 메서드
append(),drop(),rename(),melt(),pivot() - 정렬 및 그룹화 : 데이터를 특정 기준에 따라 정렬하거나 그룹화하기 위한 메서드
sort_values(),sort_index(),groupby() - 결합 및 병합 : 두 개 이상의 데이터프레임을 결합하거나 병합하기 위한 메서드
concat(),merge(),join() - 결측치 처리 : 데이터프레임 내 결측치(누락된 데이터)를 처리하기 위한 메서드
isnull(),notnull(),fillna(),dropna() - 통계 및 계산 : 데이터의 기술 통계를 계산하거나 데이터에 대한 수학적 연산을 수행하는 메서드
mean(),median(),sum(),std(),corr() - 변형 및 재구성 : 데이터프레임의 구조를 변형하거나 데이터를 재구성하기 위한 메서드
pivot(),pivot_table(),stack(),unstack() - 시계열 데이터 처리 : 시계열 데이터를 처리하기 위한 특수 메서드 집합
resample(),asfreq(),rolling()
loc와 iloc 차이
- 데이터프레임의 특정 데이터를 선택하거나 조작하는 데 사용되는 인덱싱 메서드
- loc : 행과 열의 라벨(이름)을 사용하여 데이터를 선택
df.loc[0, 'A'] # 행 라벨이 0인 행의 'A' 열 값을 선택
df.loc[:, 'B'] # 모든 행의 'B' 열 값을 선택- iloc : 행과 열의 정수 위치를 사용하여 데이터를 선택
df.iloc[0, 0] # 첫 번째 행의 첫 번째 열 값을 선택
df.iloc[:, 1] # 모든 행의 두 번째 열 값을 선택
👋🏻