웹크롤링
- 웹 페이지의 데이터를 자동으로 수집하는 기술
- 비정형 데이터를 정형 데이터로 변환
- 회사 외부에서 방대하고 다양한 정보를 수집하는 도구
- 다양한 데이터 소스를 활용할 수 있는 능력을 키우는 데 중요한 기술
import requests
url = "<URL>" # 예제 URL
response = requests.get(url)
print(response.status_code) # 상태코드 출력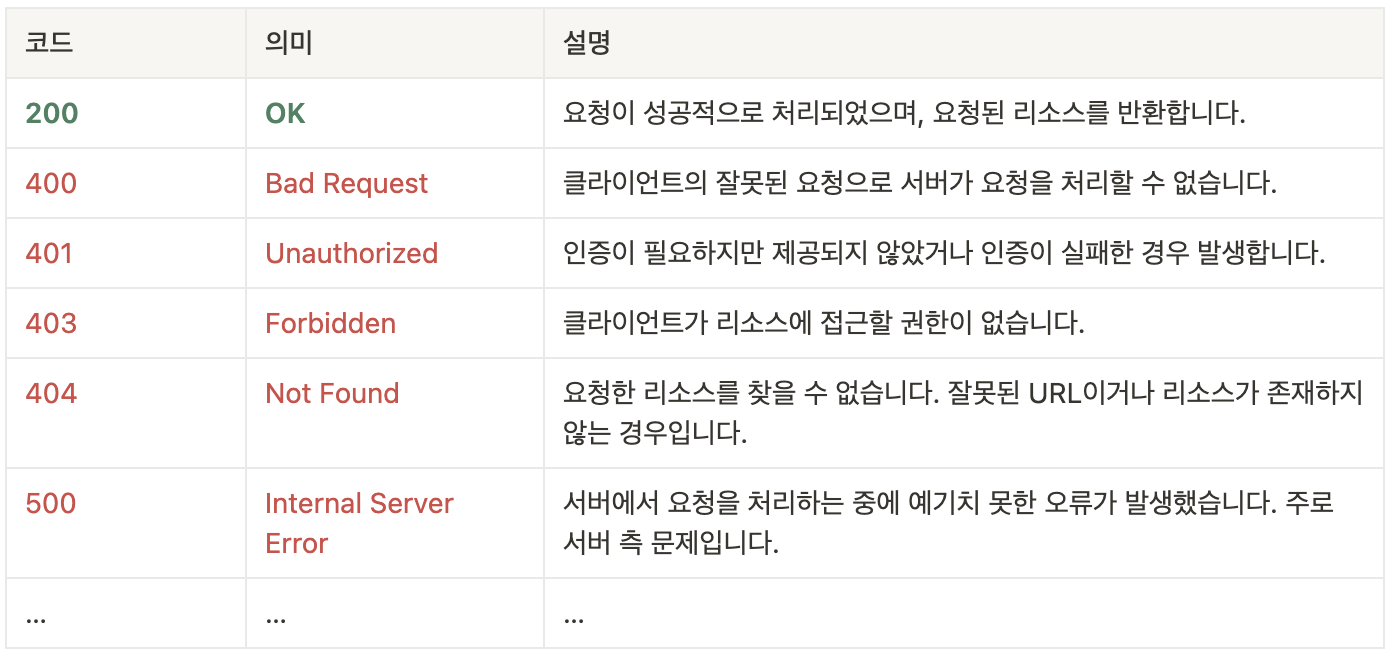
BeautifulSoup
- HTML에서 필요한 데이터를 추출하기 위해 필요한 라이브러리
- HTML 파싱(문자열에서 특정 데이터를 추출하거나 원하는 형식으로 변환하는 프로세스) 및 데이터 추출 시 사용

url = "https://search.naver.com/search.naver?query=서울날씨"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
feel_temp = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd').get_text()
humidity = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(2) > dd').get_text()
wind = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(3) > dd').get_text()
print("체감온도:", feel_temp)
print("습도:", humidity)
print("서풍:", wind)- csv로 저장
import pandas as pd
# 데이터 준비
data = [{'temperature': feel_temp, 'humidity': humidity, 'wind': wind}]
# DataFrame 생성 및 CSV 파일로 저장
df = pd.DataFrame(data)
df.to_csv('weather_webscraping.csv', index=False)
print("날씨 정보가 CSV 파일로 저장되었습니다.")객체지향 프로그래밍 (Object Oriented Programming, OOP)
- 현실 개념을 코드로 모델링 가능
- 코드 재사용성과 유지보수성 향상
- 복잡한 문제 해결에 유리
- 캡슐화, 상속, 다형성 지원
# 클래스 정의
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
print(f"안녕하세요, 저는 {self.name}이고, 나이는 {self.age}살입니다.")
def __str__(self):
return f"!학생에 대한 정보입니다!\n이름: {self.name}\n나이: {self.age}"
# 객체1, 홍길동 생성
student1 = Student("홍길동", 20)
student1.introduce()
print(student1)
# 객체2, 이영희 생성
student2 = Student("이영희", 22)
student2.introduce()
print(student2)연습문제
Q. 네이버 경제 > 증권 뉴스에 보이는 뉴스 제목을 출력해주세요!
# 라이브러리
import requests
from bs4 import BeautifulSoup
# url 가져오기
url = "https://news.naver.com/breakingnews/section/101/258"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 타이틀 가져오기
titles =soup.findAll('strong', {'class' : 'sa_text_strong'})
for title in titles:
print(title.get_text())
👋🏻