텍스트 데이터
- 전형적인 비정형 데이터 중 하나
- 전처리를 통해 분석 가능한 형태로 변형해야 함
- 자연어 처리(Natural Language Processing)를 통해 정형화된 정보를 추출하고 이를 분석에 활용해야 함
임베딩 방법
- 임베딩 : 자연어를 기계가 이해할 수 있도록 숫자 형태인 벡터로 바꾸는 과정
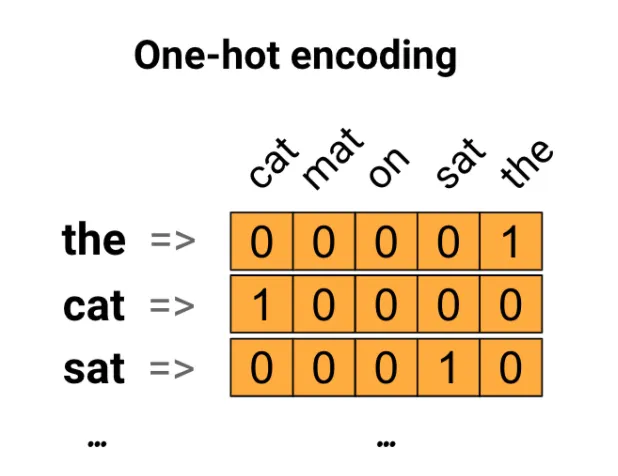
- One Hot Encoding
- 하나의 단어가 하나의 차원(컬럼)이 되는 것
- 문서에 해당 단어가 있으면 1, 없으면 0
- Term Frequency(Term Frequency - Inverse Document Frequency)
- 하나의 단어가 하나의 차원(컬럼)이 되는 것
- One Hot Encoding과는 달리 단어가 등장한 횟수를 값으로 가지는 벡터를 만듦
- scikit-learn의 CountVecotrizer 활용
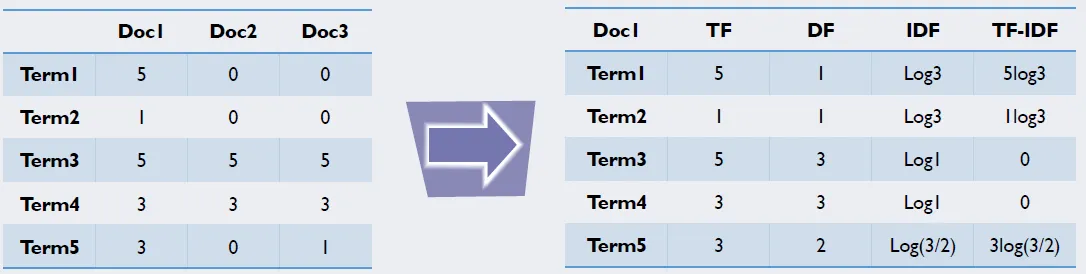
- TF-IDF (Term Frequency - Inverse Document Frequency)
- 하나의 단어가 하나의 차원이 됨
- TF만 따지면 조사나 관사 등 의미없는 단어가 자주 등장할 가능성이 큼
- 공통된 문서에서 자주 등장하는 단어는 페널티를 줘서 중요도를 낮추는 방법
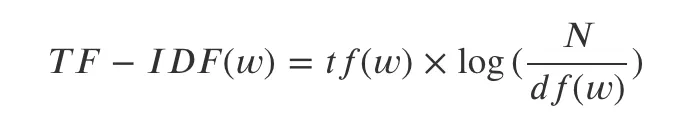
- tf(w): 단어 w의 Term Frequency / df(w): 단어 w의 Document Frequency / N: 총 문서의 개수
- scikit-learn의 TfidfVectorizer 활용
- Word Embedding
- 빈도 기반으로 단어를 벡터화하면 단어와 단어 사이의 관계, 문맥 등을 반영하기 어려움
- 연관성 있는 단어를 가까운 곳에, 연관성이 떨어지는 단어를 먼 곳에 위치하게 벡터화를 하면 단어 사이 연관성을 파악하기 수월해짐
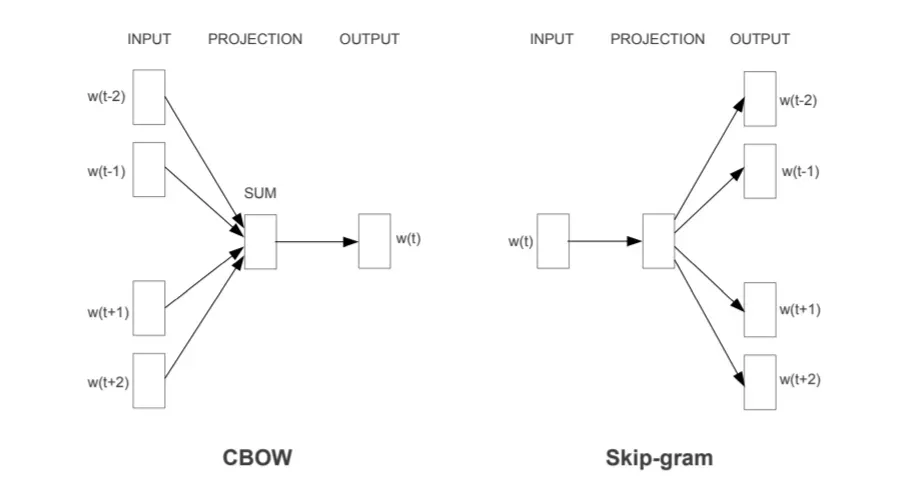
- 특정 문장에서 단어의 ‘주변 단어’를 활용하는 Word2Vec 알고리즘 등을 활용하여, 단어를 주어진 차원(하이퍼 파라미터)에 벡터화
- Skip-gram: 특정 단어가 주어졌을 때 주변 단어를 예측하는 모델(더 많이 씀)
- C-Bow: 주변 단어가 주어졌을 때 빈 칸의 단어를 예측하는 모델
- gensim의 word2vec 모델을 사용하여 구현 가능
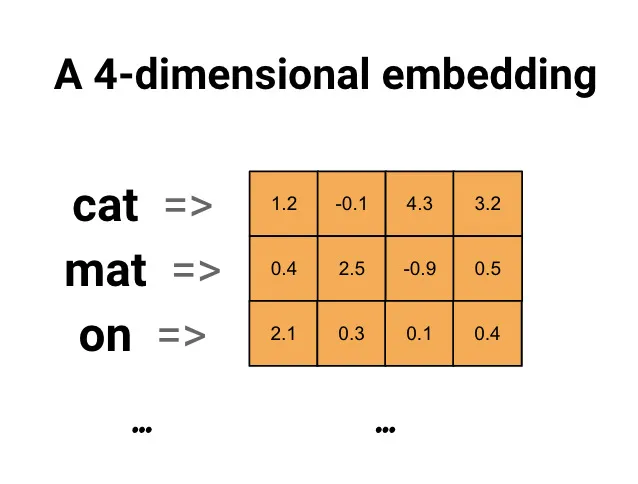
- LLM을 활용한 임베딩과 Vector DB
- ChatGPT와 같은 LLM(Large Language Model)은 수많은 텍스트 데이터를 학습하여 만들어진 결과물
- 이미 학습된 LLM의 API 호출을 통해 텍스트를 벡터로 변환 가능
- Vector DB는 벡터 형태 데이터를 효율적으로 다룰 수 있는 DB이며 벡터 형태의 검색 가능
데이터 전처리
- 문장 정리(Sentence Segmentation)
- 더 작은 문장 단위로 쪼개는 것
- 마침표처럼 확실한 구분자를 이용해 구분하는 방식이 있음
- 분석 대상 언어마다, 글의 속성에 따라 적용할 수 있는 룰이 다름
- 불필요한 문자 제거(Text Cleaning)
- 불필요한 텍스트가 포함되어 있는 경우 사전 제거 (ex.ㅋㅋㅋ, 특수문자)
- 정규 표현식(Regex)를 활용해 간편하게 특정 문자열 제거 가능
- 토큰화(Tokenization)
- 문장을 의미있는 단위로 쪼개는 작업으로 전처리의 핵심
- 영어같은 경우는 띄어쓰기 단위로만 쪼개도 각 토큰이 어느 정도 의미를 가지고 있음
- 한글의 경우 띄어쓰기에 민감하지 않아 띄어쓰기가 잘 이루어지지 않는 경우도 많을 뿐더러, 띄어쓰기 단위인 ‘어절’로 쪼개도 의미 단위로 쪼개지지 않음
- 형태소 분석기를 이용해 나뉘어진 토큰은 품사 태그(Part-of-speech, POS) 정보를 포함하고 있어 이를 분석에 활용할 수 있음
- 영문의 경우 표제어 추출(Lemmatization), 어간 추출(Stemming) 기법 활용
- 표제어 추출: 기본 사전어 단어로 변환 (ex.am, are , is → be)
- 어간 추출 : 단어 생성 규칙에 따라 어간만 남기는 방법(ex.numerical → numeric)
- 불용어 제거(Stopword)
- 토근 중에서 불필요한 토큰을 제거하는 단계
- 불용어를 모아둔 집합을 ‘불용어 사전’
- https://www.ranks.nl/stopwords/korean
사례
- 감성 분석
- 긍정과 부정, 그리고 중립으로 분류하는 분류 문제로 주로 리뷰나 댓글에 적용
- 단어마다 긍정, 부정, 중립 점수를 부여하는 감성 언어 사전을 구축하여 문장을 scoring하고 분류하는 방법
- 문장(리뷰)을 벡터화한 뒤 문장의 label을 활용하여 분류 모델을 학습하는 방법
- 텍스트 자동 분류
- 카테고리가 명시된 텍스트(문서)에 대해 카테고리를 자동으로 분류하는 분류 모델 생성
- 대량의 텍스트 데이터를 분류하여 살펴볼 때 유용
- 라벨링된 문서를 대상으로 분류 모델을 학습하여 자동 분류 모델 생성 가능
- 텍스트 데이터 클러스터링
- 텍스트 데이터를 벡터화하고 난 이후 클러스터링 과정은 정형 데이터 분석과 동일함
- 다만 정형화된 텍스트 데이터는 다른 데이터 대비 차원이 굉장히 큼
- 유클리디언 거리보다는 코사인 거리를 활용하면 좋은 성능을 기대할 수 있음
코드
# 패키지 설치
!pip install kss konlpy customized_konlpy
# 라이브러리
import re
import pandas as pd
import kss
from konlpy.tag import Okt, Kkma, Komoran
from ckonlpy.tag import Twitter
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
#warning 메시지 무시
import warnings
warnings.filterwarnings('ignore')
# 실습에 사용할 뉴스 데이터셋 받아오기 (허깅페이스)
splits = {'train': 'train.csv', 'validation': 'validation.csv', 'test': 'test.csv'}
df_news = pd.read_csv("hf://datasets/daekeun-ml/naver-news-summarization-ko/" + splits["train"])
# 리스트로 변경
news_documents = df_news['document'].to_list()
# 확인
news_documents[10]
# kss 패키지를 활용한 문장 분리
kss.split_sentences(news_documents[10])
# Regex를 활용해 영문, 한글, 숫자, 공백, '.'만 남도록 변경
re.sub(r'[^\w\s\.,]', '', news_documents[10])
# 데이터 클리닝 함수
def text_cleaning(text):
#이메일 주소 제거
text = re.sub(r'[a-zA-Z0-9._%+-]*@*[a-zA-Z0-9-]+\.(?:com|co\.kr|net)', '', text)
#날짜 형식 제거 (YYYY.MM.DD)
text = re.sub(r'\d{4}\.\d{2}\.\d{2}', '', text)
#대괄호와 내용 제거
text = re.sub(r'\[.*?\]', '', text)
#중괄호와 내용 제거
text = re.sub(r'\{.*?\}', '', text)
#소괄호와 내용 제거
text = re.sub(r'\(.*?\)', '', text)
#특수문자 제거
# 예: #, $, &, *, ^, @, !, ? 등
text = re.sub(r'[^\w\s\.,]', '', text)
#여러 개의 공백을 하나로 변경
text = re.sub(r'\s+', ' ', text)
#앞뒤 공백 제거
text = text.strip()
return text
# 함수 적용
news_documents_cleaned = [text_cleaning(doc) for doc in news_documents]
# OpenKoreanText 토크나이저 사용 실습
okt = Okt()
sample_doc = news_documents_cleaned[9]
print(sample_doc)
# morphs - 형태소 분석
print(okt.morphs(sample_doc))
#pos - 형태소 분석 결과를 POS 태그와 함께 출력
print(okt.pos(sample_doc))
#pos - 형태소 분석 결과 중에서 명사(Noun)만 출력
print(okt.nouns(sample_doc))
#Customized Konlpy를 이용해 고유명사를 추가하여 형태소 분석 진행 예시
twitter = Twitter() #OpenKoreanText 형태소 분석기의 원형
print(twitter.morphs(sample_doc))
# 변경
twitter.add_dictionary('허준이', 'Noun')
twitter.add_dictionary('고등과학원', 'Noun')
twitter.add_dictionary('수학부', 'Noun')
twitter.add_dictionary('석학교수', 'Noun')
twitter.add_dictionary('과학기술정보통신부', 'Noun')
print(twitter.morphs(sample_doc))
# POS를 활용하여 의미 있는 단어만 선별하는 작업
pos_set = ['Noun', 'Verb', 'Alpha']
def selected_tokenizer(sent, pos = pos_set) :
t = Okt()
return [x[0] for x in t.pos(sent) if len(x[0]) > 1 and x[1] in pos]
sample_tokens = [selected_tokenizer(x) for x in news_documents_cleaned[:10]]
print(sample_tokens[0])
# stopword 적용
stopwords = ['했습니다', '위해', '하기로', '합니다', '하면서', 'YTN']
sample_cleaned_token = [x for x in sample_tokens[0] if x not in stopwords]
print(sample_cleaned_token)
👋🏻