절차 : 탐색적 데이터 분석, 피쳐 엔지니어링, 데이터 정리 인코딩, 스케일링 및 사전 처리, 기계 학습 모델, 교차 검증 및 통합 예측
머신러닝의 목적 : 우주선 타이타닉이 시공간 이상과 충돌하는 동안 승객이 대체 차원으로 이송되었는지 예측
데이터 셋
train.csv
PassengerId - A unique Id for each passenger.
HomePlanet - The planet the passenger departed from, typically their planet of permanent residence.
CryoSleep - Indicates whether the passenger elected to be put into suspended animation for the duration of the voyage.
Cabin - The cabin number where the passenger is staying.
Destination - The planet the passenger will be debarking to.
Age - The age of the passenger.
VIP - Whether the passenger has paid for special VIP service during the voyage.
Name - The first and last names of the passenger.
Transported - Whether the passenger was transported to another dimension.
test.csv
Personal records for the remaining one-third (~4300) of the passengers, to be used as test data. Your task is to predict the value of Transported for the passengers in this set.
sample_submission.csv
PassengerId - Id for each passenger in the test set.
Transported - The target. For each passenger, predict either True or False.
사용 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns # 데이터 분포 시각화
sns.set(style='darkgrid', font_scale=1.4)
from imblearn.over_sampling import SMOTE
import itertools
import warnings
warnings.filterwarnings('ignore')
import plotly.express as px
import time
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV, StratifiedKFold
from sklearn.metrics import accuracy_score, confusion_matrix, recall_score, precision_score, f1_score
from sklearn.metrics import roc_auc_score, plot_confusion_matrix, plot_roc_curve, roc_curve
from sklearn.preprocessing import StandardScaler, MinMaxScaler, OneHotEncoder, LabelEncoder
from sklearn.feature_selection import mutual_info_classif
from sklearn.decomposition import PCA
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
import eli5
from eli5.sklearn import PermutationImportance
from sklearn.utils import resample
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
from sklearn.naive_bayes import GaussianNB
코드
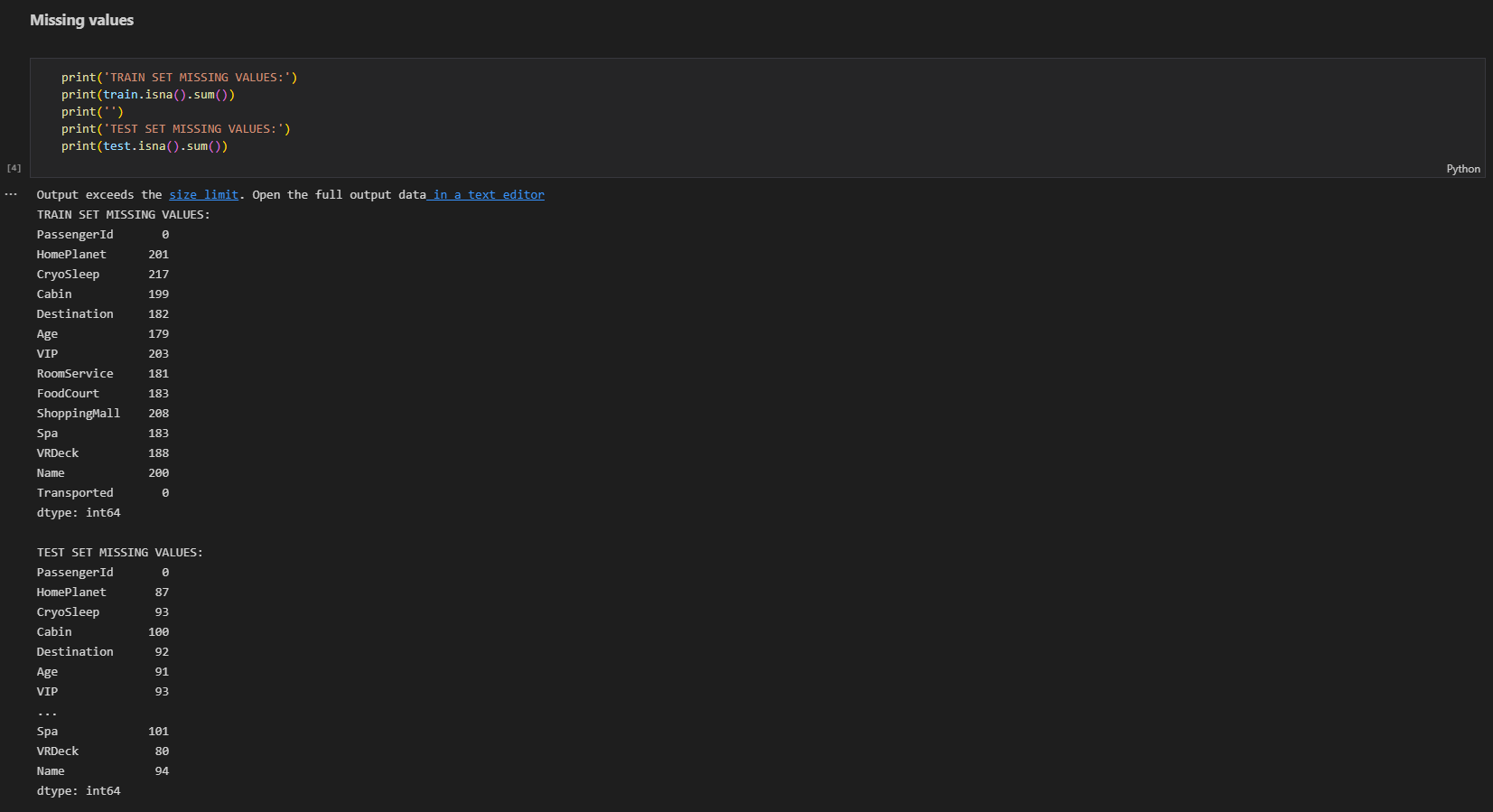 pd.isna() : DataFrame 내의 결측값 확인 후 bool로 반환
pd.isna() : DataFrame 내의 결측값 확인 후 bool로 반환
DataFrame의 Missing Values를 확인하는 코드
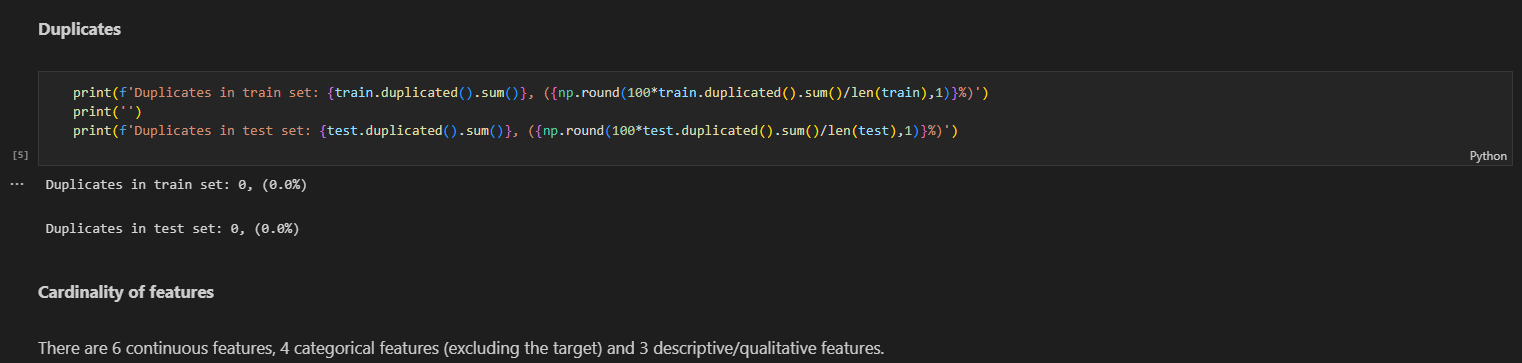 DataFrame의 중복값을 출력, DataFrame의 duplicated된 값을 DataFrame의 사이즈로 1자리 수까지 반올림해 표시
DataFrame의 중복값을 출력, DataFrame의 duplicated된 값을 DataFrame의 사이즈로 1자리 수까지 반올림해 표시
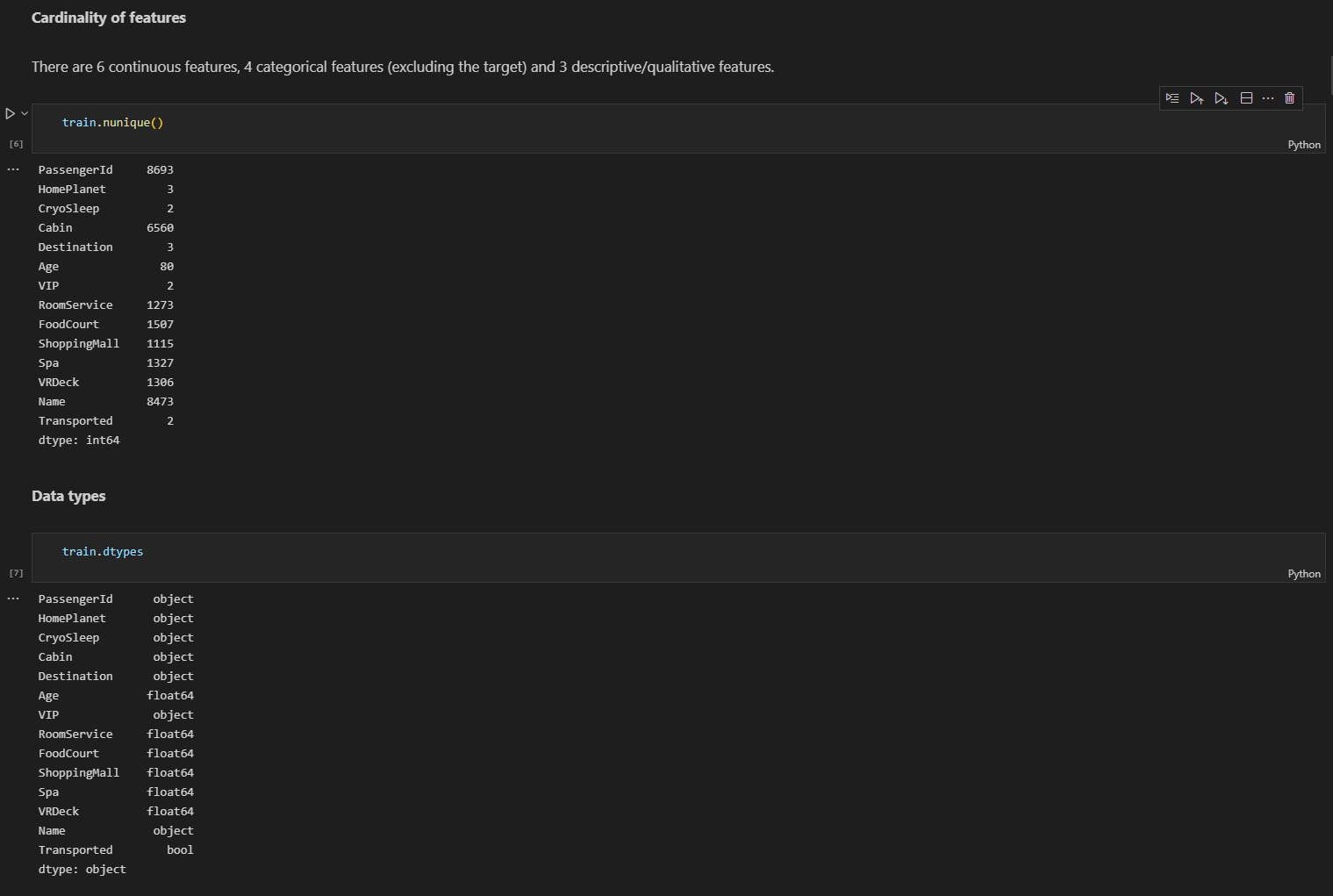 pd.nunique() : DataFrame의 고유값의 수를 출력
pd.nunique() : DataFrame의 고유값의 수를 출력
pd.dtypes() : DataFrame의 각 열의 타입을 출력
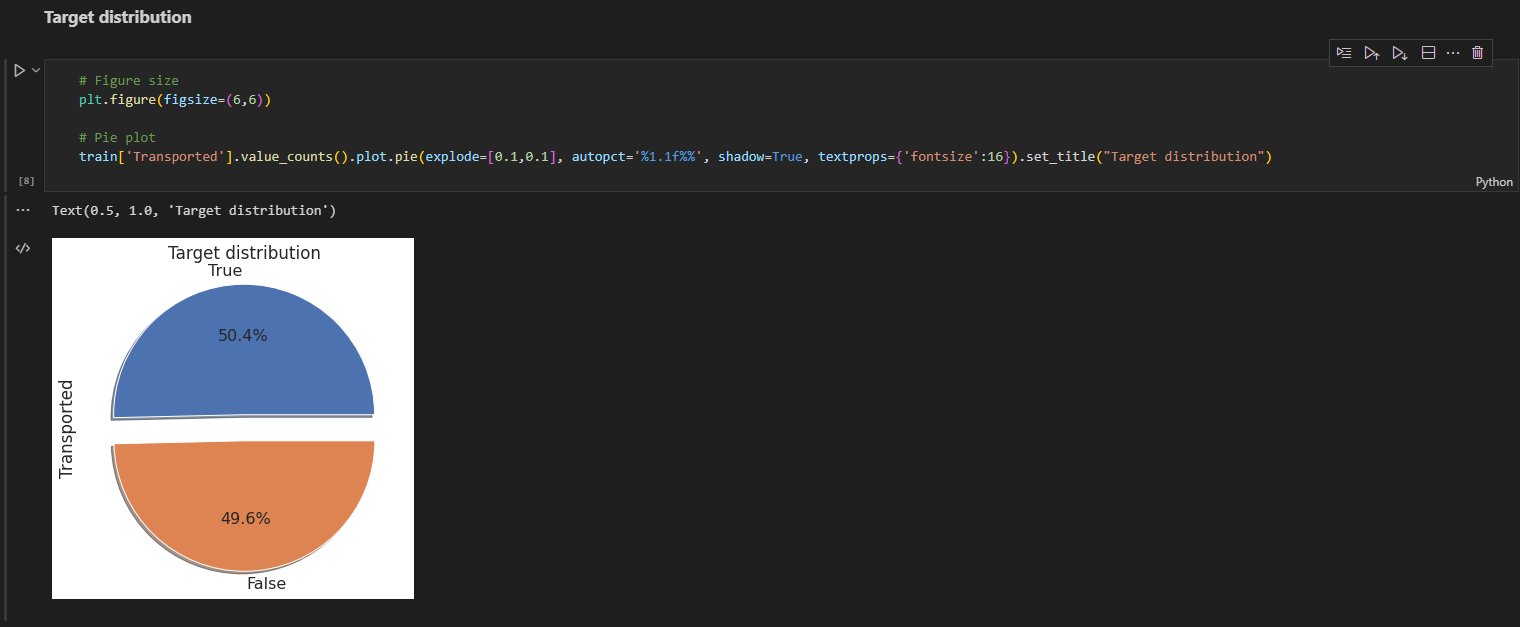 DataFrame 내의 boolean 자료형의 'Transported' 비율은 표시, 거의 반 반의 비율로 이루어져 있으며, under 또는 over sampling을 고려하지 않아도 됨.
DataFrame 내의 boolean 자료형의 'Transported' 비율은 표시, 거의 반 반의 비율로 이루어져 있으며, under 또는 over sampling을 고려하지 않아도 됨.
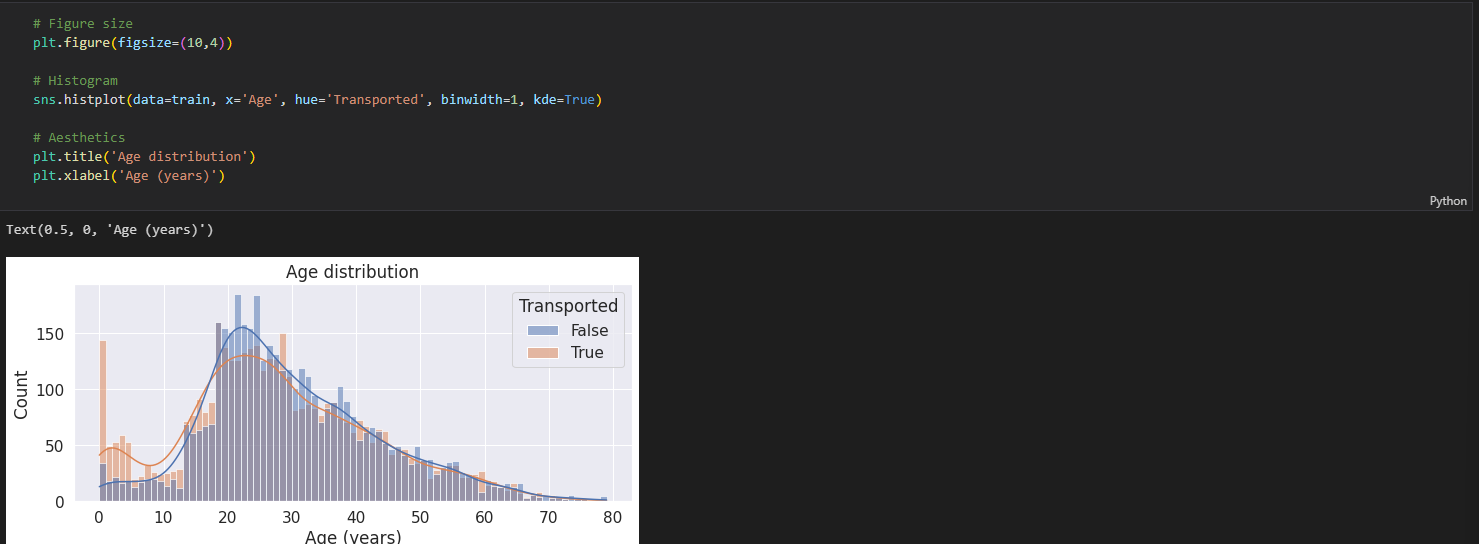 HistPlot을 이용하여, 'Age'와 'Transported'의 상관 관계를 출력.
HistPlot을 이용하여, 'Age'와 'Transported'의 상관 관계를 출력.
0~17세 층에서는 도착 비율이 더 큼.
18~34세 층에서는 대체적으로 도착하지 못한 비율이 더 큼.
35세 이상에서는 비율이 비슷하다.
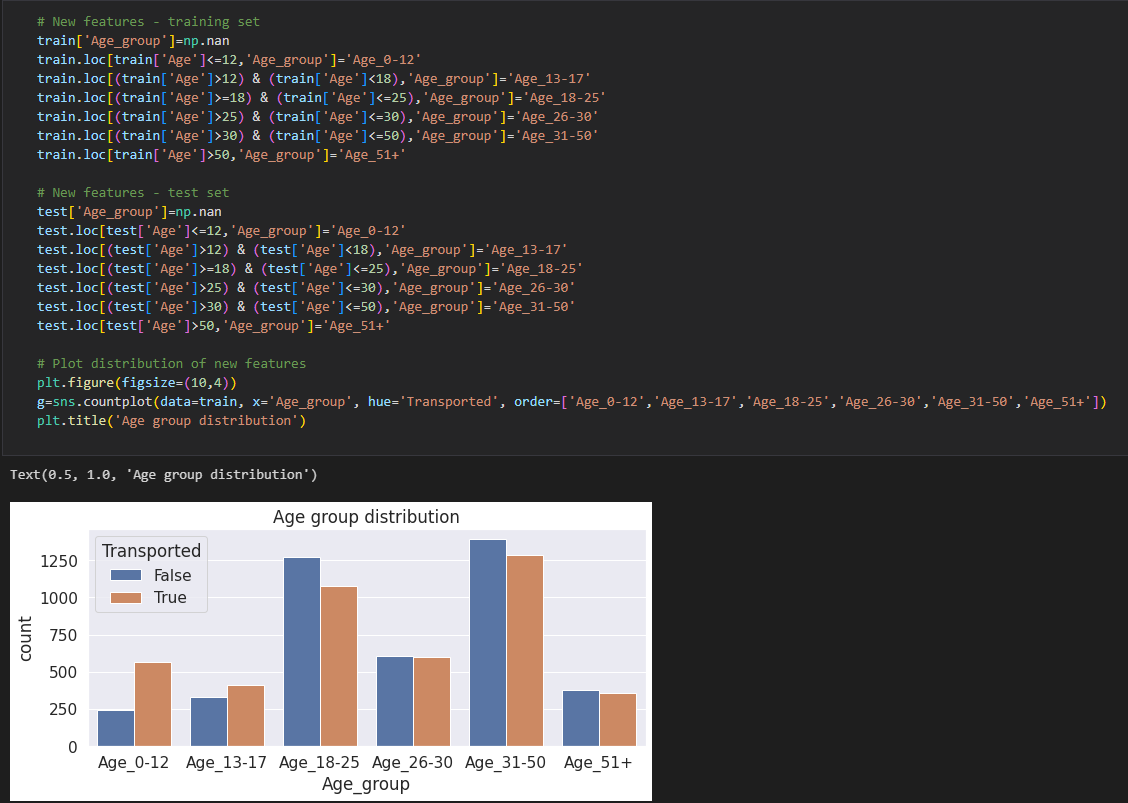 나이가 어릴 수록 도착한 비율이 높게 나오며, 18~25세의 집단과 31~50세의 집단은 도착하지 못한 비율이 더 높음.
나이가 어릴 수록 도착한 비율이 높게 나오며, 18~25세의 집단과 31~50세의 집단은 도착하지 못한 비율이 더 높음.
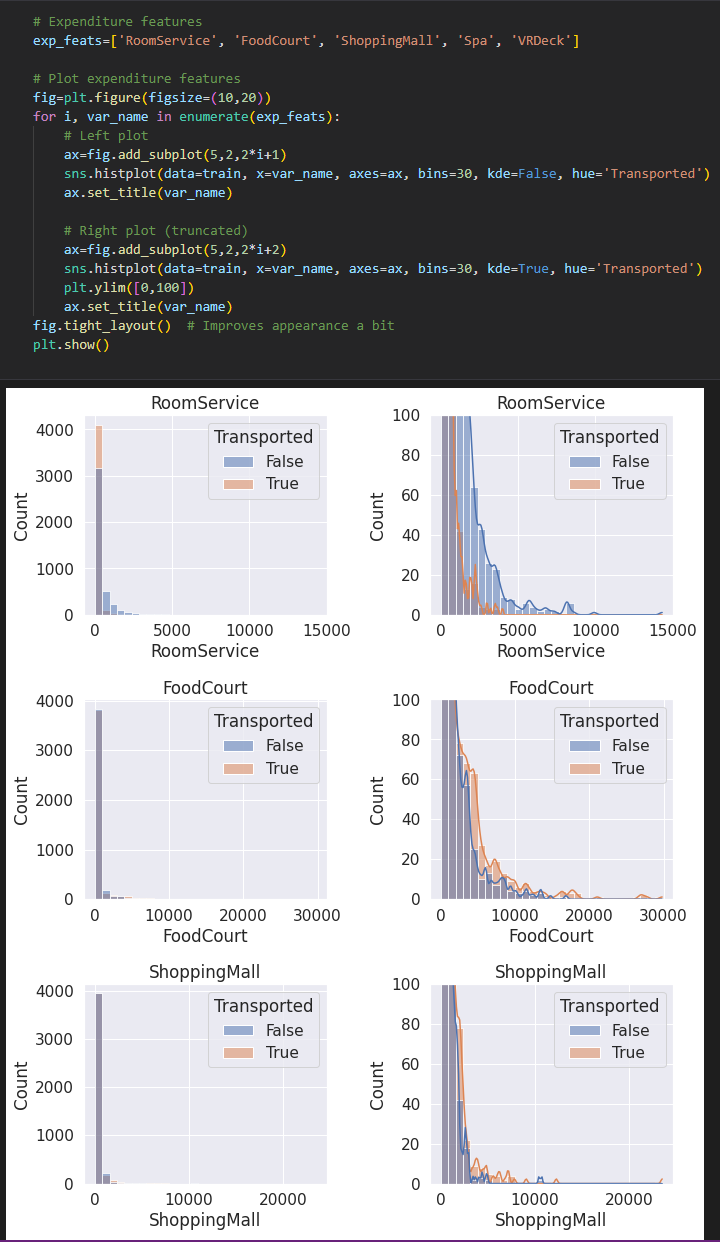
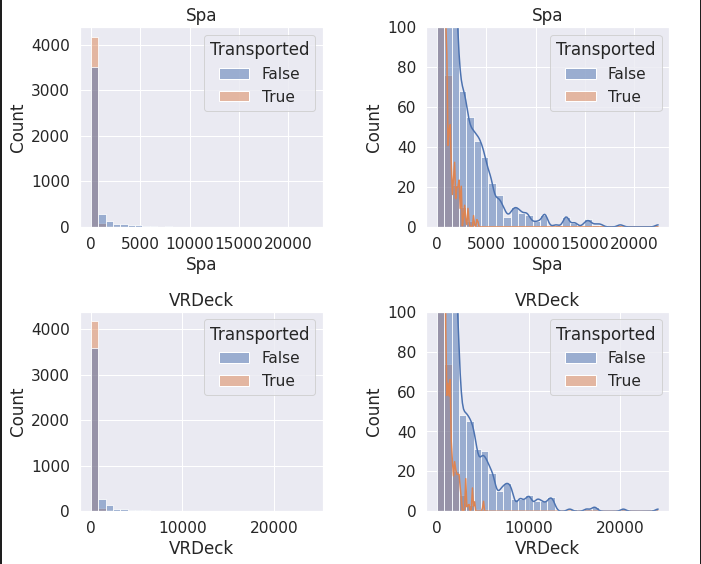 시설 이용
시설 이용
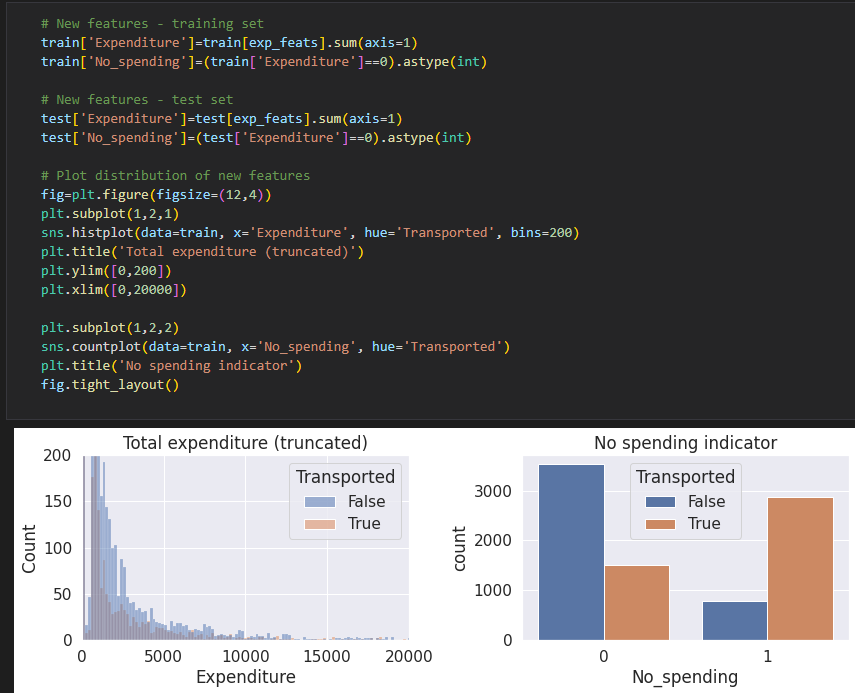
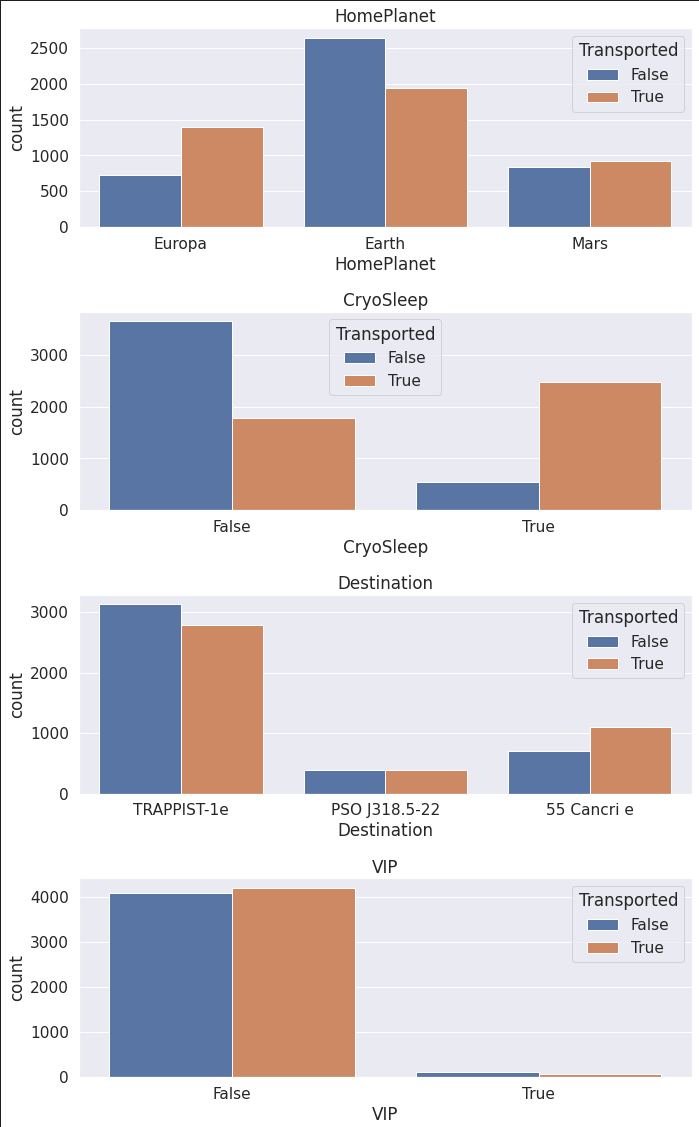
- 지구 출신 집단에서 도착한 비율이 상대적으로 적음
- 동면을 선택한 집단에서 도착한 비율이 크게 높았으며, 동면을 선택하지 않은 집단은 도착한 비율이 낮음.
- 도착한 행성은 결과에 큰 차이를 보여주지 않음.
- VIP의 유무는 결과에 차이를 보여주지 않음.
Feature engineering
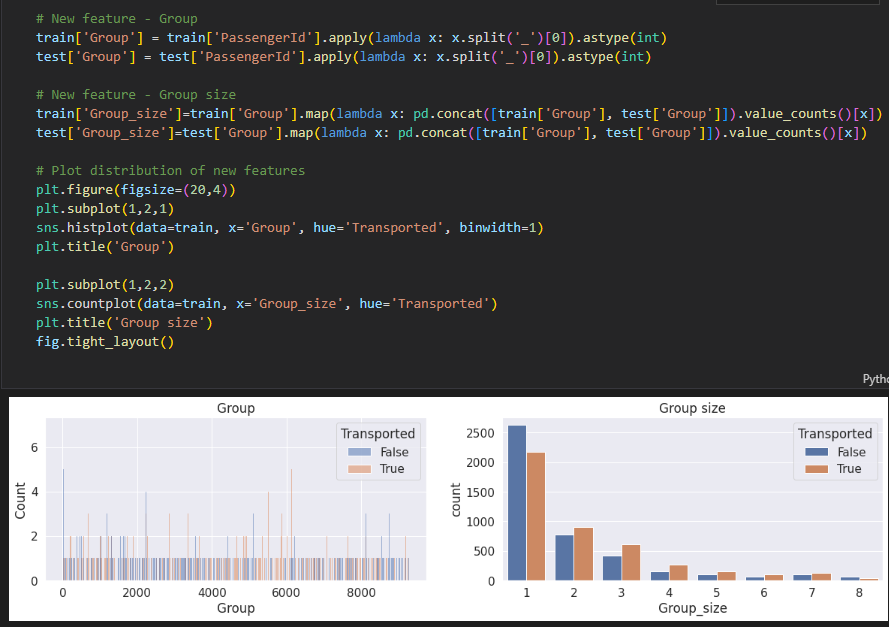 * 1인 그룹은 상대적으로 도착하지 않은 비율이 높았지만 그 외의 그룹은 도착한 비율이 높음.
* 1인 그룹은 상대적으로 도착하지 않은 비율이 높았지만 그 외의 그룹은 도착한 비율이 높음.

- 0~250 번째와 500~100 번째의 객실에서 도착한 비율이 높게 나온다.
Missing Value
Preprocessing
 중복 등 불필요한 데이터를 제거
중복 등 불필요한 데이터를 제거

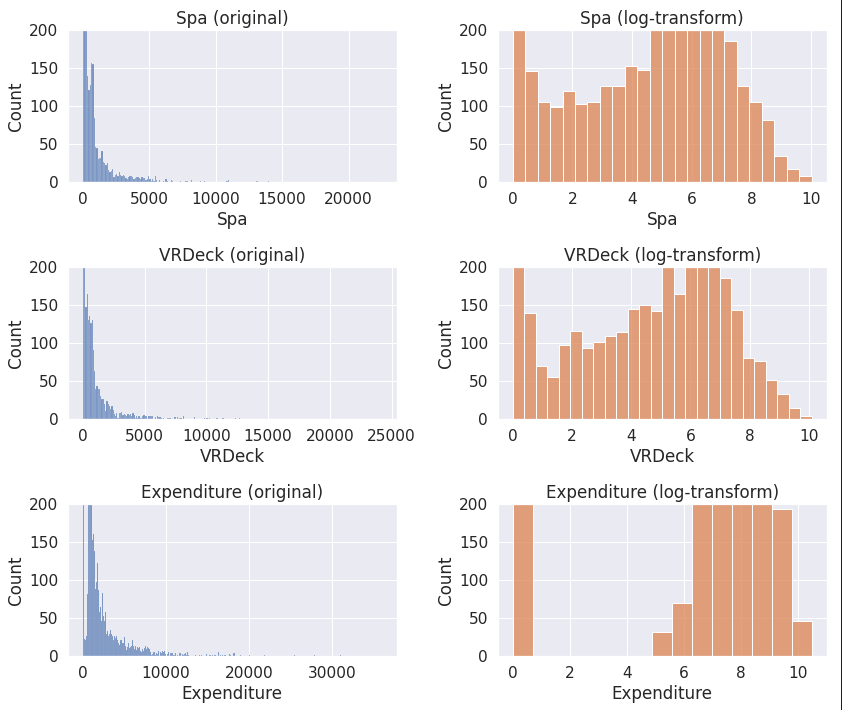 * log-transform을 이용하여 시각적으로 보기 편하게 정리
* log-transform을 이용하여 시각적으로 보기 편하게 정리
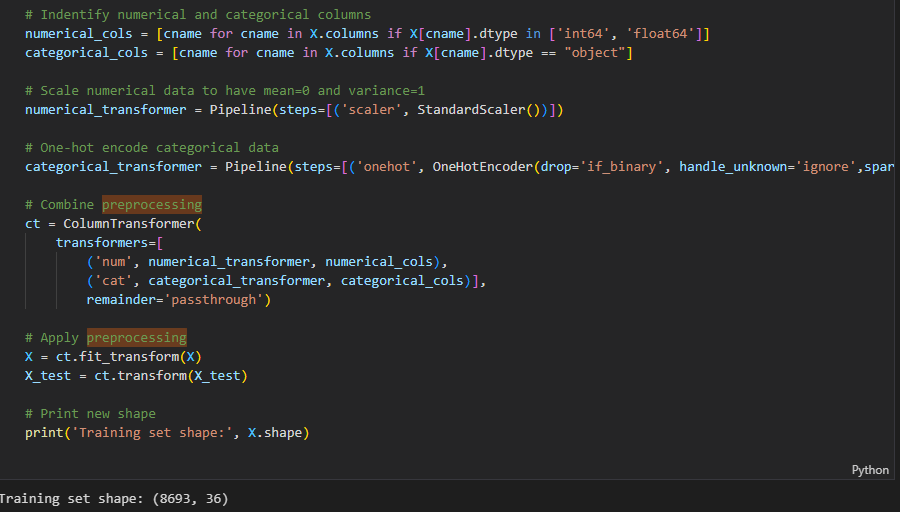 * 자료형에 따라 숫자형과 카데고리형으로 분리 후 인코딩 및 스케일링
* 자료형에 따라 숫자형과 카데고리형으로 분리 후 인코딩 및 스케일링
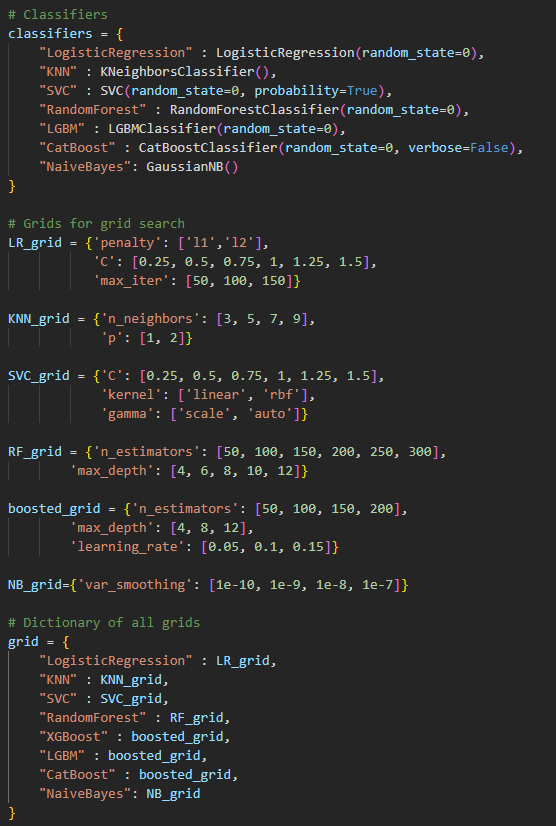 * LogisticRegression : 최소 제곱을 사용하는 선형 회귀 분석과 달리 최대우도 추정을 사용하여 목표 변수 분포에 시그모이드 곡선을 사용. S자형/논리 곡선은 데이터가 이진 출력을 가질 때 일반적으로 사용.
* LogisticRegression : 최소 제곱을 사용하는 선형 회귀 분석과 달리 최대우도 추정을 사용하여 목표 변수 분포에 시그모이드 곡선을 사용. S자형/논리 곡선은 데이터가 이진 출력을 가질 때 일반적으로 사용.
- KNN : k-근접 이웃의 대다수 클래스를 선택하여 작동하며, 여기서 사용되는 메트릭은 보통 유클리드 거리. 간단하고 효과적인 알고리듬이지만 k의 값, 데이터에 수행된 전처리, 사용된 메트릭과 같은 많은 요인에 의해 민감할 수 있음.
- SVC : 기능 공간에서 데이터를 분리하는 최적의 하이퍼플레인을 찾아, 초평면의 어느 쪽에 시험점이 놓여 있는지를 보고 예측
- RandomForest : 회귀 또는 분류 문제에 사용할 가능. 여기서 개별 트리는 배깅을 통해 구축되고 더 적은 기능을 사용하여 분할
- LGBM : XGBoost와 기본적으로 동일하지만 보다 가벼운 부스팅 기술로 작동
- CatBoost : 그레이디언트 부스트 의사결정 트리를 기반으로 하는 오픈 소스 알고리즘이다. 숫자, 범주 및 텍스트 기능을 지원
- NaiveBayes : 베이즈의 정리를 사용하여 샘플을 분류, 매우 빠르지만 단점은 입력 기능이 독립적이라고 가정
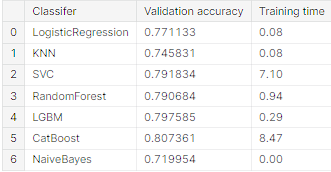
 * 각 모델 결과 CatBoost와 LGBM의 Validation accuracy가 높음을 확인.
* 각 모델 결과 CatBoost와 LGBM의 Validation accuracy가 높음을 확인.
